本文主要是介绍大道至简?ETH研究团队提出简化版Transformer模型,综合效率明显提升,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文题目: Simplifying Transformer Blocks
论文链接:https://arxiv.org/abs/2311.01906
2023年,Transformer已经成为人工智能领域中最受欢迎的基础模型,如今火热的大型语言模型,多模态大模型均由不同类型的Transformer架构组成。与先前的CNN模型类似,Transformer同样遵循一个设计规范,即首先构造一个基础块,这个基础块通常由注意力块、MLP层、跳跃连接和归一化层构成,它们以特定的排列方式进行组合,随后对基础块进行堆叠形成最终的Transformer模型。不难看出,每个基础块的内部其实存在多种不同的排列方式,这种复杂性直接导致了整体架构的不稳定。
本文介绍一篇来自苏黎世联邦理工学院(ETH Zurich)计算机科学系的研究工作,本文从信号传播理论的角度重新审视了标准Transformer基础块的设计缺陷,并提出了一系列可以在不降低训练速度的情况下对基础块进行优化的方案。例如直接移除跳跃连接和调整投影层参数等操作来简化基础块,作者在自回归解码器和BERT编码器等具体模型上的实验表明,通过简化后的Transformer可以达到与标准Transformer的相当的训练速度和性能,同时训练吞吐量提高了15%,使用的参数减少了 15%。
01. 引言
简单来说,本文的研究目的是探究Transformer基础块中各个组件的必要性,包括跳跃连接、投影矩阵、自注意力和归一化层等。从信号传播理论层面出发,本文的工作突出了信号传播的优势和目前的局限性,信号传播理论研究了神经网络参数初始化时网络内部几何信息的演化,其通过捕捉对不同层表征之间计算内积的方式来提高模型性能。然而,目前的理论往往只考虑模型的前向传递过程,而忽略了研究网络动态训练过程中的信息传递,例如跳跃连接对训练速度的益处。
从模型实际落地方面考虑,目前数十亿参数级别的参数规模已经逐渐成为大模型入门的门槛,如果能移除掉一些非必要的组件来简化Transformer基础块,既能减少参数数量,又能提高模型的吞吐量。本文简化Transformer基础块的出发点来源于作者在ICLR 2023上发表的论文《Deep Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation》[1]。

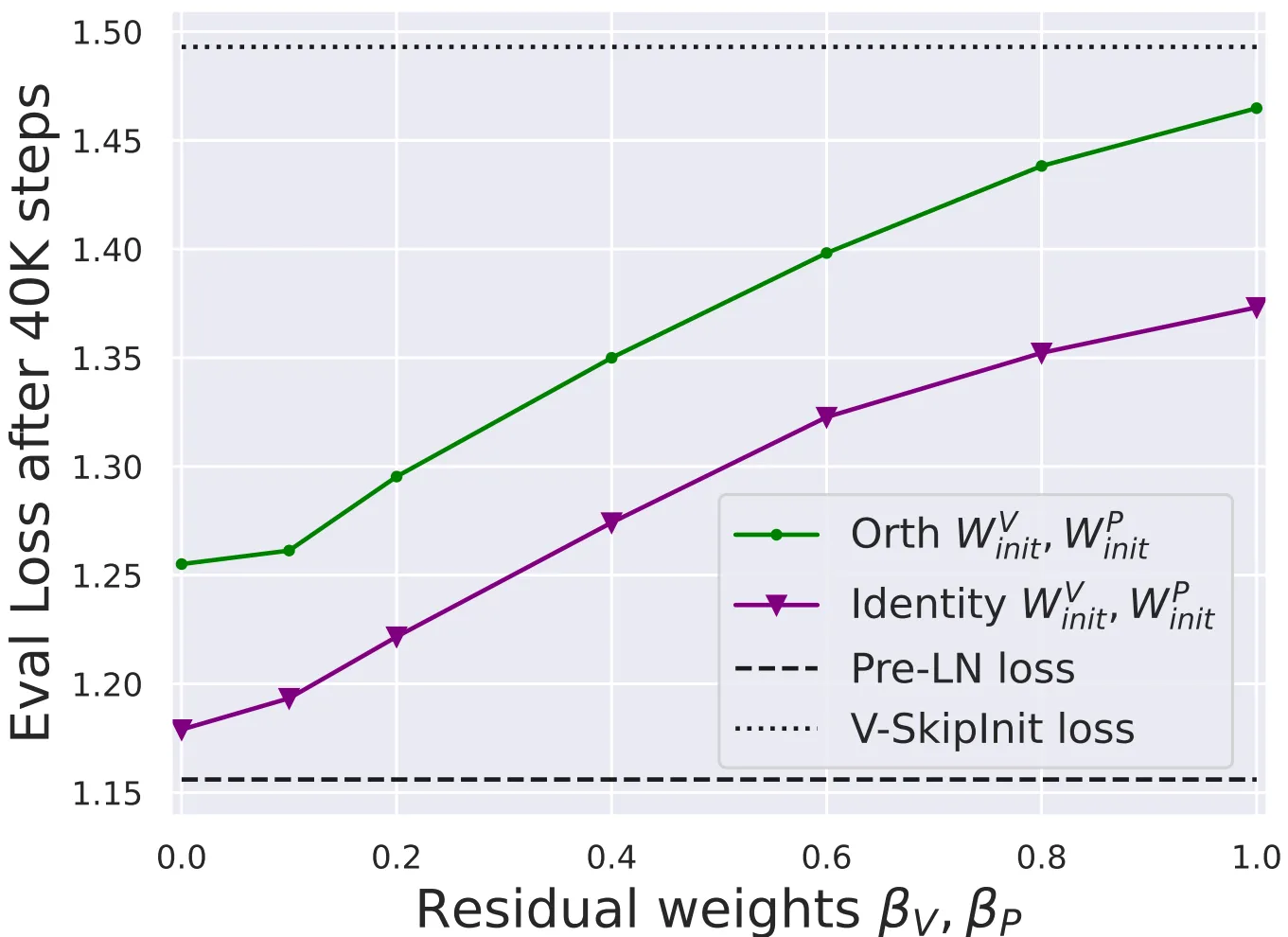
在这篇论文中,作者证明了一个重要的观察,即Transformer模型在缺乏残差连接或归一化层时仍然可以成功训练,但每次参数更新的收敛速度会显着降低。因此本文对基础块中其他组件的参数进行调整,例如调整value和投影参数的更新策略,或者直接移除,可以提高模型在缺乏残差连接时的性能。更进一步,作者将这种简化后的基础块与并行子块策略相结合就可以弥补之前方法在收敛速度上的缺陷。同时,从模型实用性和泛化性方面考虑,作者将本文的简化块应用到各种Transformer架构上,包括纯编码器和纯解码器架构,实验结果均表明简化后的基础块会达到更好的综合性能。
02. 本文方法
2.1 标准块和并行结构
目前流行的Transformer的标准块结构如下图左侧所示,称为Pre-LN,其与最原始的Post-LN块的不同之处在于二者的归一化层相对于跳跃连接的位置不同,由于Post-LN块的训练稳定性较差以及深层信号传播等问题,目前Pre-LN模块更加常用。
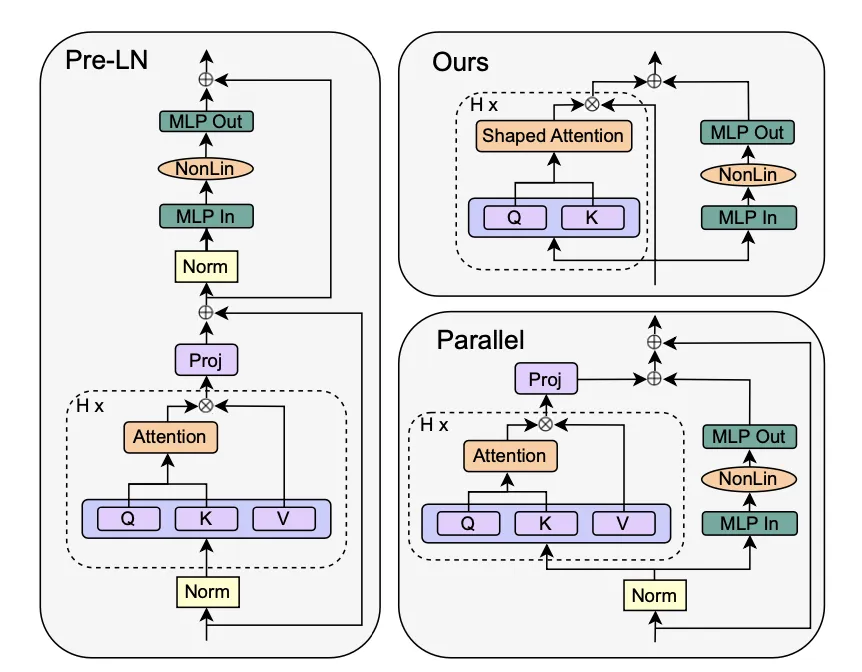

2.2 简化Transformer标准块
虽然本文的简化操作建立在信号传播理论基础之上,但是作者进行了大量的实验来进行验证,本文的所有实验均在CodeParrot数据集上进行了实验,该数据集的规模非常庞大,网络在不同设置下训练的泛化差距非常小,这使得作者可以更加专注于观察训练速度的差异。
2.2.1 移除注意力子块的跳跃连接



2.2.2 删除 MLP 子块的跳跃连接

2.2.3 移除归一化层
如果我们仔细观察Pre-LN基础块,会发现在每个子块中都会使用归一化层作为前处理或后处理,如果能去除归一化层,那我们就可以得到最简单的标准块。从信号传播初始化的角度来看,归一化操作可以隐含的削减上一子块中的权重,而这种效果也可以在跳跃连接过程通过明确指定来实现,或者使用Shaped Attention来代替。
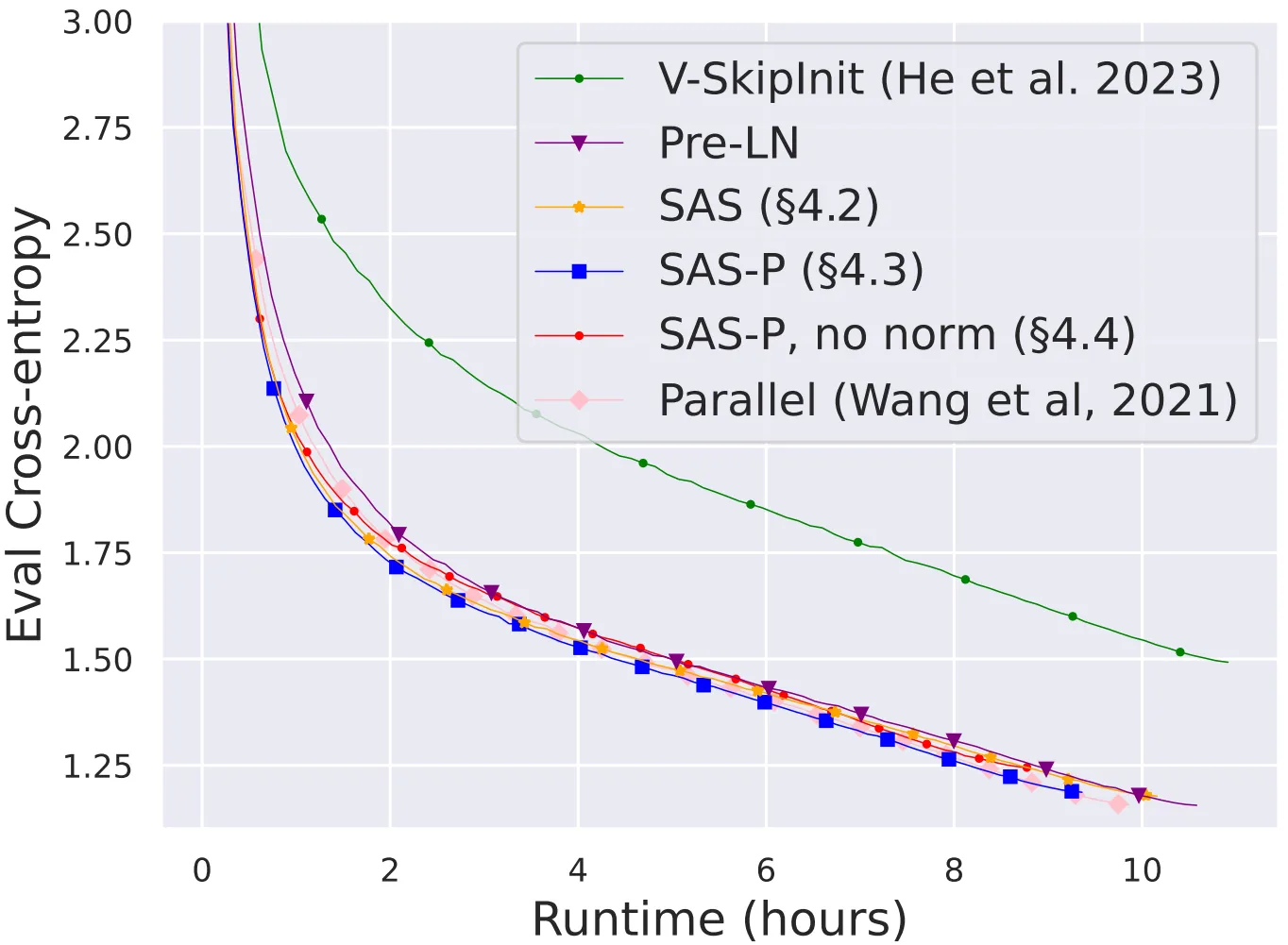
上图展示了本文移除归一化层(SAS系列)之后模型的训练速度对比,可以看到,在移除归一化层之后,最简单的SAS仍然能够达到Pre-LN块的训练速度。
03. 进一步的实验分析
3.1 深度缩放实验
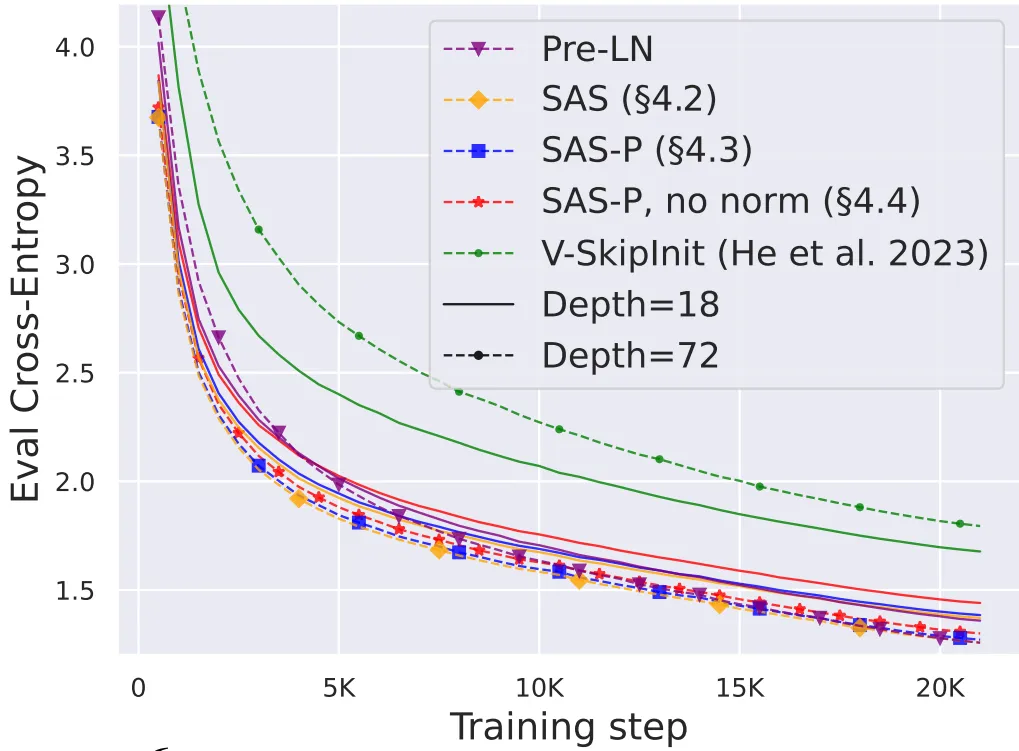
由于信号传播理论通常对网络深度参数非常敏感,一般来说,信号的退化通常出现在更深的网络中。因此,作者在下图中对transformer简化标准块在不同深度网络中的表现进行了实验,可以看出,当网络深度从18层拓展到72层时,简化标准块可以获得更低的训练loss,这表明本文提出的简化模型不仅能够训练得更快,而且能够利用更多深度提供的额外信息。
3.2 下游任务性能测试
为了衡量本文简化标准块在实际下游任务中的性能,作者选择了标准的双向纯编码器 BERT 模型作为基础模型,并采用了下游 GLUE 基准进行实验。同时,作者采用了更加经济的Crammed BERT 设置,即在有限的训练预算(在单个消费 GPU 上训练 24 小时)下,测试BERT模型的性能。
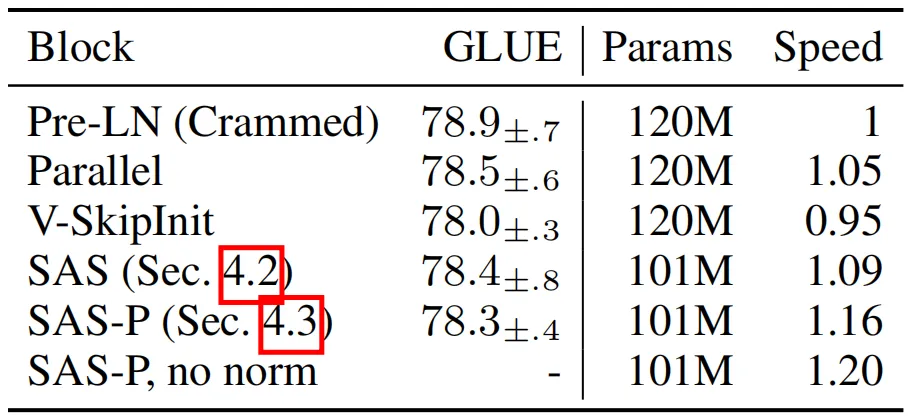
上表展示了本文方法的不同版本在masked语言建模任务上的参数数量和训练速度对比,可以发现,本文的SAS模型使用的参数减少了16%,SAS-P 和 SAS 的每次迭代速度分别比Pre-LN模块快 16% 和 9%。
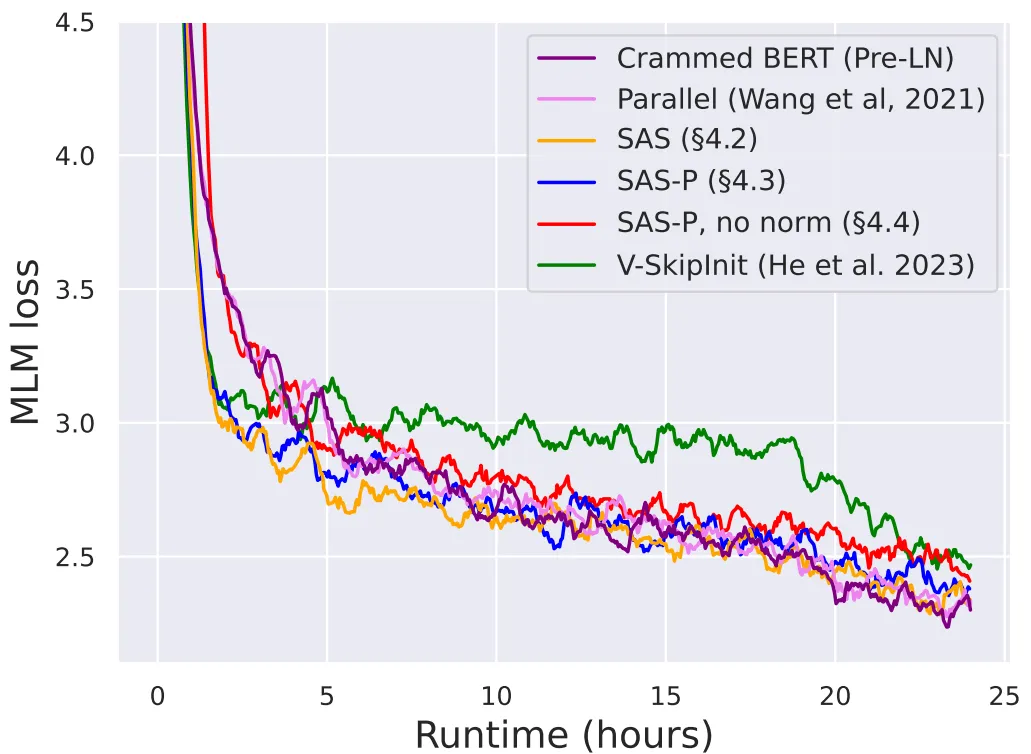
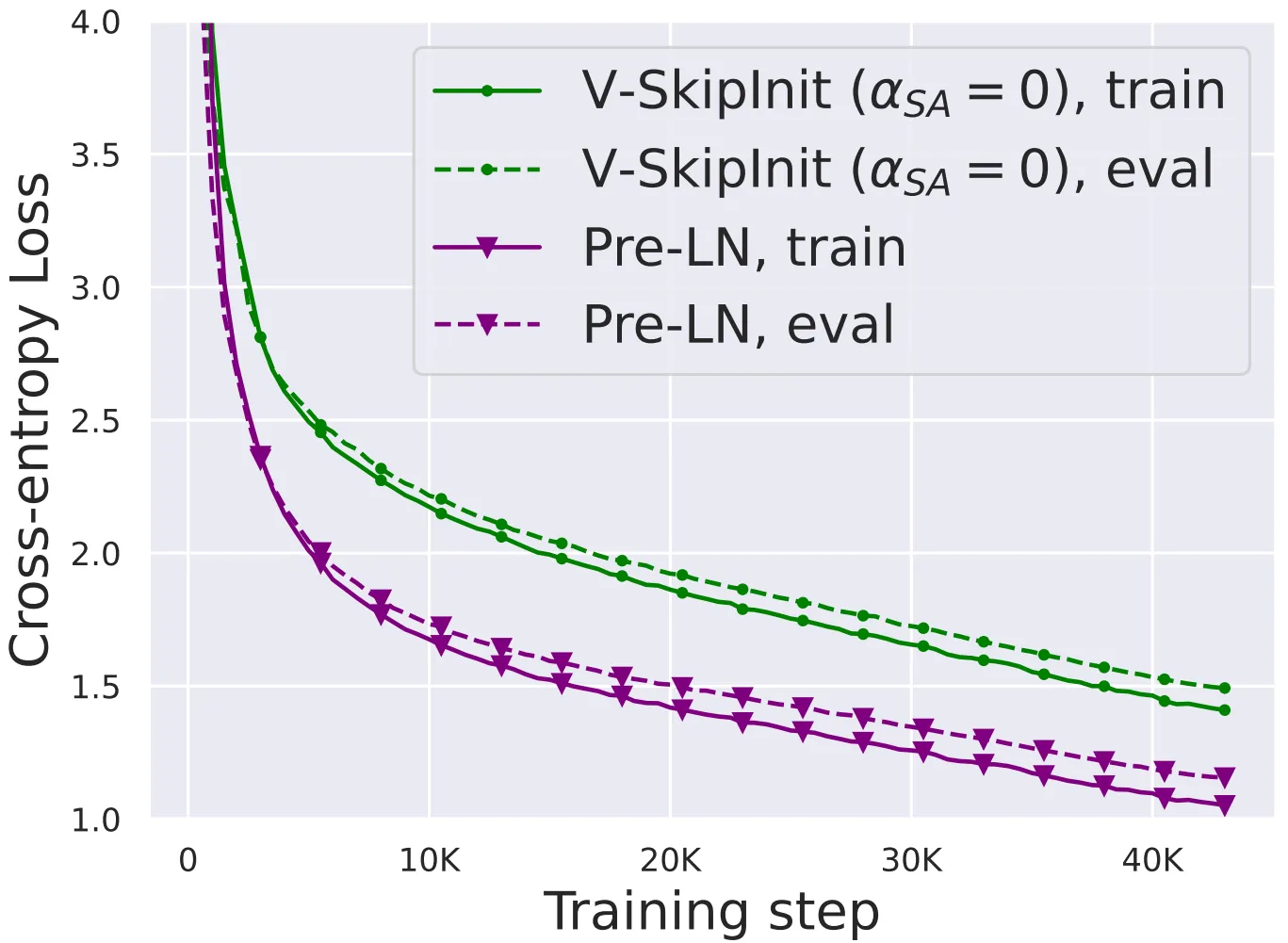
在下图中,作者展示了在 24 小时运行时间内,本文的简化区块(尤其是归一化区块)与 Pre-LN 基线的收敛速度对比,可以看到,本文的SAS系列模型的训练速度也达到了与Pre-LN相近的水平,另一方面,在不修改value和projection的情况下删除跳跃连接(即Value-SkipInit方法)会再次导致训练速度大幅下降。
04. 总结
本文针对Transformer架构中的基础块进行了一系列的理论分析和优化简化工作,但作者提到,尽管本文提出的简化块在很多架构和数据集上均能实现更高效的性能,但是目前所考虑的模型相对于几十亿和几百亿参数的transformer来说还是很小的。但是通过本文的深度缩放等实验,证明了简化块在更深层次网络中进行信息传递的潜力,这表明,通过进一步在信号传播理论层面探索基础块的运行机制,就可以将简化块扩展到更深层次和更多参数的LLMs中,将会大幅度降低参数占用和训练时间,降低大模型实际落地的成本。
参考
[1] Bobby He, James Martens, Guodong Zhang, Aleksandar Botev, Andrew Brock, Samuel L Smith, and Yee Whye Teh. Deep transformers without shortcuts: Modifying self-attention for faithful signal propagation. In The Eleventh International Conference on Learning Representations, 2023.
[2] Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
这篇关于大道至简?ETH研究团队提出简化版Transformer模型,综合效率明显提升的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





