本文主要是介绍大数据机器学习算法项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大数据机器学习算法项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现
技术栈:大数据爬虫/机器学习学习算法/数据分析与挖掘/大数据可视化/Django框架/Mysql数据库
本项目基于 Django框架开发的房屋可视化分析推荐系统。这个系统结合了大数据爬虫、机器学习算法、数据分析和数据可视化技术,旨在提供对房屋信息的全面分析和个性化推荐。系统的前端采用了HTML、CSS 和 JavaScript 技术,利用 Echarts实现数据可视化,并整合了百度地图的热力图功能,以更直观的方式展示数据。后端部分完全基于Django 框架开发,使用 MySQL作为主要数据库存储数据。推荐系统采用了协同过滤算法,其中包括基于用户行为和基于物品相似性的推荐算法,以提供用户个性化的房屋推荐。为了获取数据,系统使用了Python 中的 requests库实现爬虫功能,从网络中收集必要的数据。同时,为了提供地理信息服务,系统整合了百度地图API接口,利用其功能实现位置信息的展示和处理。该系统的核心目标在于为用户提供一套全面的房屋信息分析和个性化推荐服务,利用大数据技术和机器学习算法,为用户提供更精准、实用的房屋选择建议。通过整合前后端技术、数据分析、机器学习以及地图API,该系统为用户提供了一个交互性强、信息全面的房屋推荐平台,为房屋搜索和选择提供了更多的维度和可视化的支持。
一、 选题背景
随着社会的发展,大数据技术在各行各业的应用变得愈发广泛。其中,房地产领域作为人们生活不可或缺的一部分,也在大数据技术的推动下迎来了许多创新。为了更好地满足用户对房屋信息的需求,提供个性化的推荐服务成为房地产领域亟待解决的问题之一。基于Django/协同过滤算法的房可视化分析推荐系统选题旨在利用大数据技术和机器学习算法,基于Django框架构建一款房屋可视化分析推荐系统。该系统综合运用大数据爬虫、机器学习算法、数据分析和数据可视化等技术,以提供更深入、更个性化的房屋信息分析和推荐服务。协同过滤算法是推荐系统领域中一种重要的算法,通过分析用户行为和物品的相似性,为用户推荐可能感兴趣的物品。本项目采用协同过滤算法的两种主要形式:基于用户行为和基于物品相似性,以提高推荐的准确性和用户体验。技术栈涵盖了大数据爬虫、机器学习、数据分析和可视化,为系统提供了强大的数据处理和展示能力。前端采用HTML、CSS、JS 和 Echarts技术,实现了直观的数据可视化展示;百度地图的集成则使系统能够在地理空间上展示房屋信息,包括热力图的呈现。通过整合这些技术,该系统旨在为用户提供更全面、更个性化的房屋信息服务,帮助用户更轻松地进行房屋选择。同时,选题也对大数据技术在房地产领域的应用进行了深入研究,为相关领域的技术发展提供了有益的参考。
二、开发技术介绍
前端:html,css,js,Echats,百度地图
后端:Django
数据库:Mysql
推荐算法:协同过滤(1、基于用户行为 2、基于物品相似性)
爬虫:requests
地图API接口:百度地图API
三、数据库设计
all_public表
DROP TABLE IF EXISTS `all_public`;
CREATE TABLE `all_public` (`id` int NOT NULL AUTO_INCREMENT,`building_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`baidu_lat` float NULL DEFAULT NULL,`baidu_lng` float NULL DEFAULT NULL,`belong_region` int NULL DEFAULT NULL,`belong_public_type` int NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3459 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
loupan_public_num表
DROP TABLE IF EXISTS `loupan_public_num`;
CREATE TABLE `loupan_public_num` (`id` int NOT NULL AUTO_INCREMENT,`loupan_id` int NULL DEFAULT NULL,`youeryuan_num` int NULL DEFAULT NULL,`xiaoxue_num` int NULL DEFAULT NULL,`zhongxue_num` int NULL DEFAULT NULL,`daxue_num` int NULL DEFAULT NULL,`sanjiayiyuan_num` int NULL DEFAULT NULL,`yijiyiliao` int NULL DEFAULT NULL,`erjiyiliao` int NULL DEFAULT NULL,`huochezhan_num` int NULL DEFAULT NULL,`qichezhan_num` int NULL DEFAULT NULL,`gaotiezhan_num` int NULL DEFAULT NULL,`gongjiaozhan_num` int NULL DEFAULT NULL,`shichang_num` int NULL DEFAULT NULL,`shangchangchaoshi_num` int NULL DEFAULT NULL,`canyin_num` int NULL DEFAULT NULL,`gongyuan_num` int NULL DEFAULT NULL,`jiaoyu_count` int NULL DEFAULT NULL,`yiliao_count` int NULL DEFAULT NULL,`jiaotong_count` int NULL DEFAULT NULL,`yule_count` int NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 919 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
这里因为表数据太多,就不一一列举。
四、系统实现
1.启动Mysql数据库
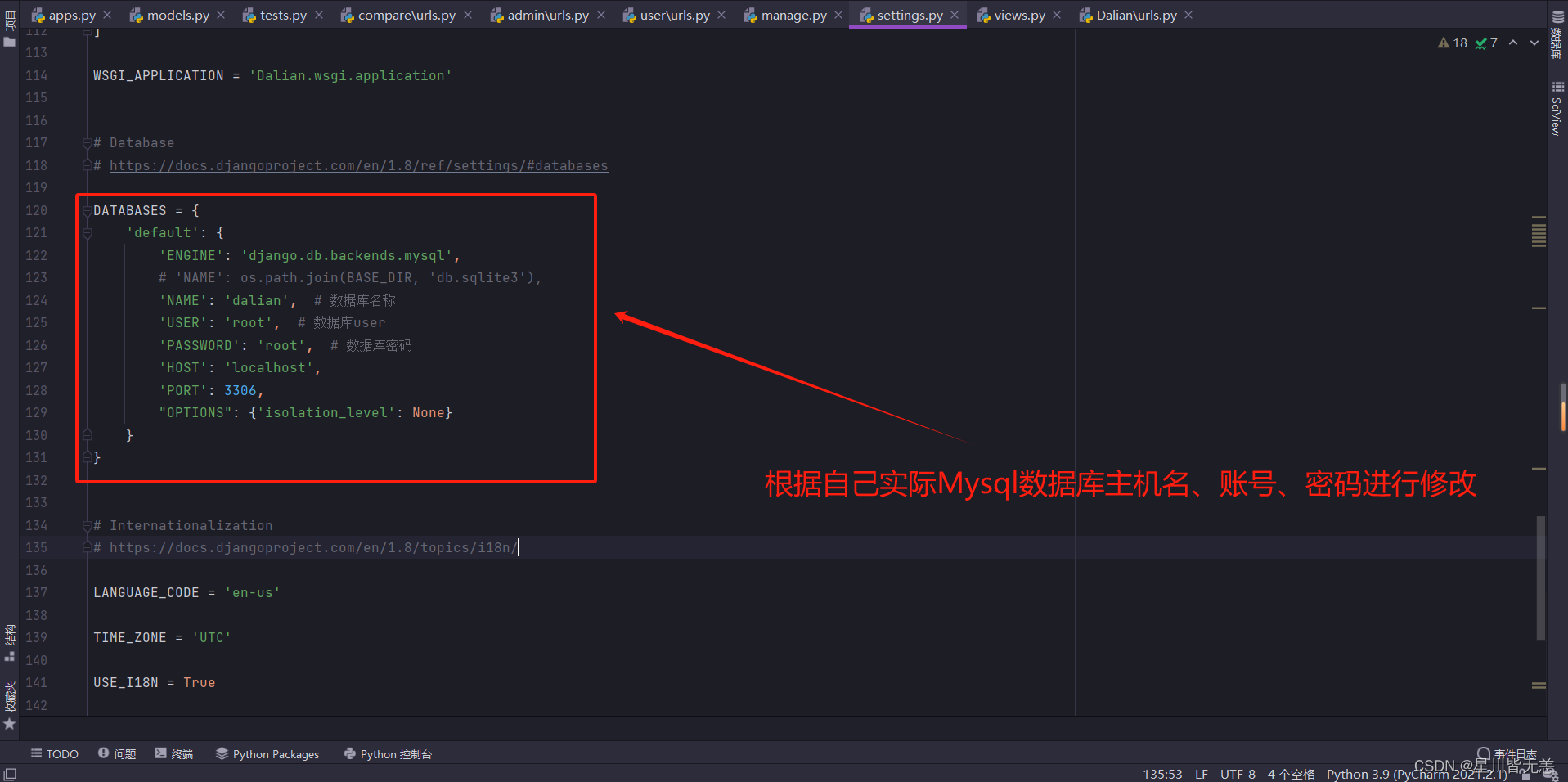
启动数据库,我这里的是localhost,账号密码根据自己实际情况进行连接就行了。

修改数据库连接,连的哪个数据库就用哪个主机名、账号和密码。
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql',# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),'NAME': 'dalian', # 数据库名称'USER': 'root', # 数据库user'PASSWORD': 'root', # 数据库密码'HOST': 'localhost','PORT': 3306,"OPTIONS": {'isolation_level': None}}
}
跨域资源共享(CORS)的设置
#跨域增加忽略
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_ALLOW_ALL = True
CORS_ORIGIN_WHITELIST = ('http://127.0.0.1:8000','http://localhost:8000',
)
CORS的设置通常用于Web开发中处理跨域请求的安全机制。我们一个一个来看:
-
CORS_ALLOW_CREDENTIALS = True:
-
这个设置表示是否允许在跨域请求中使用凭证(例如,在XMLHttpRequest或Fetch请求中包含身份验证信息,如cookies和HTTP认证)。
-
如果设置为True,表示允许使用凭证,否则禁止。
-
-
CORS_ORIGIN_ALLOW_ALL = True:
-
这个设置表示是否允许所有的域进行跨域请求。
-
如果设置为True,表示允许所有域,不管是哪个域发起的请求都会被接受。这是一种开放的跨域策略。
-
-
CORS_ORIGIN_WHITELIST:
-
这个设置是一个元组,包含了允许的特定域的列表。
-
在前两个设置都为False的情况下,这个列表会用于明确指定哪些域是被允许的跨域请求来源。
-
在这个例子中,允许的域包括
http://127.0.0.1:8000和http://localhost:8000。
-
通过这些设置我们允许所有域进行跨域请求,并允许使用凭证。同时,通过CORS_ORIGIN_WHITELIST指定了一些特定的域,确保只有这些域可以进行跨域请求。
允许的主机设置这里我设置的都是本地主机,如果要远程连接其它主机,可以自己修改:
ALLOWED_HOSTS = ['127.0.0.1', 'localhost']

其它配置都比较简单就不一一细说了,有问题可以问我。配置好我们的解释器,下载所需要的包直接启动就可以,我这里的Django是3.2.20版本:
在pycharm中打开terminal 终端输入下面命令启动:
python manage.py runserver

启动成功,端口8000:

五、项目展示
用户登录页面
用户账号密码信息注册
用户登录,普通用户注册,普通用户登录
也可以管理员注册登录
管理员登录:
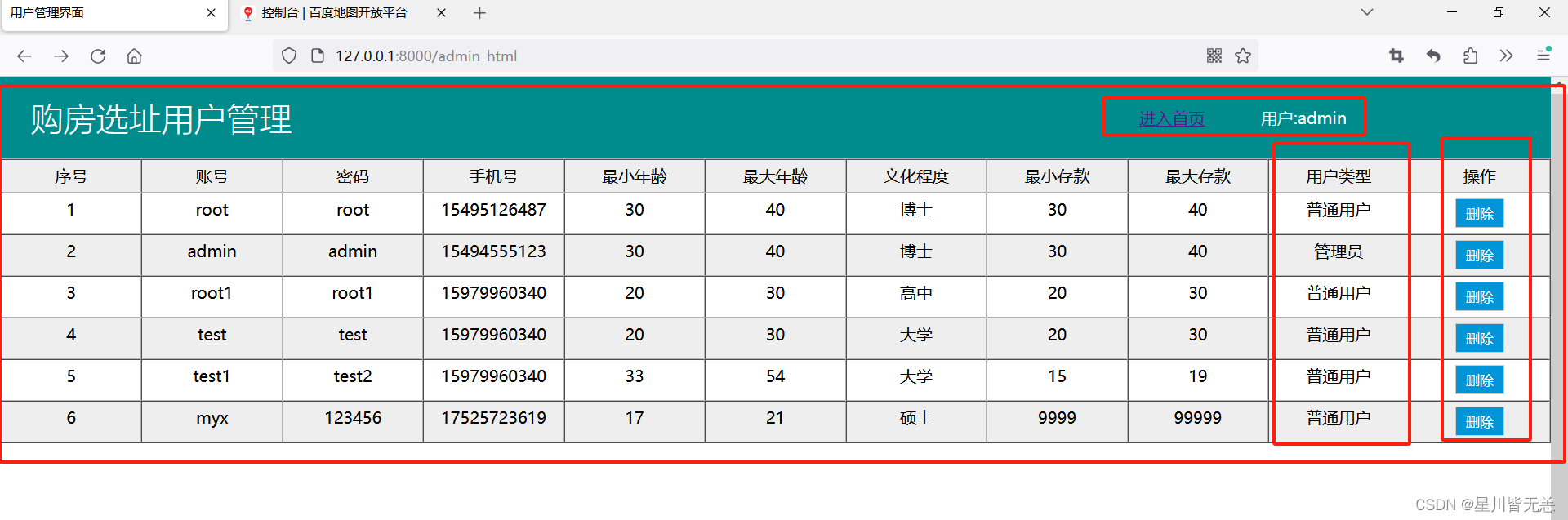
具体实现效果
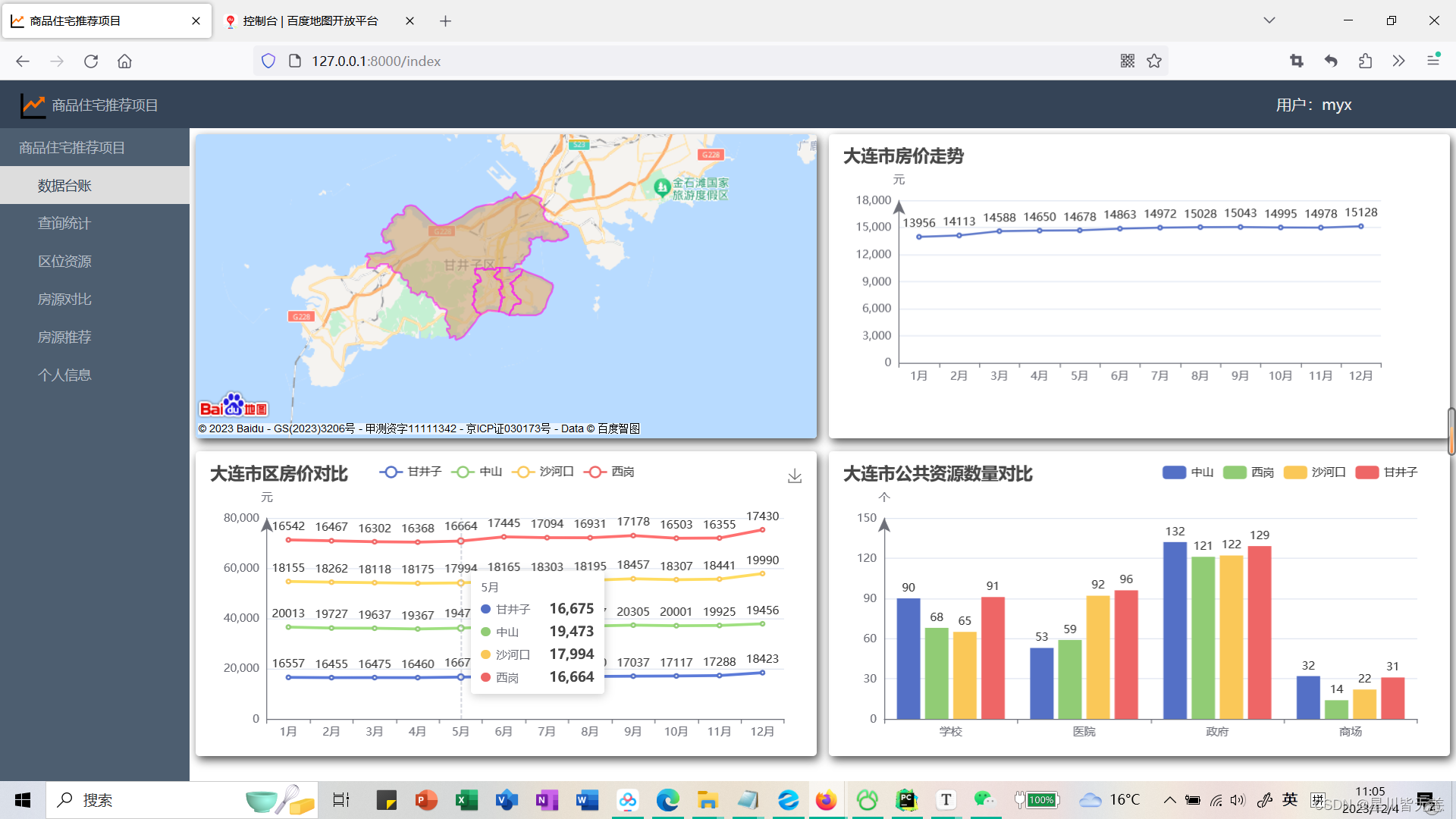
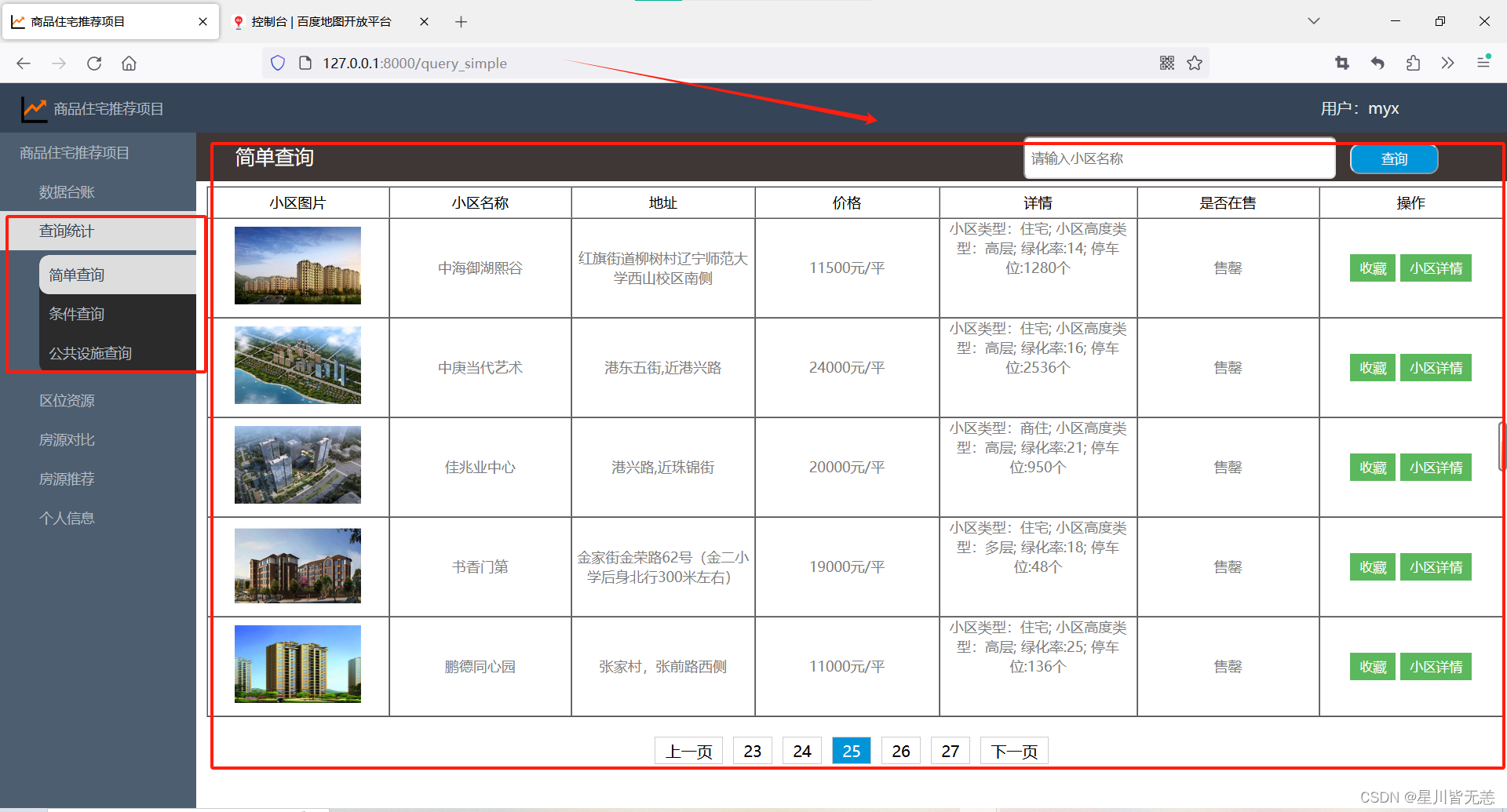
指定查询
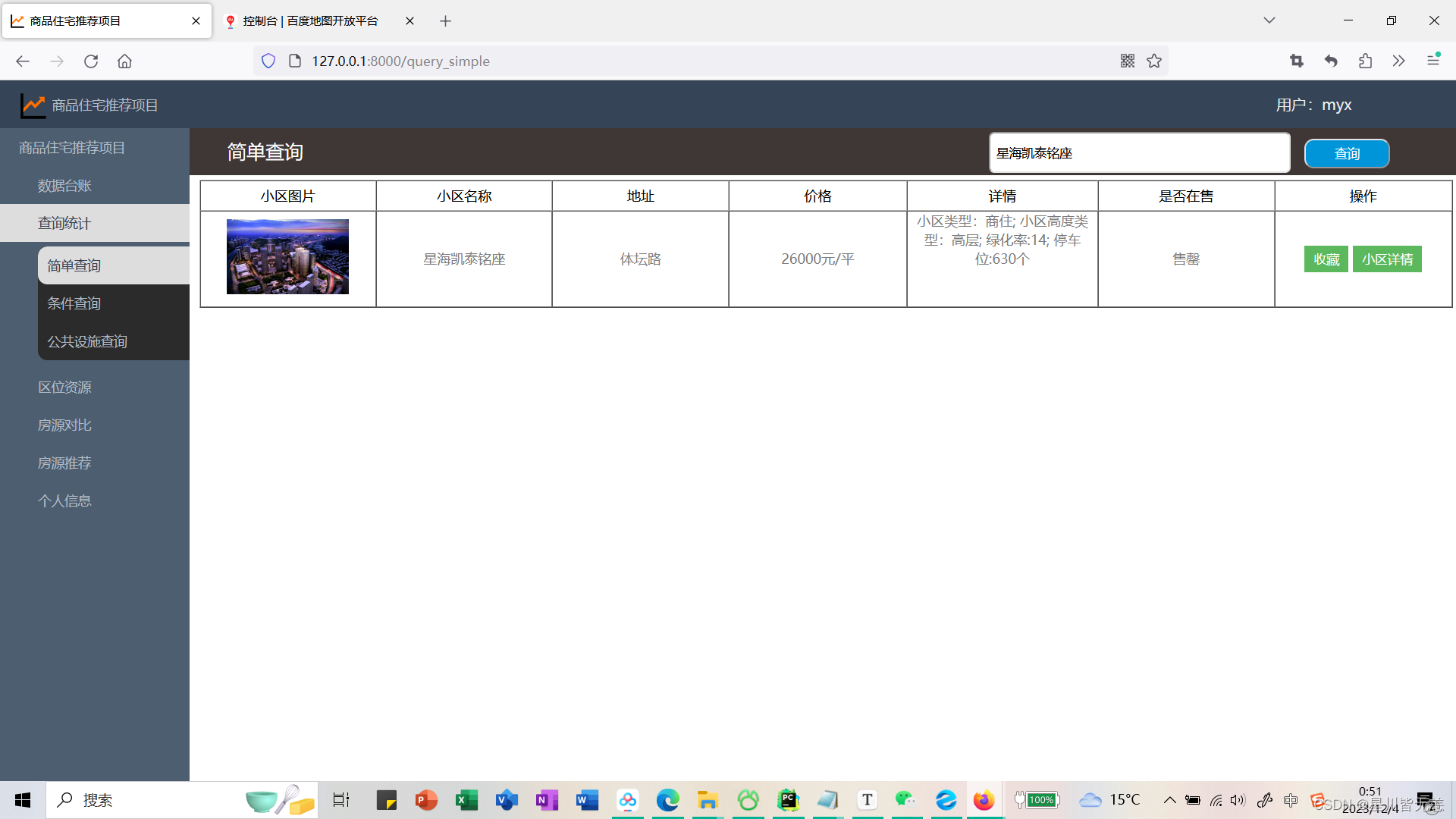
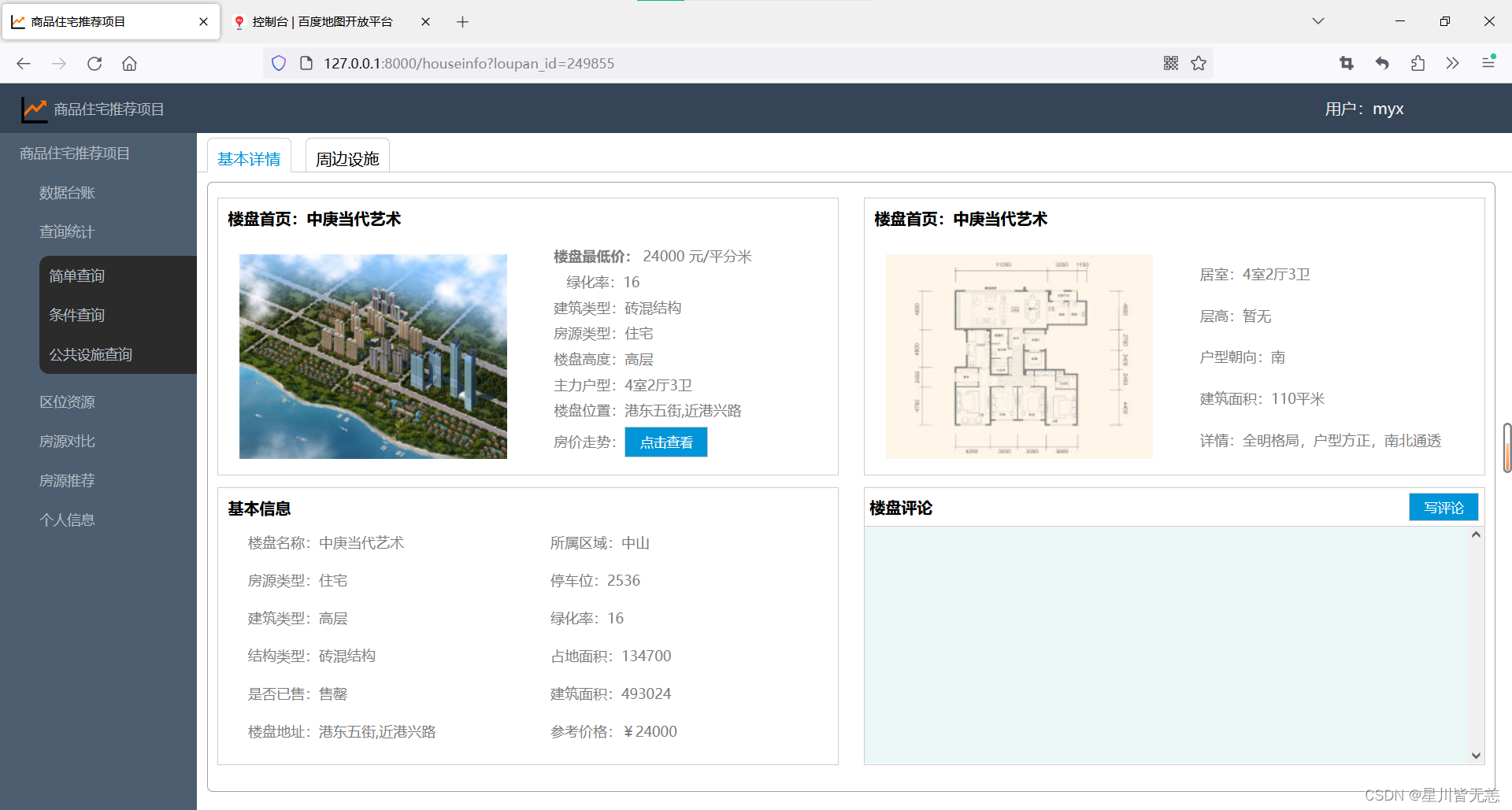
小区详情:
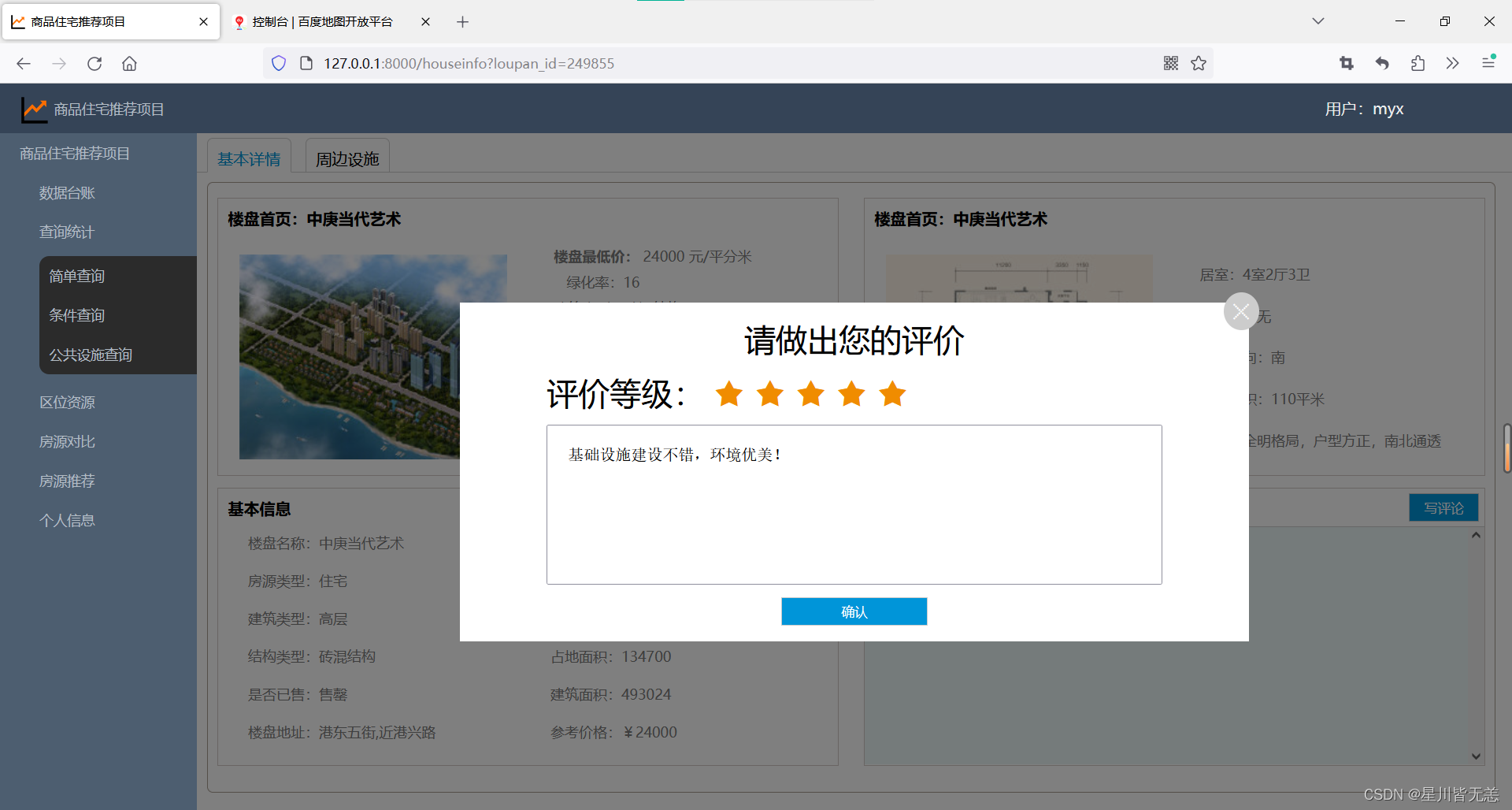
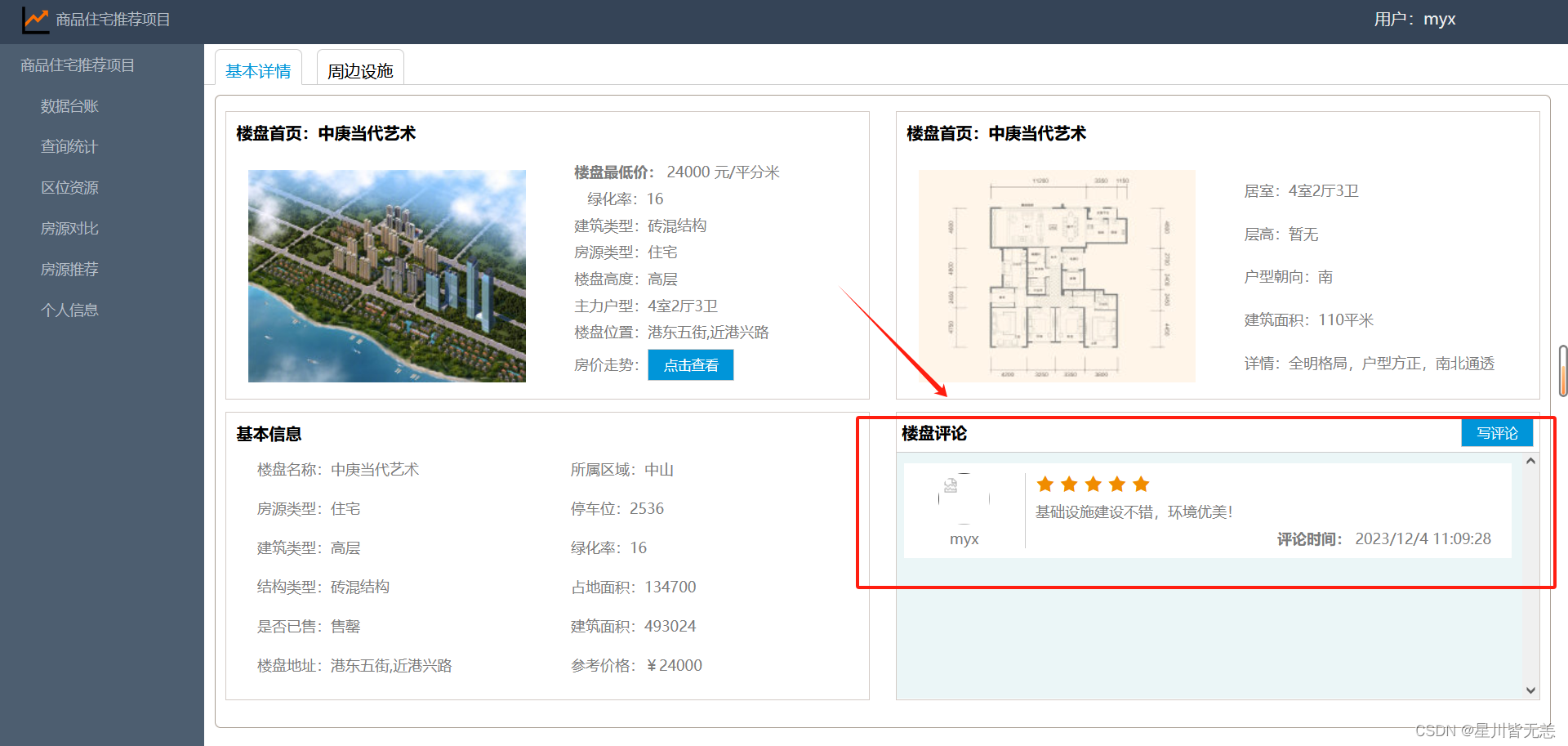
发表评论
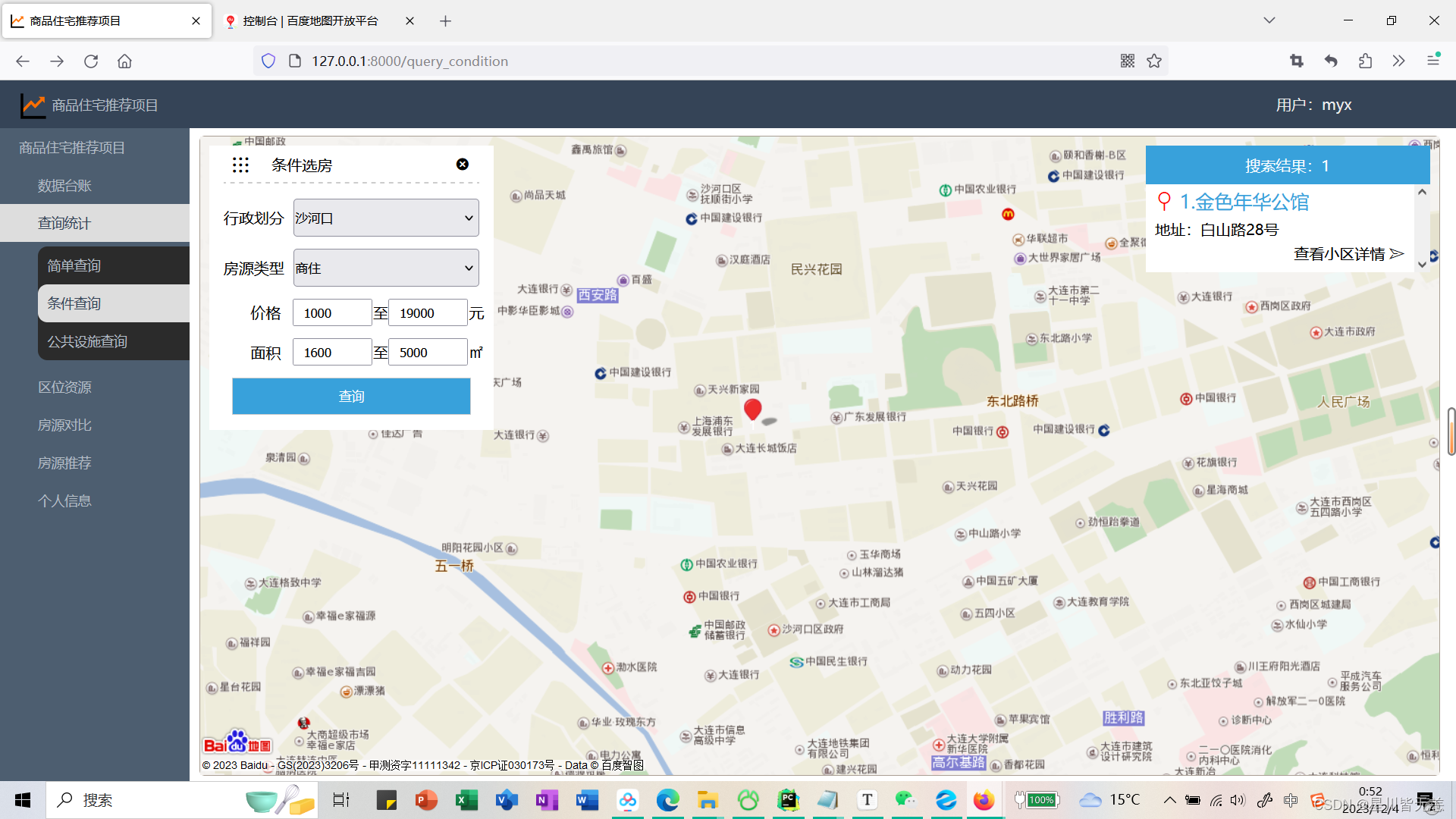
条件查询
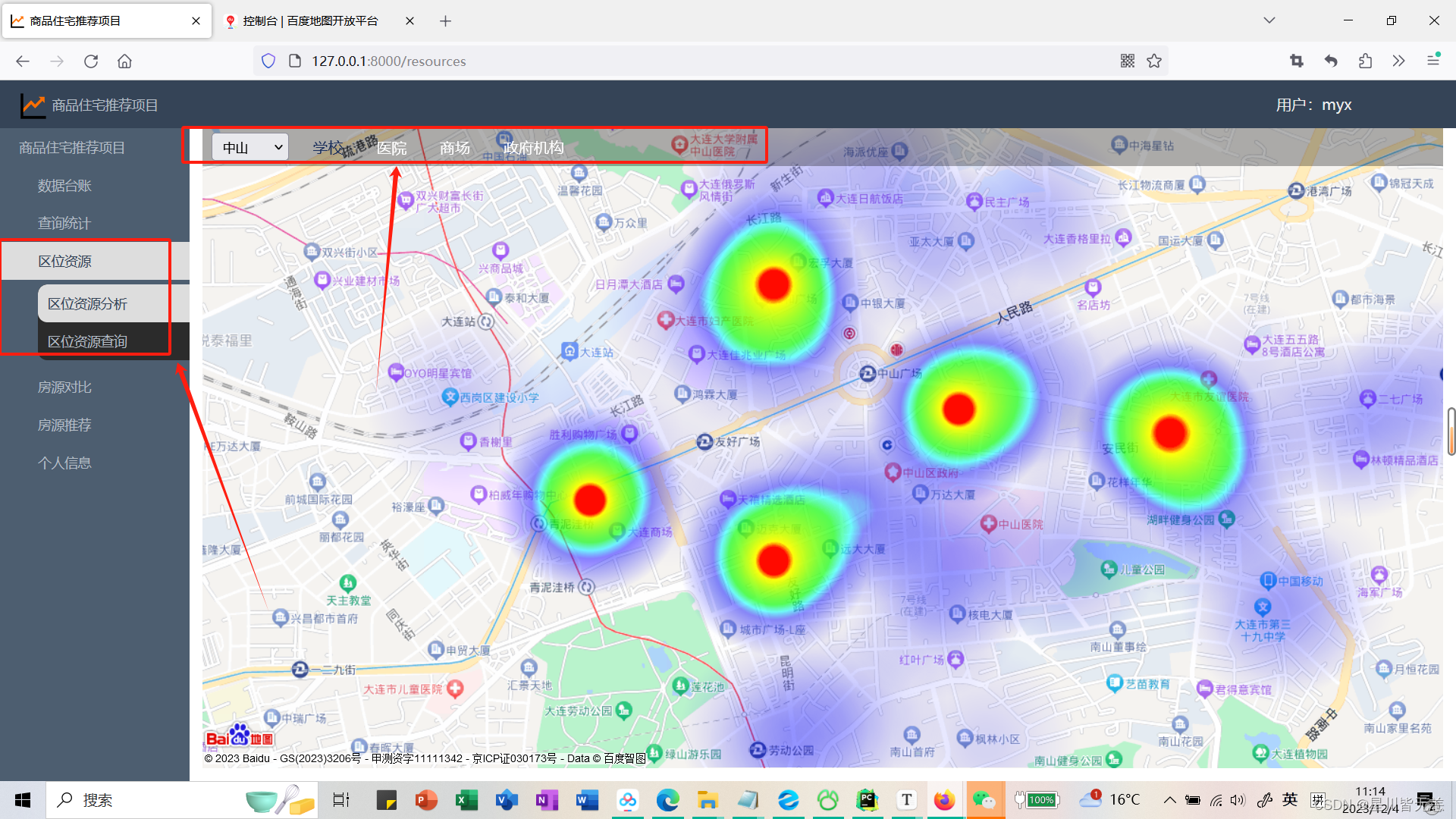
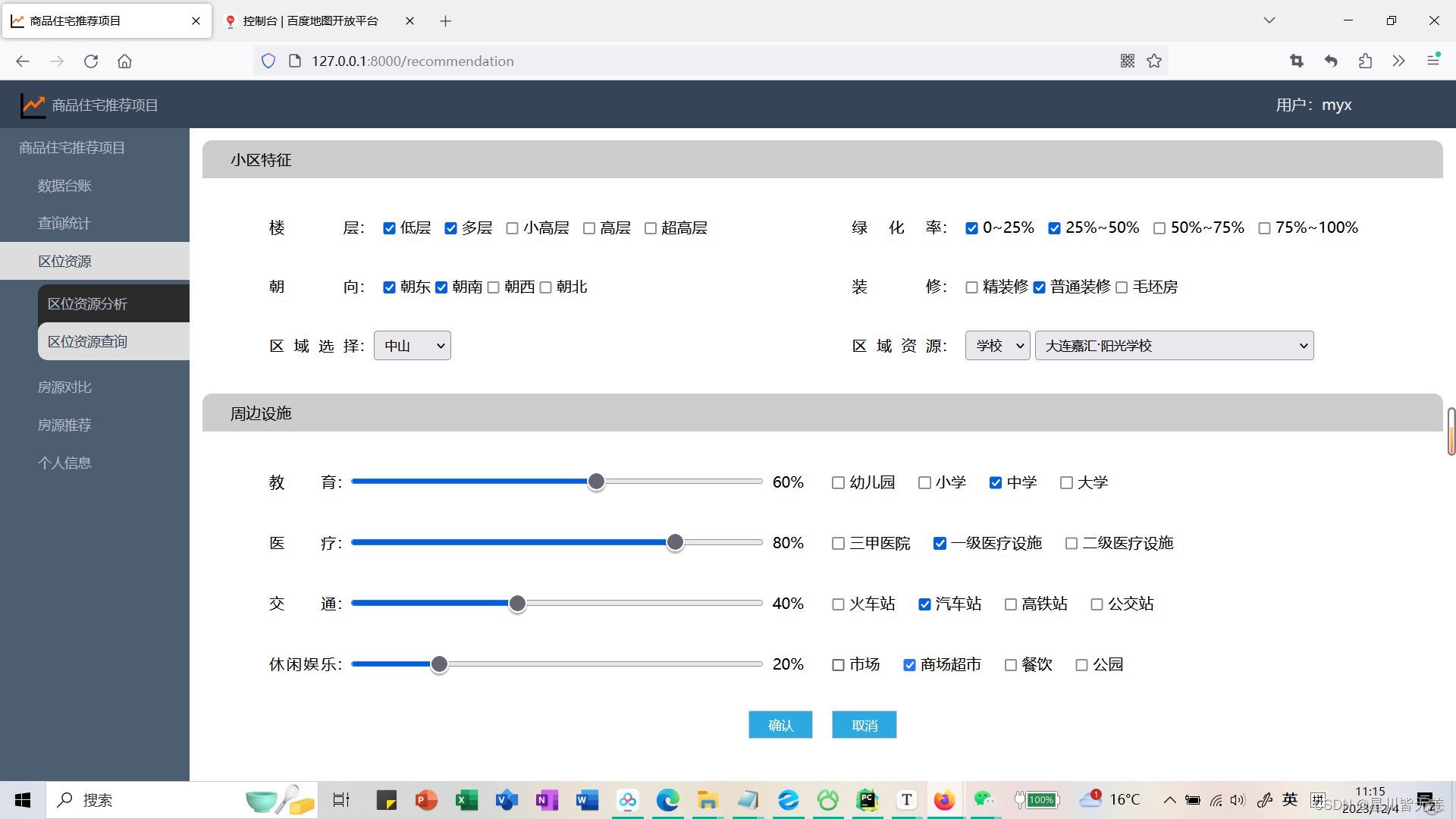
公共设施查询

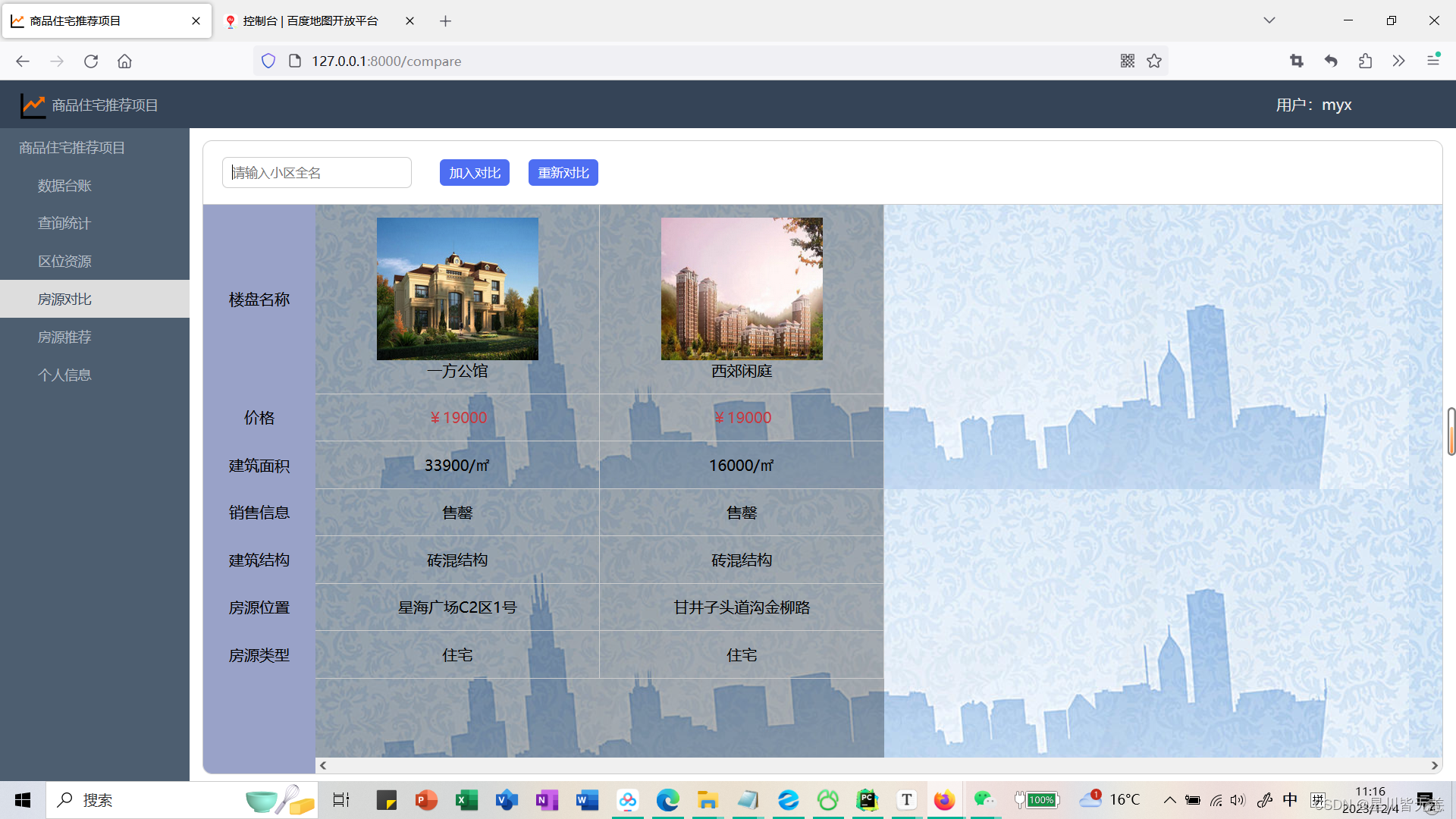
房源对比分析
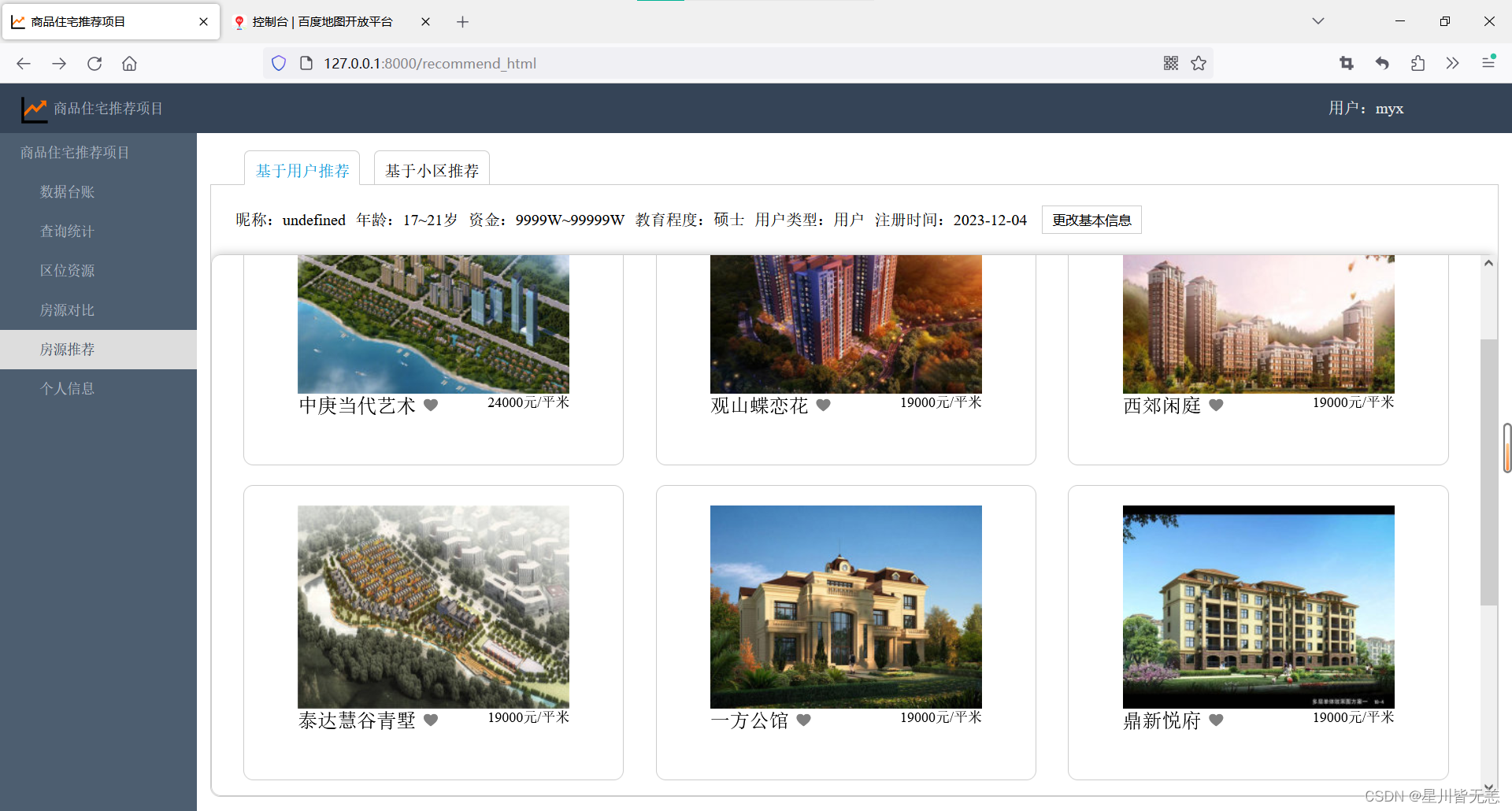
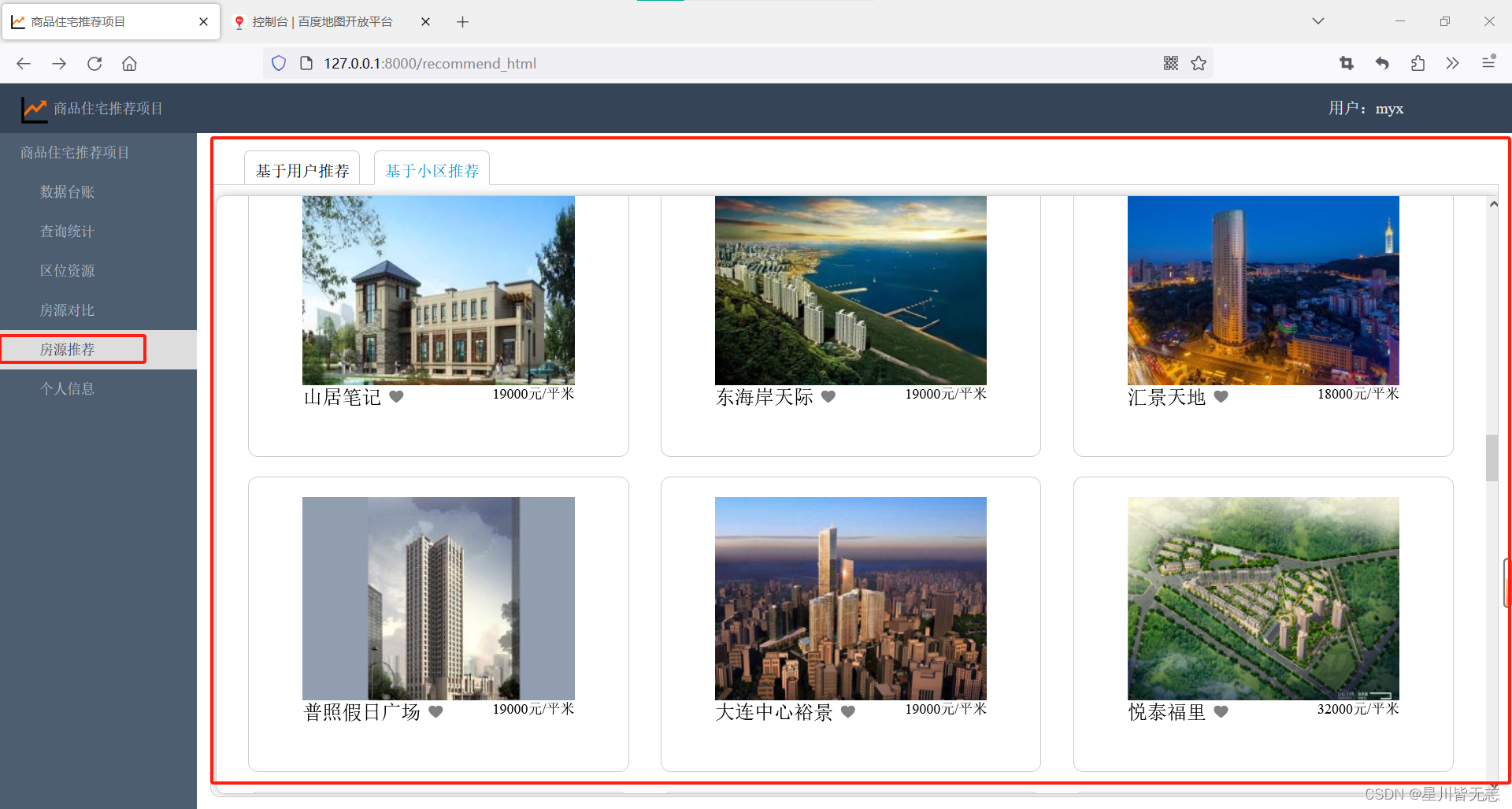
协调算法推荐(基于用户、基于小区推荐)
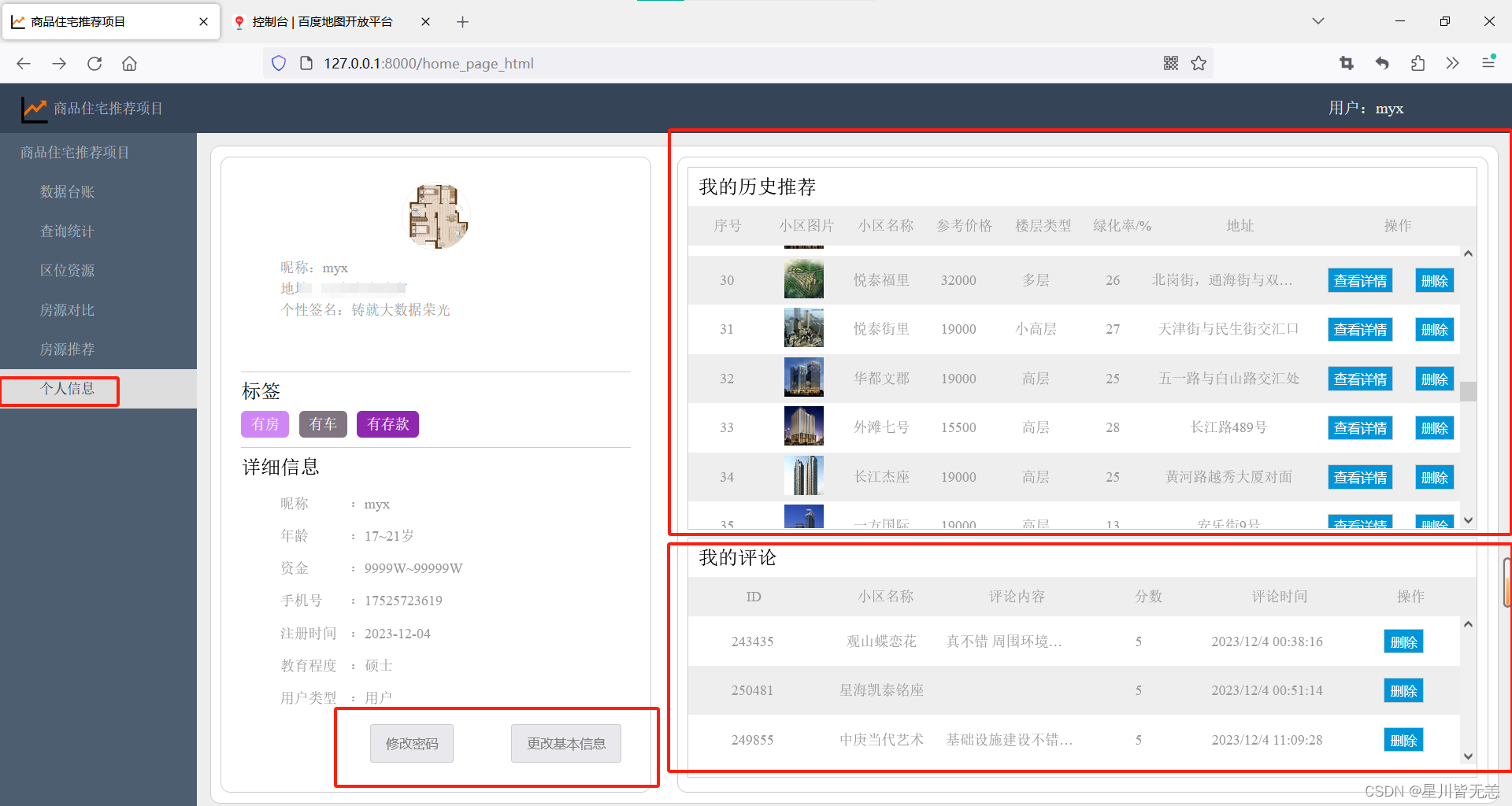
个人信息
六、结语
经过对一系列测试结果的有效分析,本平台开发系统符合用户的要求和需求。所有的基本功能齐全,可视化效果很好,服务运行稳定,操作起来简单方便,测试系统性能、整体设计和代码逻辑都很Nice!
各位有兴趣的小伙伴 可以私信我要详细的项目开发文档、每个项目脚本运行部署视频讲解、完整项目源码和其它相关资料。

最近在进行机器学习算法方面的系统研究,后面有时间和精力也会分享更多关于大数据领域方面的优质内容,喜欢的小伙伴可以点赞关注收藏,有需要的都可以私信我!感谢各位的喜欢与支持!
这篇关于大数据机器学习算法项目——基于Django/协同过滤算法的房源可视化分析推荐系统的设计与实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






