本文主要是介绍The Accelerator Wall: Limits of Chip Specialization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
The Accelerator Wall: Limits of Chip Specialization
-
摘要:
- 加速器墙:芯片上可用晶体管数量的停滞将限制加速器的设计优化空间,导致专有化硬件回报的减少,最终将会遇到加速器墙
- 论文工作:探讨了在未来加速器和定制化芯片的限制将会有哪些
- 论文使用数千个芯片的数据表(datasheet)构建的模型工具,论文描述了当前加速器如何依赖于CMOS缩放(scaling)
- 论文识别了在专有化芯片中使用的关键概念,并且通过探索研究案例,了解了专有化在不同的应用程序和芯片平台(GPU,FPGAs,ASICs)中是如何发展的,并且据此构建了模型,以预测未来可以利用专有化芯片获得什么,不能获得什么
- 用途:通过对芯片专有化收益和技术边界的定量分析,帮助研究人员理解加速器的局限性和开发克服这些局限性的方法
-
介绍
- 专有化芯片普遍存在的三个动机
- 摩尔定律接近尾声,Dennard的缩放定律的结束,芯片的功耗预算逐渐在被限制(power budget limitation)
- 在电池容量有限的移动设备和仓库规模的数据中心中,应用程序的计算需求不断增长(growing computation demand)
- 计算密集型程序中出现了高重用率的计算末世,例如深度学习中的矩阵向量乘法或者挖矿程序中的加密哈希(high reuse rate computation-patterns)
- 通过牺牲灵活性和针对特定的应用领域,专有芯片在相同功耗约束的情况下,可以提供更高的性能
- 论文的关注重点:应用芯片专门化所带来的限制
- 加速器墙:用于专有化单个应用程序的优化空间是有限的,将计算问题映射到固定的芯片资源的方法是有限的,因此在给定领域和预算下,可获得的芯片的收益也是有限的。但是随着CMOS缩放定律接近尾声,芯片的晶体管预算也会被限制,优化最终带来的收益将会减少,加速器将达到接近最优计算和硬件协同优化的极限
- 论文贡献:
- 论文利用上千个芯片的CMOS缩放公式和数据表构建了一个独立于应用的芯片CMOS潜力模型,从而解耦CMOS技术和专有化芯片对加速器收益的贡献
- 论文提出了专有化芯片收益的度量标准(CSR,chip specialization return),并且研究了流行的应用程序和不同的加速器平台,以量化CSR是如何随着加速器收益的提高而变化的
- 论文确定了常见的芯片专有化技术和这些技术的理论限制
- 论文构建了一个基于Aladdin和CMOS缩放公式的建模框架,在一系列加速器基准测试上梳理了专有化技术和CMOS工艺缩放带来的好处
- 论文对评估的应用进行了帕累托最优的投影研究,并预测了晶体管缩放结束时加速器潜力的极限
- 专有化芯片普遍存在的三个动机
-
CMOS缩放(scaling)和芯片专有化收益的相互作用(interplay)
-
定量芯片专有化的收益(quantifying):CSR(Chip specialization return)。
-
芯片的收益(gain)时通过在目标芯片上执行目标计算来测量的,它依赖于未固定的层,算法(Alg),框架(Fwk),平台(Plt),工程(Eng),物理(Phy)

-
由于芯片结构的复杂性,无法测量单个原件对整体收益的贡献情况,因此将CSR定义为芯片物理特性带来的收益和所有收益之间的比值
C R S ( A l g , F w k , P l t , E n g ) = G a i n ( A l g , F w k , P l t , E n g , P h y ) G a i n ( P h y ) CRS(Alg,Fwk,Plt,Eng)=\frac{Gain(Alg,Fwk,Plt,Eng,Phy)}{Gain(Phy)} CRS(Alg,Fwk,Plt,Eng)=Gain(Phy)Gain(Alg,Fwk,Plt,Eng,Phy) -
在目标计算领域,对于两个芯片的实际收益(reported gain)分别为GainA和GainB,可以根据下面的等式分类成两个部分:专有化驱动的收益,CMOS驱动的收益

-
-
-
CMOS的潜能模型:应用无关的模型,基于芯片的物理特性,评估芯片的CMOS驱动能力
-
模型介绍:使用了1612个CPU和1001GPU的数据建立的模型。模型的输入包括:
- CMOS节点(N)
- 芯片面积(A)或者晶体管数量(TC)
- 芯片工作频率(iv)
- 芯片的热设计功耗(TDP)(当处理器达到最大负荷时,所释放出的热量)
-
设备缩放模型:使用最新的缩放公式和最近IRDS报告中5nm的CMOS的推算,建立了一个模型,用于模拟晶体管密度,频率,能量和功率的变化
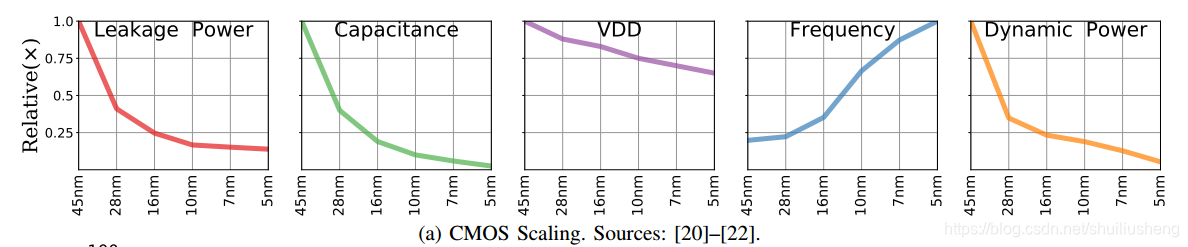
-
晶体管预算模型:
- 由于某些专有化的芯片的晶体管数量并没有公布出来,因此论文使用MSE进行回归分析,自变量为芯片晶体管密度因子D,该因子和芯片面积A成正比,和技术节点的平方成反比
T C ( D ) = 4.99.1 0 9 ∗ D 0.877 D = A r e a / ( C M O S N o d e 2 ) [ m m 2 / n m 2 ] TC(D)=4.99.10^9*D^{0.877}\\D=Area/(CMOS\ Node^2)[mm^2/nm^2] TC(D)=4.99.109∗D0.877D=Area/(CMOS Node2)[mm2/nm2]
- 在Dennard Scaling定律结束之后,由于功耗密度的限制,并不是所有的晶体管都可以同时工作,因此论文进一步结合TDP,CMOS和频率参数,用同样的方法,对芯片上可激活的晶体管数量进行建模
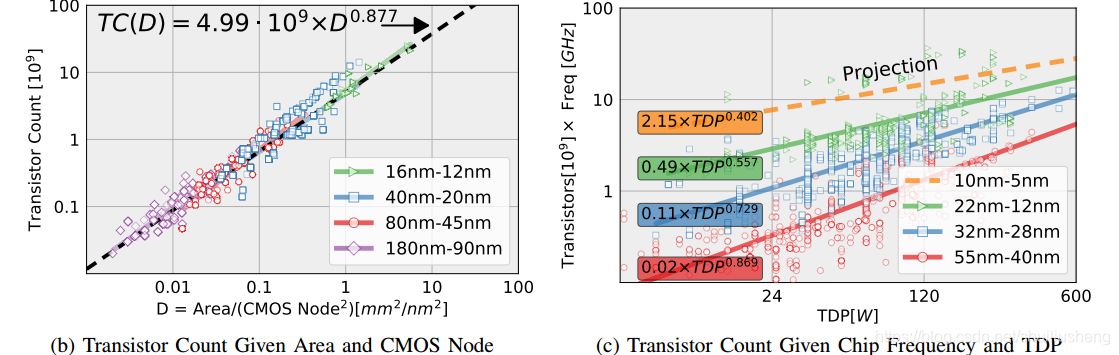
-
芯片的收益模型:结合前两个模型构建得到。因为研究的目标程序具有高度的并行性,因此将芯片吞吐量作为目标性能

-
-
经验上的专有化芯片回报
- 论文研究的四个热门的加速器领域:
- 视频解码的ASIC芯片
- 图形渲染的GPU芯片
- 卷积神经网络的FPGA
- 比特币挖矿的CPU,GPU,FPGA和ASIC
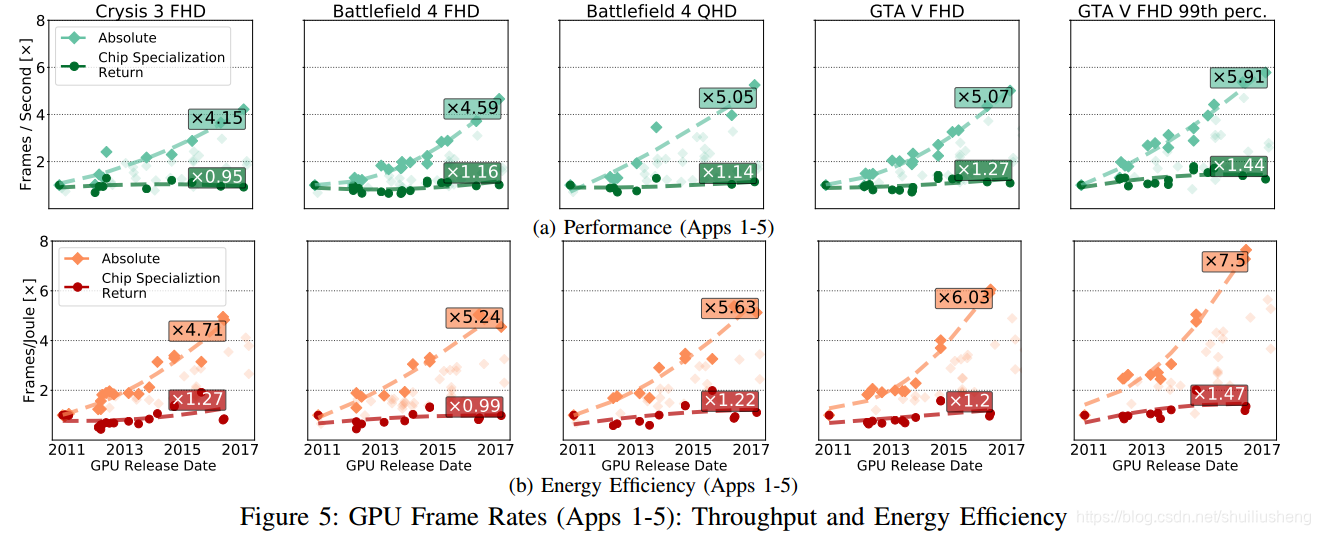
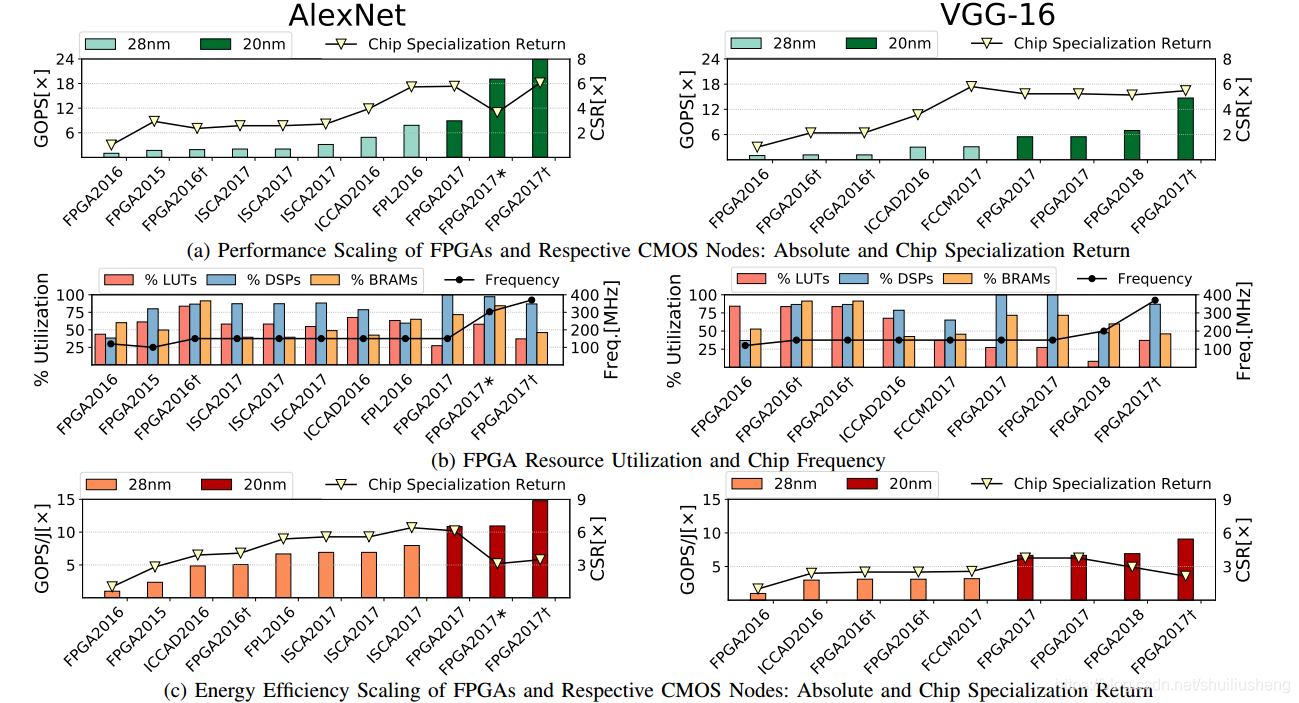
- 论文研究的四个热门的加速器领域:
-
芯片专有化的一些观念(Concepts)
-
芯片专有化过程相关的三个处理组件:memory,communication,computation
-
芯片专有化的三个概念/观念:简化(simplification),划分(partitioning),异构(heterogeneity)
- 简化:降低层次结构和数据通路复杂性的额能力,并以更低的成本获得具有类似功能的更简单的结构
- 划分:典型的被加速的应用程序通常具有高度的并行性,因此可以使用复制的通路形成并发的硬件设计来利用这种并行性
- 异构:尽管只有一个工作负载,但是也会有不同的需求。工作负载可能具有不同计算强度的阶段,或者重用许多不同的模式,因此可以通过使计算路径多样化,并裁剪每条路径以支持特定的功能来进一步减少每次计算的消耗
-
Nowatzki论文中对这些观念的划分:并发,通信,数据重用,计算和协作
-
芯片专有化中三个观念中的目标极限
-
存储简化:以访问性能为代价减少存储开销。此时存储开销会受限于工作集的最大大小(只有一层的存储结构),时间复杂度也会跟最终的大小相关
-
存储异构:存储的异构性表示为由模块和/或接口布局形成的层次结构,以支持特定于问题的访问模式。通过反映数据流图中节点间所有计算关系的分层层次结构实现最大性能
-
通信简化:以增加延迟为代价,减少导线数量,从而简化通信结构。极限是连接所有节点的最小生成树
-
通信异构:由于DFG拓扑结构反映了特定于问题的通信模式,因此通信异构性由DFG边显示定义
-
计算简化:DFG中每个节点的操作被简化为一组空间复杂度为1(固定)的门电路,时间复杂度在简化之后和输入变量个数,变量的位宽以及节点个数相关
-
计算异构:融合节点形成特定于问题的超级节点。极限是单个节点充当查找表,存储所有输入对应的计算结果
-
存储/通信/计算划分:划分会受限于DFG中的并行级别,DFG并行性级别是按照并发处理的变量的最大数量排序的
-
V代表计算中需要的值的集合,包括输入Vin,输出Vout;D代表DFG的深度;E表示边的集合;WSs代表计算阶段正在工作的集合(computation stage working set is the set of variables computed in computation stage s)

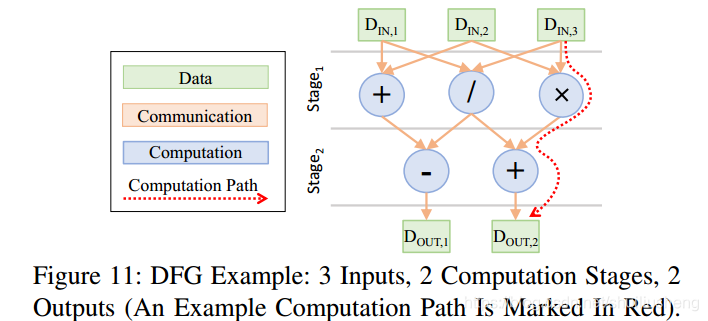
-
-
-
加速器墙
-
加速器墙:在CMOS技术停止技术进步之后,性能和能效最优的加速器芯片会被制造出来
-
论文采用了两个模型评估了若个类型的加速器的帕累托曲线边界投影:
-
线性模型
P r o j e c t i o n L i n e a r ( P h y s i c a l ) = α ∗ P h y s i c a l + β Projection_{Linear}(Physical)=\alpha*Physical+\beta ProjectionLinear(Physical)=α∗Physical+β -
对数模型
P r o j e c t i o n L o g ( P h y s i c a l ) = α ∗ l o g ( P h y s i c a l ) + β Projection_{Log}(Physical)=\alpha*log(Physical)+\beta ProjectionLog(Physical)=α∗log(Physical)+β
-
-
论文使用这两种模型确定了每种加速器芯片的性能和能效随着物理性能和能效之间的帕累托边界曲线,给出了在这些加速器使用5nm工艺的CMOS技术时,这些加速器的最优能效和性能
-
结论:当一个领域成熟起来,并且支配算法被固定下来,此时在一个固定的芯片预算下,芯片专有化将会更加的难以获取收益
-
这篇关于The Accelerator Wall: Limits of Chip Specialization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






