本文主要是介绍分类预测 | GASF-CNN格拉姆角场-卷积神经网络的数据分类预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分类预测 | GASF-CNN格拉姆角场-卷积神经网络的数据分类预测
目录
- 分类预测 | GASF-CNN格拉姆角场-卷积神经网络的数据分类预测
- 分类效果
- 基本描述
- 模型描述
- 程序设计
- 参考资料
分类效果




基本描述
1.GASF-CNN格拉姆角场-卷积神经网络的数据分类预测(完整源码和数据)
2.自带数据,多输入,单输出,多分类。程序可出分类效果图,混淆矩阵图。
3.直接替换数据即可使用,保证程序可正常运行。运行环境MATLAB2022及以上。
4.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。
模型描述
GASF-CNN(Gramian Angular Summation Field Convolutional Neural Network)是一种基于格拉姆角场和卷积神经网络的数据分类预测方法。
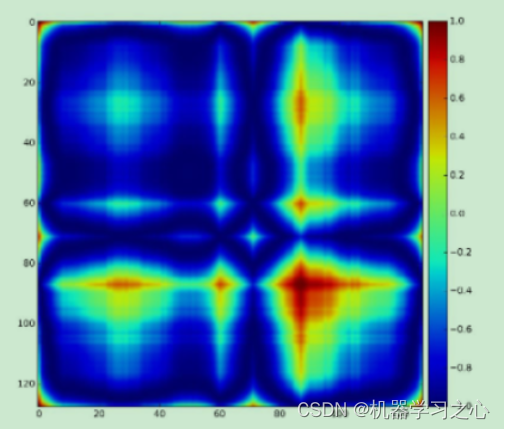
GASF是一种将时间序列数据转换为图像表示的方法。它基于格拉姆角和和求和运算,将时间序列数据转换为二维矩阵。这个转换过程捕捉了时间序列数据的周期性和相对关系,从而提供了更丰富的特征表示。
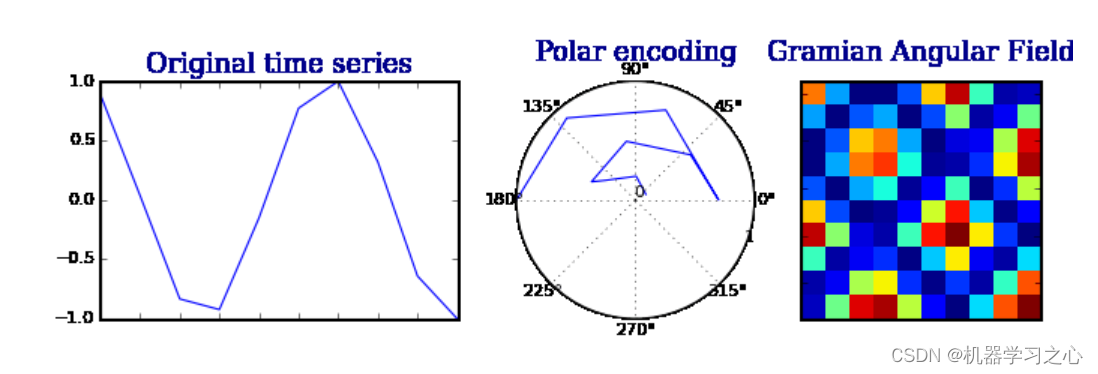
卷积神经网络(CNN)是一种常用的深度学习模型,专门用于处理具有网格结构的数据,如图像。CNN通过在输入数据上应用一系列的卷积操作和非线性激活函数,自动学习输入数据中的特征。在图像分类任务中,CNN已经取得了很大的成功。
GASF-CNN结合了GASF和CNN的优势,用于数据分类预测。其基本步骤如下:
输入数据准备:将时间序列数据转换为GASF表示。这涉及将时间序列数据划分为小的时间窗口,并使用GASF算法将每个时间窗口转换为GASF图像。
卷积神经网络构建:建立一个CNN模型,用于从GASF图像中学习特征并进行数据分类。CNN模型通常由卷积层、池化层、全连接层等组成,可以根据具体任务进行设计。
模型训练:使用标记的训练数据对GASF-CNN模型进行训练。通过将GASF图像作为输入,将标签作为目标输出,使用反向传播算法和优化技术(如随机梯度下降)来调整模型参数,以最小化预测错误。
模型预测:使用训练好的GASF-CNN模型对新的未标记数据进行分类预测。将未标记数据转换为GASF图像,并通过CNN模型获取预测结果。
GASF-CNN方法适用于各种类型的时间序列数据分类任务,如股票价格预测、心电图分类、运动识别等。它通过结合GASF的优势和CNN的特征学习能力,提供了一种强大的数据分类预测方法。
程序设计
- 完整程序和数据私信博主回复GASF-CNN格拉姆角场-卷积神经网络的数据分类预测。
convolution2dLayer([3, 1], 16) % 卷积核大小 3*1 生成16张特征图batchNormalizationLayer % 批归一化层reluLayer % Relu激活层convolution2dLayer([3, 1], 32) % 卷积核大小 3*1 生成32张特征图batchNormalizationLayer % 批归一化层reluLayer % Relu激活层fullyConnectedLayer(1) % 全连接层regressionLayer]; % 回归层
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%% 参数设置
options = trainingOptions('adam', ... % Adam 梯度下降算法'MaxEpochs', 300, ... % 最大训练次数 300'InitialLearnRate', 1e-2, ... % 初始学习率为0.01'LearnRateSchedule', 'piecewise', ... % 学习率下降'LearnRateDropFactor', 0.1, ... % 学习率下降因子 0.1'LearnRateDropPeriod', 200, ... % 经过200次训练后 学习率为 0.01 * 0.1'Shuffle', 'every-epoch', ... % 每次训练打乱数据集'Plots', 'training-progress', ... % 画出曲线'Verbose', false);
————————————————
版权声明:本文为CSDN博主「机器学习之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kjm13182345320/article/details/127179100参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229
这篇关于分类预测 | GASF-CNN格拉姆角场-卷积神经网络的数据分类预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






