本文主要是介绍推荐系统粗排召回相关性优化的最新进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:cmathx
原文链接:https://zhuanlan.zhihu.com/p/195548025
编辑:深度传送门
看到三篇干货满满&&很实用的相关性优化paper,先上论文大餐。

https://arxiv.org/pdf/2002.03932.pdf
Google的paper(How to pretrain?),主要是讲怎么样更好的设计pretrain任务,用于问答任务。

https://arxiv.org/pdf/2004.12832.pdf
Stanford的paper(How to late fusion?),主要是讲怎么样更好的让query和doc进行late fusion,用于召回侧&&粗排?相比双塔dssm模型,recall更优;相比交互式dssm模型,效率上更优。此外,召回侧可以使用faiss超大规模检索,用于工业界的搜索/推荐等系统。

https://arxiv.org/pdf/1905.01969.pdf
Facebook的paper(How to late fusion?),和上个paper的目的一致,怎么样进行late fusion,提高检索的效率,提高召回率。
PS:文中的截图均来自于上面三篇paper。。。
零、相关性之DSSM回顾
1)双塔DSSM模型
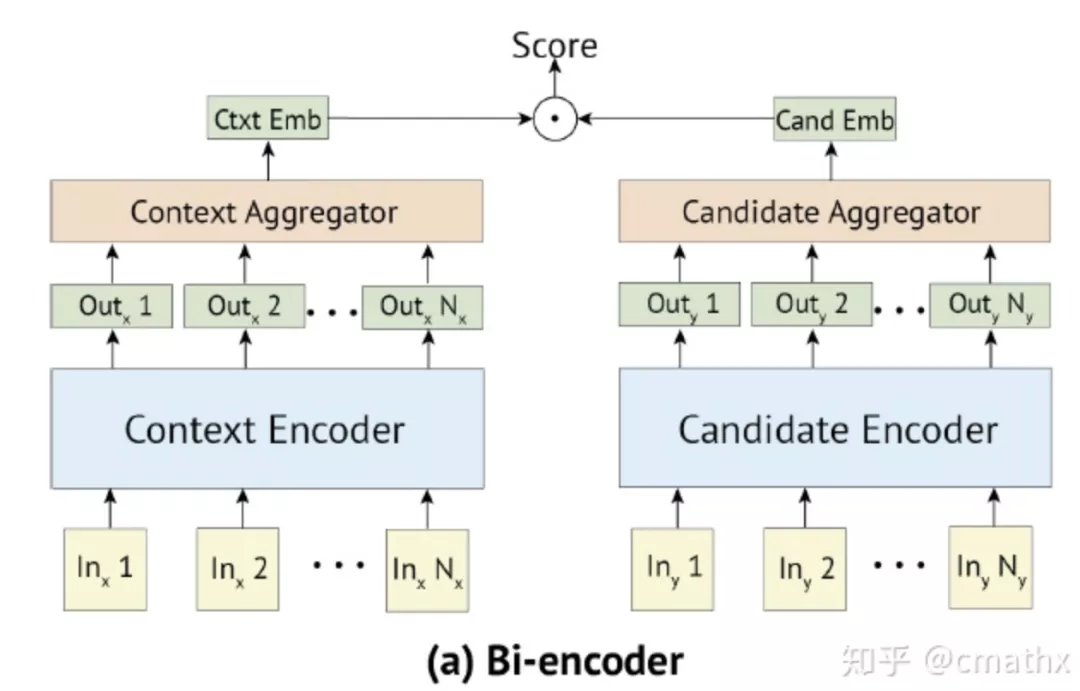
双塔DSSM模型
query(context)和doc(candidate)独立进行建模,各自得到embedding,最后进行相似度度量(L2/cosine等)。在搜索/推荐或者其他相似性检索领域,召回侧可以使用faiss(乘积量化)或者nsg(基于图检索)等方式,对超大规模的doc embedding进行索引。具体使用的时候,由query embedding来召回topk的结果用于后续的排序侧。此外,在粗排的过程中,也可以基于这种方式快速计算相似度,作为特征之一。
2)交互DSSM模型
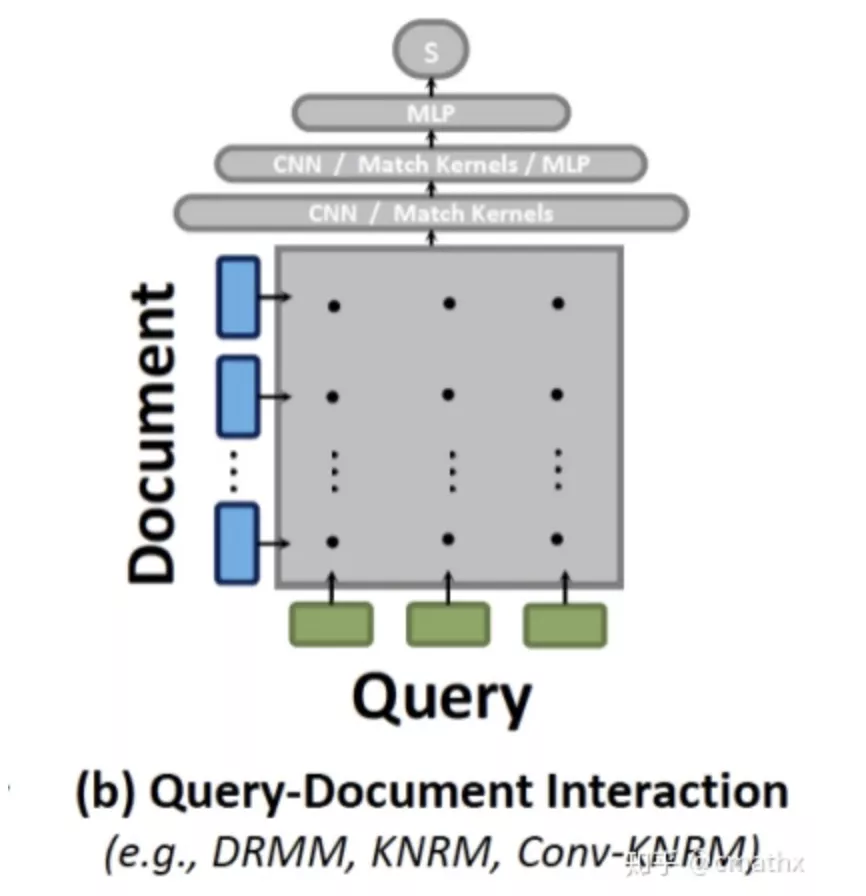
交互式DSSM模型-i
交互式DSSM模型-ii
交互的DSSM模型,一种方式是刚开始计算出query和doc在term级别的相似度矩阵,在此基础上走神经网络,类似:KNRM、Conv-KNRM等;另一种方式和bert预训练类似,输入部分query和doc以[sep]分隔,走encoder模块建模,以隐藏层[cls]作为最终的embedding。这种方式,相比双塔DSSM模型计算相似度得分更为精确,但是计算的运算量相对较高,一般用在精排部分。
一、How to Pretrain
本文的要点是提出了ICT、BFS、WLP三种构造预训练数据的方式,用于提升预训练模型的建模能力。在问答的任务上,取得了显著的效果效果提升,实验部分测试集包括:SQuAD、Natural Qustions。
1)基本概念
下面表述下ICT、BFS、WLP三个概念到底是啥?结合paper里面的两张截图来解释下。
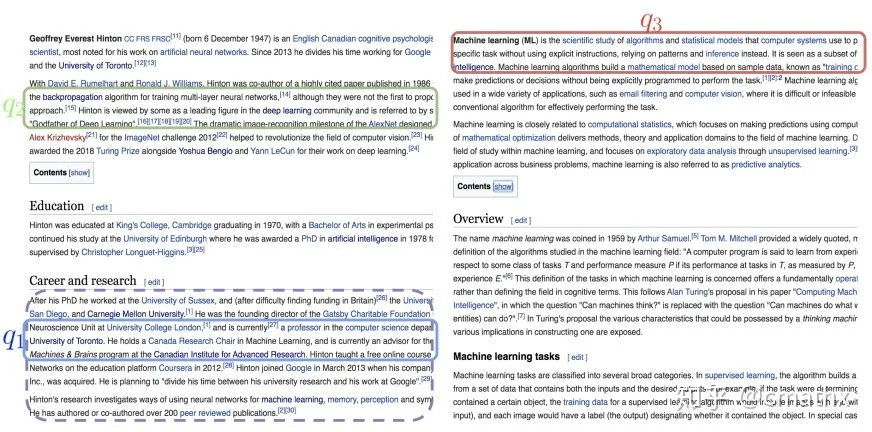

i)ICT:query为维基文章段落里面的某个句子;doc为该段落的其余句子;
ii)BFS:query为维基文章第一段随机选取的句子;doc为同一页面随机选取的一个段落;
iii)WLP:query为维基文章第一段随机选取的句子;doc为另外一个页面(query对应的句子,包含的超链接跳转到的页面)的某个段落;
2)实验结论
最后,贴两个主要的实验结果,来得到一些主要的实验结论。
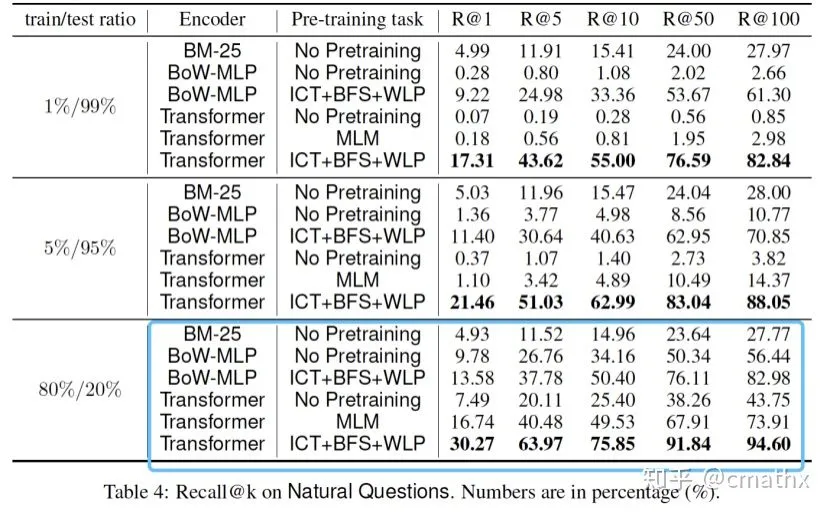
BoW-MLP:基于bag-of-words的方式,走MLP网络进行建模。可以看到,结合ICT+BFS+WLP三种预训练方式,相比MLM方式实验结果显著提升。
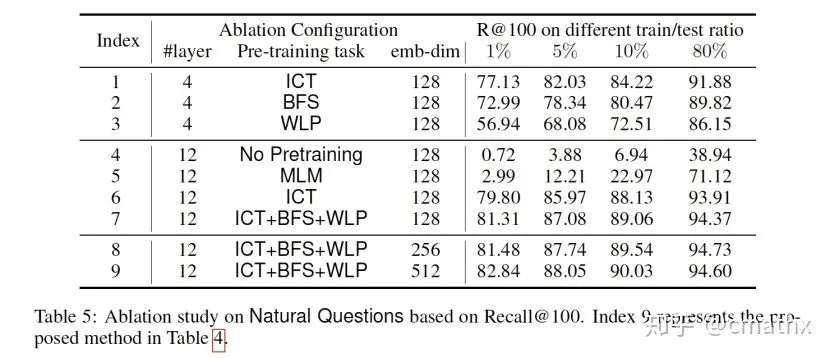
三种预训练方式中,ICT效果比其他两者要好。此外,提高最终embedding的维度,实验结果会好一点。
二、ColBERT
本文的核心思想,在于怎么样让query和doc的embedding进行late fusion,相比单纯直接进行相似性度量(L2/cosine),召回率得到提高。此外,在粗排上计算速度得到显著提升,召回侧可以引入faiss进行超大规模检索。
1)建模&&检索

query建模:构造出统一的输入长度,不够的补[mask],采用bert进行建模,使用cnn压缩隐藏层表征长度,最终得到Eq个embedding表征。doc建模:filter表示过滤标点符号等一些不相关的表征,最终得到Ed个embedding表征。
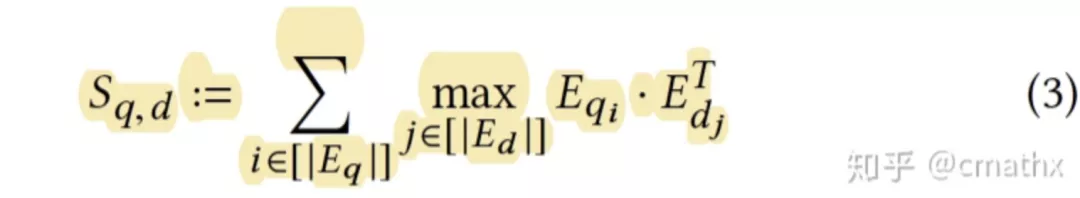
在粗排的计算中,query的建模结果以一个2D矩阵存储,doc的建模结果以一个3D矩阵存储,max本质是进行max-pooling操作,最终再叠加一个矩阵求和操作。在召回侧的计算中,分成两个阶段:filter和refine,filter:max这部分的操作,对每个q_i用faiss检索出topk’的结果,得到Nq*k’个doc;refine:在Nq*k’个doc结果中,采用和粗排一样的计算方式,得到最优的k个结果,作为最终的检索结果。
2)实验结论
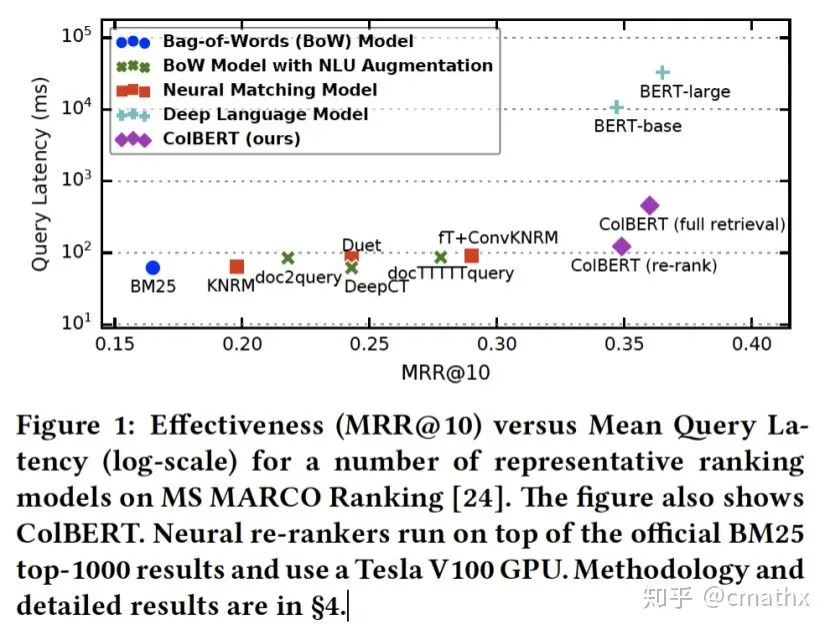
直接上一个简单的硬核实验结论,ColBERT的效果比ConvKNRM明显要好,此外检索的速度比BERT-base模型要快几个数量级。
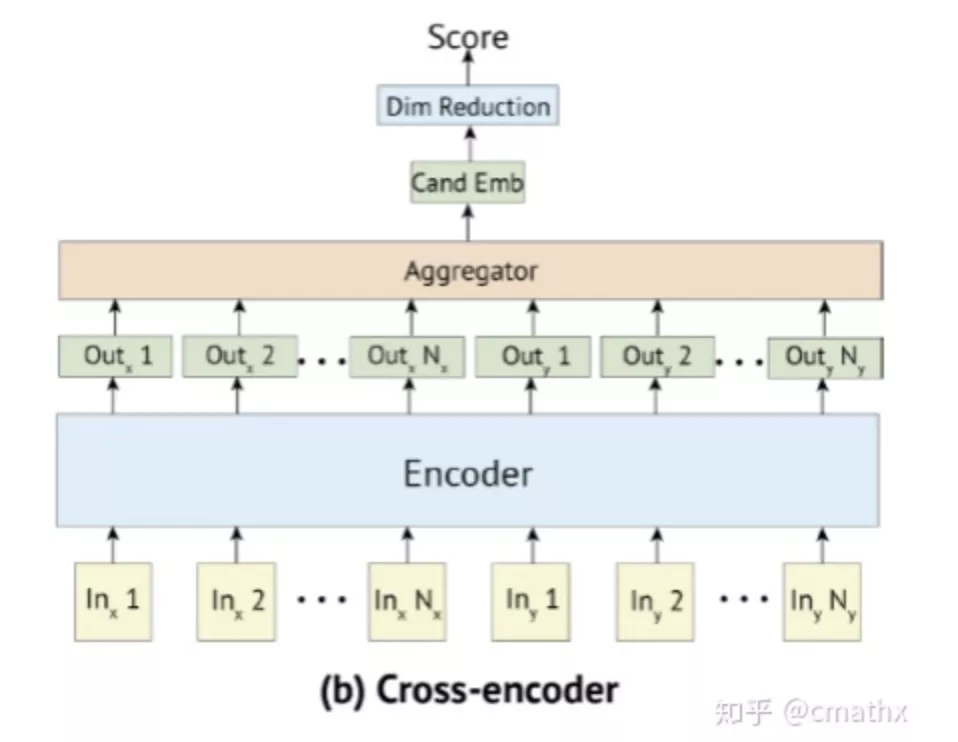
三、Poly-Ecnoders
1)建模


和stanford paper不一致的地方,这边doc(candidate)的建模结果只有一个embedding。第一个公式,主要是用于paper里面的对话任务,query(context)为对话的前面n条记录,因此query太长了,需要做一个压缩。第二个公式,采用attention的方式,计算query中各个embedding和doc的相关性,最终采用加权向量方式作为最终query的embedding。这边计算attention的时候,引入了softmax,因此这种建模的方式引入faiss可能是个问题?paper里面也只展示了粗排的相关实验结果。
2)实验结论
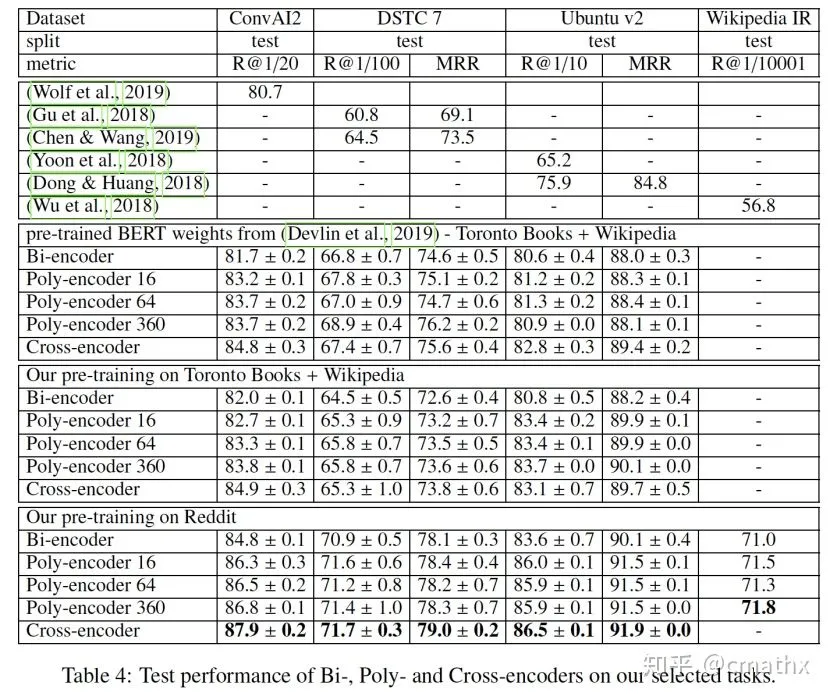
从召回率指标上来看,在不同测试集上,Poly-encoder的实验结果基本快和Cross-encoder持平。
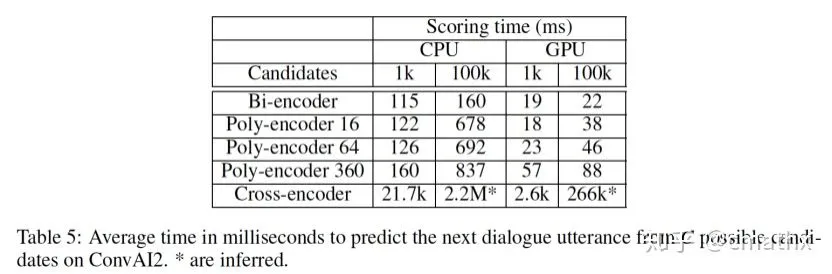
从检索的效率来看,相比Bi-encoder,Poly-encoder的检索耗时大约多了3-4倍,当候选召回在100k规模,使用cpu耗时大约678-837ms。相比Cross-encoder显然显著降低。
这篇关于推荐系统粗排召回相关性优化的最新进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






