本文主要是介绍一篇文章搞懂 ConcurrentSkipListMap,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文隶属于专栏《100个问题搞定Java并发》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见100个问题搞定Java并发
正文
跳表
在 JDK 的并发包中,除常用的哈希表外,还实现了一种有趣的数据结构一一跳表。
跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。
它们都可以对元素进行快速査找。
但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整,而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。
这样带来的好处是:
在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。
而对于跳表,你只需要部分锁即可。
这样,在高并发环境下,你就可以拥有更好的性能。
就查询的性能而言,因为跳表的时间复杂度是 O ( logn ),所以在并发数据结构中, JDK 使用跳表来实现一个 Map ,即 ConcurrentSkipListMap。
跳表的另外一个特点是随机算法。
跳表的本质是同时维护了多个链表,并且链表是分层的。下图是跳表结构示意图。
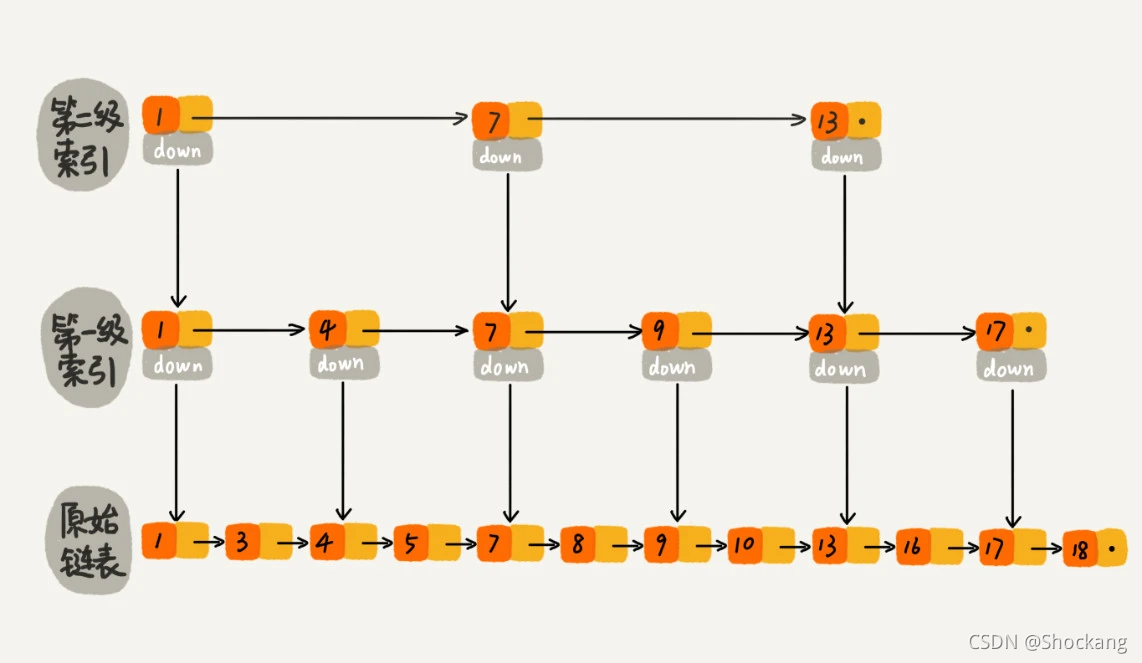
底层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层链表的子集,一个元素插入哪些层是完全随机的。
因此,如果运气不好,你可能会得到一个性能很糟糕的结构。
但是在实际工作中,它的表现是非常好的。
跳表内的所有链表的元素都是排序的。
查找时,可以从顶级链表开始找。
一旦发现被査找的元素大于当前链表中的取值,就会转入下一层链表继续找。
这也就是说在查找过程中,搜索是跳跃式的。
查找 10
在跳表中査找元素 10 ,如上图所示。
查找从顶层的头部索引节点开始。
由于顶层的元素最少,因此可以快速跳过那些小于 10 的元素。
很快,查找过程就能到元素 10。
由于在第 2 层,元素 13 大于 10 ,故肯定无法在第 2 层找到元素 10 ,直接进入底层(包含所有元素)开始査找,并且很快就可以根据元素 9 搜索到元素 10 。 整个过程,要比一般链表从元素 1 开始逐个搜索快得多。
因此,很显然,跳表是一种使用空间换时间的算法。
跳表实现 Map 与 哈希算法实现 Map
使用跳表实现 Map 和使用哈希算法实现 Map 的一个不同之处是:
哈希并不会保存元素的顺序,而跳表内所有的元素都是有序的。
因此在对跳表进行遍历时,你会得到一个有序的结果。
因此,如果你的应用需要有序性,那么跳表就是你的最佳选择。
实践
下面展示了 ConcurrentSkipListMap 的简单使用方法。
package com.shockang.study.java.concurrent.skip_list;import java.util.Map;
import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapDemo {public static void main(String[] args) {Map<Integer, Integer> map = new ConcurrentSkipListMap<>();for (int i = 0; i < 30; i++) {map.put(i, i);}for (Map.Entry<Integer, Integer> entry : map.entrySet()) {System.out.println(entry.getKey());}}
}
源码分析(JDK8)
跳表的内部实现由几个关键的数据结构组成。
Node
首先是 Node ,一个 Node 表示一个节点,里面含有 key 和 value (就是 Map 的 key 和 value )两个重要的元素。
每个 Node 还会指向下个 Node ,因此还有一个元素 next 。
方法 casValue 用来设置 value的值,相对的 casNext() 方法用来设置next的字段。
/*** Nodes hold keys and values, and are singly linked in sorted* order, possibly with some intervening marker nodes. The list is* headed by a dummy node accessible as head.node. The value field* is declared only as Object because it takes special non-V* values for marker and header nodes.*/static final class Node<K,V> {final K key;volatile Object value;volatile Node<K,V> next;/*** Creates a new regular node.*/Node(K key, Object value, Node<K,V> next) {this.key = key;this.value = value;this.next = next;}/*** Creates a new marker node. A marker is distinguished by* having its value field point to itself. Marker nodes also* have null keys, a fact that is exploited in a few places,* but this doesn't distinguish markers from the base-level* header node (head.node), which also has a null key.*/Node(Node<K,V> next) {this.key = null;this.value = this;this.next = next;}/*** compareAndSet value field*/boolean casValue(Object cmp, Object val) {return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);}/*** compareAndSet next field*/boolean casNext(Node<K,V> cmp, Node<K,V> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);}/*** Returns true if this node is a marker. This method isn't* actually called in any current code checking for markers* because callers will have already read value field and need* to use that read (not another done here) and so directly* test if value points to node.** @return true if this node is a marker node*/boolean isMarker() {return value == this;}/*** Returns true if this node is the header of base-level list.* @return true if this node is header node*/boolean isBaseHeader() {return value == BASE_HEADER;}/*** Tries to append a deletion marker to this node.* @param f the assumed current successor of this node* @return true if successful*/boolean appendMarker(Node<K,V> f) {return casNext(f, new Node<K,V>(f));}/*** Helps out a deletion by appending marker or unlinking from* predecessor. This is called during traversals when value* field seen to be null.* @param b predecessor* @param f successor*/void helpDelete(Node<K,V> b, Node<K,V> f) {/** Rechecking links and then doing only one of the* help-out stages per call tends to minimize CAS* interference among helping threads.*/if (f == next && this == b.next) {if (f == null || f.value != f) // not already markedcasNext(f, new Node<K,V>(f));elseb.casNext(this, f.next);}}/*** Returns value if this node contains a valid key-value pair,* else null.* @return this node's value if it isn't a marker or header or* is deleted, else null*/V getValidValue() {Object v = value;if (v == this || v == BASE_HEADER)return null;@SuppressWarnings("unchecked") V vv = (V)v;return vv;}/*** Creates and returns a new SimpleImmutableEntry holding current* mapping if this node holds a valid value, else null.* @return new entry or null*/AbstractMap.SimpleImmutableEntry<K,V> createSnapshot() {Object v = value;if (v == null || v == this || v == BASE_HEADER)return null;@SuppressWarnings("unchecked") V vv = (V)v;return new AbstractMap.SimpleImmutableEntry<K,V>(key, vv);}// UNSAFE mechanicsprivate static final sun.misc.Unsafe UNSAFE;private static final long valueOffset;private static final long nextOffset;static {try {UNSAFE = sun.misc.Unsafe.getUnsafe();Class<?> k = Node.class;valueOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("value"));nextOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("next"));} catch (Exception e) {throw new Error(e);}}}
Index
另外一个重要的数据结构是 Index 。
顾名思义,这个表示索引内部包装了 Node ,同时增加了向下的引用和向右的引用。
索引节点表示跳表的级别。
注意,尽管 Node 和 Index 都有前向字段,但它们的类型不同,处理方式也不同,将字段放置在共享抽象类中无法很好地捕获这些字段。
/*** Index nodes represent the levels of the skip list. Note that* even though both Nodes and Indexes have forward-pointing* fields, they have different types and are handled in different* ways, that can't nicely be captured by placing field in a* shared abstract class.*/static class Index<K,V> {final Node<K,V> node;final Index<K,V> down;volatile Index<K,V> right;/*** Creates index node with given values.*/Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {this.node = node;this.down = down;this.right = right;}/*** compareAndSet right field*/final boolean casRight(Index<K,V> cmp, Index<K,V> val) {return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);}/*** Returns true if the node this indexes has been deleted.* @return true if indexed node is known to be deleted*/final boolean indexesDeletedNode() {return node.value == null;}/*** Tries to CAS newSucc as successor. To minimize races with* unlink that may lose this index node, if the node being* indexed is known to be deleted, it doesn't try to link in.* @param succ the expected current successor* @param newSucc the new successor* @return true if successful*/final boolean link(Index<K,V> succ, Index<K,V> newSucc) {Node<K,V> n = node;newSucc.right = succ;return n.value != null && casRight(succ, newSucc);}/*** Tries to CAS right field to skip over apparent successor* succ. Fails (forcing a retraversal by caller) if this node* is known to be deleted.* @param succ the expected current successor* @return true if successful*/final boolean unlink(Index<K,V> succ) {return node.value != null && casRight(succ, succ.right);}// Unsafe mechanicsprivate static final sun.misc.Unsafe UNSAFE;private static final long rightOffset;static {try {UNSAFE = sun.misc.Unsafe.getUnsafe();Class<?> k = Index.class;rightOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("right"));} catch (Exception e) {throw new Error(e);}}}
HeadIndex
整个跳表就是根据 Index 进行全网的组织的。
此外,对于每一层的表头还需要记录当前处于哪一层。
为此,还需要一个名为 Headlndex 的数据结构,表示链表头部的第一个 Index ,它继承自 Index 。
/*** Nodes heading each level keep track of their level.*/static final class HeadIndex<K,V> extends Index<K,V> {final int level;HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {super(node, down, right);this.level = level;}}
这样核心的内部元素就介绍完了。
对于跳表的所有操作,就是组织好这些 Index之间的连接关系。
这篇关于一篇文章搞懂 ConcurrentSkipListMap的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!