本文主要是介绍VideoAssembler 一种新颖的方法,生成具有多样化内容的视频的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 方法
- 代码
VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model

本文提出了VideoAssembler,一种新颖的方法,生成具有多样化内容的视频。它可以保留实体的保真度,并生成可控的内容。
摘要
身份一致的视频生成旨在合成由文本提示和实体的参考图像共同引导的视频。目前的方法通常使用交叉注意力层来整合实体的外观,主要捕获语义属性,从而导致实体的保真度降低。此外,这些方法需要对遇到的每个新实体进行迭代微调,从而限制了它们的适用性。为了应对这些挑战,我们引入了VideoAssembler,一种新颖的端到端的身份一致性视频生成框架,可以在遇到新实体时直接进行推理。VideoAssembler擅长制作视频,这些视频不仅对输入的参考实体具有灵活性,而且对文本条件具有响应性。此外,通过调整实体的输入图像数量,VideoAssembler能够执行从图像到视频生成到复杂视频编辑的任务。VideoAssembler包含两个主要组件:参考实体金字塔( Reference Entity Pyramid,REP )编码器和实体-提示注意力融合( Entity-Prompt Attention Fusion,EPAF )模块。其中REP编码器旨在为稳定扩散模型的去噪阶段注入全面的外观细节。同时,利用EPAF模块对文本对齐特征进行有效整合。此外,为了减轻稀缺数据的挑战,我们提出了一种对训练数据进行预处理的方法。我们在UCF - 101、MSRVTT和DAVIS数据集上对VideoAssembler框架的评估表明,它在( UCF - 101的FVD为346.84 , IS为48.01)的定量和定性分析中都取得了良好的性能。
方法
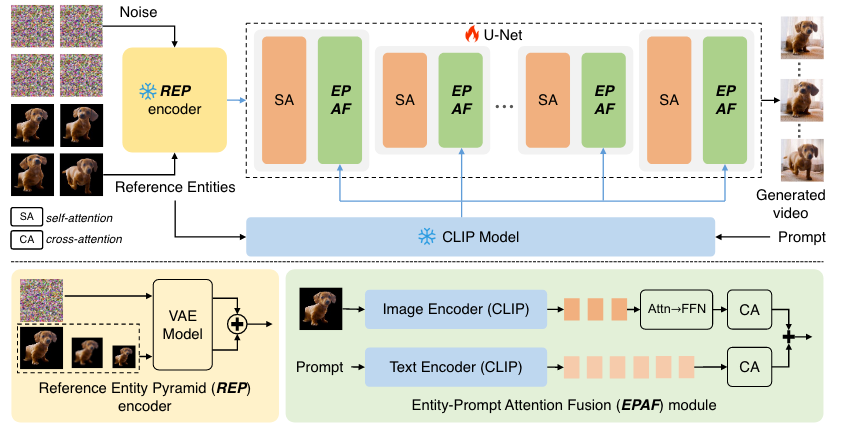
本文的VideoAssembler方法的训练管道。该模型可以根据给定的实体和文本提示生成高保真度的视频。我们训练了U - Net中包含的所有注意力层,同时保持VAE和CLIP模型冻结。
给定某一实体的一系列静态外观,生成该实体的视频是非平凡的。时间一致性和保真度都具有挑战性。为此,我们提出了VideoAssembler,其训练流程如图2所示。VideoAssembler旨在生成高保真、高质量的视频,并受参考实体和文本提示的制约。与现有的微调方法[ 4、25、34]不同,VideoAssembler是一个端到端的框架,能够与多样化的实体阵列进行直接推理。输入实体图像的数量可以灵活地确定,即使是单个图像也可以满足最低要求。我们的方法是基于VidRD [ 9 ],它是一个纯文像转换模型。包括用于潜在表示的VAE和用于潜在去噪的U - Net。VideoAssembler包含参考实体金字塔( Reference Entity Pyramid,REP )编码器和实体-提示注意力融合( Entity-Prompt Attention Fusion,EPAF )模块两部分。此外,由于训练数据的限制,我们还贡献了一种新的数据处理方法。我们介绍了VideoAssembler的概况和Sec中的预备知识。
代码
项目页面在 https://gulucaptain.github.io/videoassembler/.
这篇关于VideoAssembler 一种新颖的方法,生成具有多样化内容的视频的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





