本文主要是介绍KNN算法原理 K Nearest Neighbour,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
K-临近算法原理
简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,常用的是计算欧几里得距离,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。
一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
实例:选取鸢尾花数据进行分类
# load_iris是机器学习库提供给我们研究算法的数据
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data # 150个花的特征数据
target = iris.target # 每个数据对应的分类结果
target_names = iris.target_names # 每个结果对应的名字
feature_names = iris.feature_names # 所有的特征features = DataFrame(data=data,columns = feature_names)# 获取训练集和测试集,为了能够在图上显示,只选择两个特征进行features.iloc[:,0].std()
#0.828066127977863features.iloc[:,2].std()
#1.7652982332594662features.iloc[:,1].std()
#0.4358662849366982features.iloc[:,3].std()
#0.7622376689603465# 选区标准差较大的两个作为训练数据
# samples(训练集、测试集)
X_train = features.iloc[:130,2:4]
y_train = target[:130]# 测试集(验证训练模型的准确度)
X_test = features.iloc[130:,2:4]
y_test = target[130:]# 绘制图形
import matplotlib.pyplot as plt
%matplotlib inline
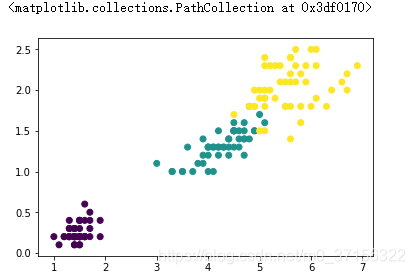
samples = features.iloc[:,2:4]# 展示真实数据的分类情况
plt.scatter(samples.iloc[:,0],samples.iloc[:,1],c=target)
# 定义KNN分类器,训练数据,生成预测结果。
knnclf = KNeighborsClassifier(n_neighbors=5)
knnclf.fit(X_train,y_train)
y_ = knnclf.predict(X_test)# 获取所有预测点(满屏幕的点),将满屏幕的点最为预测数据
xmin,xmax = samples.iloc[:,0].min(),samples.iloc[:,0].max()
ymin,ymax = samples.iloc[:,1].min(),samples.iloc[:,1].max()x = np.linspace(xmin,xmax,100)
y = np.linspace(ymin,ymax,100)xx,yy = np.meshgrid(x,y)X_test = np.c_[xx.ravel(),yy.ravel()]
y_ = knnclf.predict(X_test)
# 显示数据
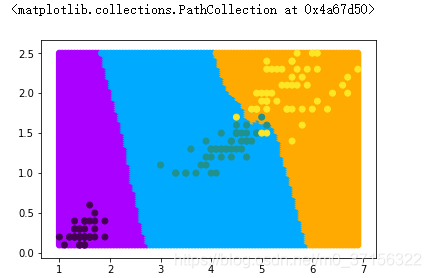
from matplotlib.colors import ListedColormapcmap = ListedColormap(['#aa00ff','#00aaff','#ffaa00'])# 展示预测数据的分类情况
plt.scatter(X_test[:,0],X_test[:,1],c=y_,cmap=cmap)
# 展示真实数据的分类情况
plt.scatter(samples.iloc[:,0],samples.iloc[:,1],c=target)
KNN算法还可用于回归分析
第一步:生成模型,并训练数据
第二步:使用模型,预测数据
大概思路,使用周围几个点(根据n_neighbors的取值)坐标的平均值作为线上的点
小结
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:时间复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
这篇关于KNN算法原理 K Nearest Neighbour的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






