本文主要是介绍深度学习硬件这件事,GPU、CPU、FPGA到底谁最合适?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
二、数据的训练:CPU与GPU之争
2.1、现状
在如今的深度学习平台上,CPU面临着一个很尴尬的处境:它很重要又不是太重要。 它很重要,是因为它依旧是主流深度学习平台的重要组成部分:现百度首席科学家吴恩达曾利用16000颗CPU搭建了当时世界上最大的人工神经网络“Google Brain”并利用深度学习算法识别出了“猫”,又比如名震一时的“AlphaGo”就配置了多达1920颗CPU。
但是它又不是太重要:相比于其他硬件加速工具,传统的CPU在架构上就有着先天的弱势。

上图是CPU与GPU内部结构上的对比,总体上来说二者都是由控制器(Control),寄存器(Cache、DRAM)和逻辑单元(ALU:Arithmetic Logic Unit)构成。但是三者的比例却有很大的不同。在CPU中控制器和寄存器占据了结构中很大一部分,与之相反,在GPU中,逻辑单元的规模则是远远超过其他二者之和。这种不同的构架就决定了CPU在指令的处理/执行,函数的调用上有着很好的发挥,但由于逻辑单元所占比重较小,相对于GPU而言,在数据的处理方面(算术运算或者逻辑运算)的能力就弱了很多。
我们拿NIVIDA公司基于Maxwell构架的GPU来详细说明。这颗代号GM200的显示核心主要由4个图形处理集群(GPC:Graphics Processing Clusters ),16个流处理集群(SMM:Steaming Multiprocess)和4个64bit显存控制器组成。每个流处理集群中包含了4个调度器(Warp),每个调度器又控制着32个逻辑计算核心(Core),这些Core是实现逻辑计算的基本单元。
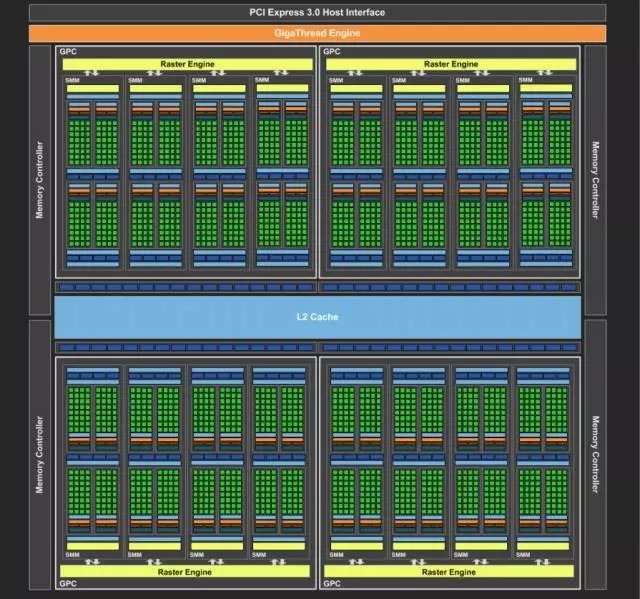
GPU进行数据处理的过程可以描述成:GPU从CPU处得到数据处理的指令,把大规模、无结构化的数据分解成很多独立的部分然后分配给各个流处理器集群。每个流处理器集群再次把数据分解,分配给调度器所控制的多个计算核心同时执行数据的计算和处理。如果一个核心的计算算作一个线程,那么在这颗GPU中就有32×4×16, 2048个线程同时进行数据的处理。尽管每个线程/Core的计算性能、效率与CPU中的Core相比低了不少,但是当所有线程都并行计算,那么累加之后它的计算能力又远远高于CPU。对于基于神经网络的深度学习来说,它硬件计算精度要求远远没有对其并行处理能力的要求来的迫切。而这种并行计算能力转化为对于硬件的要求就是尽可能大的逻辑单元规模。通常我们使用每秒钟进行的浮点运算(Flops/s)来量化的参数。不难看出,对于单精度浮点运算,GPU的执行效率远远高于CPU。

除了计算核心的增加,GPU另一个比较重要的优势就是他的内存结构。首先是共享内存。在NVIDIA披露的性能参数中,每个流处理器集群末端设有共享内存。相比于CPU每次操作数据都要返回内存再进行调用,GPU线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高(速度:共享内存》全局内存)。
再就是高速的全局内存(显存):目前GPU上普遍采用GDDR5的显存颗粒不仅具有更高的工作频率从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。我们认为在数据处理中,速度往往最终取决于处理器从内存中提取数据以及流入和通过处理器要花多少时间。
而在传统的CPU构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在CPU中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在60GB/s左右徘徊。与之相比,大显存带宽的GPU具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
而且就目前而言,越来越多的深度学习标准库支持基于GPU的深度学习加速,通俗点描述就是深度学习的编程框架会自动根据GPU所具有的线程/Core数,去自动分配数据的处理策略,从而达到优化深度学习的时间。而这些软件上的全面支持也是其他计算结构所欠缺的。
2.2、未来
但是CPU真的在未来规模深度神经网络的计算中沦为花瓶么?CPU巨擘英特尔显然不甘于出现这样的局面。
在其于去年发布的代号“KNL(Knignts Landing)融核”处理器介绍中,我们发现英特尔针对目前CPU的种种弊端做出了很大的调整:首先在硬件架构上集成了更多的核心(72颗),这意味着有更多的逻辑单元去进行运算。其次是英特尔为这些核心增加了“可变精度”的支持,在低精度模式下(深度学习通常使用单精度)大幅度提高其浮点运算能力(3+TFlops),甚至接近GPU的性能指标。在内存支持方面,它不仅可以支持更多的内存,而且大幅提高了与内存间数据通讯的带宽,这也解决了目前CPU数据传输速度的弊端。

与这颗处理器相匹配的,是“MIC(Many Integrated Core)”众核同构计算模型。也是有别于其他加速硬件而被称为众核计算的原因:它可以完美运行X86代码。简而言之就是它可以直接脱离CPU直接与内存相连来进行深度学习。相对于“CPU+加速硬件”的异构模型,这种众核计算在很大程度上避免了CPU与加速硬件之间的通讯带宽问题。从而优化深度学习训练时间。
以现状而论,GPU的风头远远盖过CPU,但是对于CPU而言,新发布的处理器在构架上的变化让它把曾经的劣势(核心数/带宽)逐渐变为了它潜在的优势。因此,二者数据训练领域之争还依旧会持续下去。
三、数据的推断:FPGA VS ASIC
虽然“CPU+GPU”或者“MIC”的计算模型被广泛的应用于各种深度学习中去。其实CPU与GPU都是利用现有的成熟技术去提供了一种通用级的解决方法来满足深度学习的要求,尽管如Intel 与NVIDIA不断推出了如“KNL”和“Pascal”系列加速芯片来助阵深度学习,但这仅仅是大公司对于深度学习的一种妥协,而并不是一种针对性的专业解决方案。
目前在深度学习模型的训练领域基本使用的是SIMD(Single Instruction Multiple Data:单指令多数据流架构)计算,即只需要一条指令就可以平行处理大批量数据。但是,在平台完成训练之后,它还需要进行推理环节的计算。这部分的计算更多的是属于MISD(Multiple Instruction Single Data:多指令流单数据流)。比如讯飞语音输入法在同一时间要对数以百万计的用于的语音输入进行识别并转化为文字输出。
在这个阶段,他们的作用必远不如训练阶段那么得心应手。而在未来,至少95%的深度学习都用于推断,尤其是在移动端。只有不到5%的是用于模型训练。因此,寻找低功耗,高性能,低延时的加速硬件成了当务之急。在这种情况下,人们把目光投向了“FPGA”与“ASIC”。
3.1、现状
FPGA全称是Field Programmable Gate Array:可编程逻辑门阵列。相对于之前两种芯片,它有一下几个的特点:硬件层面上,其内部集成大量的数字电路基本门电路和存储器,用户可以通过烧入配置文件来定义这些它们之间的连线,从而达到定制电路的目的;逻辑层面上,它不依赖于冯诺依曼结构,一个计算得到的结果可以被直接馈送到下一个无需在主存储器临时保存,因此不仅存储器带宽需求比使用GPU 或者CPU实现时低得多,而且还具有流水处理和响应迅速的特点。
ASIC(Application-Specific Integrated Circuit)是一种为专门目的而设计的集成电路。是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。ASIC的特点是面向特定用户的需求。亮点在于运行速度在同等条件下比FPGA快。根据谷歌披露的数据,完全版的“AlphaGo”拥有1920颗CPU和280颗GPU,除此此外,还有它还安装一定数量的TPU(Tensor Processing Unit)。 尽管谷歌一直对TPU语焉不详,业内普遍认为“AlphaGo”对围棋局势的预判所使用的置信网络(Value network)就是依赖TPU的发挥。

与GPU/CPU相比,FPGA与ASIC拥有良好的运行能效比,在实现相同性能的深度学习算法中,GPU所需的功耗远远大于FGPA与ASIC。浪潮与Intel 于去年底FPGA加速卡 F10A 最高性能的加速卡,单芯片峰值运算能力达到1.5TFlops,功耗才35W,每瓦特功率42GFlops,是GPU的数倍之高。其次,对于SIMD计算,GPU/CPU尽管具有很多逻辑核心,但是受限于冯诺依曼结构,无法发挥其并行计算的特点。而FPGA与ASIC不仅可以做到并行计算,而且还能实现流水处理。这大大减小了输入与输出的延时比。
下图是FPGA与ASIC在设计环节的对比。FPGA从设计的角度来说更加的灵活多变。只要用 Verilog或者其他描述语言定义好内部的逻辑结构即可实现硬件加速器功能。而ASIC则更像是一锤子卖卖:针对特定功能深度学习算法量身定做的。而且ASIC的设计和制造要经过很多的验证和物理设计,与FPGA的即插即用相比,需要更多的时间,而且从设计到制造,付出的代价也相应的高了很多。一般来说,基于FPGA的开发周期大约为6个月,而相同规格的ASIC则需要1年左右。

但是话又说回来,事物都有两面性。FPGA的的架构固然带来了应用上的灵活性和低成本,但是从执行的效率上来说,它又远远比不上ASIC,FPGA的通用性必然导致冗余。FPGA的运算电路基于查找表,比如说,FPGA内部有1000万个自定义逻辑部件,一个4输入的查找表单元需要96个晶体管来支持,而在ASIC上来实现估计只需要10个左右。这些冗余也必然体现在芯片的面积和功耗上。
与CPU与GPU之争的一边倒相比,由于功能与市场定位等原因,二者间的竞争还是相当缓和。
由于FPGA具有开发周期短,上市速度快,可配置性等特点,目前被大量的应用在大型企业的线上数据处理中心,和军工单位。
而ASIC由于一次性成本远远高于FPGA,但由于其量产成本低,因此应用上就偏向于消费电子,如移动终端等领域。
3.2、未来
上文所说,在未来的深度学习中,大约有95%的应用是数据的推断。而且FPGA或者ASIC相较于GPU/CPU无论在研发还是产出上的成本都明显降低。因此必然是兵家必争之地。无论从INTEL收购ALTRA/ Movidius,还是XILINX与IBM合作,抑或谷歌和高通默默开发自己的专属ASIC中都可见一斑。而且针对移动端的深度学习,FPGA或者ASIC更多的会以SOC形式出现,以至于更好的优化神经网络结构提升效率。
这篇关于深度学习硬件这件事,GPU、CPU、FPGA到底谁最合适?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



