本文主要是介绍Abraxas: Throughput-Efficient Hybrid Asynchronous Consensus,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 笔记
- 后续的研究方向
- 摘要
- 引言
- 网络延迟弹性与性能
- 两者兼而有之
- 基于DAG的协议
Abraxas: Throughput-Efficient Hybrid Asynchronous Consensus
CCS 2023

笔记
后续的研究方向
摘要
用于状态机复制(SMR)的协议经常在性能与对网络延迟的恢复能力之间进行权衡。特别地,用于异步SMR的协议容忍任意网络延迟,但当网络快速时牺牲吞吐量/延迟,而部分同步协议在快速网络中具有良好性能,但如果网络经历高延迟,则无法取得进展。现有的混合协议对任意网络延迟具有弹性,并且在网络快速时具有良好的性能,但如果网络在快速和慢速之间重复切换,例如在通常快速但具有间歇性消息延迟的网络中,则会遭受高开销(“颠簸”)。
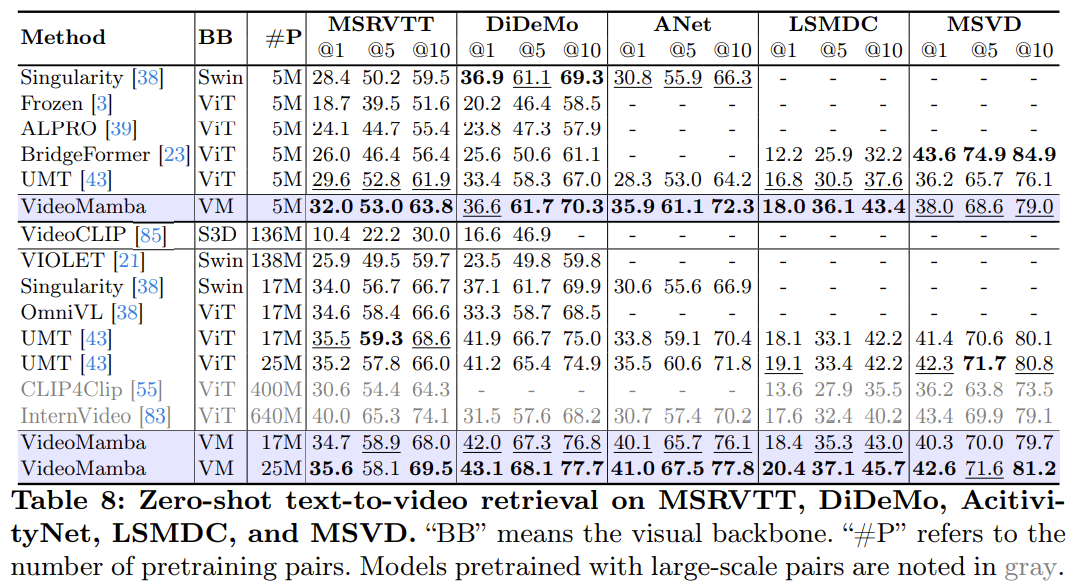
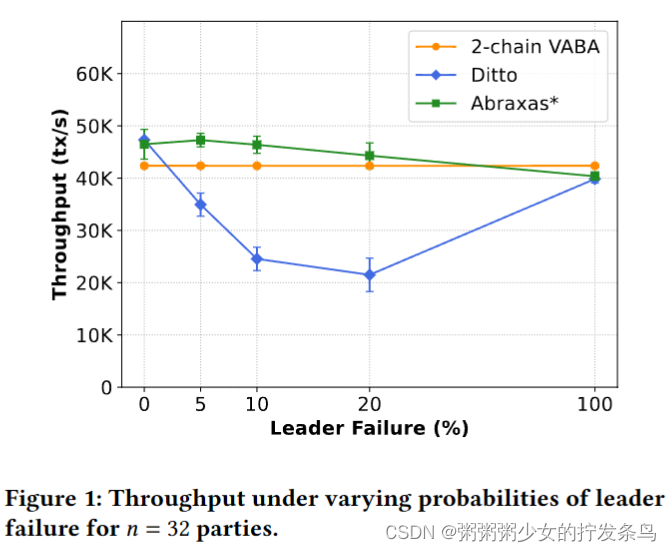
我们提出了Abraxas,这是一种通用的方法,用于从任何“快速”协议π-快速和异步协议π-慢速构建混合协议,以实现(1)在任意网络行为下与π-慢速等效的安全性和性能,以及(2)在条件有利时与π-快速等效的性能。我们用现有的π-快(Jolteon)和π-慢(2-链VABA)的最佳协议实例化Abraxas,并通过实验表明,所得到的协议显著优于Ditto,即先前的先进混合协议。
引言
状态机复制(SMR)协议[17,21,23]构成了分布式账本技术或区块链的核心。SMR允许分布式各方就块的无边界有序序列(即链)达成一致,每个块都包含一些预定数量的事务。SMR在部分恶意方存在的情况下的安全性需要两个基本特性:一致性和活跃性。一致性要求所有诚实的各方就其输出的任何块达成一致。活跃性保证了进步,因为如果所有诚实的各方都持有一些交易作为输入,那么该交易最终将被这些各方包含在一些块输出中。
网络延迟弹性与性能
SMR文献主要考虑三种网络设置:同步、部分同步和异步。在同步网络中,假设所有消息在发送后的某个固定(已知)时间Δ内送达。这允许容忍高达𝑡 < 𝑛/2个恶意方。然而,在实践中,通常很难保证完全同步。这促使了部分同步[7,9,10,24]和异步[5,8,14,18,19]协议的设计,它们只能容忍𝑡 < 𝑛/3腐败方。
在部分同步设置中,网络最初是异步的,但保证在一些未知(但有限)的全局稳定时间(GST)后变得完全同步。这一假设允许通过依赖负责推动协议进展的领导者来实现高效的确定性协议。例如,在GST之后,如果领导者没有故障,则此类协议可以在三轮通信中确认阻塞[10]。此外,在这种情况下,这种协议的延迟和吞吐量可以严格优于同步协议,因为它们的运行时间取决于实际的网络延迟𝛿而不是(通常是悲观的)最坏情况下的同步参数Δ。然而,在GST之前或当领导者是恶意的时,这些协议需要调用相对昂贵的领导者轮换子协议。在这些情况下,部分同步协议可以执行重复的前导旋转,在此期间没有取得任何进展。
在异步设置中,消息可能会延迟任意长的时间,唯一的保证是它们最终会被传递。任何安全的异步协议都必须随机化。不幸的是,这代表了一个重大问题瓶颈:事实上,与(确定性的)部分同步协议相比,最先进的异步协议通常需要更多的轮次来输出一个块(例如,预期>10轮次[2,14])。这不仅导致高延迟,而且导致低吞吐量,因为各方直到前一个块被确认才开始处理下一个块。
两者兼而有之
理想情况下,SMR协议即使在最坏的情况下也是安全的,同时在良好的条件下具有良好的性能。考虑到这一目标,Kursawe和Shoup开始了一系列关于所谓混合(或乐观)协议的工作[16,22]。这类协议有一个确定性的“快速路径”,当条件有利时(例如,当领导者诚实且网络快速时),如部分同步协议中所述,可以快速取得进展;还有一个回退的“慢速路径”,在条件不有利时,如异步协议中所示,可以保证活跃性。通过在这些路径之间交替,混合协议可以实现高效率和强安全性。Aublin等人[4]后来对该技术进行了研究,他介绍了一种用于构建混合协议的通用框架;Pass和Shi[20]在他们的Thunderella协议中进一步完善和推广了混合技术。在过去的几年里,混合协议在异步[12,18]和同步[1,3,20]设置中继续受到人们的强烈兴趣。
在异步设置中,现有混合协议的一个缺点是,当它们频繁地回退到慢速路径时,它们的性能会受到影响。特别是,大多数混合协议首先尝试运行快速路径,只有在一定的超时时间后才回落到慢速路径(否则协议可能会不必要地回落)。因此,在最坏的网络条件下,即使是最好的混合协议[12,18]的效率也明显低于纯异步协议。这种不令人满意的状态引发了一个自然的问题:是否存在异步混合协议,其性能在条件有利时可与最佳部分同步协议相媲美,在条件不利时可与最优异步协议相媲美?
基于DAG的协议
最近基于DAG的协议[11,13,15]部分回答了这个问题,因为即使在网络条件波动的情况下,它们也能保持稳定的吞吐量和延迟。基于DAG的协议分步骤进行,在每个步骤中𝑛各方提议𝑂(𝑛)并行的块(一个层),并且每个提议都指向前一层中的多个块。这种方法的一个优点是,它们将协议的活跃度与事务广播解耦,这允许它们在从间歇性的活跃度损失中恢复时一次提交多个块。然而,这些基于DAG的方法的一个问题是,它们需要Ω(𝑛3) 每层的总通信量,这意味着当各方数量增加时,它们会导致高网络拥塞。此外,由于需要存储𝑛每层的块——除了指向前一层中块的所有指针之外——运行基于DAG的协议的各方的内存占用是Ω(𝑛2) 。

这篇关于Abraxas: Throughput-Efficient Hybrid Asynchronous Consensus的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)