本文主要是介绍Collective Affinity Learning for Partial Cross-Modal Hashing(CALM)--文献翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

摘要
在过去的十年中,已经开发了各种无监督哈希方法用于跨模态检索。然而,在实际应用中,每个模态数据都可能遭受一些缺失样本的影响,这通常是不完整的情况。大多数现有工作假设每个对象都出现在两种模态中,因此它们可能不适用于部分多模态数据。为了解决这个问题,我们提出了一种新颖的集体亲和学习方法(CALM),它集体和自适应地学习锚图,用于在部分多模态数据上生成二进制代码。在 CALM 中,我们首先共同构建特定于模态的二部图,并推导出一个概率模型来计算每个模态的完整数据到锚点的亲和力。理论分析揭示了它恢复丢失的邻接信息的能力。此外,提出了一种稳健的模型,通过自适应地学习统一的锚图来融合这些特定于模态的亲和力。然后,来自学习到的锚图的邻域信息作为反馈,指导之前的亲和力重建过程。为了解决公式化的优化问题,我们进一步开发了一种具有线性时间复杂度和快速收敛的有效算法。最后,对融合的亲和力进行锚图哈希(AGH)以进行跨模态检索。基准数据集的实验结果表明,我们提出的 CALM 始终优于现有方法。
挑战与困难
由于数据的复杂分布和组织[1]-[3],跨未标记的异构模式检索相似或相关实体的任务已变得具有挑战性。异质性在许多多媒体应用中已经无处不在[4]、[5],因为数据通常是从各种特征提取器收集的或从不同的领域获得的。每组特征都可以被认为是一种特定的模态[6],[7]。例如,视频可以用视觉和音频信息来表示;图像可以用颜色和形状来表示;一个网页可以用图像、文字和 Urls来表示。
两个挑战
1、不完整的特定于模式的信息。如果我们为两种模态学习统一的表示,则可以保证相似关系或哈希码的模态间一致性。然而,尽管它对学习表示有潜在的贡献,但所有缺失样本引起的不完整信息都被浪费了。
2、无根据的多模态一致性。如果我们分别学习特定于模态的表示,则可以削弱由缺失样本引起的不利影响,因为学习过程是在每个模态上独立进行的。但是,对于出现在两种模态中的对象,如何保证上述相似关系或哈希码的模态间一致性仍不清楚。

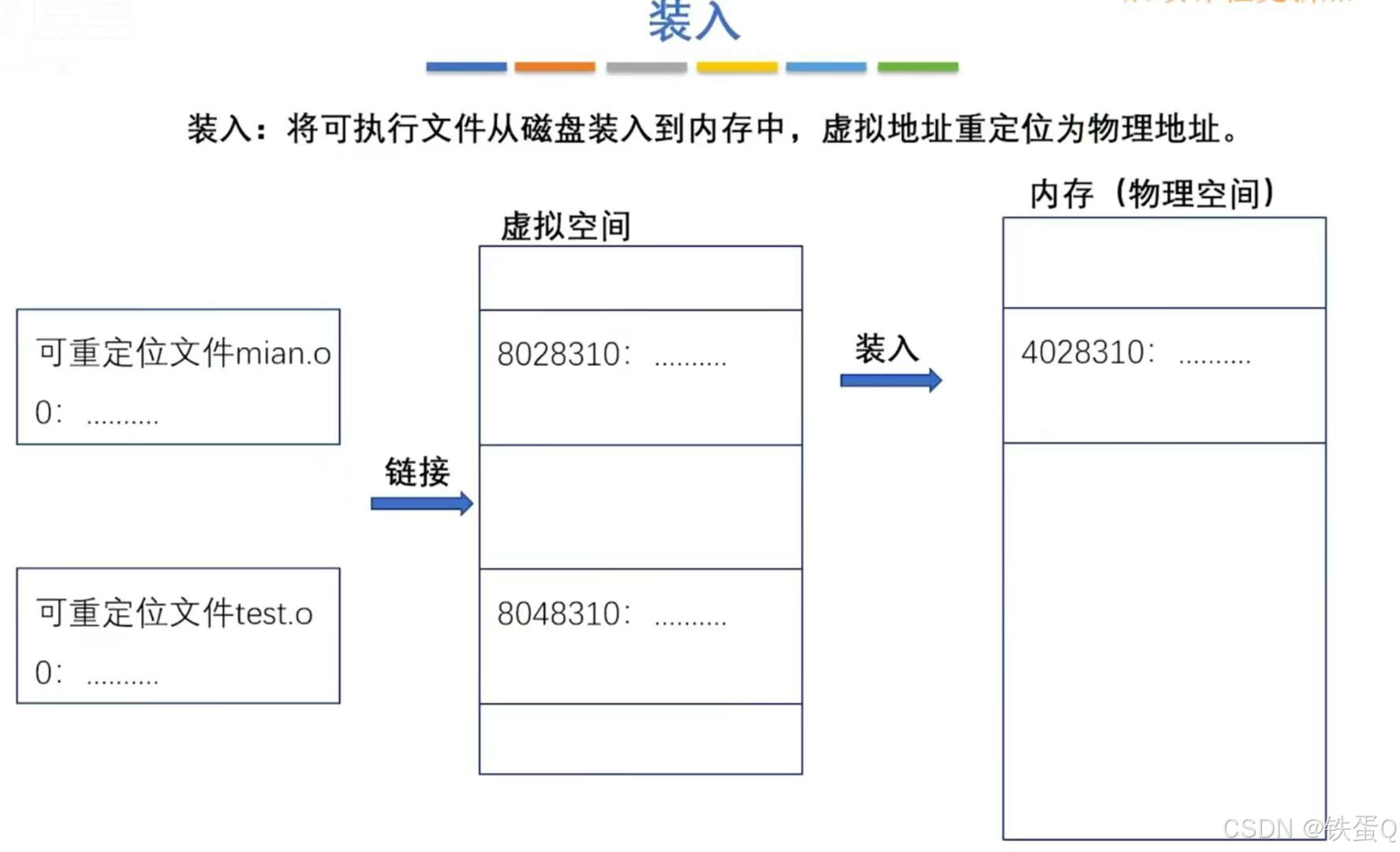
图 1. (a) 完整和 (b) 部分多模态数据的散列说明。相同的形状表示相同的模态,相同的颜色表示相同的类别/语义标签。黑色斜线表示相应的样本实际上是缺失的。
如图 1(a) 所示。他们假设每个对象的不同模态在多模态数据中共存。然而,在现实世界的跨模态检索应用程序中,每种模态都可能存在一些缺失样本,这会导致部分多模态数据,如图 1(b) 所示。例如,网页上的某些图片可能由于用户删除而无法访问,网页上的某些 URL 可能成为无效链接。
| 1、提出了一种有效的无监督学习策略,称为集体亲和学习方法 (CALM),用于部分跨模态散列。 CALM的整个框架包括三个交替的模块:集体亲和力重建、自适应亲和力融合和邻域信息反馈。 |
| 2、我们推导出一个概率模型,通过对应关系共同重建缺失的亲和力。由不完整的模态特定信息引起的第一个挑战是通过集体亲和力重建来解决的。 |
| 3、我们开发了一种强大的算法来自适应地融合不同模态的邻接信息。第二个挑战是通过具有线性时间复杂度和快速收敛的自适应亲和融合有效地解决了不必要的模态间一致性。 |
| 4、我们利用融合邻接的邻域信息作为反馈来指导亲和力重建,为CALM设计了一种自引导机制。 |

假设有 n 个人具有不同的专业背景。对于一个新颖的概念,他们的意见可能不同且互补。然后,每个人都可以通过 CL 获得新的知识并纠正他/她的先前知识。集体学习有三个关键组成部分:
1、学习过程的目的是让每个人最后都有一个完整的知识。因此,CL应该是所有人知识的统一。
2、每个人可能更喜欢听少数志同道合的人的意见。因此,“邻居”会影响所学知识的质量。
3、学习应该是动态的以及邻里信息。学习过程和“邻居”的更新应该迭代整合。
图 2 说明了整个框架。受 CL 的启发,我们提出的 CALM 具有三个设计模块:
1、第 III-B 节侧重于如何重建涉及缺失样本的亲和力。它们在对应关系(图 2 中的虚线)的指导下由模态内的亲和性共同重构,即对象的不同模态是同源的。这对应于人类集体学习的第一个关键组成部分。
2、第 III-C 节自适应地学习统一的锚点图,以便融合这些计算的来自不同模态的数据到锚点的亲和力。因此保证了相似性关系和散列码的模态间一致性。这类似于人类集体学习的第二个关键组成部分
3、第 III-D 节建议通过使用邻域信息作为集体亲和力重建的反馈,使 CALM 成为一个自我引导的框架。这就像人类集体学习的第三个关键组成部分。
B.集体亲和力重建
假设给定 n 个具有两种异构媒体类型的对象。
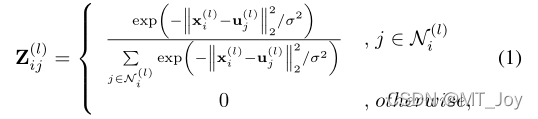
不相关为0,相关则需要计算其二分图。则xi和uj之间的数据到锚点的亲和性通过公式计算。

这两个矩阵本质上是不同的,必然会影响下一步学习具有统一亲和力的锚图。
C.自适应亲和融合



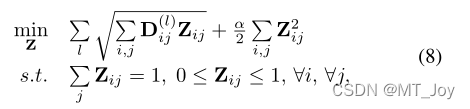
其中 α 2 是正则化参数。很明显,在我们的最终模型(8)中没有明确的权重参数需要预定义。在等式(8)中,似乎不同的模态具有相同的权重。有人可能想知道“权重自适应”是什么意思。我们将其推迟到第 IV-A 节,其中还将描述优化过程。
在第 IV-A 节中,我们将揭示我们对模型 (8) 的优化在迭代期间自动学习权重,这在无监督任务中具有显着优势。同时,第 IV-A 节将讨论如何通过为每个对象选择适当数量的最近锚对来确定参数 α 的值。
D. 邻里信息反馈

学习一个统一的锚点图,并以自适应方式为每个对象选择 k 个最近的锚点对。学习到的anchor graph的邻域信息可以作为反馈。通过邻域信息的反馈,集体亲和力重建(Section III-B)和自适应亲和力融合(Section III-C)以自我引导的方式迭代集成。
结论和未来工作
1、提出了一种新颖的基于 CALM 的无监督散列框架,用于部分跨模态检索。具体来说,首先共同构建涉及缺失样本的特定模态二部图。然后,我们在对应关系的帮助下计算完整的数据到锚点的亲和力。为了进一步融合两种模态的邻接信息,提出了一种具有线性时间复杂度和快速收敛的自适应算法。最后,来自融合锚图的邻域信息指导之前的亲和力重建。我们对融合的亲和力进行锚图哈希(AGH)以进行跨模态检索。在基准数据集上进行的大量实验表明,我们提出的 CALM 比现有方法具有更好的性能。
2、至于未来的工作,可能会有更有效的部分多模态数据框架。第一节中提到的两个不同的挑战并没有彻底解决。关于集体学习的策略,数据驱动和知识驱动的方法相结合可能是有前途的。
方法大致过程总结
首先利用不完备的数据样本构造特定模态的二分图,然后通过相对应的样本关联关系计算出每个数据样本与锚点样本之间的相似度图,最后利用融合的相似度关系在缺失数据上生成二值哈希码。最后利用生成的二值哈希码与原数据直接量化得到哈希码表进行比对进行跨模态检索
这篇关于Collective Affinity Learning for Partial Cross-Modal Hashing(CALM)--文献翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!