本文主要是介绍【力扣热题100】207. 课程表 python 拓扑排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【力扣热题100】207. 课程表 python 拓扑排序
- 写在最前面
- 207. 课程表
- 解决方案:判断是否可以完成所有课程的学习
- 方法:拓扑排序
- 实现步骤
- Python 实现
- 性能分析
- 结论
写在最前面
刷一道力扣热题100吧
难度中等
https://leetcode.cn/problems/course-schedule/?envType=study-plan-v2&envId=top-100-liked
207. 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 2000
0 <= prerequisites.length <= 5000
prerequisites[i].length == 2
0 <= ai, bi < numCourses
prerequisites[i] 中的所有课程对 互不相同
解决方案:判断是否可以完成所有课程的学习
本问题涉及到一个常见的图论问题,即检测有向图中是否存在循环。在这个场景中,课程可以被视为图的节点,而先修课程的要求可以被视为有向边。
我们的目标是:检查这个有向图是否包含一个循环。如果存在循环,意味着有些课程的先修要求彼此相互依赖,从而导致无法完成所有课程。
方法:拓扑排序
为了解决这个问题,我们可以使用拓扑排序。拓扑排序是一种对有向无环图(DAG)的顶点的线性排序,使得对于任何来自顶点 u 到顶点 v 的有向边,u 在排序中都出现在 v 之前。
如果我们在进行拓扑排序的过程中发现无法完成排序(即图中存在循环),那么就意味着无法完成所有课程的学习。
实现步骤
- 构建图:首先,我们需要构建图的表示。通常,这可以通过邻接表来实现。
- 计算入度:对于图中的每个节点(课程),计算进入该节点的边的数量,即该课程的先修课程数量。
- 初始化队列:创建一个队列,用于存放所有入度为0的节点(没有先修课程的课程)。
- 进行拓扑排序:
- 从队列中移除一个节点(课程),并将其添加到拓扑排序的结果中。
- 遍历从该节点出发的所有边,将与之相连的节点的入度减1。
- 如果某个相邻节点的入度变为0,则将其加入队列。
- 检查是否可以完成排序:如果排序的结果包含所有的课程,则返回 true;否则,返回 false。
Python 实现
下面是问题的 Python 实现,使用了拓扑排序的方法:
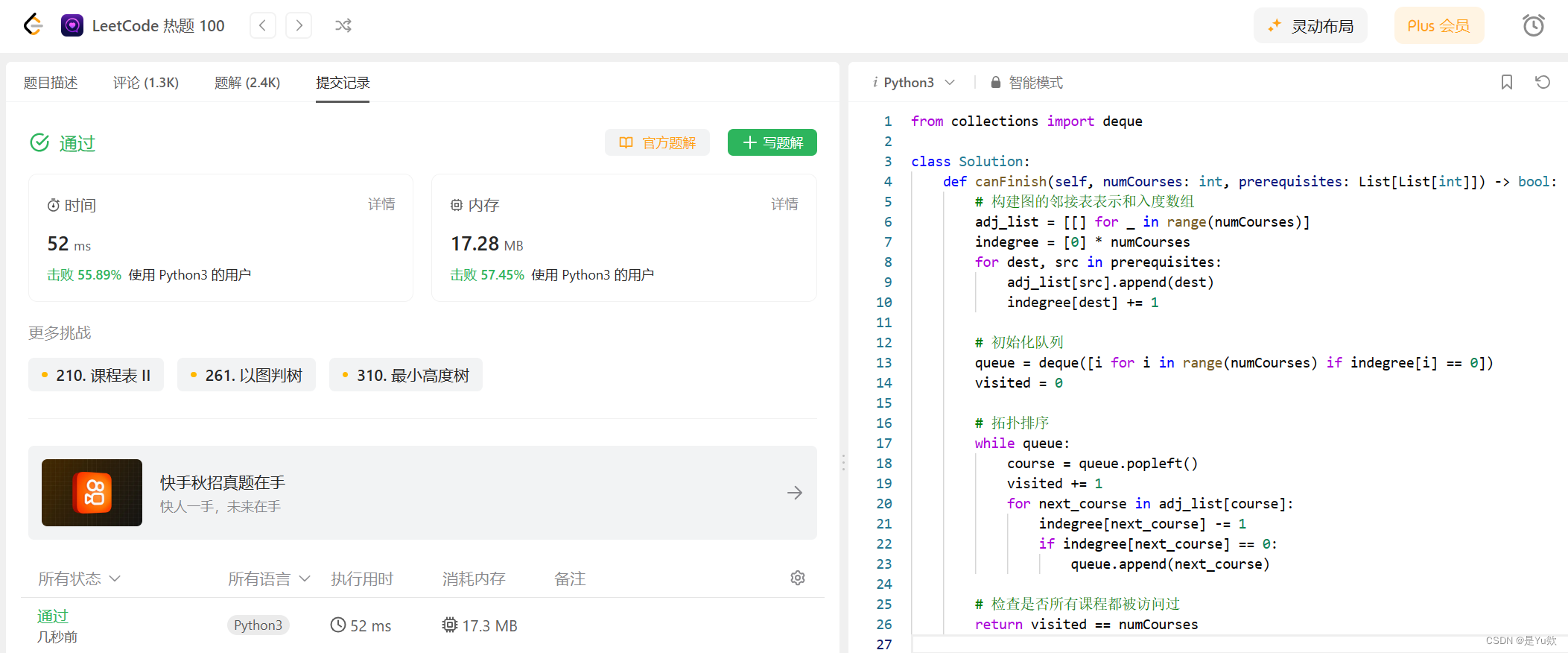
from collections import dequeclass Solution:def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:# 构建图的邻接表表示和入度数组adj_list = [[] for _ in range(numCourses)]indegree = [0] * numCoursesfor dest, src in prerequisites:adj_list[src].append(dest)indegree[dest] += 1# 初始化队列queue = deque([i for i in range(numCourses) if indegree[i] == 0])visited = 0# 拓扑排序while queue:course = queue.popleft()visited += 1for next_course in adj_list[course]:indegree[next_course] -= 1if indegree[next_course] == 0:queue.append(next_course)# 检查是否所有课程都被访问过return visited == numCourses
性能分析
- 时间复杂度:O(N + P),其中 N 是课程数量,P 是先修课程对的数量。
- 空间复杂度:O(N + P),用于存储图的邻接表和入度数组。
结论
使用拓扑排序,我们可以高效地确定是否可能完成所有课程的学习。
这种方法在计算机科学的许多领域,如任务调度、数据处理等,都有广泛的应用。
这篇关于【力扣热题100】207. 课程表 python 拓扑排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






