本文主要是介绍2023Q4 私有化版本发布,和鲸 ModelWhale 持续赋能大科研、高校教改的 AI for Science,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为数据科学多人协同平台,和鲸 ModelWhale 从一而终地为各级用户提供完备而周全的解决方案,覆盖数据研究、算法探索、模型调优、Python 案例教学等多个场景。特别地,如果对研究分析平台有更高的安全合规要求、希望兼容原有业务系统(比如已有的服务器资源、数据平台等)、或者有其他定制化需求,我们建议采买 ModelWhale 私有化独立部署服务:支持定制化解决方案设计、独立产品功能开发、专属的客户成功系列服务等。
2023Q4 私有化部署版本,已顺利通过公测并将于近期部署到客户环境中。本季度主要进行了以下迭代:
- 硬件分析环境:新增 算力节点池,支持算力独享、按需跨部门共享的调度策略
- 软件分析环境:新增 使用 API 接入数据、常用分析软件及模板接入
- 科研:AI4S 大科研探索分析能力拓展,包括:大模型开发训练、复杂任务编排、算法封装交付
- 高校:Python 案例实训教学(OBE)能力拓展,新增 分组作业、老师-学生视角切换、优化结课存档
- 更规范的资产管理:优化 元数据及 DOI 管理(FAIR 原则),新增 门户内容公开申请、优化 资产搜索查询
- 更便捷的账号迁移(已有第三方用户系统打通、免登录)、更丰富的开放接口、支持国际化多语言(中/英)切换
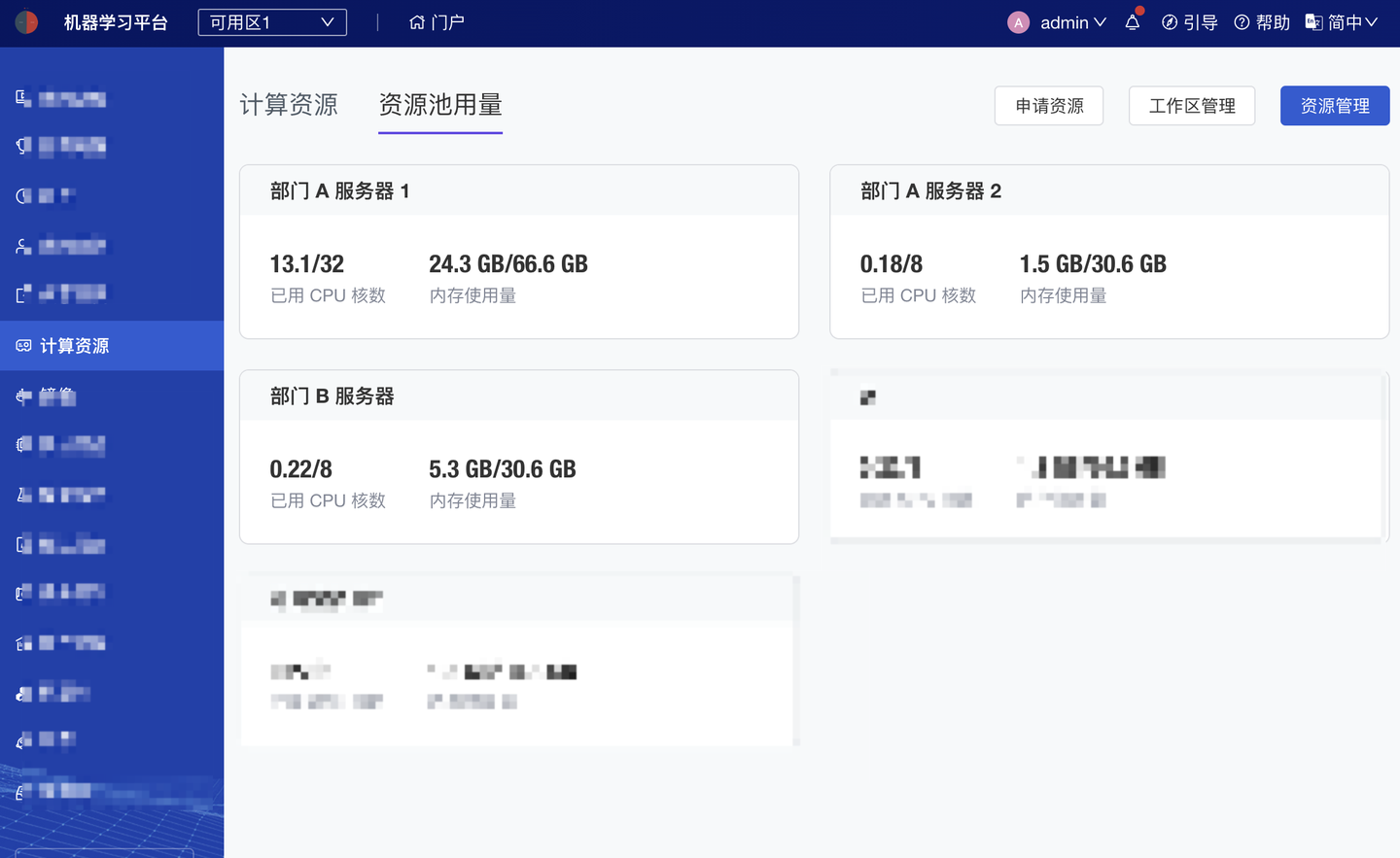
一、硬件分析环境管理:新增 算力节点池,支持算力独享、按需跨部门共享的调度策略
组织内顺畅的开放协同、合力研究,需要统一的分析平台进行资源及成果共享。而算力方面,在更开放的协作场景,部门间的算力“相互支援、按需调度”,可以实现更充分的算力利用、释放研发效能。平台现已支持将不同部门的机器构成不同的节点池(资源池);用户启用算力时,平台会依据优先级策略调度算力:独立(非共享)节点池 > 共享节点池。
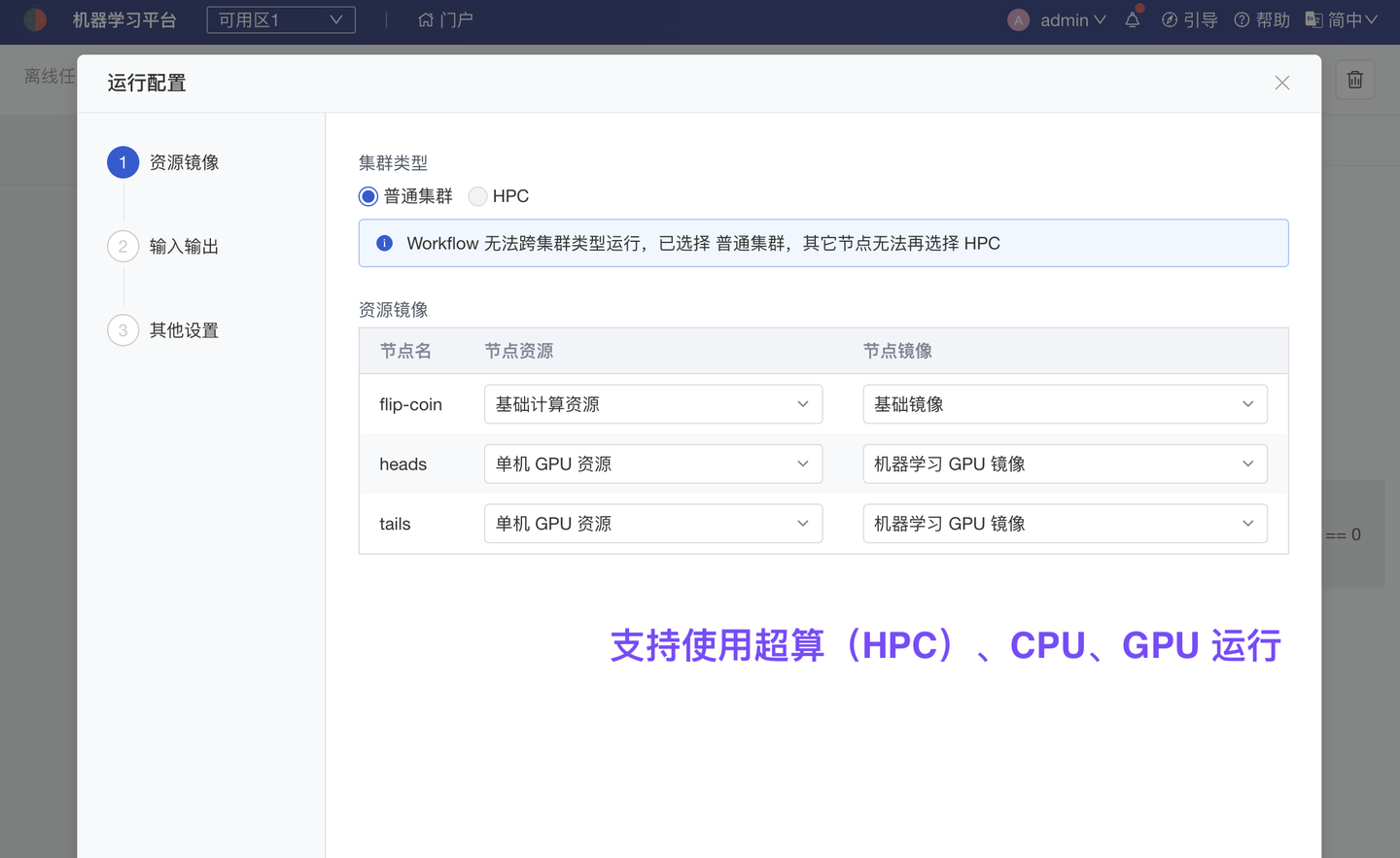
而在不同节点池下,平台支持接入超算集群(HPC)、GPU 集群、普通 GPU 及 CPU,实现比本地更细颗粒的算力分配使用、监控管理、伸缩调度。
算力节点池监控
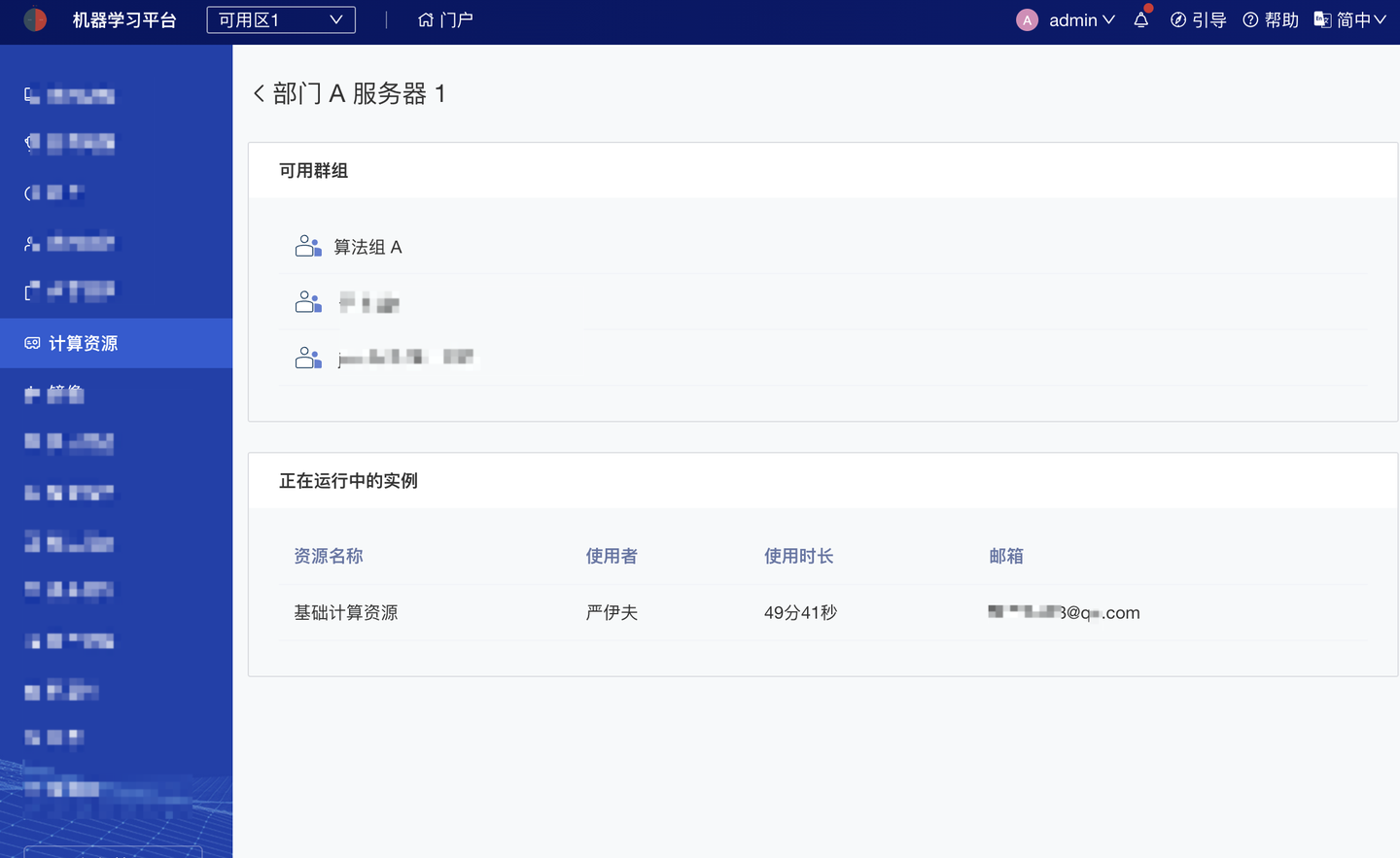
超算集群(HPC)使用
二、软件分析环境:新增 API 数据接入、常用分析软件及模板接入
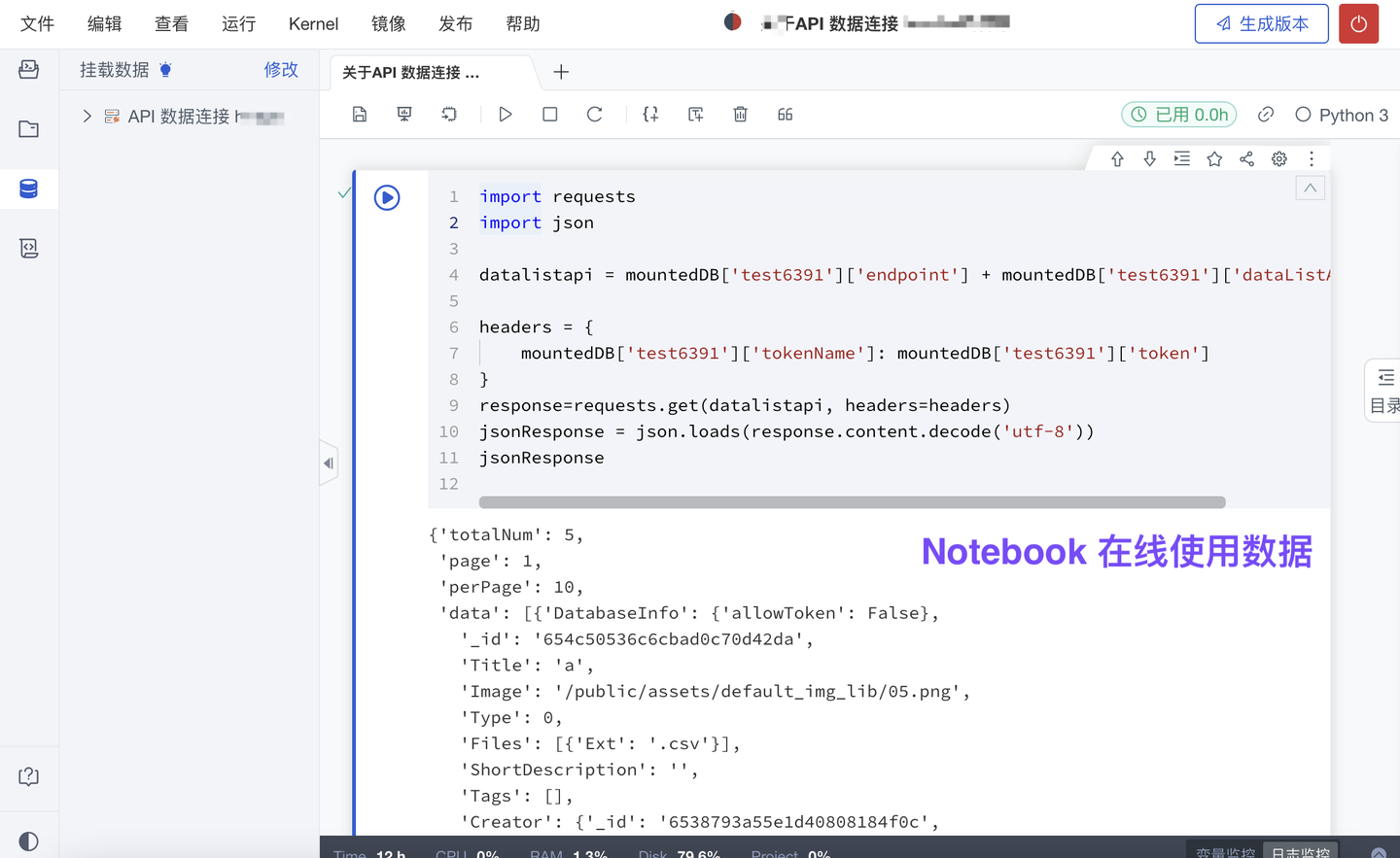
1、新增 API 数据连接,继承原有第三方系统权限管控
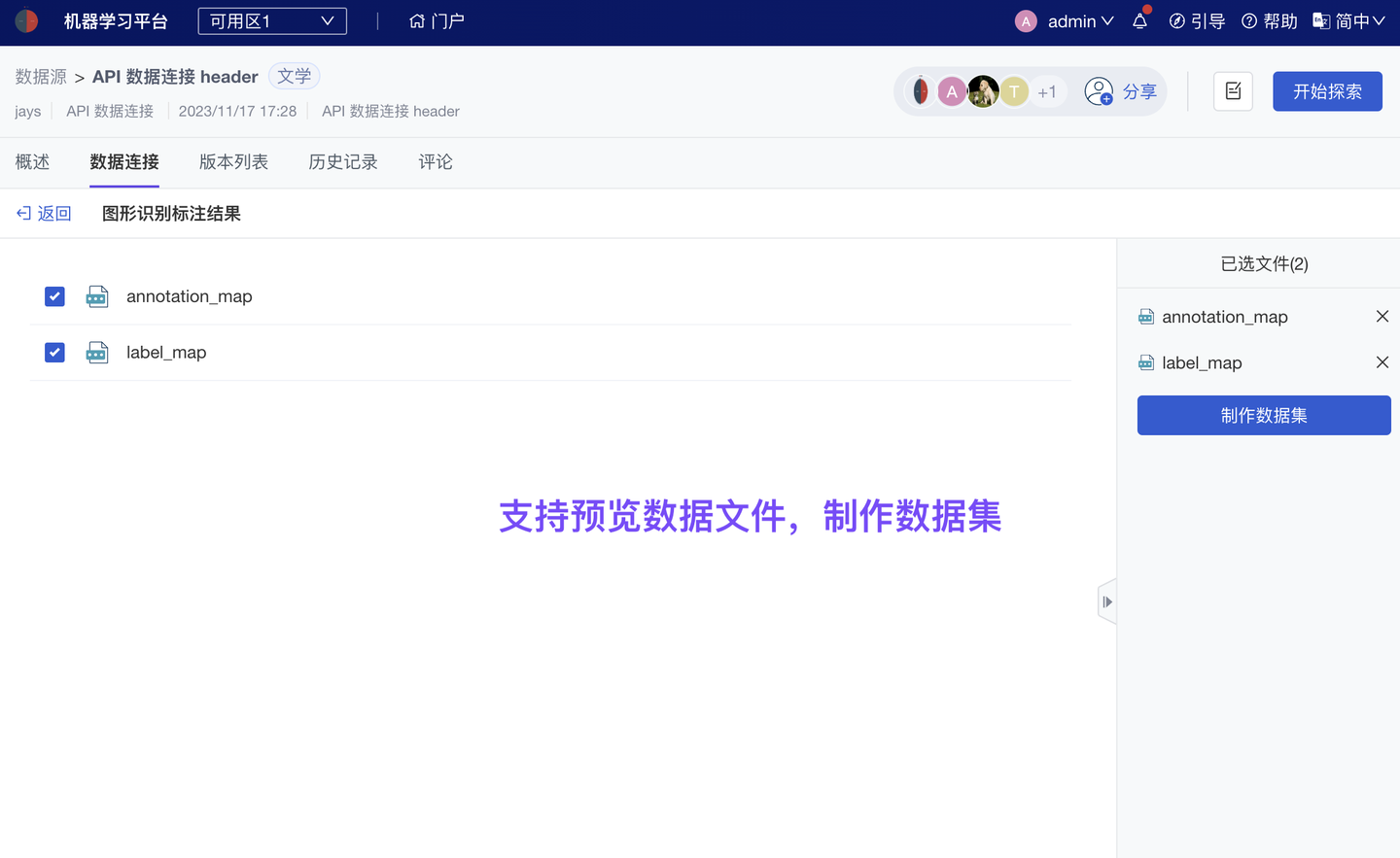
平台支持多种数据源的接入和使用,包括:关键数据成果(数据集)、研究源数据(NAS 数据源、Vertica 及其他常用数据库、对象存储)、其他第三方存储数据(服务接口调用、API 数据连接)、大模型 Common Data(超算自有存储)。
如果数据存储在“第三方系统”并已有一套严格的数据使用权限设计,平台支持继承已有权限管控:原有权限不会失效,亦无需在分析平台再次配置权限。只需填写由该第三方系统提供的 API 配置,即可在平台实现对这些数据产品的调用分析。
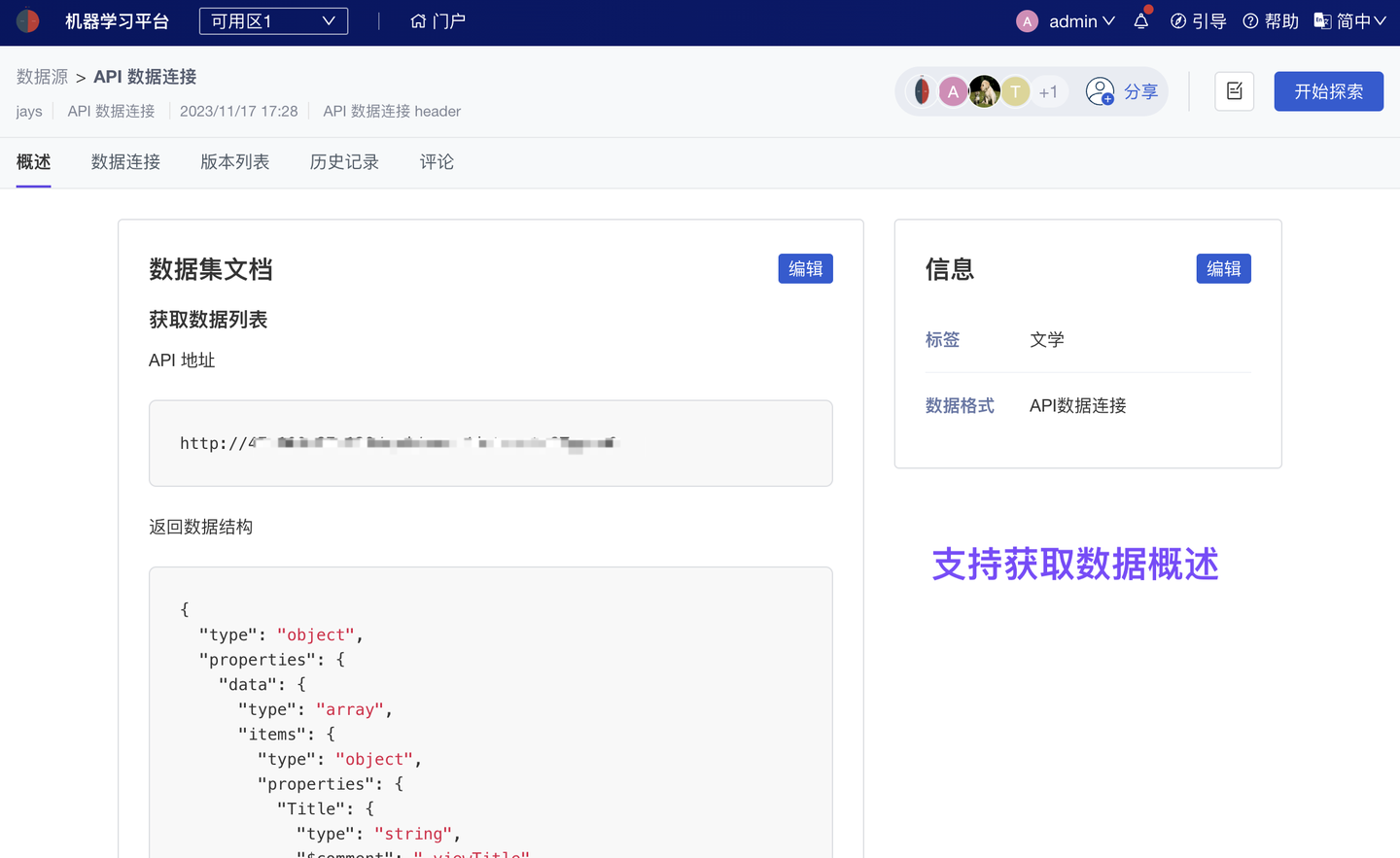
2、新增 常用分析软件、研究框架丝滑迁移
本地常用的分析软件、分析框架、团队内标准的 SOP 工作流,均已支持迁移到平台使用。
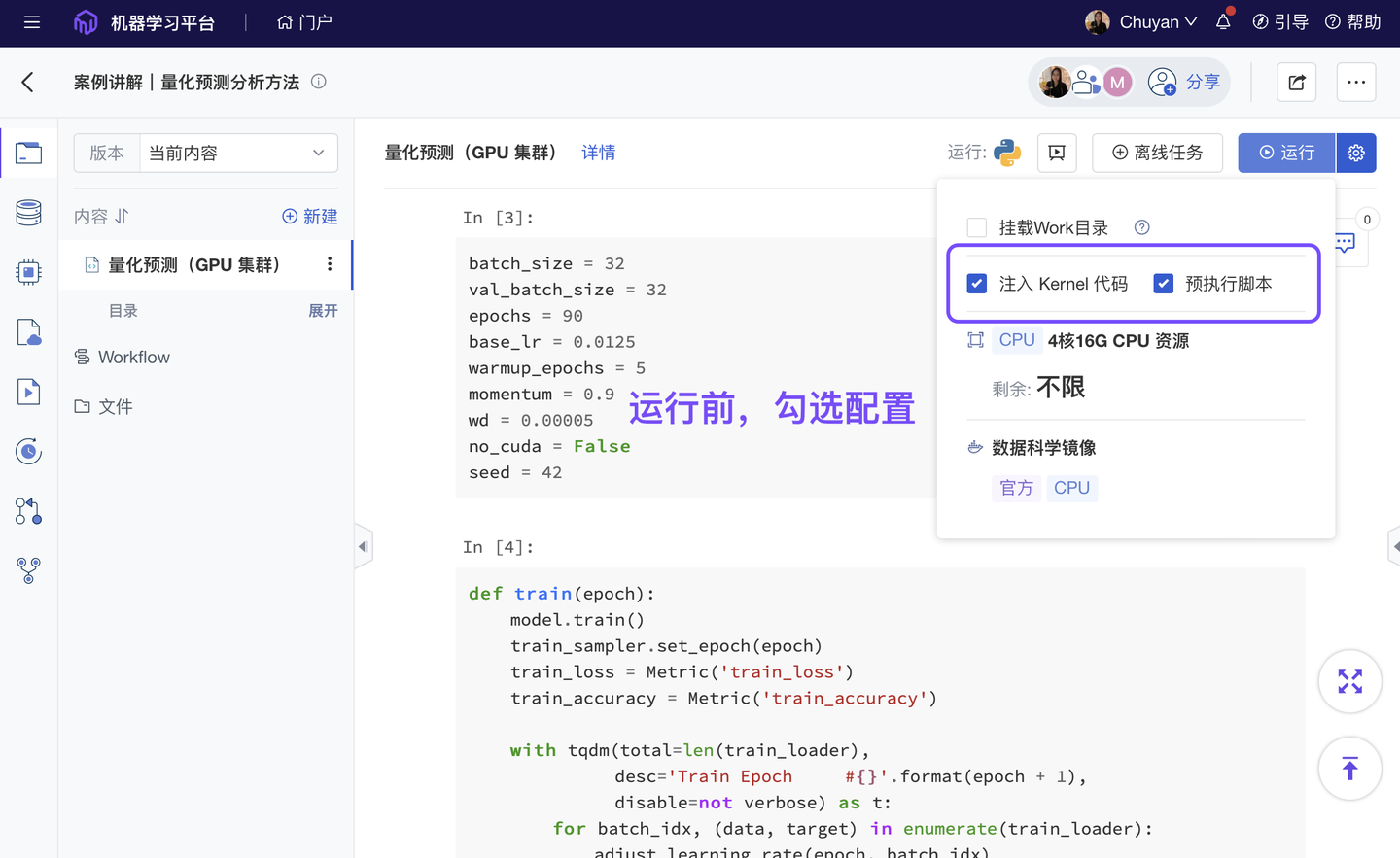
- 新增 软件仓库:支持在平台 Notebook 在线调用本地常用的 Python 库、可执行程序及其他软件。
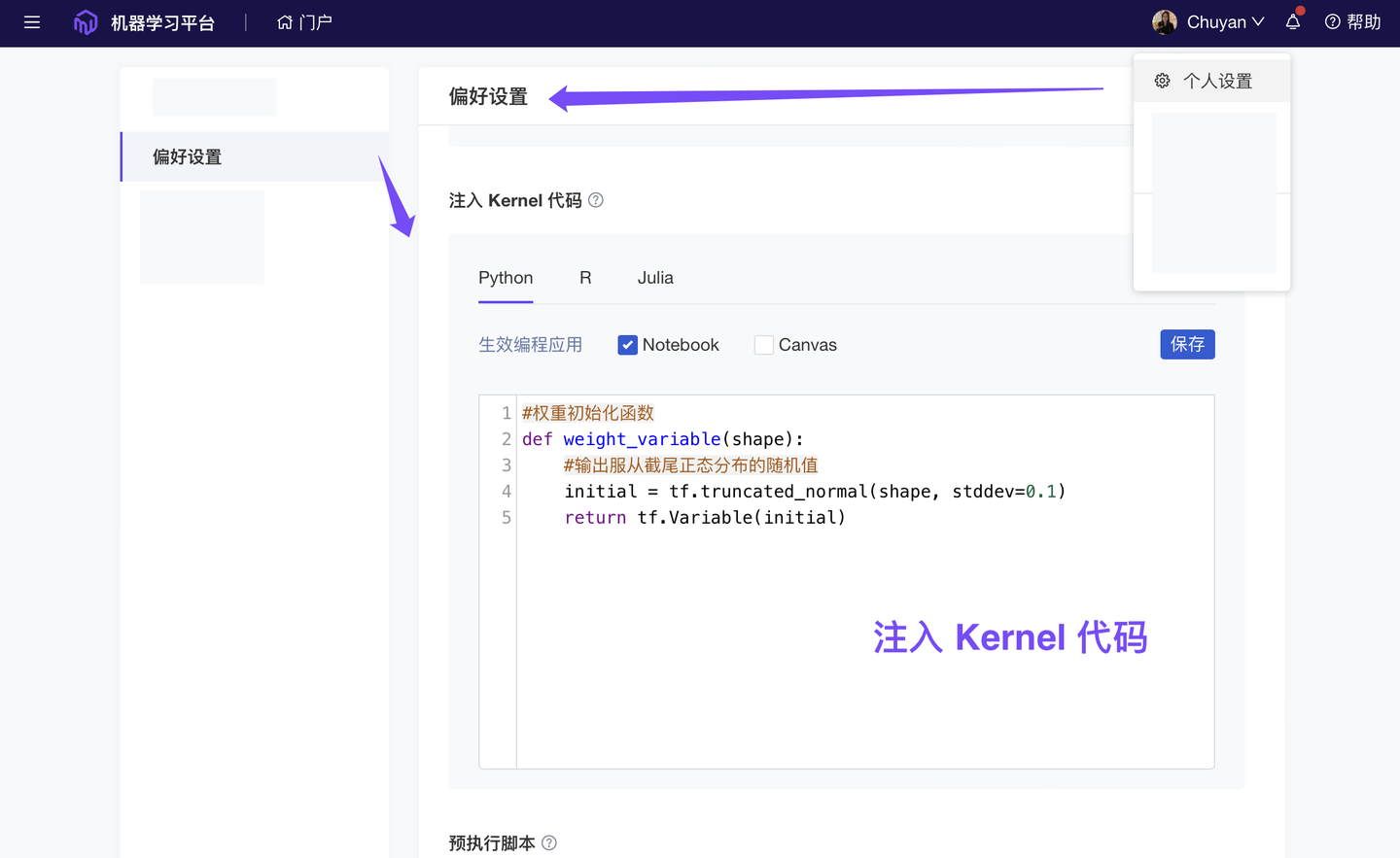
- 新增 预注入代码、脚本:支持在数据分析前预加载某些工具库、分析代码、文件,或者提前注入环境变量、shell 指令,快捷构建所需研究环境。
- 优化 分析模板复用:团队内标准的 SOP 工作流(如分析框架模板、研究报告模板、数据处理模板),可以在团队内分发共享,避免重复造轮,提高生产效率。


三、科研:AI4S 大科研探索分析能力拓展
1、“模型开发 - 训练 - 部署 - 运维”能力提升
大模型(如 LLM)的开发训练对算力、存储、分析工具、多人协作工具均提出了较高要求,平台拥有适用于模型“开发 - 训练 - 部署 - 运维”的全流程基础设施,可帮助工程师、科学家们更好地进行大模型开发训练、多人协同研究以及其他 AI for Science 分析探索。

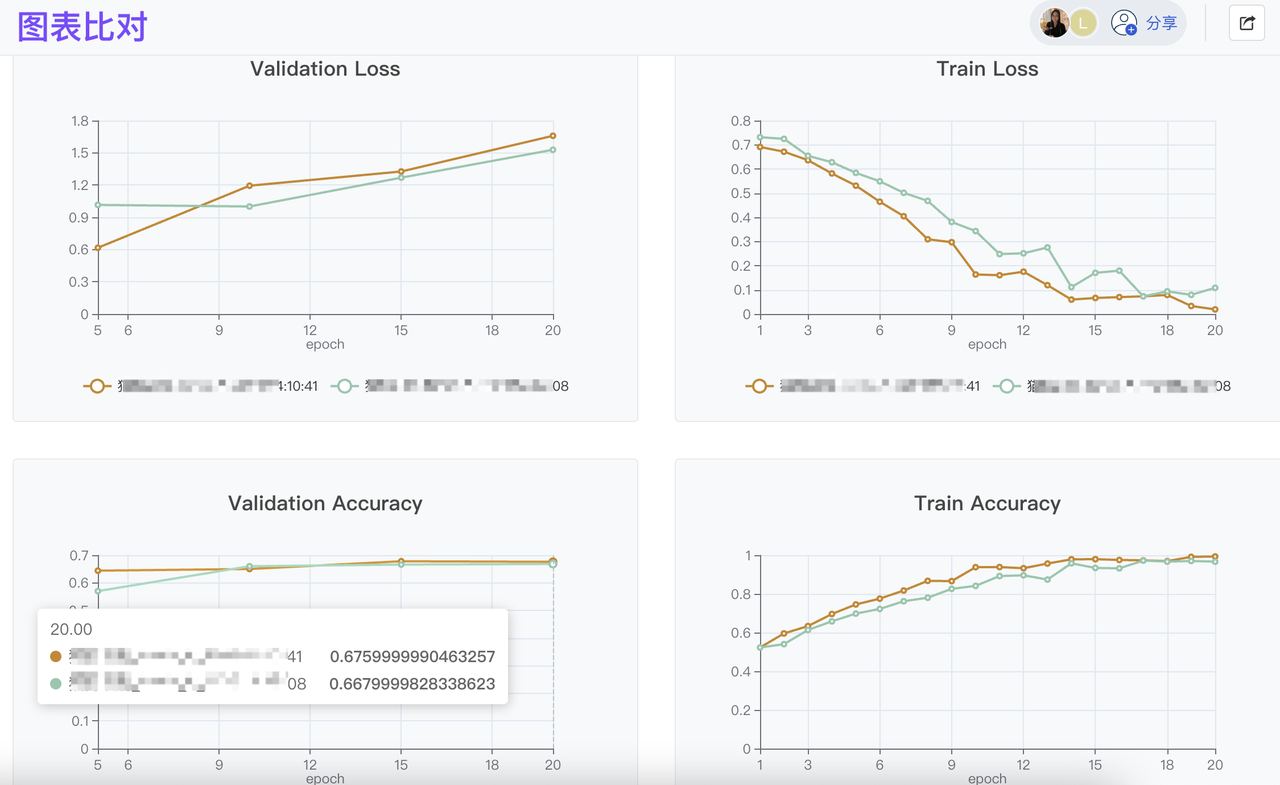
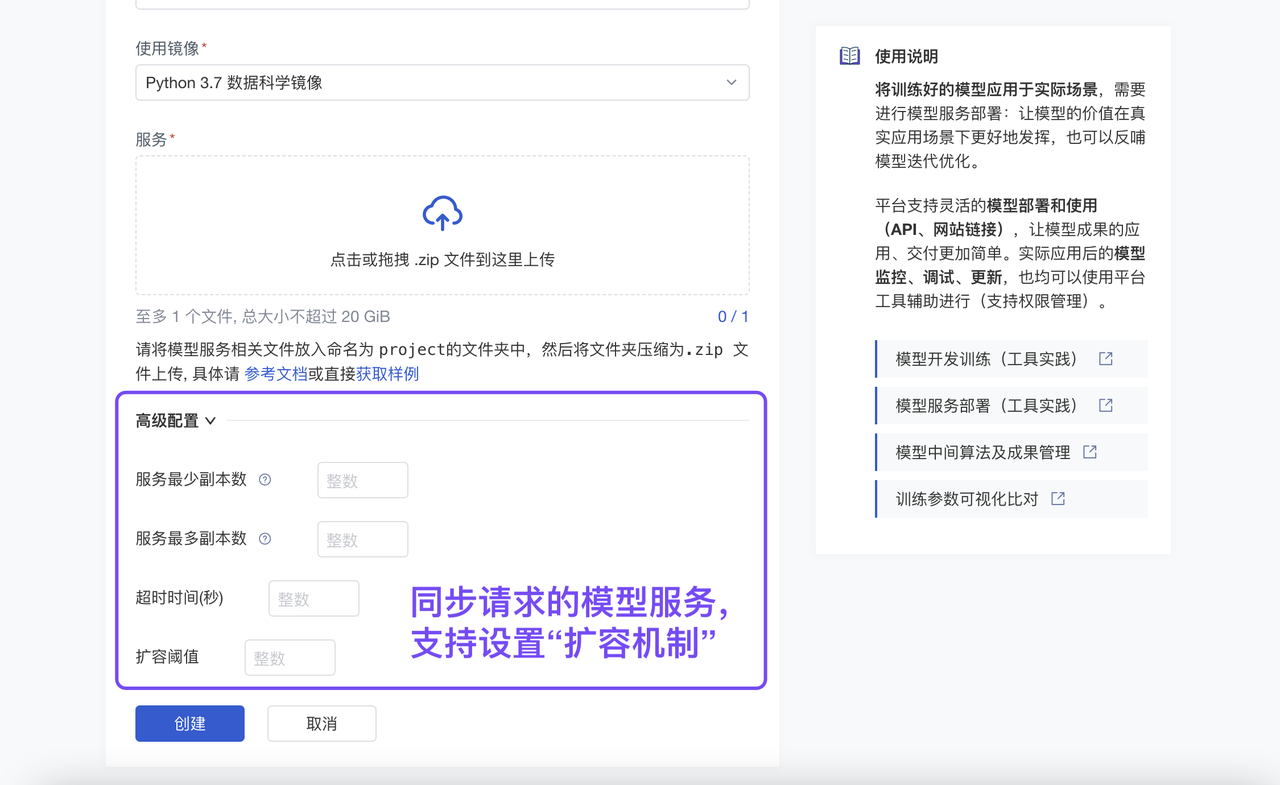
模型开发训练阶段,平台提供训练过程记录(Tracking)及可视化比对分析,同时兼容 MLFlow,全面协力模型参数的尝试与调整、最优结果记录及部署;服务调用环节,支持灵活的同步/异步请求以及精细的算力扩容管理;平台的模型运维监控系统,提供你详细的模型调用记录、算力使用追踪,以便调整运行策略(扩容/回收)、二次调优模型。
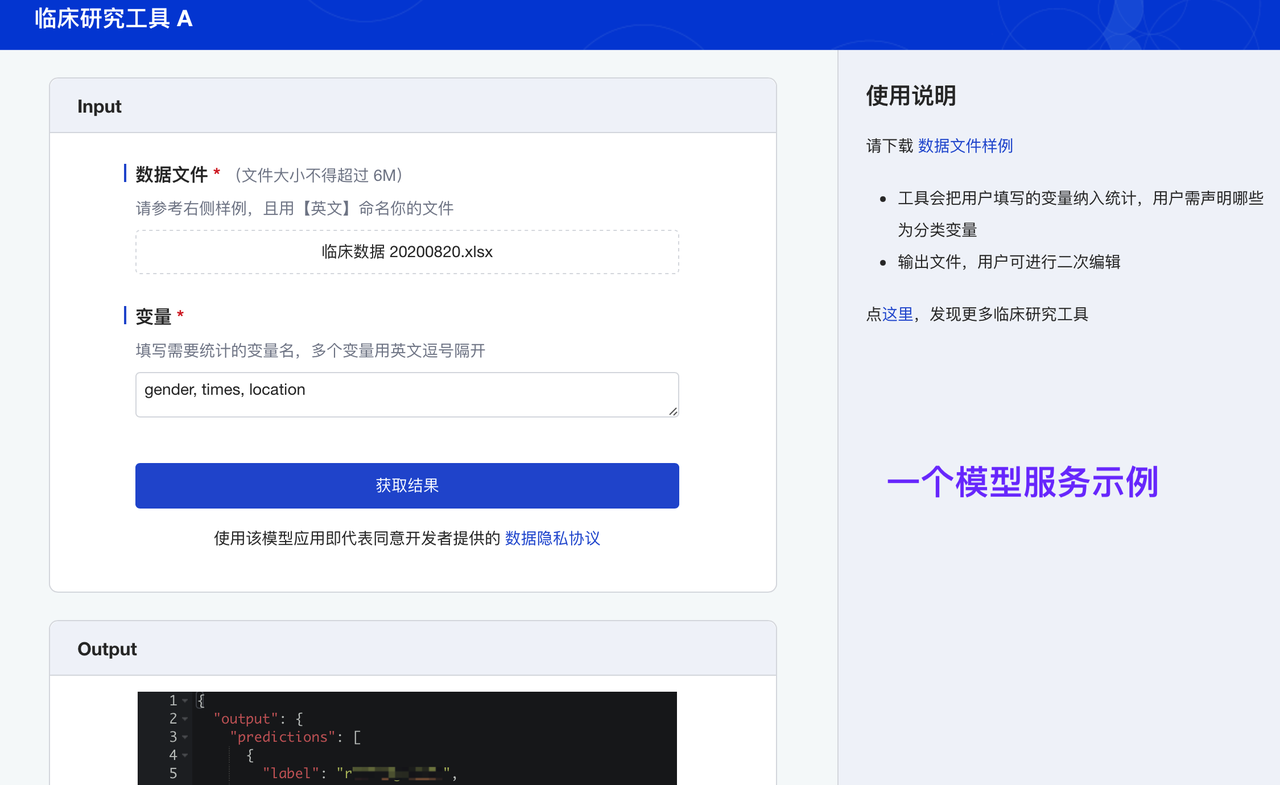
平台也支持开源预训练模型的快捷部署(如 Github 上的 gradio 项目),供大家便捷体验模型使用效果。

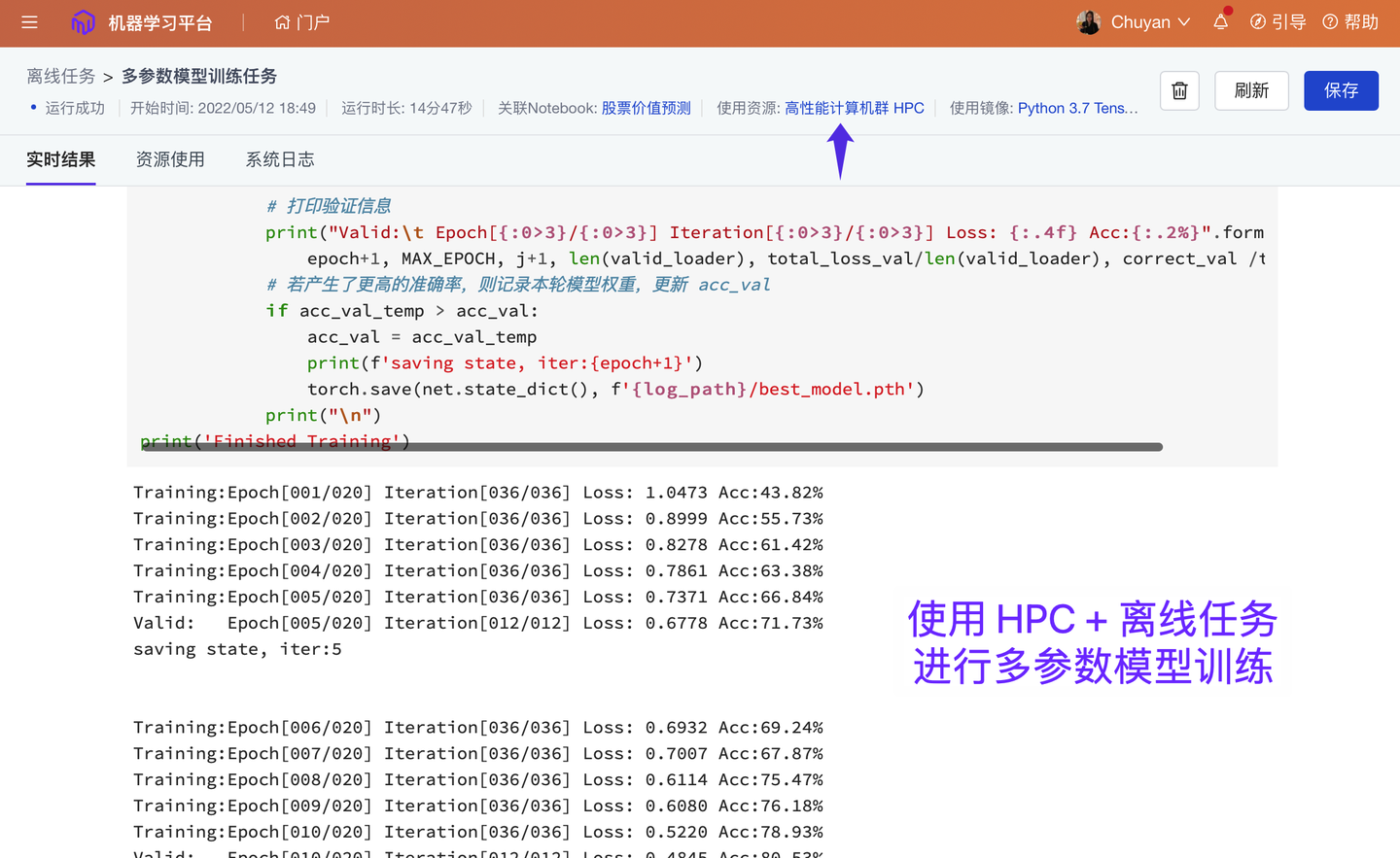
2、“复杂任务的编排、运行”能力提升(新模块 ✓)
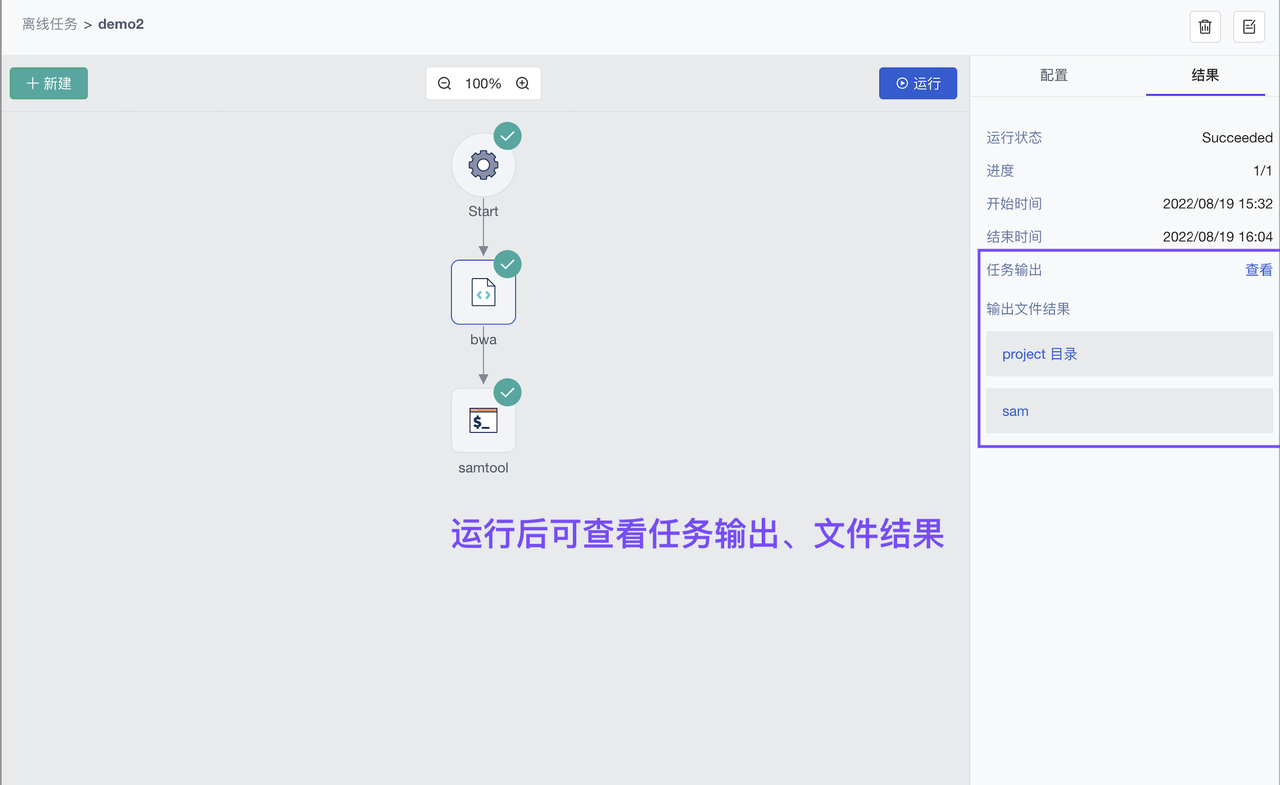
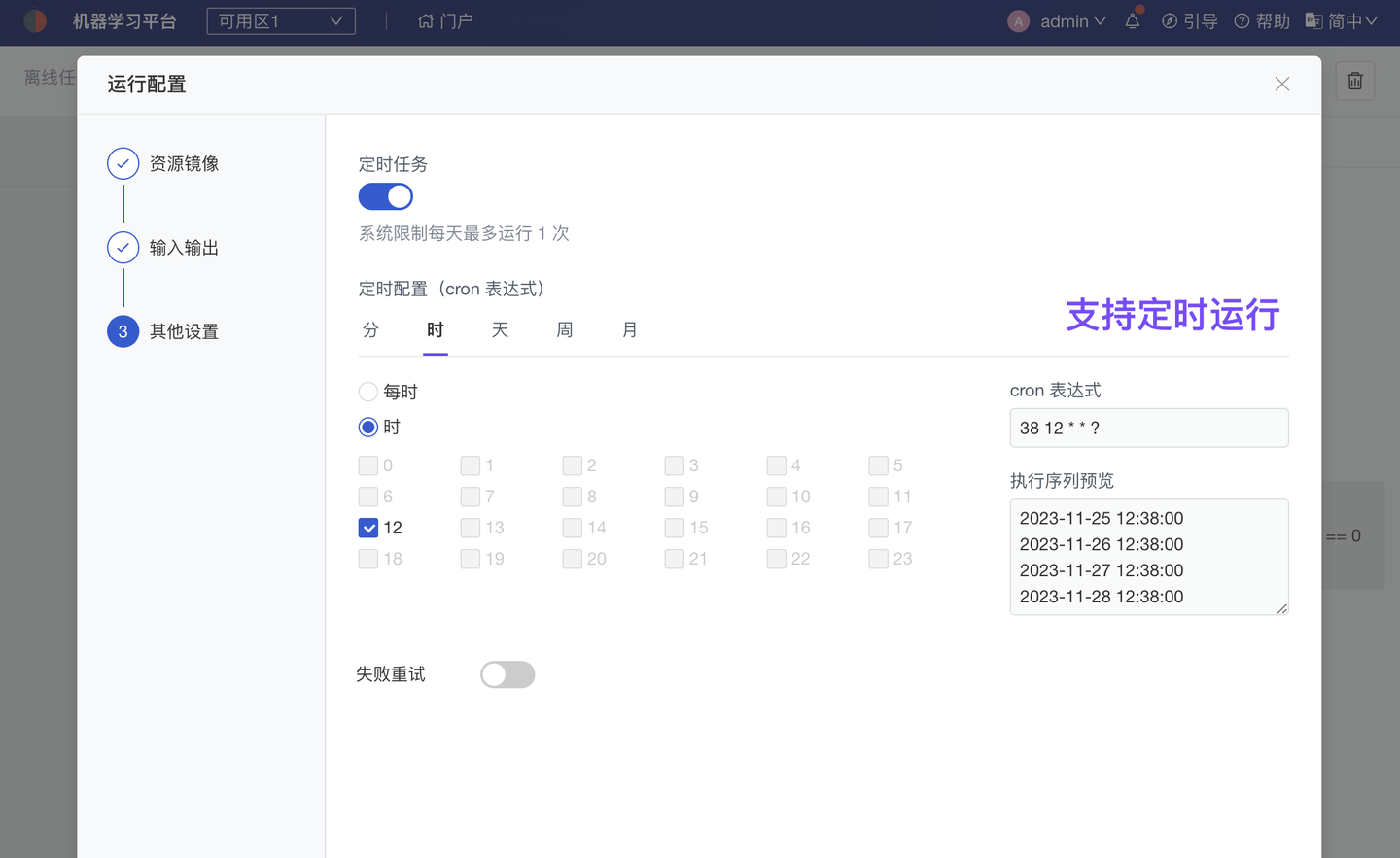
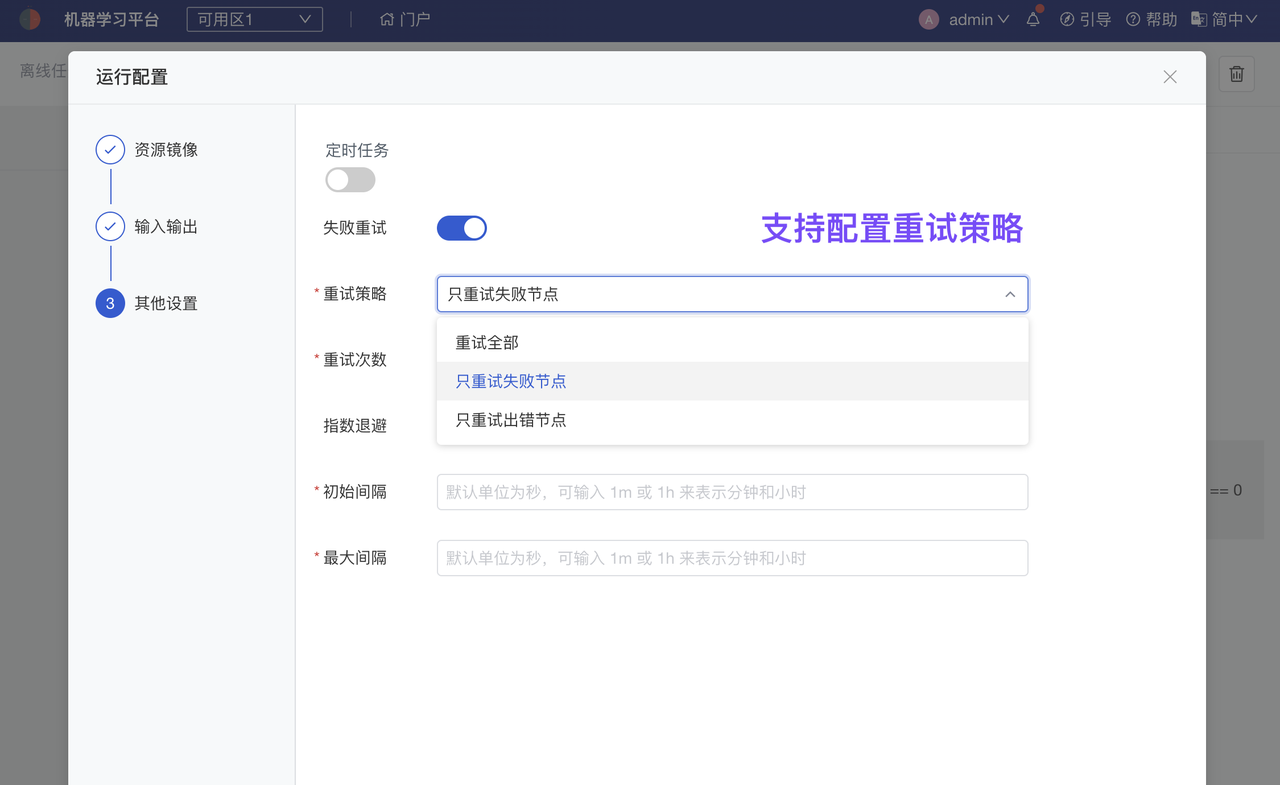
大小模型结合或多节点复杂任务,建议使用平台 Workflow 进行任务编排、并行计算。Workflow 任务节点支持 Notebook、Bash 脚本、Python 脚本、R 脚本多种类型;同时支持使用超算集群、GPU集群、GPU、CPU 组合运算,以及配置定时运行策略、结果重试策略。
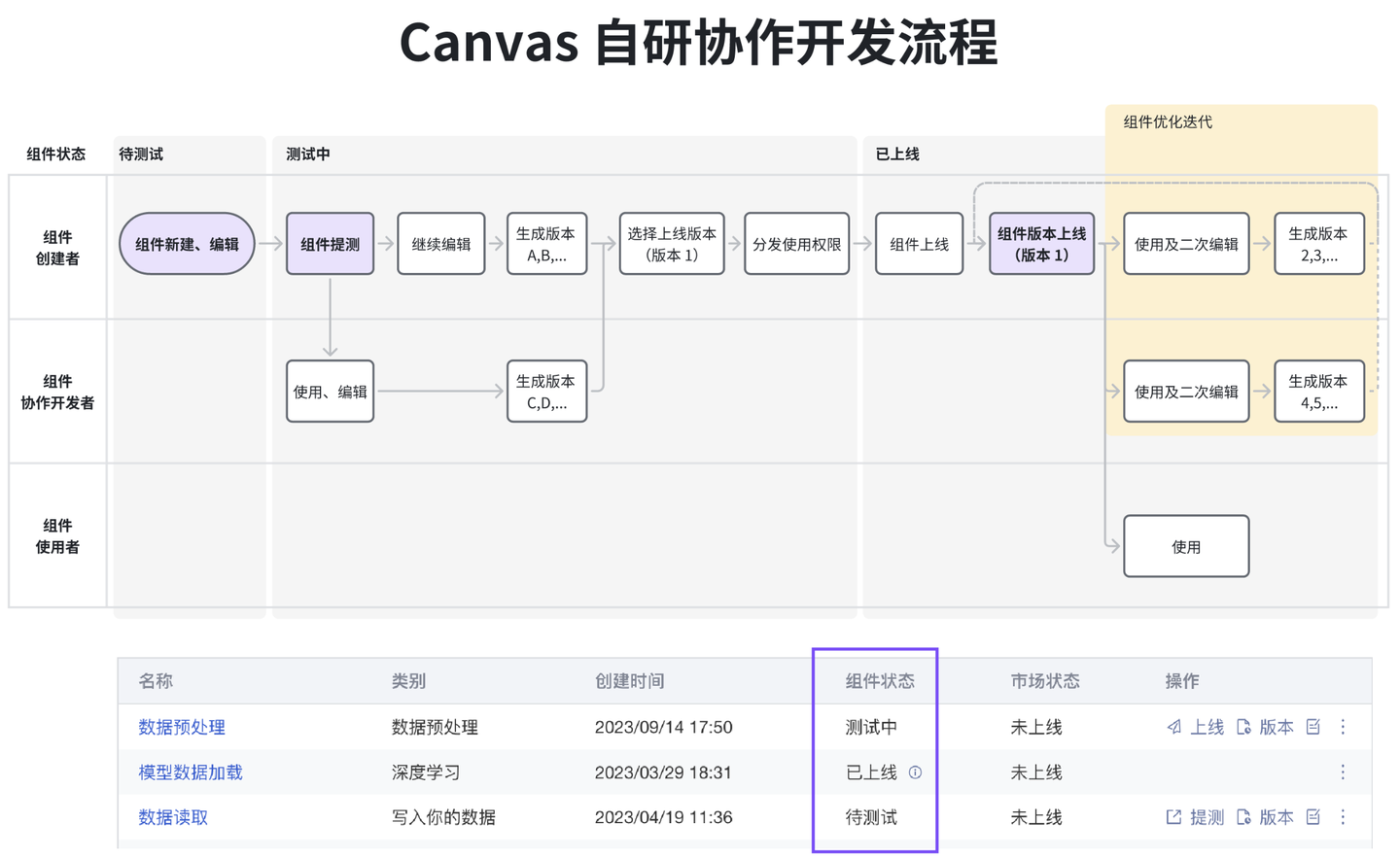
3、“多人算法开发 - 成果封装复用”能力提升
平台 Canvas 拥有 “算法封装”+“算法快捷使用” 能力,组织内算法工程师可以【自研 Canvas 组件】封装代码,【分发 Canvas 分析模板】供组织成员直接使用、快速搭建研究框架、低代码完成数据分析工作。本季度我们对“Canvas 多人自研开发流程”进行了升级迭代:开发流程更规范、开发权限更清爽、组件使用更便捷。

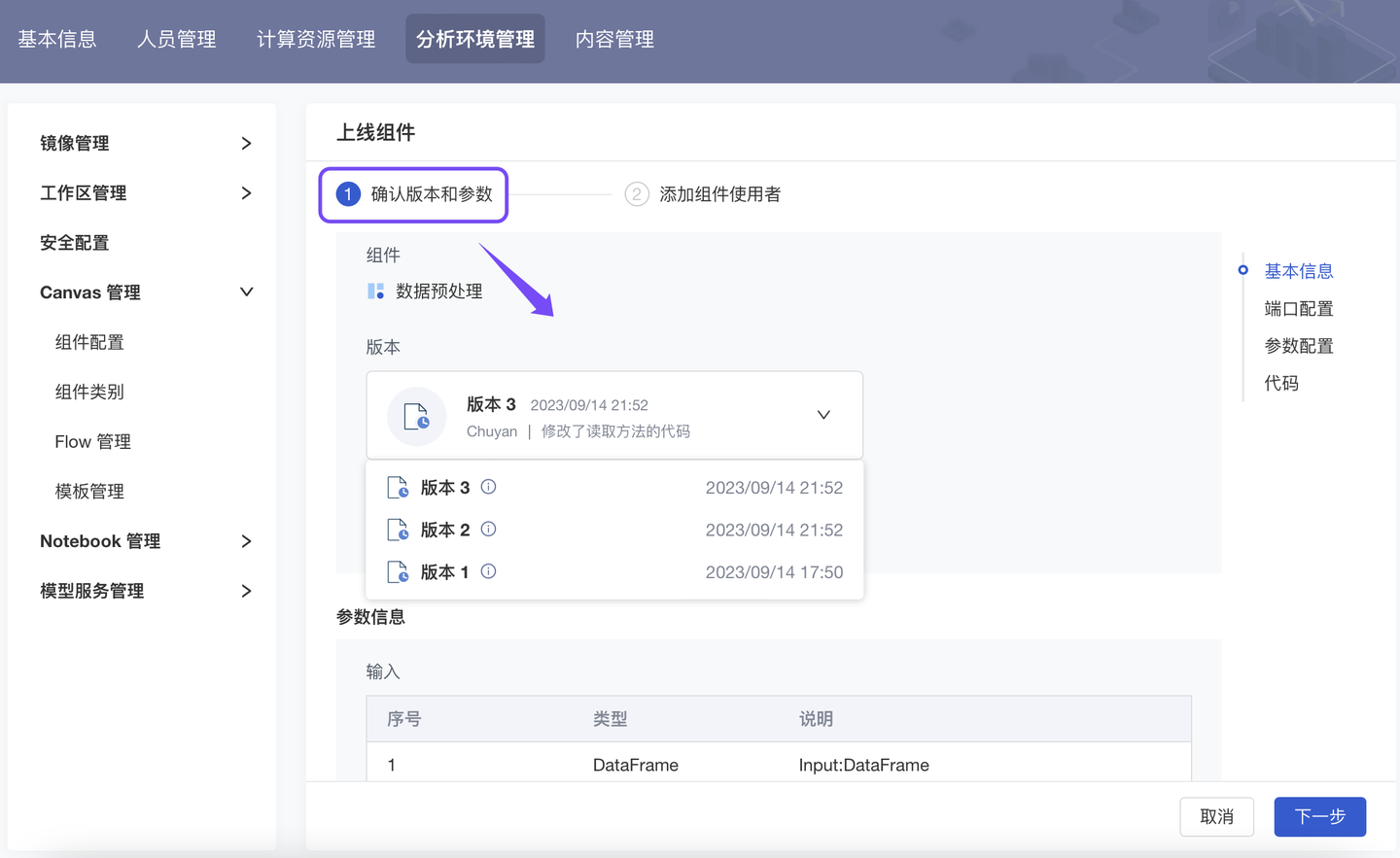
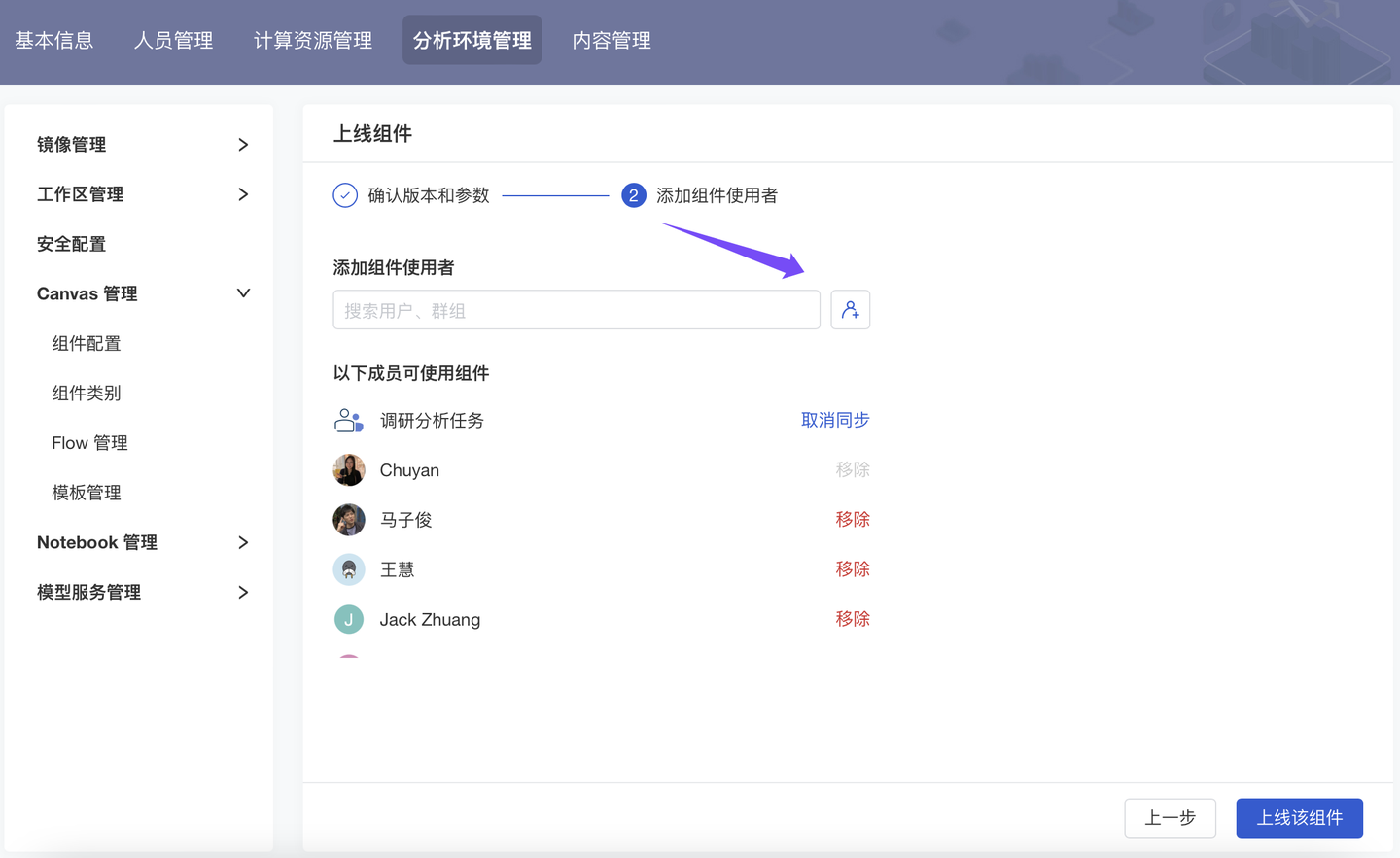
四、高校:Python 案例实训教学(OBE)能力拓展
为促进高校教改,依据 OBE 成果导向的教育模式,平台帮助学生真实 Coding、快速理解数据科学方法、逐步形成数据科学思维。老师可以调用平台丰富的案例教材、教学工具,设计实践作业、分组作业、自动评审作业等,构建案例实训教学课程。教学平台本季度新增:
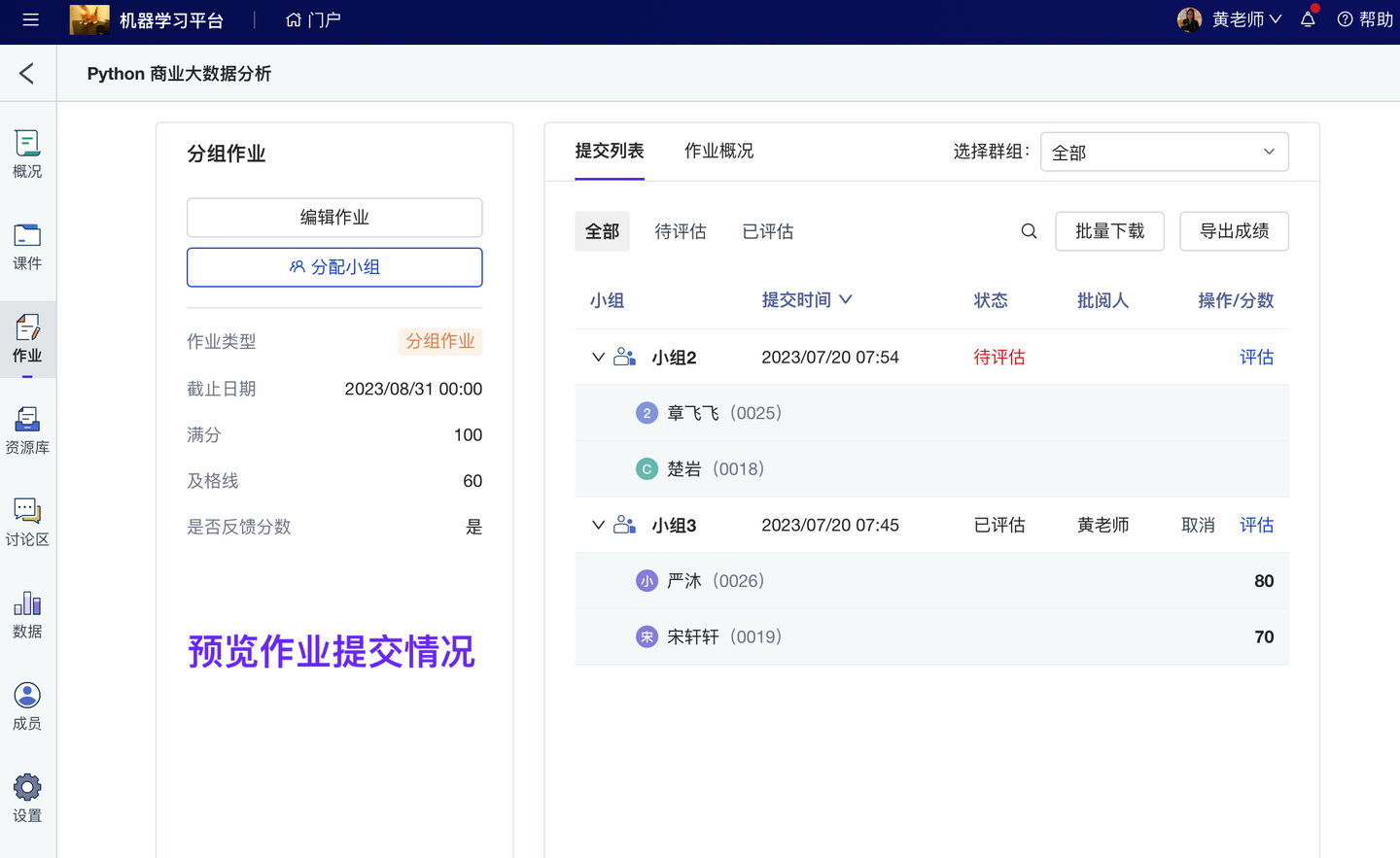
- 分组作业:支持区分小组得分/个人得分、批量设置/管理小组、作业在线预览评审、作业导出留存。
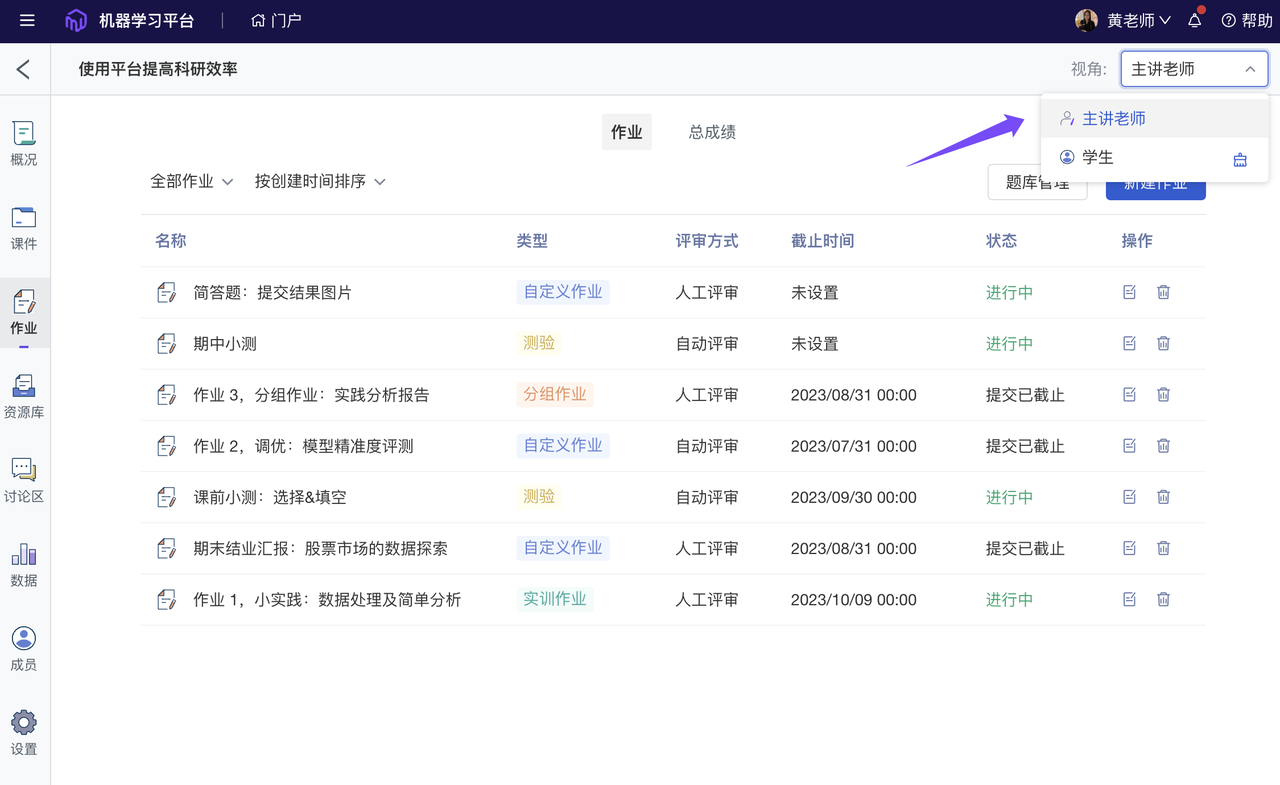
- “老师-学生”视角切换:老师可以随时检查课程展示是否符合预期,及时调整教学策略。
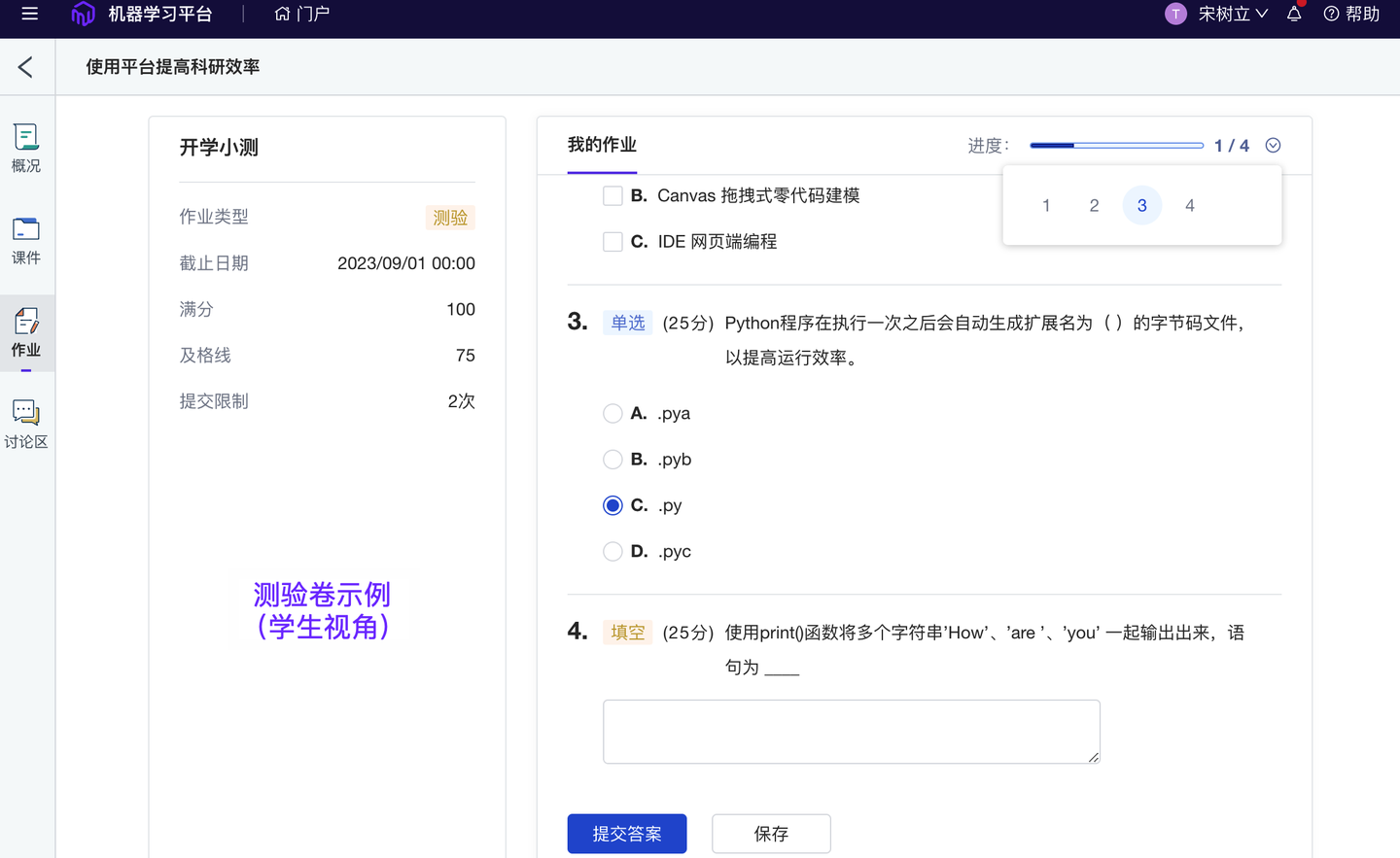
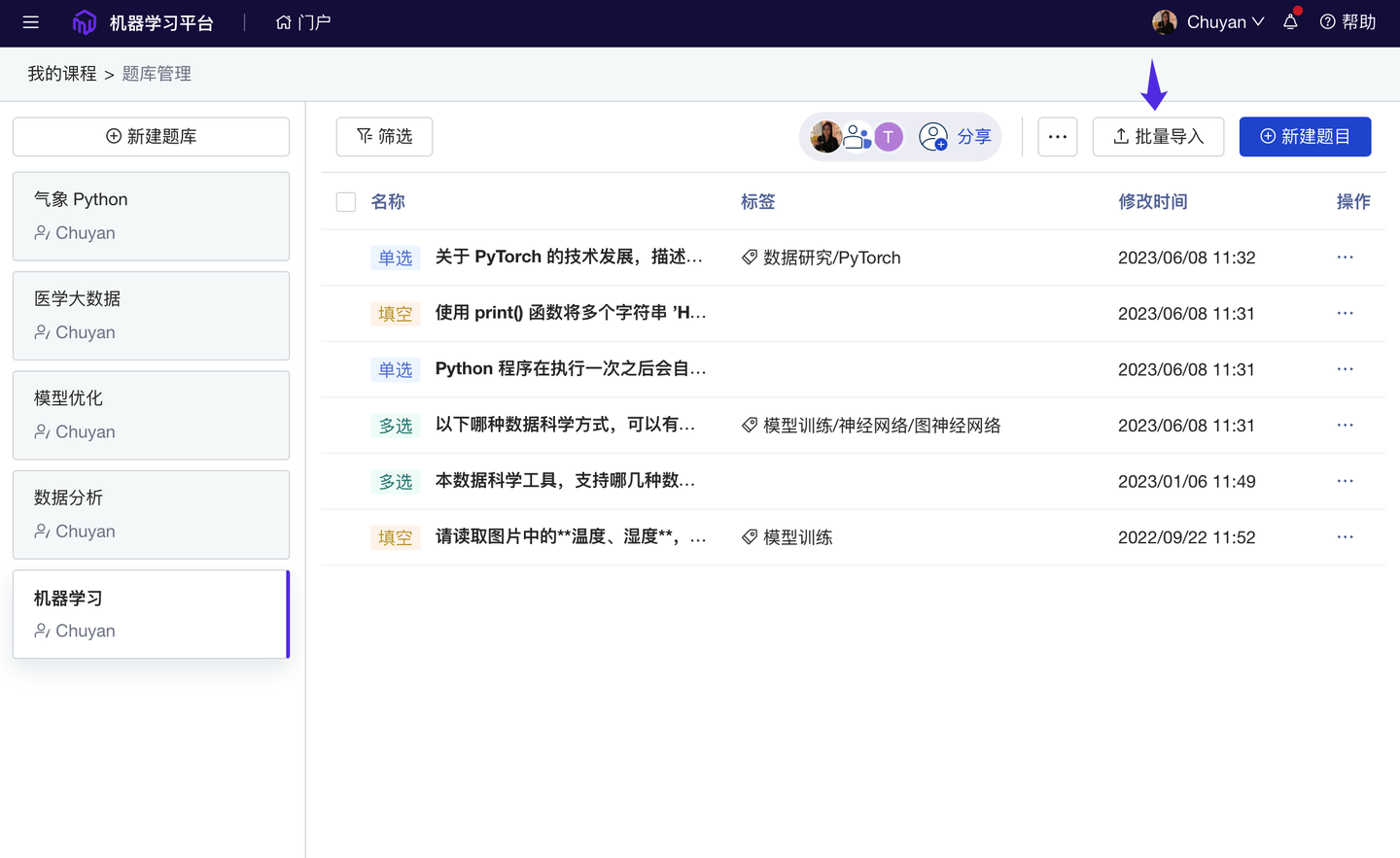
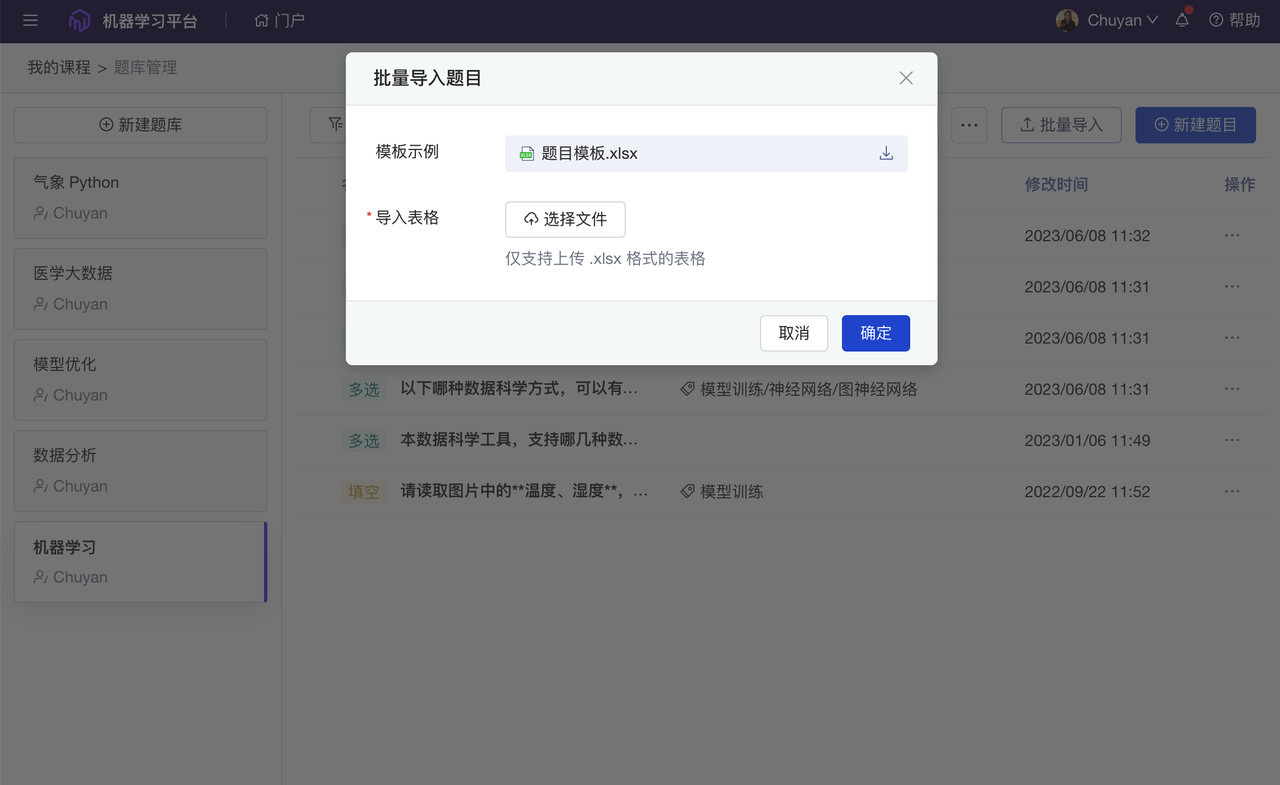
- 测验题批量上传至课程题库:更方便“课题组”迁移教学内容和“老师”复用调整。
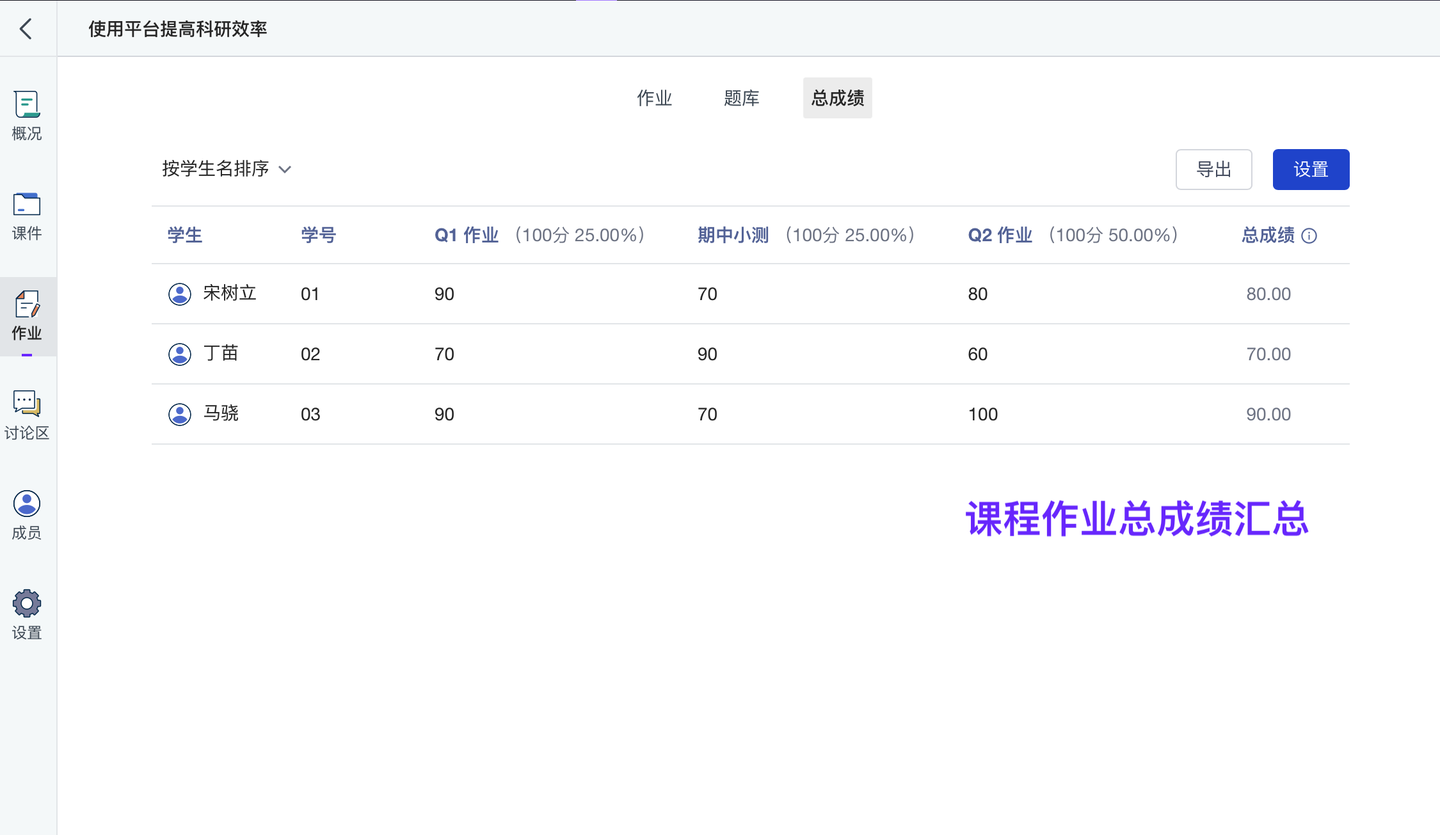
- 也优化了结课存档相关设施,如:分作业权重配置及总成绩计算导出、课程归档、课程复用等。
分组作业


“老师-学生”视角切换


测验题批量上传(至课程题库)
结课存档

五、更规范的资产管理
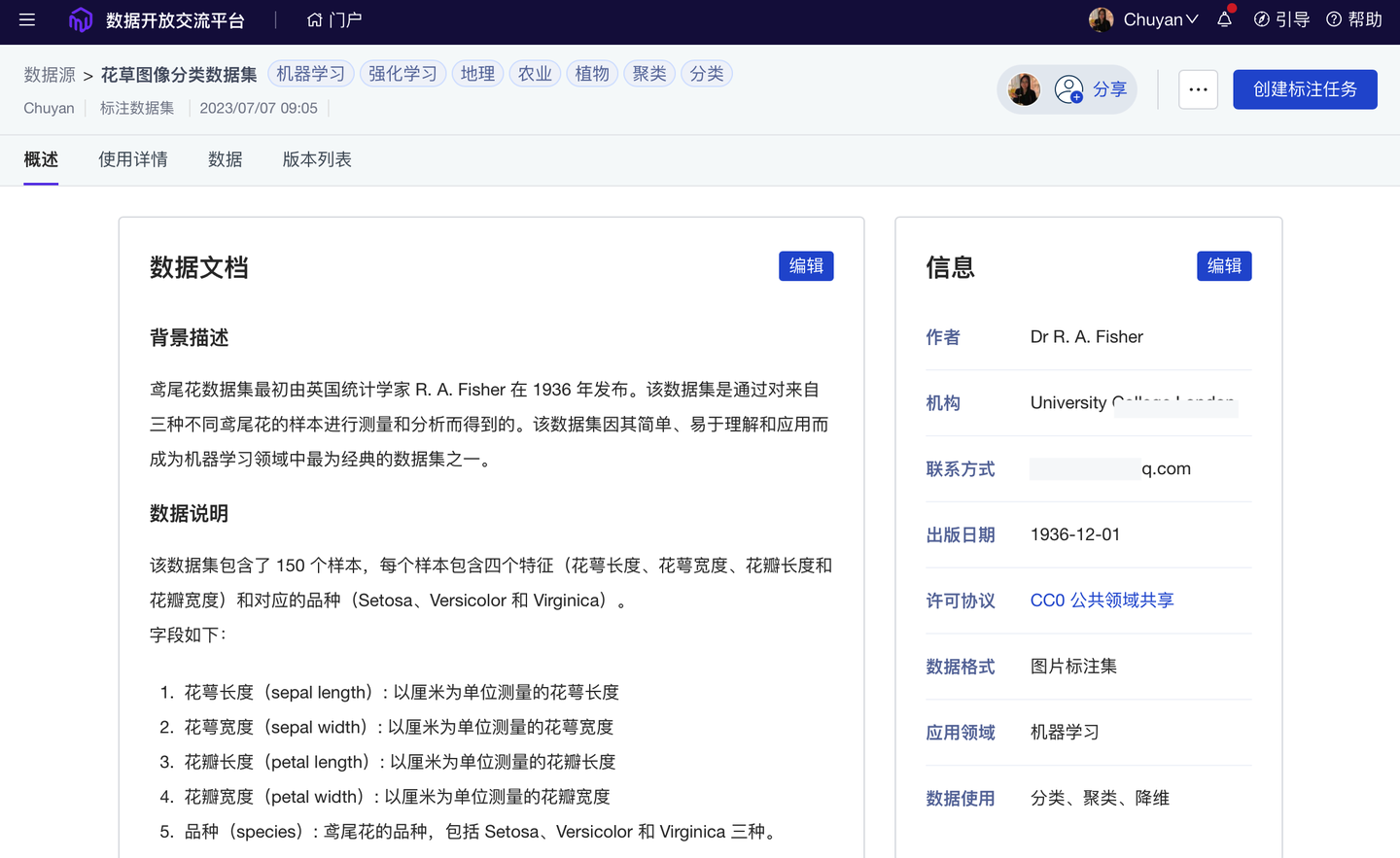
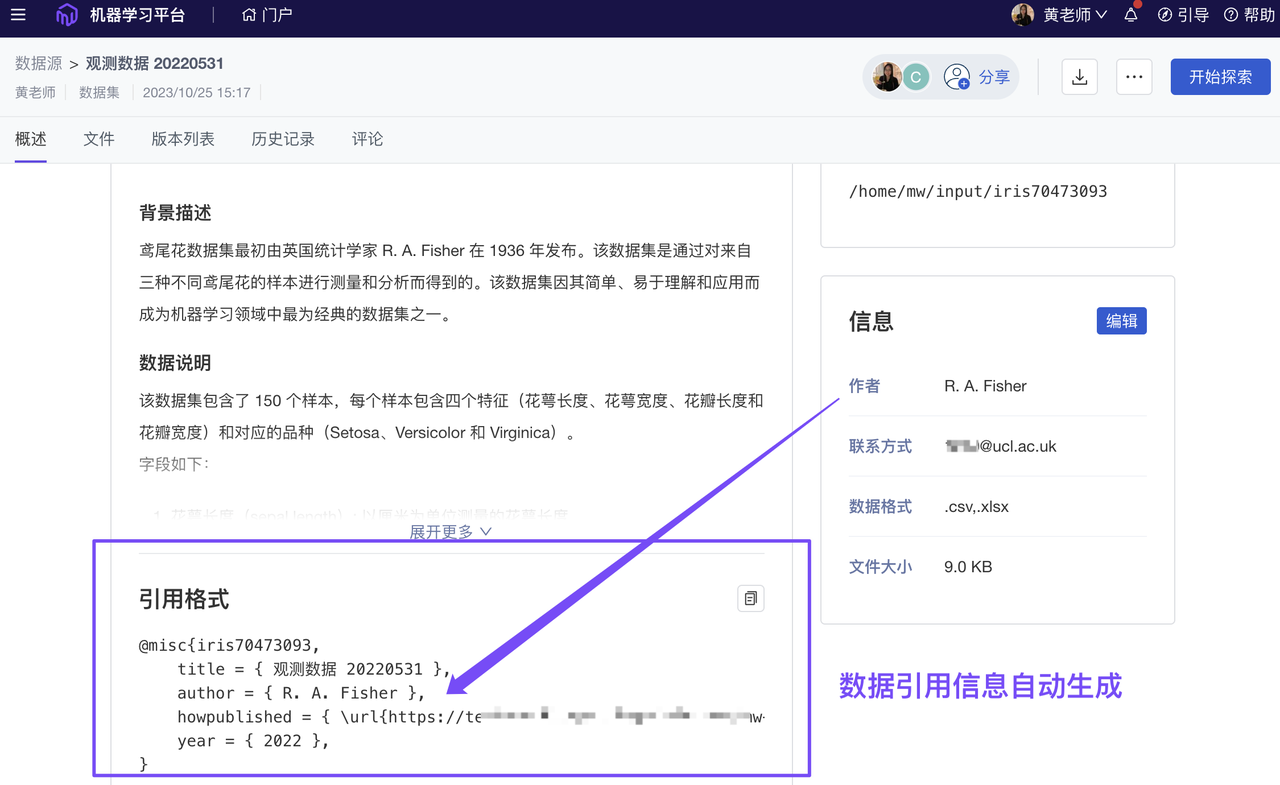
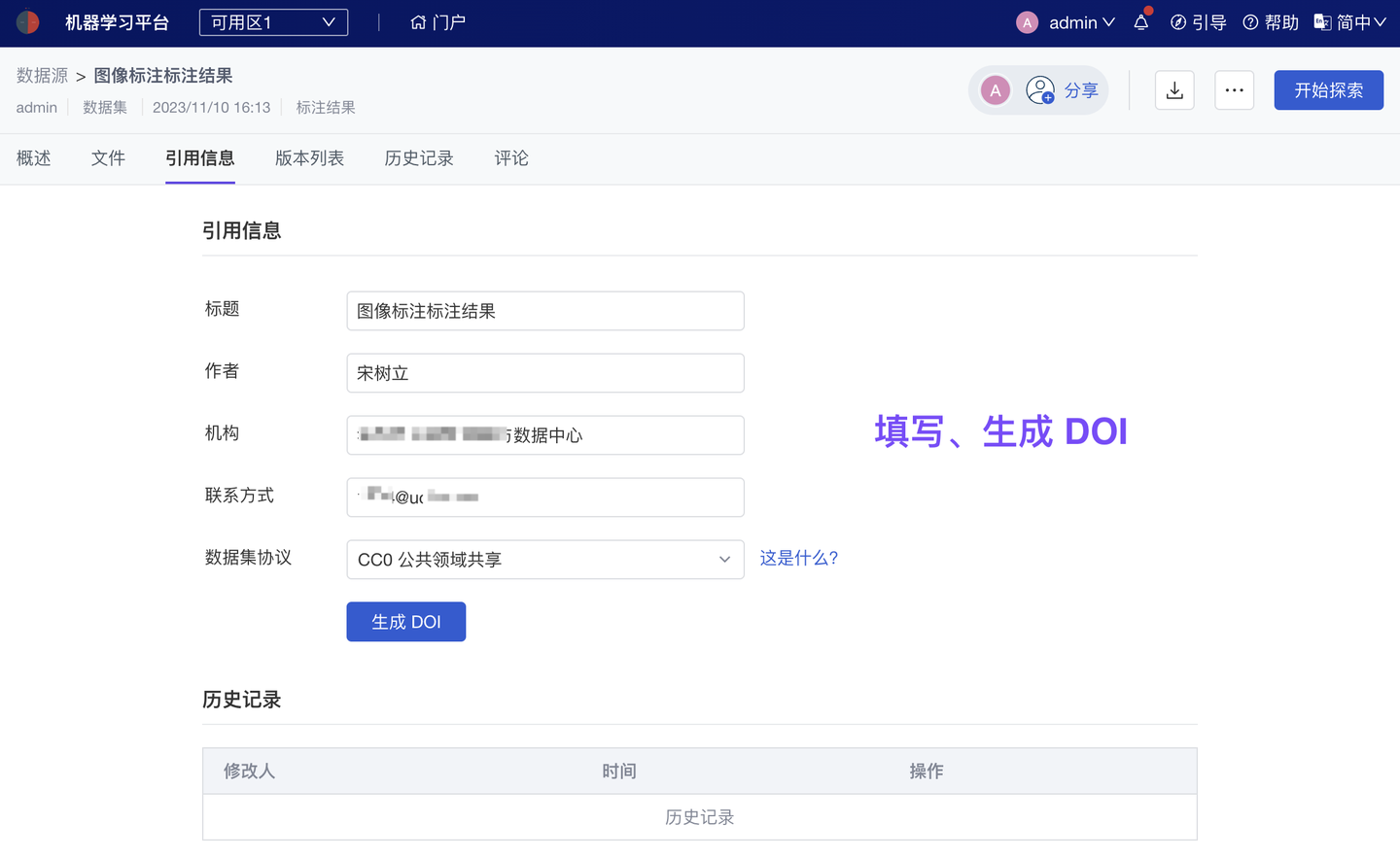
为实现科学数据更规范的管理、展示、使用,平台已应用 FAIR 原则:通过“元数据体系”,保证数据资产的可发现(Findable)、可访问(Accessible)、可互操作(Interoperable)、可重用(Reusable)。我们也提供了规范的 DOI 和数据引用格式,以便数据使用者可以更便捷、更规范地标记数据来源。
此外,平台还提供“独立门户”,作为内容分享窗口,连接外部伙伴。为促进生态共建、内容共享的积极氛围,现已支持由组织成员自主申请公开其工作成果,比如再分析数据、研究代码报告、机器学习算法、大模型探索实践、模型服务应用等。
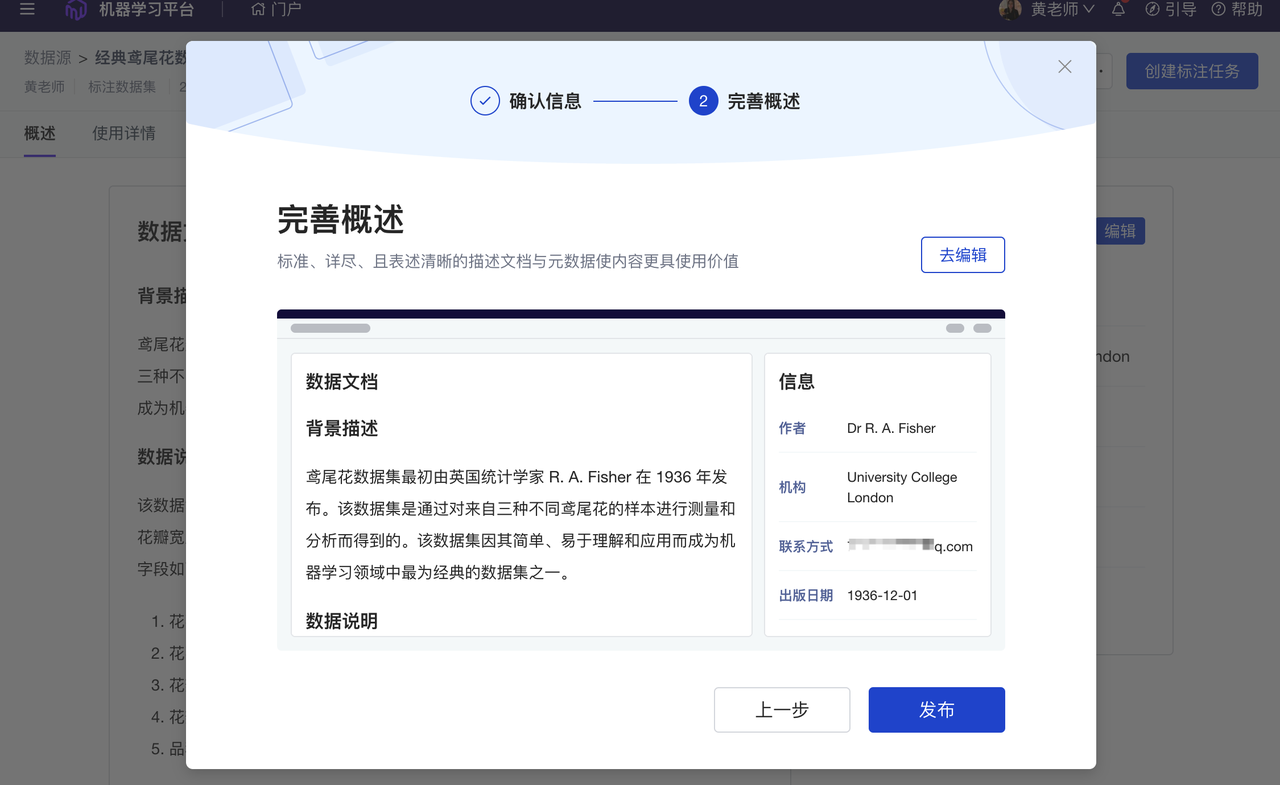
优化 元数据及 DOI 管理
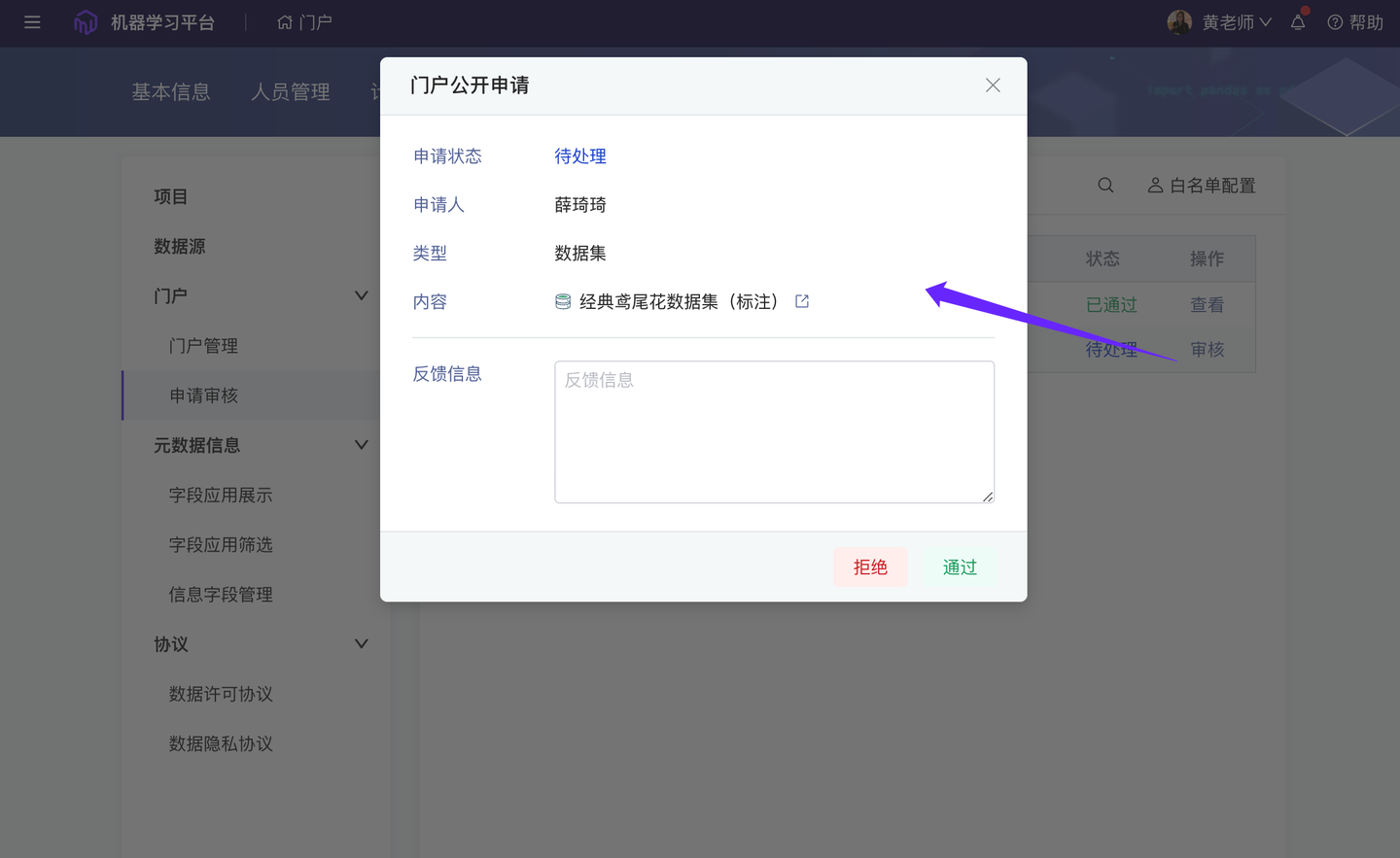
新增 门户内容公开申请

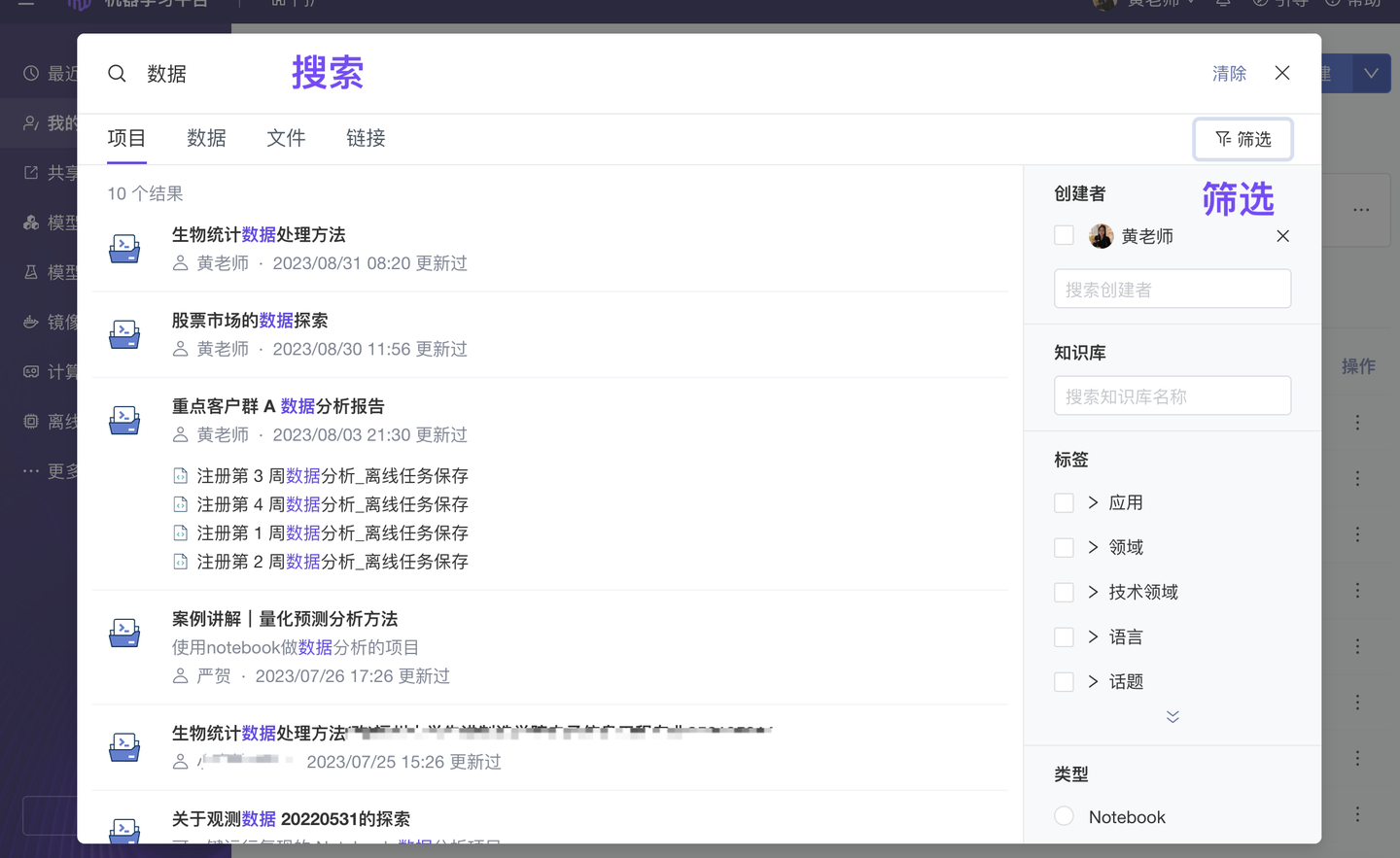
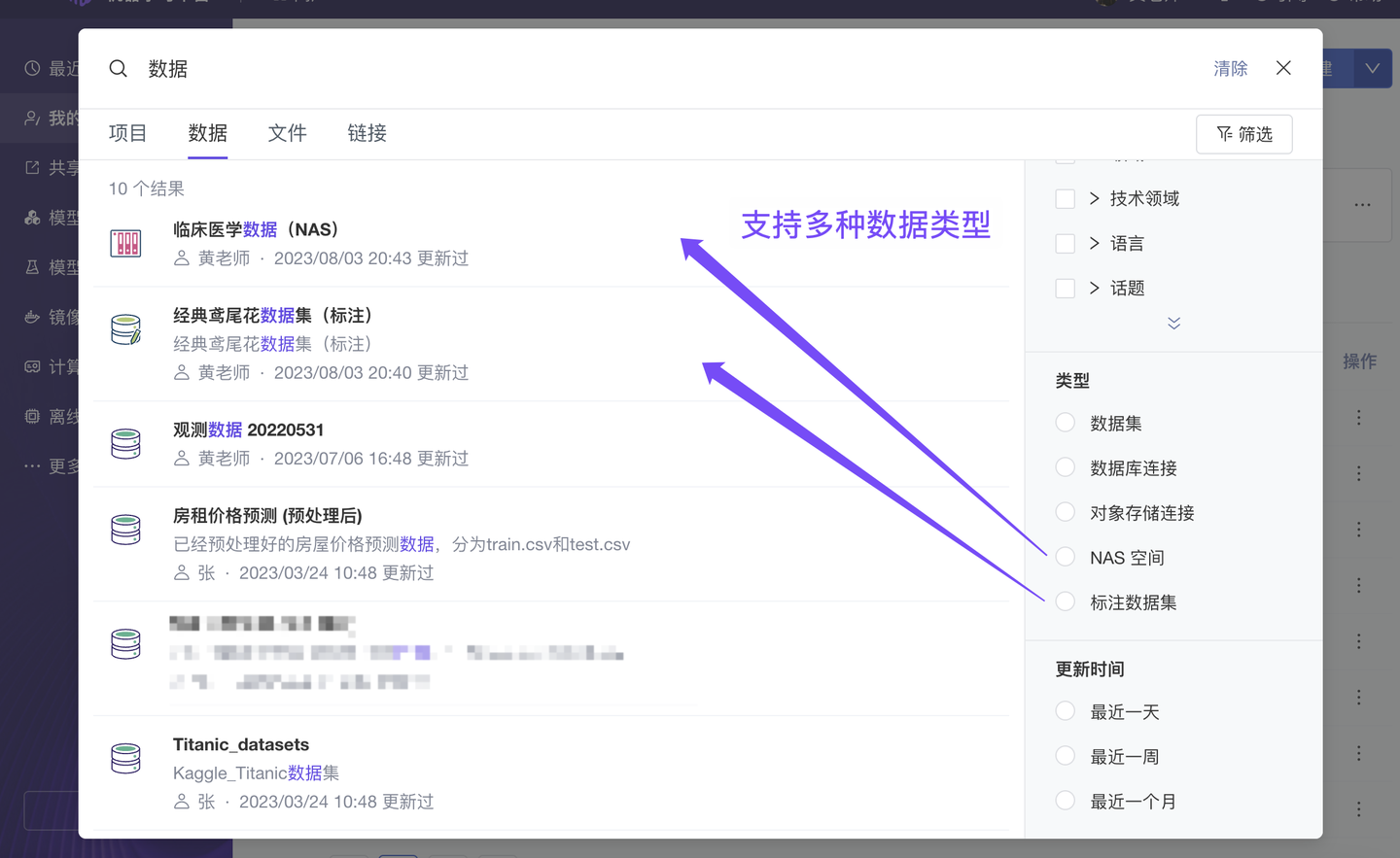
优化 资产搜索查询
六、更便捷的账号迁移、更丰富的开放接口、支持多语言(中/英)切换
平台支持与客户已有的第三方用户系统打通:直接使用已有第三方账号(如 Authing, User-OneID, 其他 OA 账号)即可完成平台的注册、登录/免登录。我们也提供丰富的数据接口,可灵活对接其他平台系统;以及数据埋点相关设施,帮助进行业务分析、监控。
此外,为助力国际化业务发展,我们进行了语言版本的全面升级,新增 支持多语言(中/英)双语切换,让多语言人才的沟通协作更流畅。
以上,就是本季度 ModelWhale 私有化版本更新的全部内容。
进入 Modelwhale 官网,免费试用 Modelwhale 专业版(个人研究)或团队版(组织协同),获赠 CPU、GPU 算力!(建议使用 pc 端体验试用)
若对 ModelWhale 有任何建议、疑问,或有试用续期需求,欢迎点击【联系产品顾问】,MoMo 很高兴为你服务、与你交流(咨询备注“私有化产品咨询”)。
这篇关于2023Q4 私有化版本发布,和鲸 ModelWhale 持续赋能大科研、高校教改的 AI for Science的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








