本文主要是介绍CCKS2023-面向上市公司主营业务的实体链接评测-亚军方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
赛题分析
大赛地址
https://tianchi.aliyun.com/competition/entrance/532097/information
任务描述
本次任务主要针对上市公司的主营业务进行产品实体链接。需要获得主营业务中的产品实体,将该实体链接到产品数据库中的某一个标准产品实体。产品数据库将发布在竞赛平台上。比如某一公司主营业务为“主要生产日用居家小家电,生活零售用品等相关产品”,选手从这段话中得到“日用居家小家电”这一产品实体,称为主实体;通过实体链接技术,找到产品数据库中的“生活小件家电”这一标准产品实体,称为链接实体。主实体与链接实体构成一个链接实体对,表示这两个实体是不同名称的相同实体。通过这些链接实体对,从而实现词语消歧以及数据源的融合。选手可以通过合理途径利用其他相关信息辅助任务完成,但是需要在方法描述文档中详细描述如何获取的相关信息以及如何在任务中使用该信息。
任务目标
参赛队伍需要能够准确的从公司主营业务中的出所有产品实体,即主实体,并且需要确定每个主实体在产品数据库中是否存在链接,若存在则需要在产品数据库中找到所有链接实体,形成一个或多个链接实体对,并给出权重,完成实体链接。需要注意的是,一个主实体的所有链接实体的权重相加需要为1。
数据样例一:
| 输入:{“companyName”:“xx公司”, “主营业务描述”:“ 公司主要业务为电力、热力生产和供应。”} |
数据样例二:
| 输入:{“companyName”:“xx公司”, “主营业务描述”:“ 啤酒、饮料制造和销售。”} |
任务描述和方案构思
本次任务主要针对上市公司的主营业务进行产品实体链接。首先需要获得主营业务中的产品实体,然后将该实体链接到产品数据库中的某一个标准产品实体。基于此,本方案将赛题任务拆解为三个阶段,如下图所示。

- 第一阶段:对每个公司的主营文本进行实体抽取,得到待链接的产品实体;
- 第二阶段:训练向量召回模型,利用产品数据库构建向量索引,并且对每个待链接实体进行向量召回,得到召回候选项;
- 第三阶段:训练分类排序模型,基于上一阶段得到的召回候选项,进行二分类,得到最终的链接实体;
下面分别对每一个阶段进行详细描述。
任务方案拆解
第一阶段-实体抽取
本阶段任务是对每个公司的主营文本进行实体抽取,得到待链接的产品实体。但是观察数据发现,主营文本中产品实体错综复杂,属于 常规实体、间断实体(非连续实体)和嵌套实体的混合型实体, 还有一些总结性的实体,单一的实体抽取方案很难处理这种情况。基于此,最终采用采用了两种方案:基于span双指针网络的抽取方案和基于cpt模型的生成式方案。
span双指针网络的抽取方案
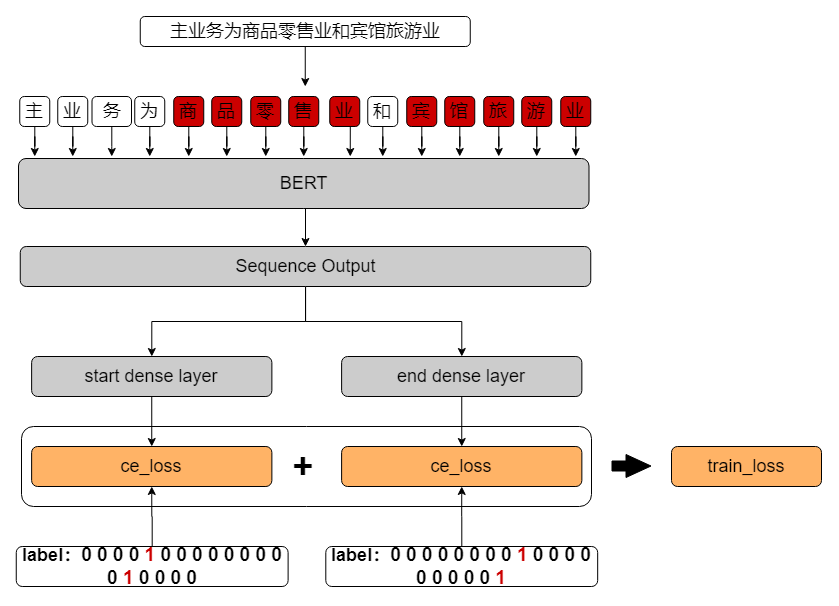
在指针标注体系中,使用span模块代替了CRF模块,加快了训练速度,以半指针-半标注的结构预测实体的起始位置,同时标注过程中给出实体类别,简单点说,就是设置两个指针start和end,分别记录每一种实体的开始和结束的位置,并且在记录位置的同时,标注该实体的类别,如上图所示,”商品零售业“和”宾馆旅游业“表示两个实体,但是同属于产品实体一类,实体类别用1表示,最后输出层分别用start dense layer和end dense layer两个指针网络标注两个实体的起始位置和所属类别,最后的损失由两个指针网络的损失累加求和。
训练数据
span双指针网络的抽取方案,在训练数据方面,做了一些数据增强,主要集中在两点:
- 将产品数据库中的数据直接加入训练集,进行模型训练;
- 使用链接实体替换主营业务文本中的产品实体,进行数据增广;
基于cpt模型的生成式方案
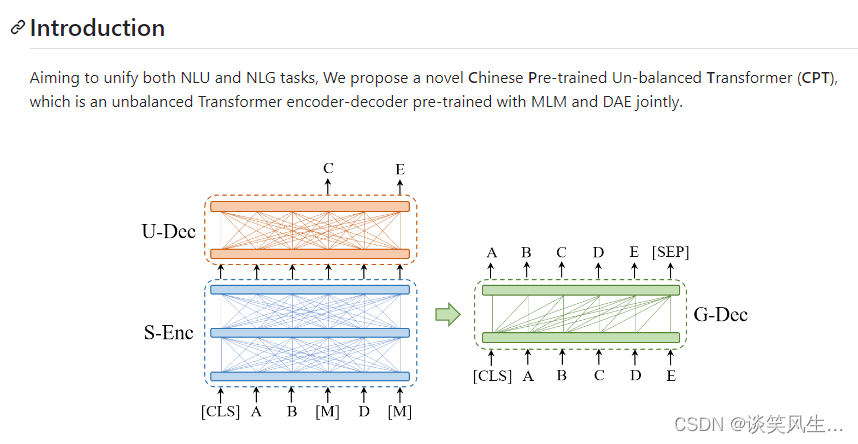
cpt模型是复旦nlp提出的中文生成式模型,本方案基于cpt模型,用于实体抽取。比如某一个公司的主营业务文本为:主营业务为商品零售业和宾馆旅游业,那么具体训练逻辑如下:
- 训练集输入:主营业务为商品零售业和宾馆旅游业;
- 训练集标签:商品零售业#宾馆旅游业;
标签使用固定格式,即:使用#进行分割,使用这种生成的方式进行实体抽取。
cpt参考链接:https://github.com/fastnlp/CPT
训练数据
基于cpt模型的生成式实体抽取方案,在训练数据方面,做了一点优化:
- 使用链接实体替换主营业务文本中的产品实体,进行数据增广;
模型融合
另外,本阶段使用不同的训练参数(种子、学习率、对抗学习fgm参数、batch_size等等)、不同的初始化模型权重,训练了两个方案的多个模型,每个模型预测一次,生成多个预测文件,进行融合,并且在融合过程中,对于相似的实体,进行实体消歧。
第二阶段-向量召回
本阶段任务是训练向量召回模型,并且利用产品数据库构建向量索引,然后对实体抽取得到的实体(产品实体)进行向量召回,得到召回候选项。
向量召回模型的选择
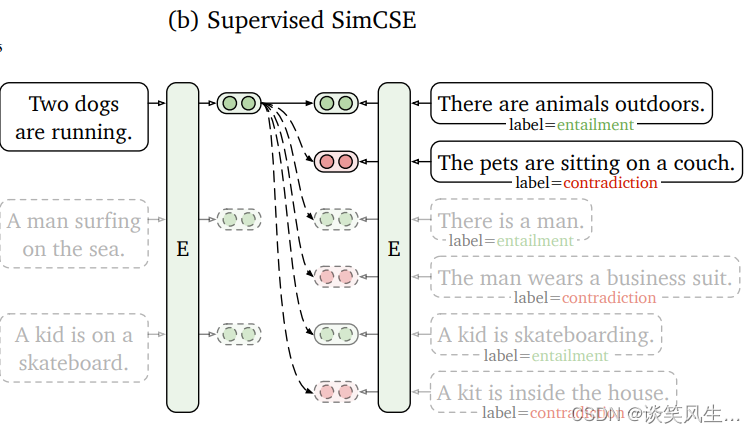
本方案向量召回模型选择的是基于对比学习的simcse模型,结构如下图,simcse原理这里不再赘述,可自行查阅论文。
向量召回模型训练的数据准备
训练数据主要由两部分组成,正例数据和负例数据。
- 正例数据:直接使用官方提供的训练数据,使用其中的产品实体和链接实体组成正例对;
- 负例数据:产品实体从产品数据库中随机选择实体组成负例;
向量索引的构建
向量召回模型训练完成之后,对产品数据库中的每一个产品实体进行向量化表征,然后利用faiss工具构建向量索引库;
实体向量召回
基于第一阶段实体抽取得到的实体,对每一个实体进行向量召回,取top30的召回项作为候选项。
第三阶段-分类排序
经过第一阶段和第二阶段,已经得到了公司主营业务文本中的每一个产品实体及其对应的top20候选项,接下来是确定top30候选项中哪些是真正的链接实体,我们选择了二分类来做这个任务。
分类模型
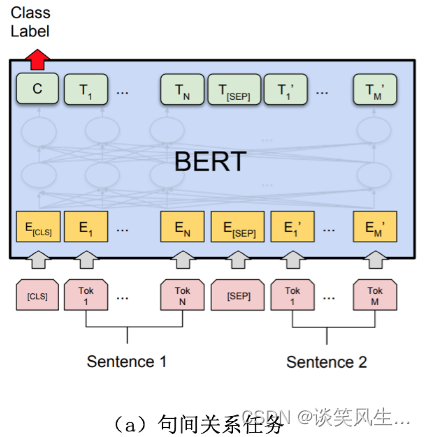
分类模型选择基于bert的二分类模型,如下图所示。
分类模型训练数据
训练数据主要由两部分组成,正例数据和负例数据。
- 正例数据:直接使用官方提供的训练数据,使用其中的产品实体和链接实体组成正例对;
- 负例数据:从正例数据中,对产品实体进行向量召回,得到top20候选项,从top20候选项中过滤掉真正的链接实体,剩下的非链接实体与原来的产品实体,组成负例对。举个例子,官方提供的训练数据中,面类和面条分别是产品实体和链接实体,利用向量召回,对面类进行召回,得到两个候选项:面条和面料,显然面类和面料组成一对负例。
分类模型训练完成之后,便可以对公司主营业务文本中的每一个产品实体及其对应的top30候选项,进行分类,确定其真正的链接实体。
总结
最终成绩:初赛第一名,复赛第二名。
另外,感觉给标注数据整体质量不高,存在很多前后冲突、模棱两可的情况,因此榜单上的整体得分都不高。
这篇关于CCKS2023-面向上市公司主营业务的实体链接评测-亚军方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








