本文主要是介绍ibox爬虫逆向分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标网址 ibox
aHR0cHM6Ly93d3cuaWJveC5hcnQvemgtY24vZmluZC8=
最近做了ibox的新品数据采集,这里来分享一下思路。
该网站难点主要在请求参数与响应内容都为ArrayBuffer,然后它的
AES_CBC加密方法比较难扣(对我而言,可能是技术问题)。
加密点比较容易寻找,通过断点找到发起请求的地方,data为一个arraybuffer。
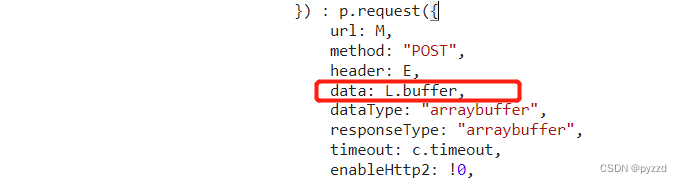
往上找L
L由aes得来,这里可以推出加密数据为N,x为key与iv。
x值由i.key加密得到。i.key的值通过搜索可以知道是另一个接口返回的。


而N的值由一个压缩算法得到。b值生成算法中比较关键的是O
{
method: c.method || "GET",
header: O,
body: v,
call_id: g
}
O中数据基本可以不变,但是有一个value决定了请求的页码。
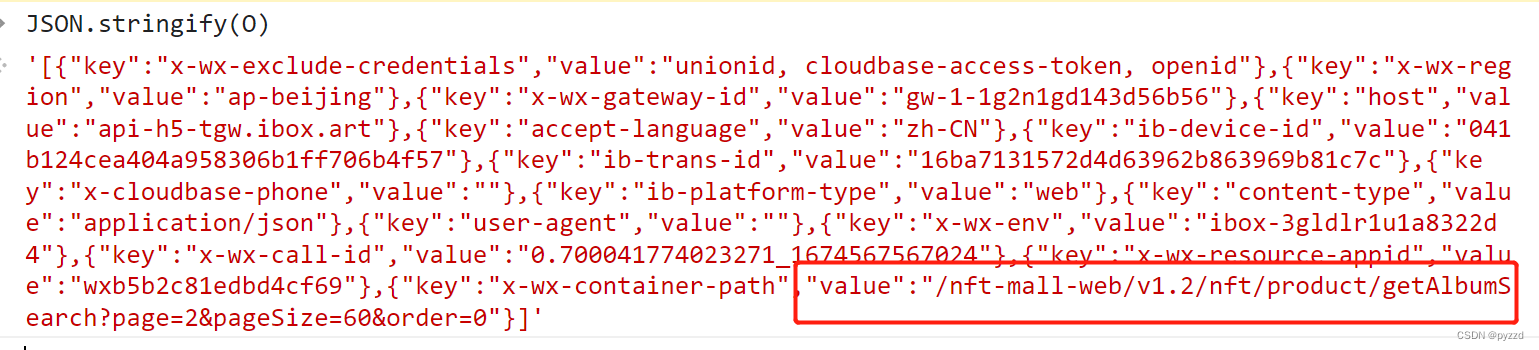
到这里请求参数的生成逻辑基本理清了,然后就是扣代码。我是将所有代码扣下来然后通过导出函数来实现的,不然一个一个扣太麻烦了。
响应信息的解密流程也差不多,没有什么难度

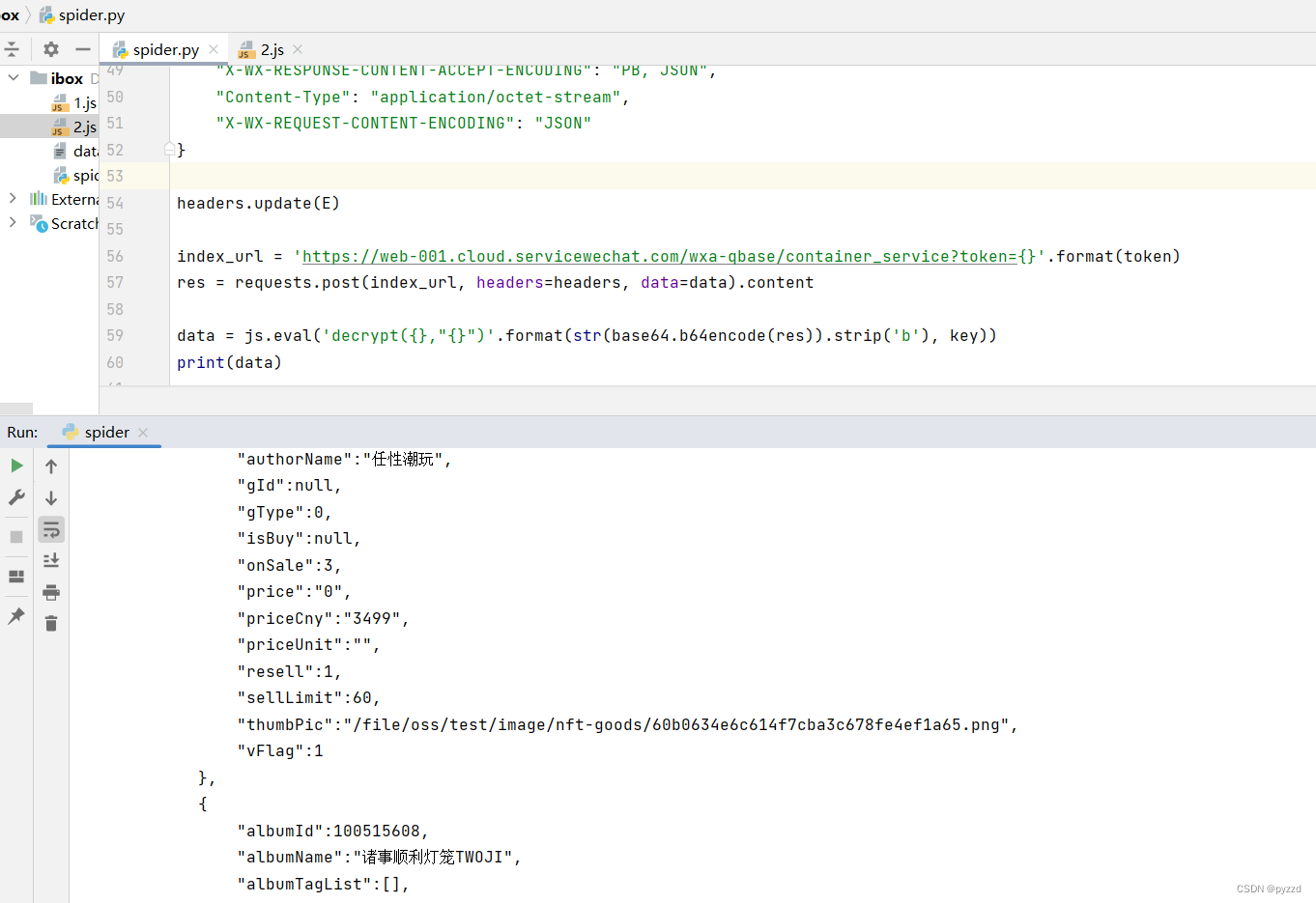
源码:各平台数据解密源码
这篇关于ibox爬虫逆向分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





