本文主要是介绍【论文记录】Input Perturbation: A New Paradigm between Central and Local Differential Privacy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
算法&基本思想
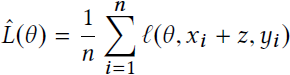

- By line 7 in Algorithm 1, it can be seen that the noise added to the original data affects the gradient. (adds noise to original data instances, leading perturbation on the gradient and eventually causing perturbation on the model parameters)
理论分析
这篇关于【论文记录】Input Perturbation: A New Paradigm between Central and Local Differential Privacy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





