本文主要是介绍基于 APN 的 CXL 链路训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🔥点击查看精选 CXL 系列文章🔥
🔥点击进入【芯片设计验证】社区,查看更多精彩内容🔥
📢 声明:
- 🥭 作者主页:【MangoPapa的CSDN主页】。
- ⚠️ 本文首发于CSDN,转载或引用请注明出处【https://mangopapa.blog.csdn.net/article/details/132129387】。
- ⚠️ 本文目的为 个人学习记录 及 知识分享。因个人能力受限,存在协议解读不正确的可能。若您参考本文进行产品设计或进行其他事项并造成了不良后果,本人不承担相关法律责任。
- ⚠️ 若本文所采用图片或相关引用侵犯了您的合法权益,请联系我进行删除。
- 😄 欢迎大家指出文章错误,欢迎同行与我交流 ~
- 📧 邮箱:mangopapa@yeah.net
- 💬 直达博主:loveic_lovelife 。(搜索或点击扫码)
文章目录
- 1. 前言
- 2. 硬件自协商
- 注意事项
- 3. APN @CXL
- 4. Modified TS @CXL
- 4.1 Modified TS 协商
- 4.2 Modified TS 内容
- 5. Q&A
- 6. 参考
1. 前言
两组件通信的前提是建链(建立通信链路),CXL 也不例外。支持 CXL 的 Host 和 Device 在正式发送 CXL Transaction 进行通信之前需要在两者之间建立一条可靠的物理链路,确保双方能够互相识别信令,对相关通信参数进行协商并达成一致,这个过程即链路训练(Link Training)。
广义而言,链路训练包括物理层和数据链路层的训练;侠义上讲,链路训练指物理层的链路训练。本文只讨论物理层的链路训练。
2. 硬件自协商
CXL 链路通过 Flex Bus 进行 Transaction 传输。CXL Flex Bus 支持 Native PCIe Mode 和 CXL Mode 两种模式,只有工作在 CXL Mode 时才能进行 CXL IO、Cache、Mem 的 Transaction 传输。至于最终采用何种工作模式,由硬件在链路训练期间动态协商决定。
CXL Flex Bus 链路训练跟 PCIe 链路训练大同小异,PCIe LTSSM 相关规则在 CXL 链路训练中仍然适用。CXL 链路训练期间,采用 替代协议协商(Alternate Protocol Negotiation,APN)机制、链路两端的组件交换 Modified TS 来进行以下 CXL Flex Bus 相关能力的协商:
- 是否支持 PCIe、CXL.io、CXL.cache、CXL.mem 协议;
- 支持的 Flit Mode:68B Flit、Standard 256B Flit、Latenct-Optimized 256B Flit、PBR Flit;
- 是否支持链路性能调控相关的 Sync Header Bypass、CXL NOP Hint、CXL.io Throttle;
- 是否为多逻辑设备(Multi-Logical Device,MLD);
- 链路上是否存在 Retimer1、Retimer2。
以上协商由下行端口(Downstream Port,DSP/DP)发起,上行端口(Upstream Port,USP/UP)进行响应,在 LTSSM 第一次进入 L0 之前就已协商完毕。链路初次进入 L0 时链路速率为 2.5 GT/s,未达到 CXL 协议要求的最低链路速率 8 GT/s,这意味着链路训练尚未完成,理所当然也无法发送 CXL Transaction。革命尚未成功,同志们仍需努力,仍需进行更高速率的链路训练。
CXL 物理链路训练成功的直接标致是 8 GT/s 或以上传输速率时 DSP/USP 的 LTSSM 均能到达 L0。68B Flit Mode 时,对于 DSP,其 LTSSM 在即将进入 8 GT/s 或更高速率 L0 之前,Flex Bus 逻辑物理层先发送 SDS 再发送 Null Flit(区别于 PCIe 的 Idle Symbol),待链路速度达到目标速率后可正式发送 CXL Transaction;对于 USP,只有在其收到对端 DSP 物理层以上层次发来的 Flit 之后,USP 的物理层才能通知其上层 Link Up、可以开始发 CXL Transaction。
如果 CXL 链路训练能够达到 2.5 GT/s 或 5 GT/s 的链路速度,但无法达到 8 GT/s 及以上速率,则 CXL 链路训练失败。此时,即便 Device 支持 PCIe,也无法回退到 2.5 或 5 GT/s 的 PCIe Mode。想要切换到 PCIe Mode,需要 LTSSM 回退到 Detect,软件关闭 APN 协商相关控制信息后再次发起针对 PCIe Mode 的链路训练。
Flex Bus 在 CXL Mode 时支持链路减宽(Width Degradation)或降速(Speed Downgrade)。如果所需的 Link Width/Speed 在协议支持的范围内,其可以直接从 L0 进入 Recovery 进行相关操作,无需重新进行 CXL Mode 的协商;若 Degrade 到其他 CXL 不支持的 Width 或 Speed,需要回退到 Detect 重新训练。
注意事项
如果 CXL 组件支持的最大速率为 8 GT/s 或 16 GT/s,在链路新训练之前应把支持的最大速率置为 32 GT/s。之所以这么做,是因为 APN 机制初现于 PCIe Gen5,Modified TS Usage Selected 字段位于 32 GT/s Control Register 中。设置支持 32 GT/s,确保该寄存器可用,从而确保能够发出 Modified TS 从而进行 APN 协商。在 APN 协商完毕之后,需要软件修改支持的最大速率为真实的最大速率。
对于 eRCH 或 eRCD 这类只支持 CXL 1.1 的组件,其不支持热插拔,BIOS 默认会关闭 APN 以阻止热插拔,需要软件手动打开。
3. APN @CXL
当 PCIe 之外的协议运行在 PCIe PHY 上,比如此处的 CXL 协议,需要采用 APN 机制进行替换协议相关细节的协商。CXL 链路 LTSSM 退出 Detect 状态后开始链路训练进程,在 Configuration 状态期间采用 APN 机制进行 Flex Bus 能力协商。
APN 机制在 LTSSM Configuration 中的位置如下图所示,APN 机制中的 Flex Bus 能力协商不影响通道号 Lane Number 的协商,两者并行。

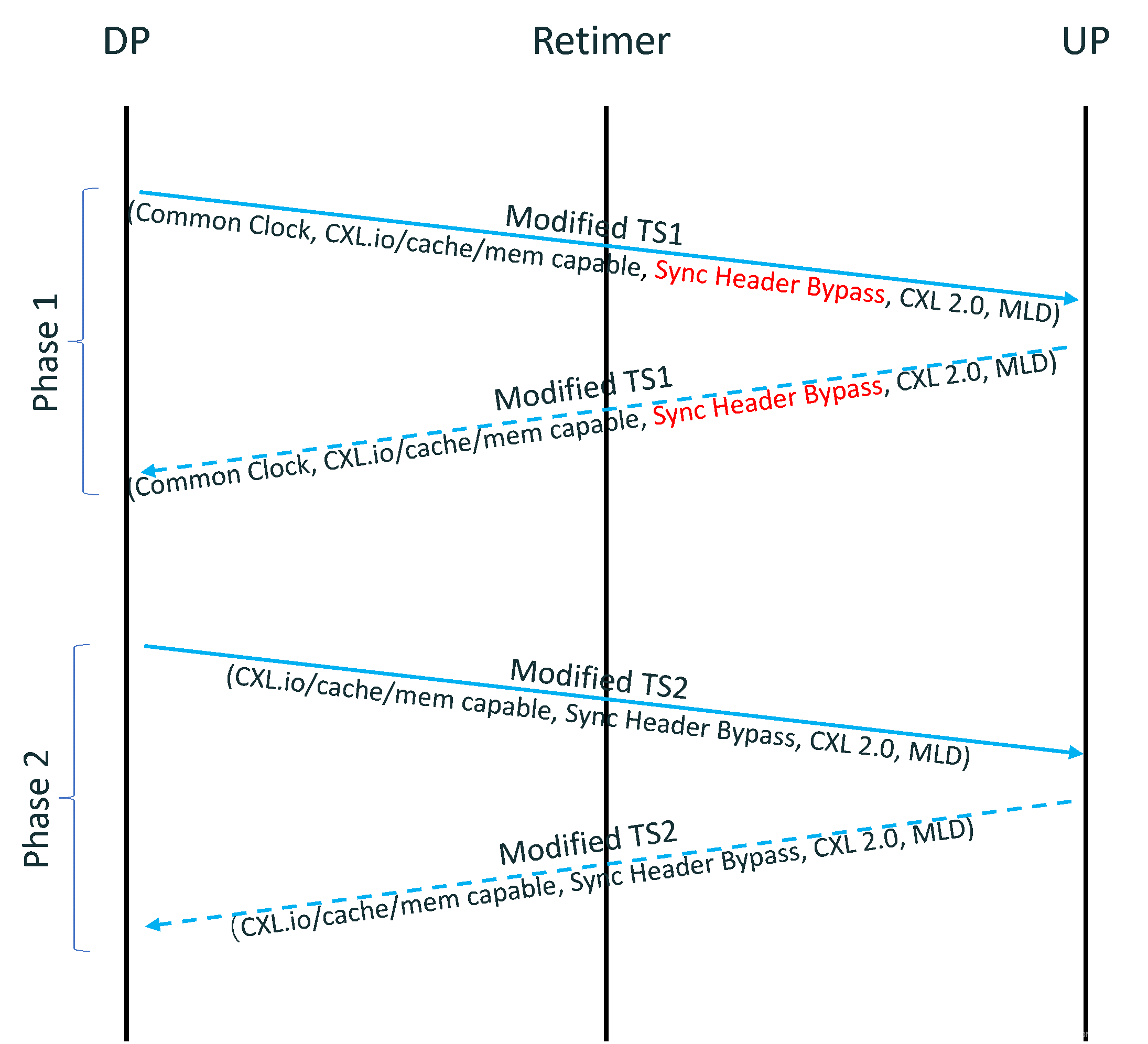
CXL Flex Bus 能力协商可分为先后两个阶段(下图):
- Phase 1,提议阶段,链路两端的组件在本阶段互相通报自身支持的 Flex Bus 特性,发生于
Configuration.LaneNum.Wait->Configuration.LaneNum.Accept期间。大致流程如下:- LTSSM 进入
Confoguration.LaneNum.Wait之后,若 CXL 链路 DSP 支持 CXL 协议,由 DSP 发送带有 Flex Bus 相关信息的 Modified TS1 发起 CXL Mode 协商。 - USP 收到 DSP 发来的 Modified TS1 后,若其支持 CXL 协议,USP 反馈能够反映其自身 Flex Bus 能力的 Modified TS1。
- LTSSM 进入
- Phase 2,决议阶段,DSP 及 USP 在本阶段决定最终采用的工作模式及 Flex Bus 相关功能,发生于
Configuration.Complete期间。大致流程如下:- DSP 收到 USP 反馈回来的 Modified TS1 后做决定,决定是否启动 CXL、具体使能的协议/模式/特性,并通过 Modified TS2 反馈决议结果给 USP。在进入 Configuration.Idle 之前 DSP 至少需连续发送 16 笔 Flex Bus Enable 字段一致 Modified TS2。
- USP 收到 DSP 发来的 Modified TS2 之后,反馈 Modified TS2 进行确认。USP 在连续收到 8 笔 Flex Bus Enable 一致的 Modified TS2 之后可以退出到
Configuration.Idle。
4. Modified TS @CXL
4.1 Modified TS 协商
Modified TS 用于 APN 协商过程中,其只有 8b/10b 编码的一种形式。允许发送 Modified TS 的 LTSSM 子状态有 Configuration.Lanenum.Wait、Configuration.Lanenum.Accept 及 Configuration.Complete,在此之前,必须在 Polling.Active、Polling.Cfg、Cfg.Linkwidth.Start、Cfg.Linkwidth.Accept 状态将 Standard TS1/TS2 Symbol 5 的 Bits[7:6] 置为 2’b11,收发端对是否支持 Modified TS 进行协商。只有在收发端均支持 Modefied TS 时,才能发送 Modified TS,否则仍然发送 Standard TS。
4.2 Modified TS 内容
跟 Standard TS 比,Modified TS 更改了 Symbol 6~15,这些 Symbol 在 Standard TS 中主要是均衡相关字段。CXL 所用的 Modified TS 关键字段的释义如下:
- Symbol 5,Bits[7:6] =11b 来指示当前 TS 为 Modified TS。
- Symbol 8-9,
- Bits[2:0]用以指示 Modified TS Usage,即 Modified TS 的用途。该字段的值由 32.0 GT/s Control Register(下图)中的 Modified TS Usage Mode Selected 字段决定。010b 表示当前 Modified TS 用以 APN 协商。
- Bits[15:3]携带有 Modified TS 的 Info1。其中,Bits[4:3]指示 APN 状态,Bits[15:5]指示协议细节。对于 CXL,Bits[7:5]指示 Alternate Protocol ID,000b 表示 Flex Bus;Bit8 指示 Common Clock;Bits[15:9] Reserved。Common Clock Bit 是 DSP 给 Retimer 用的,Retimer 根据该信息决定开启哪些特性。
- Symbol 10-11 携带有 Vendor ID,对 CXL 而言,这里填写 1e98h。
- Symbol 12-14 携带有 Modified TS Info2。对于 CXL 而言,Bits[7:0]指示 Flex Bus 支持的能力,Bits[23:8]指示 Flex Bus Additional Info:
- Bit[0]: PCIe Capable/Enable
- Bit[1]: CXL.io Capable/Enable,若支持 CXL 68B Flit 或者 VH,必须支持 CXL.io
- Bit[2]: CXL.mem Capable/Enable
- Bit[3]: CXL.cache Capable/Enable
- Bit[4]: CXL 68B Flit and VH Capable/Enable (formerly known as CXL 2.0 Capable/Enable)。若开启了 PCIe Flit Mode,则 CXL 不能开启 68B Flit 或 VH。
- Bits[7:5]: Reserved
- Bit[8]: Multi-Logical Device Capable/Enable。Switch USP 此处必须置零。
- Bit[9]: Reserved
- Bit[10]: Sync Header Bypass Capable/Enable。仅适用于 68B Flit Mode,不适用于 256B Flit Mode。若开启了 Bypass Sync Header,在链路速度达到 8 GT/s 或以上速率时才 Bypass Sync Header。对于 Retimer,其必须不加修改地从其伪 USP 传到伪 DSP。若 Retimer 不支持 Bypass Sync Header,其从下行伪端口到上行伪端口传递该 TS 时可以将该字段清零,不允许私自置一,置一 USP 可以置一。若 Retimer 不支持 CXL,DSP 会假设 Retimer 不支持该特性。
- Bit[11]: Latency-Optimized 256B Flit Capable/Enable
- Bit[12]: Retimer1 CXL Aware1
- Bit[13]: Reserved
- Bit[14]: Retimer2 CXL Aware2
- Bit[15]: CXL.io Throttle Required at 64 GT/s,USP 采用该字段来指示其在 64 GT/s 速率下是否需要 CXL.io Throttle。若其不支持接收联系的 CXL.io Flit,该字段需要置一。DSP 收到后会将该字段保存在 DVSEC Flex Bus Port Status Register 中。
- Bits[17:16]: CXL NOP Hint Info[1:0],指示是否支持在收到 NOP Flit Hint 后插入 NOP Flit、需要插入几个 NOP Flit。
- Bit[18]: PBR Flit Capable/Enable,指示是否具备/开启 PBR。若未开启 PCIe Flit Mode,则 PBR Flit 也不能开启。PCIe Flit Mode 意味着 256B Flit Mode,PBR 采用 256B Flit。
- Bits[23:19]: Reserved
5. Q&A
- Crosslink 时由谁发起 APN 协商?
在 LTSSM 进入 Configuration 状态发起 APN 协商之前已经确定了 DSP、USP,仍然由 DSP 发起 APN 协商。
6. 参考
- CXL Base Spec, r3.0
| |
🔥 精选往期 CXL 协议系列文章,请查看【 CXL 专栏】🔥
⬆️ 返回顶部 ⬆️
这篇关于基于 APN 的 CXL 链路训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








