本文主要是介绍论文阅读:Depth-attentional Features for Single-image Rain Removal,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2019 CVPR:DAF-Net
这是2019CVPR的一篇文章,主要创新点是引入了深度信息完成去雨。

本篇文章首先指出了现有的方法由于忽略了物理特性,导致去雨的有效性较低。同时分析了雨图成像机理,指出远处的物体更多地是被雾遮挡,近处的则是雨纹,分析了受场景深度影响的雨的视觉效果,并共同制定了一个带有雨条纹和雾的雨成像模型;然后,并准备了一个新的数据集。然后设计了一个端到端的深度神经网络,我们训练它通过深度引导的注意力机制来学习深度注意力的特征,并回归剩余映射来产生无雨的图像输出。
创新之处:
1、引入了深度信息,制定了基于场景深度的雨的视觉效果的雨成像过程,实现了雨条纹和雾的合成。
2、设计了一个端到端的神经网络,形成深度指导的注意力机制学习深度注意特征,根据注意权值对残差图进行回归,去除输入雨图像中的雨条纹和雾。
3、准备了一个新的雨去除数据集。
前人工作:
由于现有数据集的限制,雨图数据都是通过清晰图像加上雨纹合成的,因此这些方法主要关注雨纹图像。
传统方法:
1、最早期通过设计基于低水平图像统计的手工先验来去除图像中的雨纹。
2、Barnum 结合条纹模型和雨的特征,在频域内检测和去除雨纹。
3、Chen 通过一个低秩先验去除雨纹,因为雨纹通常具有相似和重复的模式。
4、Li 采用基于高斯混合模型的patch先验对背景和雨层进行去除雨纹。
5、Zhu 估计主导降雨方向并提出了一种双层联合优化方法来迭代地将雨纹从背景中分离出来。
基于CNN:
1、Fu 从训练数据中学习无雨层和雨层之间的映射函数。DerainNet
2、Yang 创建了一个多任务网络,共同检测和去除降雨。JORDER
3、Fu 利用先验知识从输入图像中构造出基层和细节层,然后通过深度网络从细节层学习残差。DDN
4、Li 使用SE-Net建立了一个上下文扩展网络,迭代地预测阶段残差。RESCAN
5、Zhang开发了一种残差感知分类器来确定雨密度,并将几个紧密相连的网络堆叠起来,以此来估计残差。DID-MDN
同时:
Garg和 Nayar 通过考虑场景深度和光源,开发了一种基于图像的降雨生成算法。
网络结构

其中,
蓝色部分是:用于从输入中提取多分辨率特征的卷积神经网络
绿色部分是:用于预测深度图的解码器分支
橙色部分是:学习注意权重的深度引导注意机制
黄色部分是:另一个解码器分支,用于产生深度注意特征和注意权重;
最后,我们使用一组组卷积对深度注意特征(粉红色部分)进行残差预测,并将其加入到输入中,生成输出的无雨图像。
成像具体工作:
1、雨成像模型

在自然界的成像中,造成视觉阻挡的不仅有雨纹,还有雨带来的雾。一般情况下,认为离相机近的受雨纹影响比较大,离相机较远的受雾的影响比较大。
如图所示,是雨纹强度随深度影响的曲线,其中最大雨纹强度为tr0.
1、相机附近的场景对象(d≤d1),其关联的图像区域以雨纹为主,雾较小,即其中d1 = 2fa, f为焦距,a为雨滴半径,雨纹强度为最大雨纹强度tr0.
2、场景对象远离相机(d≥d2≫d1),其相关的图像区域将由雾与小雨纹组成,当d增加时,tr趋于0。
3、随着d从d1增加到d2,雨条纹强度将下降,雾强度将上升。
2、雨图像的公式:
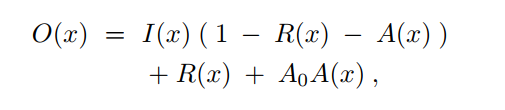
其中,I(x)为场景亮度清晰的无雨图像;R(x)∈[0,1]表示降雨层;A0为大气光,假设为一个全局常数;且A(x)∈[0,1]表示雾层;
具体表示如下图:

雨层:
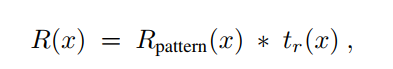
其中R pattern(x)∈[0,1]是图像空间中均匀分布的雨条纹的强度图像;tr(x)为依赖场景深度的雨条纹强度图,*代表着像素乘法。
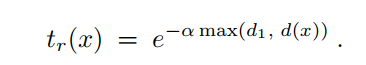
其中α是一个控制雨纹强度的衰减系数。此外,tr0(这是最大的雨条纹强度)= e−αd1,而tr (x)始于tr0并逐渐下降至零在d (x)超越d1后。
雾层:
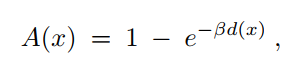
其中β是一个衰减系数,控制雾的厚度,β越大,雾越厚。
3、新建数据集
拍摄一对真实的有雨和无雨的照片进行训练几乎是不可能的,因为场景对象可能会移动,环境光线和相机曝光可能会改变。因此,现有的用于去雨的数据集通常是通过在照片上添加一个二维的雨纹层来制备。最近的深层网络只是简单地对其进行训练以去除雨。显然,物理雨模型被忽略了,所以现有的方法对真实的照片往往是失败的;
因此,新建立一个新的数据集 RainCityscapes
数据集都是户外照片,每一张都有一个深度图,雨图像显示出不同程度的雨和雾。
从上面的公式来生成雨纹强度tr和雾层A。
参数分别设为(α,β,a)={(0.02, 0.01, 0.005), (0.01, 0.005, 0.01),(0.03, 0.015, 0.002)}
选用阴天无阴影的图片作为深度图,并使用深度去噪细化深度图。
最后得到9432张训练图片和1188张测试图片。
4、模拟成像的局限性
模拟成象过程假设雨层和雾层是均匀分布和相互独立的。而在现实世界中,雨、雾的视觉效果与雨强相关;雨的外观取决于相机参数(如曝光时间);而降雨强度变化更为复杂。相机自身运动也会分散雨的分布,造成图像空间额外的运动模糊。虽然我们的降雨模型是近似的,缺乏光学模型,但是合成的图像确实有助于改善与之前的工作和数据相比的结果,这些工作和数据忽略了我们所探索的降雨特性。
网络具体工作:
DAF-Net网络工作流程:
网络首先利用卷积神经网络(CNN)从输入图像中提取低层细节和高层语义,并生成不同分辨率的特征图。
然后使用两个解码器分支,每个分支逐步上采样一个特征图,并将其与相同分辨率的CNN 特征图相结合,生成一个新的特征图。
在顶部的解码器分支中,我们进一步回归深度图,并通过深度引导注意力机制学习一组注意力权重。
在底部的解码分支中,我们首先生成最终的(最高分辨率的)特征图,然后将其与顶部分支的注意力权重相结合,生成深度注意特征。
最后,在这些特征上应用一组群卷积,预测残差映射,并将其加入到输入图像中,得到无雨输出图像。
1、顶部解码器分支回归深度图
当上采样特征图的宽度达到输入的四分之一时,我们添加一个监控信号,并对输入图像进行深度映射。注意,较低分辨率的深度图足以作为学习注意权重的指导,因此我们退回四分之一宽度深度图以减少计算和内存开销。
然后,通过对监控信号(训练数据集中的输入深度图)中的深度值进行转换,对深度值的对数进行回归:
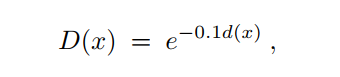
d(x) 是像素x上的场景深度。
D(x)是网络中的监控信号。因此,网络中的回归深度图实际上是对数深度值的图。
2、深度注意特征
首先在我们的网络中回归深度图,并以此为指导来学习一组注意力权重。然后,我们可以使用这些权值来集成来自我们网络底部解码器分支的特征图,从而形成雨条纹和雾的残留图。在此基础上,将残差映射加入到雨图像中,得到输出的无雨图像。
图为深度指导注意力机制:从回归深度图D(x)中学习权值.

如图:
首先采用3个卷积块对D(x)进行ReLU非线性运算,在每个3x3的卷积层之后。
最后一个卷积块的输出是一组未归一化的注意权值{A1, A2,…}。一般来说,每一种权重都对应一种特定类型的雨纹和雾。
然后,应用Softmax函数对权重进行归一化,生成注意权重{W1 W2,…,每一个都与一组雨纹和雾有关。
卷积和Softmax层用公式表达如下:
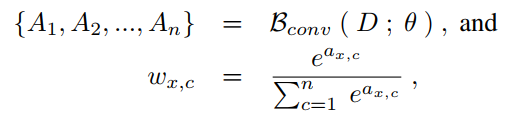
从底部解码器分支产生的最高分辨率的特征映射F b有256个特征通道。
接下来,我们把它分成256个通道的n个子映射,每个子映射Fib (i =1、2、……, n)有256/n个通道,分辨率与原始特征图 F b相同;实际上,我们设n为64。
然后,我们将Wc与cth子映射Fcb的每个特征通道按元素顺序相乘,生成深度注意特征。
现在,我们准备了n个独立部分的深度注意特征。因此,我们可以在深度注意特征的每个部分分别进行n组的组卷积,以增强特征的表达性。通过采用组卷积,每个组中的特征只负责删除具有较小类内方差的某种雨条纹和雾。最后,我们使用1×1的卷积将来自不同组的所有特征进行合并,得到残差图 Res(x),并将输入的雨图O(x)加入其中,得到输出的无雨图I(x).
3、训练
损失函数:
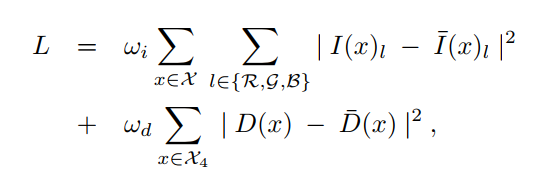
其中,ωi和ωd权重、X和X4分别表示输出图像和深度图的图像域;
I(x)l和I¯(x)l分别表示像素的l-th RGB X中像素x的颜色通道中的预测值和真实值。
D(x)和D¯(x)分别表示像素x处的预测深度和真实深度;
I(x)l、I¯(x)l、D(x)和D¯(x)的值被归一化为[0,1]。
注意,无雨图像I(x)的大小与输入图像相同,但深度图D(x)的大小仅为输入的1/16。
4、参数
Adam优化
第一个动量值为0.9,第二个动量值为0.99,权值衰减为5×10−4。
自适应地调整单个网络参数的学习速率,即对频繁更新的参数具有较高的学习速率,反之亦然。
基本学习率设为0.00001,迭代70000次之后减少学习率
迭代100000次
mini-batchsize = 1
Titan Xp
CF-Caffe
分页符
这篇关于论文阅读:Depth-attentional Features for Single-image Rain Removal的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)