本文主要是介绍Hologres性能优化指南1:行存,列存,行列共存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Hologres中支持行存、列存和行列共存三种存储格式,不同的存储格式适用于不同的场景。
在建表时通过设置orientation属性指定表的存储格式:
BEGIN;
CREATE TABLE <table_name> (...);
call set_table_property('<table_name>', 'orientation', '[column | row | row,column]');
COMMIT;
存储模式使用建议:
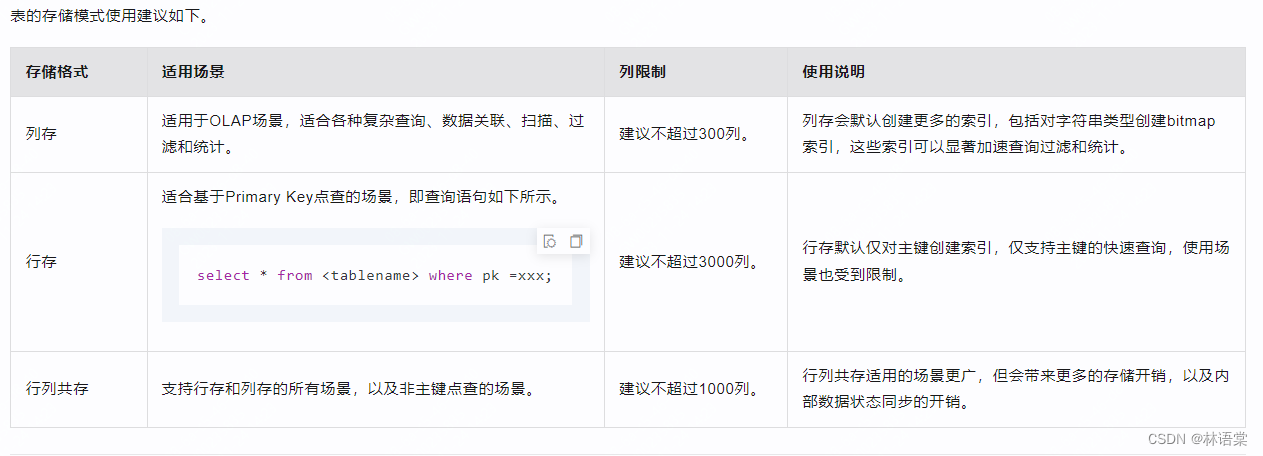
列存:
技术原理:
如果表是列存,那么数据将会按照列的形式存储。列存默认使用ORC格式,采用各种类型的Encoding算法(如RLE、字典编码等)对数据进行编码,并且对编码后的数据应用主流压缩算法(如Snappy、 Zlib、 Zstd、 Lz4等)对数据进一步进行压缩,并结合Bitmap index、延迟物化等机制,提升数据的存储和查询效率。
系统会为每张表在底层存储一个主键索引文件,详情请参见主键Primary Key。列存表如果设置了主键PK,系统会自动生成一个Row Identifier(RID),用于快速定位整行数据,同时如果为查询的列设置合适的索引(如Distribution Key、Clustering Key等),那么就可以通过索引快速定位到数据所在的分片和文件,从而提升查询性能,因此列存的适用范围更广,通常用于OLAP查询的场景。
列存----OLAP场景
建表语法
begin;
create table public.tbl_col (
id text NOT NULL,
name text NOT NULL,
class text NOT NULL,
in_time TIMESTAMPTZ NOT NULL,
PRIMARY KEY (id)
);
call set_table_property('public.tbl_col', 'orientation', 'column');
call set_table_property('public.tbl_col', 'clustering_key', 'class');
call set_table_property('public.tbl_col', 'bitmap_columns', 'name');
call set_table_property('public.tbl_col', 'event_time_column', 'in_time');
commit;
select * from public.tbl_col where id ='3333';
select id, class,name from public.tbl_col where id < '3333' order by id;
**
行存:
如果Hologres的表设置的是行存,那么数据将会按照行存储。行存默认使用SST格式,数据按照Key有序分块压缩存储,并且通过Block Index、Bloom Filter等索引,以及后台Compaction机制对文件进行整理,优化点查查询效率。
(推荐)设置主键Primary Key
系统会为每张表在底层存储一个主键索引文件,详情请参见主键Primary Key。行存表设置了Primary Key(PK)的场景,系统会自动生成一个Row Identifier(RID),RID用于定位整行数据,同时系统也会将PK设置为Distribution Key和Clustering Key,这样就能快速定位到数据所在的Shard和文件,在基于主键查询的场景上,只需要扫描一个主键就能快速拿到所有列的全行数据,提升查询效率,
行存主要针对点查的使用场景;
(不建议使用)设置的PK和Clustering Key不一致
但如果在建表时,设置表为行存表,且将PK和Clustering Key设置为不同的字段,查询时,系统会根据PK定位到Clustering Key和RID,再通过Clustering Key和RID快速定位到全行数据,相当于扫描了两次,有一定的性能牺牲,SQL示例如下。
综上:行存表非常适用于基于PK的点查场景,能够实现高QPS的点查。同时建表时建议只设置PK,系统会自动将PK设置为Distribution Key和Clustering Key,以提升查询性能。不建议将PK和Clustering Key设置为不同的字段,设置为不同的字段会有一定的性能牺牲。
行列共存:
在实际应用场景中,一张表可能用于主键点查,又用于OLAP查询,因此Hologres在V1.1版本支持了行列共存的存储格式。行列共存同时拥有行列和列存的能力,既支持高性能的基于PK点查,又支持OLAP分析。数据在底层存储时会存储两份,一份按照行存格式存储,一份按照列存格式存储,因此会带来更多的存储开销。
数据写入时,会同时写一份行存格式和写一份列存格式,只有两份数据都写完了才会返回成功,保证数据的原子性。
数据查询时,优化器会根据SQL,解析出对应的执行计划,执行引擎会根据执行计划判断走行存还是列存的查询效率更高,要求行列共存的表必须设置主键:
对于主键点查场景(如select * from tbl where pk=xxx语句)以及Fixed Plan加速SQL执行场景,优化器会默认走行存主键点查的路径。
对于非主键点查场景(如select * from tbl where col1=xx and col2=yyy语句),尤其是表的列很多,且查询结果需要展示很多列,行列共存针对该场景,优化器在生成执行计划时,会先读取列存表的数据,读取完成后根据列存键值Key查询行存表的数据,避免全表扫描,提升非主键查询性能。该场景能充分发挥行列共存的优势,提高数据的快速检索性能。
对于其他的普通查询,则会默认走列存。
因此行列共存表在通常查询场景,尤其是非主键点查场景,查询效率更好,。
这篇关于Hologres性能优化指南1:行存,列存,行列共存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




