本文主要是介绍python爬取robomaster论坛数据,作为后端数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一. 内容简介
python爬取robomaster论坛数据,作为后端数据
二. 软件环境
2.1vsCode
2.2Anaconda
version: conda 22.9.0
2.3代码
三.主要流程
3.1 接口分析
# 接口分析
# 全部数据
# https://bbs.robomaster.com/forum.php?mod=forumdisplay&fid=63 20
# 机械设计
# https://bbs.robomaster.com/forum.php?mod=forumdisplay&fid=63&filter=typeid&typeid=11 20
# 嵌入式
# https://bbs.robomaster.com/forum.php?mod=forumdisplay&fid=63&filter=typeid&typeid=12 20
# 视觉算法
# https://bbs.robomaster.com/forum.php?mod=forumdisplay&fid=63&filter=typeid&typeid=13 9
# 其他
# https://bbs.robomaster.com/forum.php?mod=forumdisplay&fid=63&filter=typeid&typeid=14
# 分页
# &filter=typeid&page=3
3.2 通过selenium爬取网页结构
大疆这个网站是直接在服务端渲染好的,只能从结构里面爬了,不能直接拿接口数据了,content是整个网页结构
import urllib.request
from lxml import etree
import json
from selenium.webdriver.common.by import By
from selenium import webdriver
import random
import time
import pyautogui
from datetime import datetime
import random
def seleniumRequest(url,chrome_path,waitTime): options = webdriver.ChromeOptions()options.add_experimental_option('excludeSwitches', ['enable-automation'])options.add_experimental_option('useAutomationExtension', False)# 谷歌浏览器exe位置options.binary_location = chrome_path# 是否要启动页面# options.add_argument("--headless") # 启用无头模式# GPU加速有时候会出bugoptions.add_argument("--disable-gpu") # 禁用GPU加速options.add_argument("--disable-blink-features=AutomationControlled")driver = webdriver.Chrome(options=options)driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})# 启动要填写的地址,这就启动浏览器driver.get(url)# 这是关闭浏览器# 等待页面加载,可以根据实际情况调整等待时间driver.implicitly_wait(waitTime)# 获取完整页面结构full_page_content = driver.page_source# 关闭浏览器driver.quit()return full_page_content
# # 处理完整页面结构
# print(full_page_content)
url = "https://bbs.robomaster.com/forum.php?mod=forumdisplay&fid=63&page=2"
print(url)chrome_path = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
waitTime = 8
# 获取网页结构
# 通过selenium调用浏览器访问
content = seleniumRequest(url,chrome_path,waitTime)
print(content)
3.2 从网页结构中爬出数据,存入json文件中
import random
from datetime import datetime, timedeltadef generate_random_date(start_date, end_date):random_days = random.randint(0, (end_date - start_date).days)random_date = start_date + timedelta(days=random_days)return random_date.strftime("%Y-%m-%d")start_date = datetime(2021, 1, 1)
end_date = datetime(2023, 12, 31)# 给html变成tree用于xpath解析用
tree = etree.HTML(content)
# 改进的XPath表达式,选择你感兴趣的div元素
# 解析对应数据
contents = tree.xpath("//*[starts-with(@id, 'normalthread')]")img = contents[0].xpath(".//*[@id='aaa']//img/@src")baseurl = " https://bbs.robomaster.com/"lists=[]
id = 1
for index, url in enumerate(contents):imgurl = contents[index].xpath(".//*[@id='aaa']//img/@src") imgurl = baseurl + imgurl[0]all = contents[index].xpath(".//p//a//text()")url = contents[index].xpath(".//p//a/@href")url = baseurl + url[1]# 题目title = all[1]end_index = title.find('】')title = all[1][end_index+1:]end_index= 0if title == None:continue# 作者name = all[2]if "作者" not in name:continue# 查看view = random.randint(1000, 50000)# 评论comment = all[3]if "回复" not in comment:continue# 时间time = generate_random_date(start_date, end_date)# print(index,url)item = {id: id,'imgurl': imgurl,'title':title,'name':name,'view':view,'comment':comment,'time':time,'type':1,'url': url}lists.append(item)id = id + 1
json_data = json.dumps(lists, indent=4)# 将JSON数据写入文件
with open("data.json", "w") as json_file:json_file.write(json_data)
print("JSON数据已保存到文件")
3.4 json存入数据库中
import json
import mysql.connector# 读取JSON文件
with open('data.json', 'r') as file:data = json.load(file)# 连接到MySQL数据库
conn = mysql.connector.connect(host='localhost',port=3306, # MySQL默认端口号user='root',password='1234qwer',database='competitionassistant'
)cursor = conn.cursor()# 创建表(如果不存在的话),并清空表数据# item = {# id: id,# 'imgurl': imgurl,# 'title':title,# 'name':name,# 'view':view,# 'comment':comment,# 'time':time,# 'type':1# }cursor.execute('''
CREATE TABLE IF NOT EXISTS form_list (id INT AUTO_INCREMENT PRIMARY KEY,imgurl VARCHAR(128),title VARCHAR(128),name VARCHAR(64),view VARCHAR(16),comment VARCHAR(16),time VARCHAR(16),type INT,url VARCHAR(128)
)
''')
# 先清空一下表cursor.execute('TRUNCATE TABLE form_list')
# 将数据插入数据库
for item in data:# print(item)# cursor.execute('''# INSERT INTO index_img (img_url, prod_id, seq, status, create_time, update_time)# VALUES (%s, %s, %s, %s, %s, %s)# ''', (item['img_url'], item['prod_id'], item['seq'], item['status'], item['create_time'], item['update_time']))sql_statement = f"""INSERT INTO form_list (imgurl, title, name, view, comment, time, type, url)VALUES ('{item['imgurl']}', '{item['title']}', '{item['name']}', '{item['view']}', '{item['comment']}', '{item['time']}', '{item['type']}', '{item['url']}')"""print(sql_statement)cursor.execute(sql_statement)print()
# 提交更改并关闭连接
conn.commit()
conn.close()3.4 结果
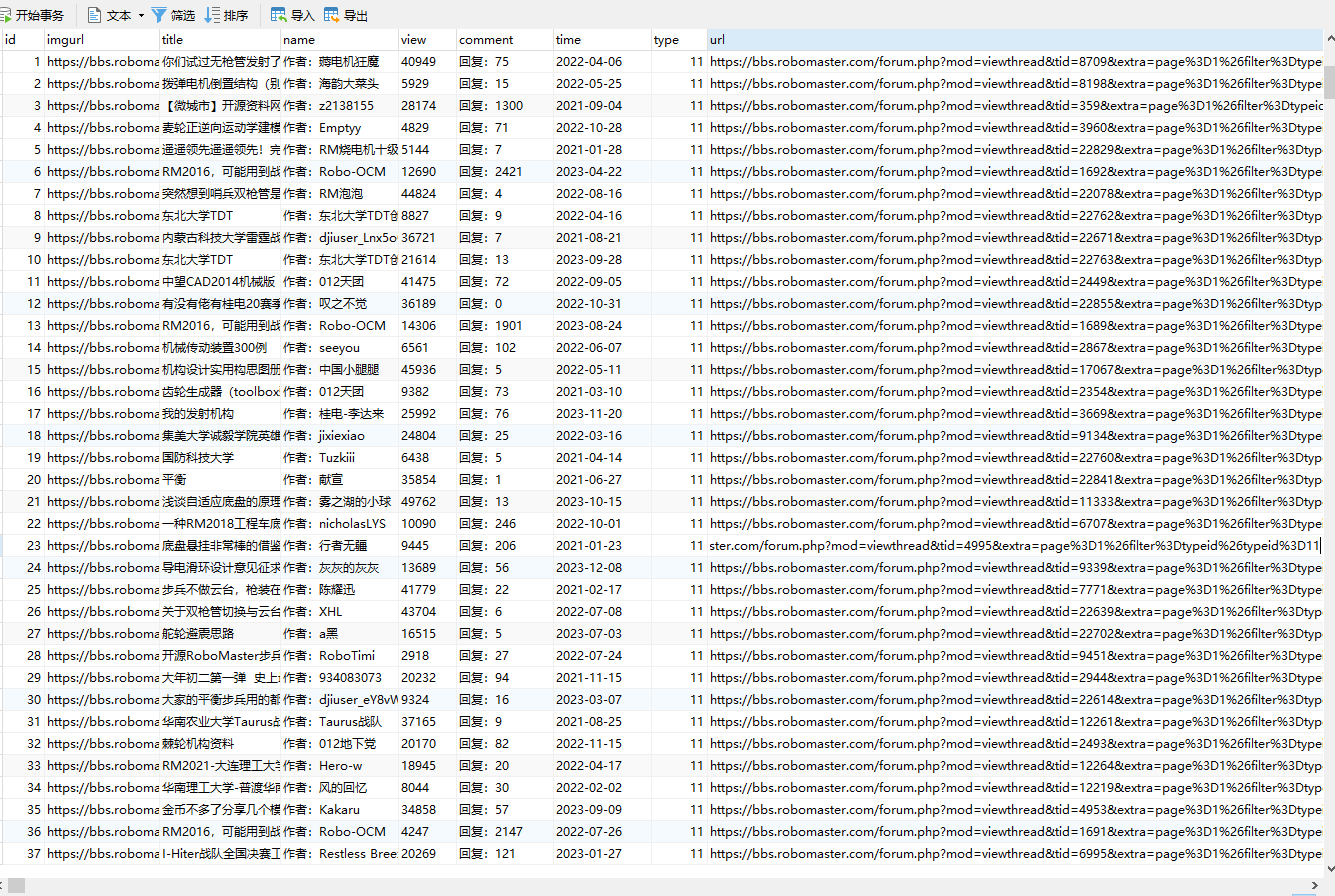
这篇关于python爬取robomaster论坛数据,作为后端数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






