本文主要是介绍[跑代码]BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Installation(下载代码-装环境)
conda create -n bk-sdm python=3.8
conda activate bk-sdm
git clone https://github.com/Nota-NetsPresso/BK-SDM.git
cd BK-SDM
pip install -r requirements.txtNote on the torch versions we've used
-
torch 1.13.1for MS-COCO evaluation & DreamBooth finetuning on a single 24GB RTX3090
-
torch 2.0.1for KD pretraining on a single 80GB A10
火炬2.0.1在单个80GB A100上进行KD预训练-
如果A100上总批大小为256的预训练导致gpu内存不足,请检查torch版本并考虑升级到torch>2.0.0。
我的版本也是torch2.0.1 单个A100(80G)理论上吃的下256batch 
-
小的例子
PNDM采样器 50步去噪声
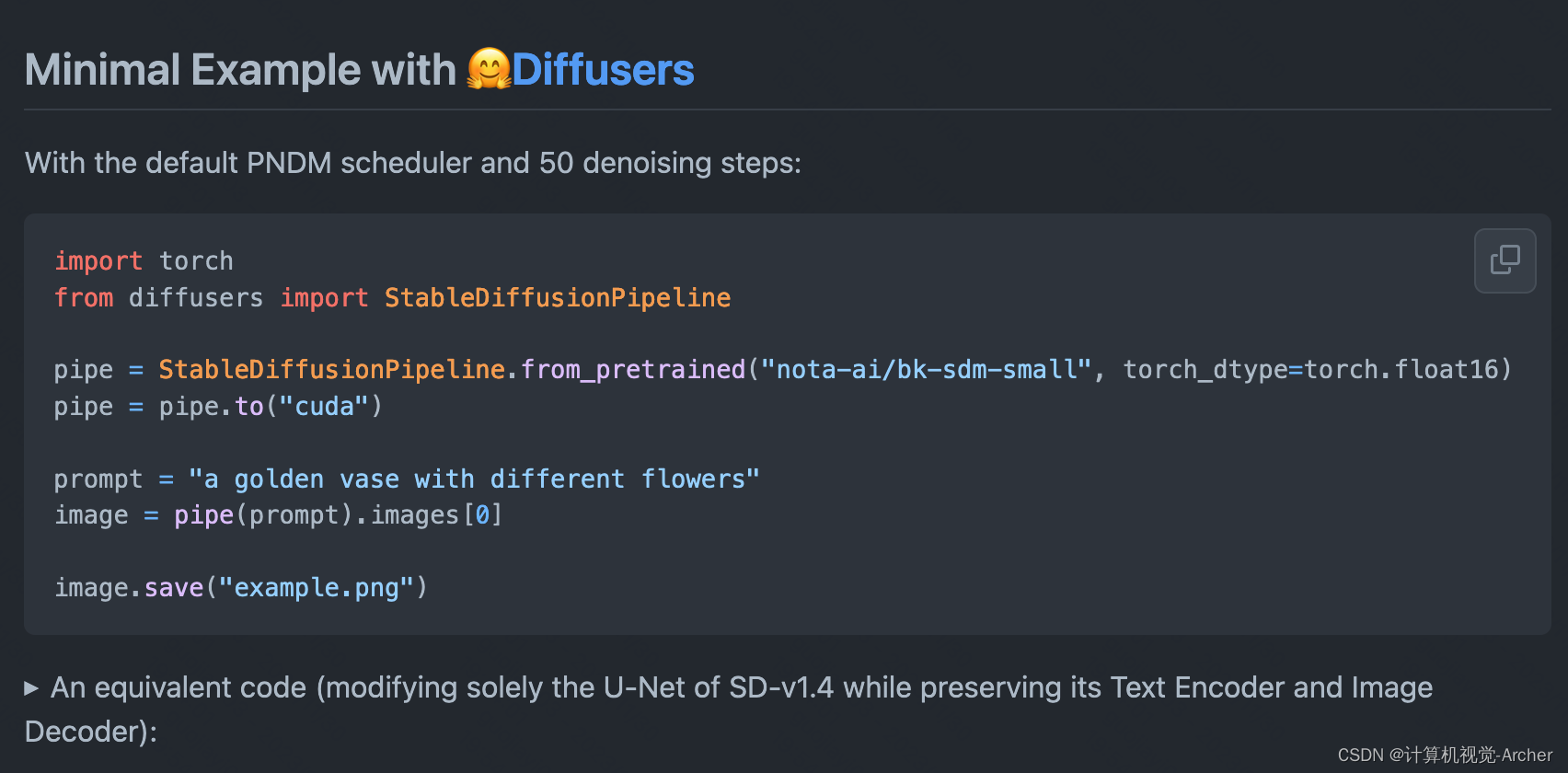
等效代码(仅修改SD-v1.4的U-Net,同时保留其文本编码器和图像解码器):
Distillation Pretraining
Our code was based on train_text_to_image.py of Diffusers 0.15.0.dev0. To access the latest version, use this link.
BK-SDM的diffusers版本0.15
我的diffusers版本比较高0.24.0
检测是否能够训练(先下载数据集get_laion_data.sh再运行代码kd_train_toy.sh)
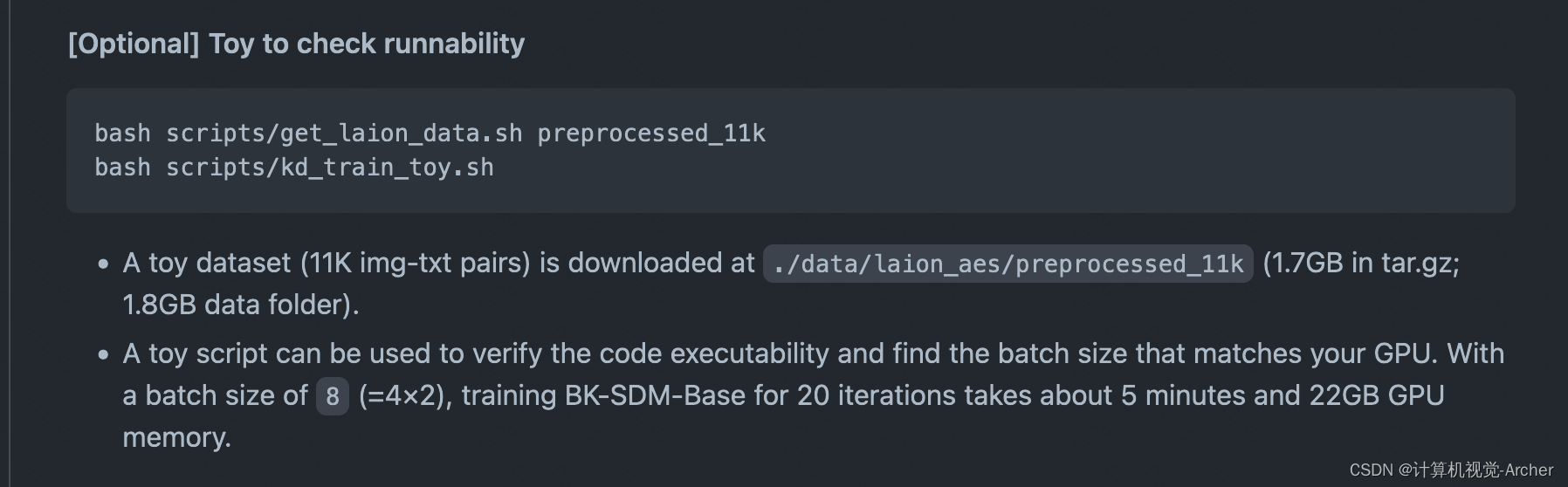
1 一个玩具数据集(11K的img-txt对)下载到。
bash scripts/get_laion_data.sh preprocessed_11k/data/laion_aes/preprocessed_11k (1.7GB in tar.gz;1.8GB数据文件夹)。
get_laion_data.sh
需要修改,实际就是下载这三个数据集,我自行下载
# https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/data/improved_aesthetics_6.5plus/preprocessed_11k.tar.gz
# https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/data/improved_aesthetics_6.5plus/preprocessed_212k.tar.gz
# https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/data/improved_aesthetics_6.5plus/preprocessed_2256k.tar.gz我修改后下载文件名 https://... .../preprocessed_11k.tar.gz直接粘贴到网址里面也可以下载
wget $S3_URL -0 $FILe_PATH
$S3_URL 就是这个网址
$FILe_PATH 就是下载路径./data/laion_aes/preprocessed_11k
DATA_TYPE=$"preprocessed_11k" # {preprocessed_11k, preprocessed_212k, preprocessed_2256k}
FILE_NAME="${DATA_TYPE}.tar.gz"DATA_DIR="./data/laion_aes/"
FILE_UNZIP_DIR="${DATA_DIR}${DATA_TYPE}"
FILE_PATH="${DATA_DIR}${FILE_NAME}"if [ "$DATA_TYPE" = "preprocessed_11k" ] || [ "$DATA_TYPE" = "preprocessed_212k" ]; thenecho "-> preprocessed_11k or 212k"S3_URL="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/data/improved_aesthetics_6.5plus/${FILE_NAME}"
elif [ "$DATA_TYPE" = "preprocessed_2256k" ]; thenS3_URL="https://netspresso-research-code-release.s3.us-east-2.amazonaws.com/data/improved_aesthetics_6.25plus/${FILE_NAME}"
elseecho "Something wrong in data folder name"exit
fiwget $S3_URL -O $FILE_PATH
tar -xvzf $FILE_PATH -C $DATA_DIR
echo "downloaded to ${FILE_UNZIP_DIR}"2 一个小脚本可以用来验证代码的可执行性,并找到与你的GPU匹配的批处理大小。
批量大小为8 (=4×2),训练BK-SDM-Base 20次迭代大约需要5分钟和22GB的GPU内存。
bash scripts/kd_train_toy.shMODEL_NAME="CompVis/stable-diffusion-v1-4"
TRAIN_DATA_DIR="./data/laion_aes/preprocessed_11k" # please adjust it if needed
UNET_CONFIG_PATH="./src/unet_config"UNET_NAME="bk_small" # option: ["bk_base", "bk_small", "bk_tiny"]
OUTPUT_DIR="./results/toy_"$UNET_NAME # please adjust it if neededBATCH_SIZE=2
GRAD_ACCUMULATION=4StartTime=$(date +%s)CUDA_VISIBLE_DEVICES=1 accelerate launch src/kd_train_text_to_image.py \--pretrained_model_name_or_path $MODEL_NAME \--train_data_dir $TRAIN_DATA_DIR\--use_ema \--resolution 512 --center_crop --random_flip \--train_batch_size $BATCH_SIZE \--gradient_checkpointing \--mixed_precision="fp16" \--learning_rate 5e-05 \--max_grad_norm 1 \--lr_scheduler="constant" --lr_warmup_steps=0 \--report_to="all" \--max_train_steps=20 \--seed 1234 \--gradient_accumulation_steps $GRAD_ACCUMULATION \--checkpointing_steps 5 \--valid_steps 5 \--lambda_sd 1.0 --lambda_kd_output 1.0 --lambda_kd_feat 1.0 \--use_copy_weight_from_teacher \--unet_config_path $UNET_CONFIG_PATH --unet_config_name $UNET_NAME \--output_dir $OUTPUT_DIREndTime=$(date +%s)
echo "** KD training takes $(($EndTime - $StartTime)) seconds."单GPU训练BK-SDM{Base, Small, Tiny}-0.22M数据训练
bash scripts/get_laion_data.sh preprocessed_212k
bash scripts/kd_train.sh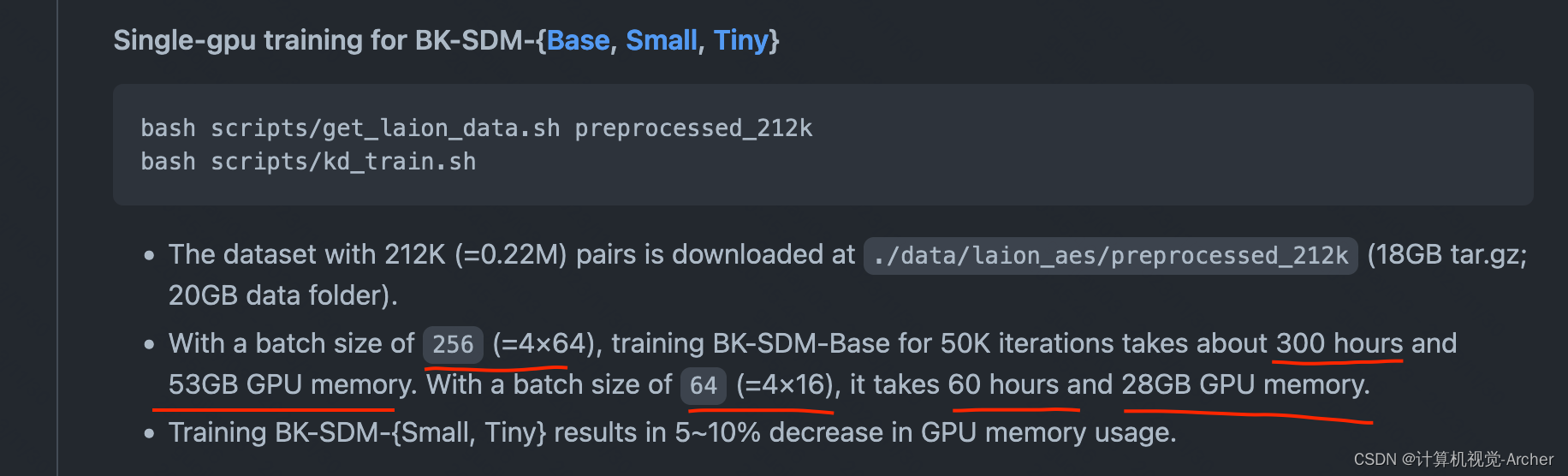
1 下载数据集preprocessed_212k
2 训练kd_train.sh
(256batch 训练BD-SM-Base 50K轮次需要300hours/53G单卡)
(64batch 训练BD-SM-Base 50K轮次需要60hours/28G单卡) 不理解?
单GPU训练BK-SDM{Base, Small, Tiny}-2.3M数据训练
这篇关于[跑代码]BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






