本文主要是介绍Re51:读论文 Language Models as Knowledge Bases?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Language Models as Knowledge Bases?
ArXiv网址:https://arxiv.org/abs/1909.01066
官方GitHub项目:https://github.com/facebookresearch/LAMA
本文是2019年EMNLP论文,作者来自脸书和伦敦大学学院。
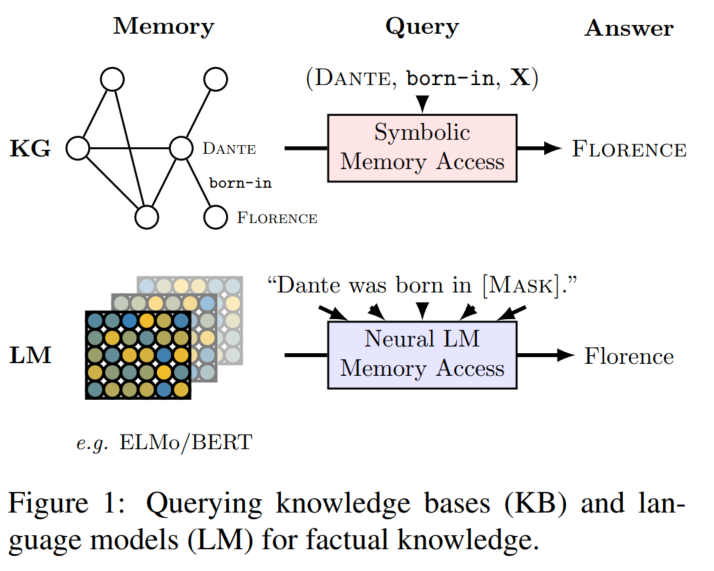
本文关注LM中蕴含的知识,想要探索的问题是,通过在大型的文本语料上进行预训练,语言模型是否已经(或是有潜力)学习到并存储下了一些事实知识(主体-关系-客体形式的三元组 (subject, relation, object) 或是问题-答案对)?
本文通过将事实三元组转换为自然语言形式,让LM(未经过微调的)用完形填空的形式来预测其中的object(把relation反过来也能预测subject),来进行这一探查:LAMA (LAnguage Model Analysis)
评估正确结果的排序
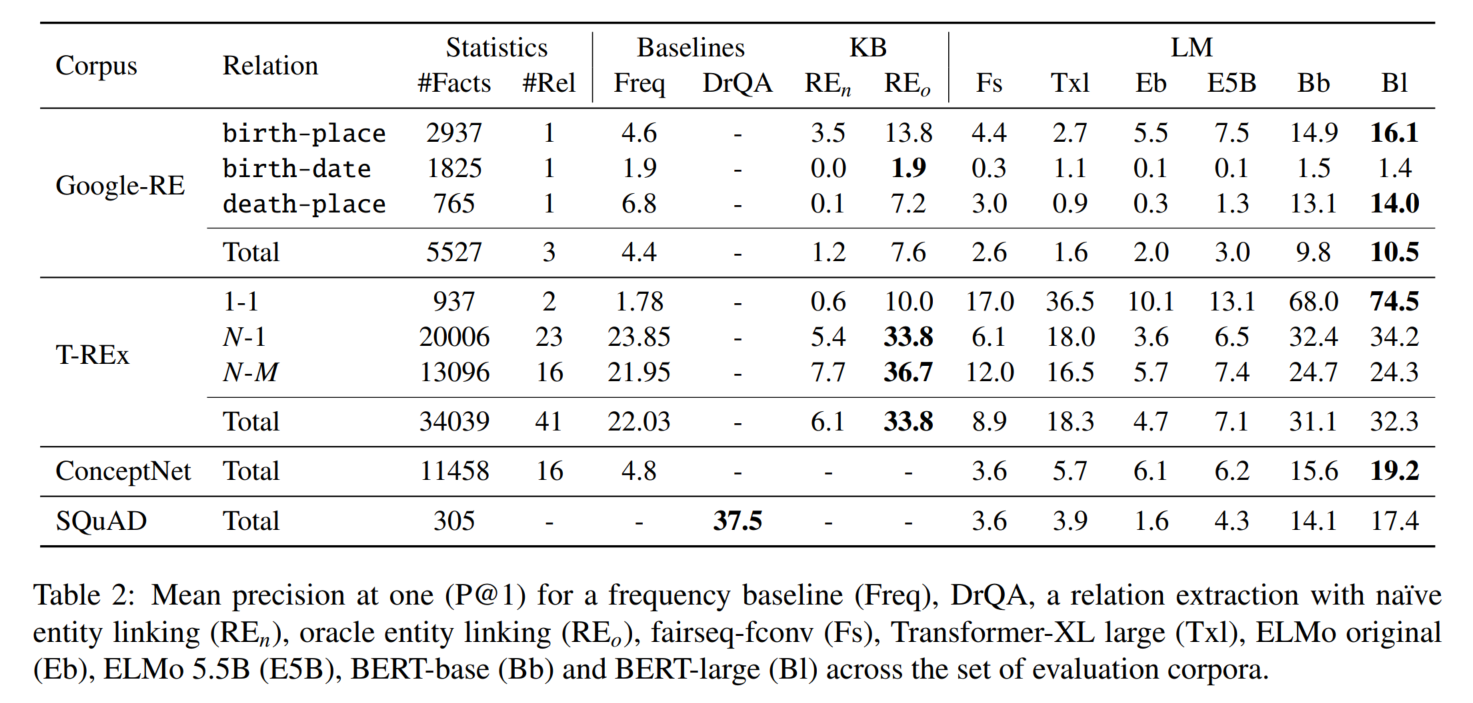
实验结论:1. BERT表现很好,可以匹敌传统的有监督学习方法 2. LM对有些知识比其他知识学得更好(N-to-M 关系表现较差)
(什么1984经典句式)
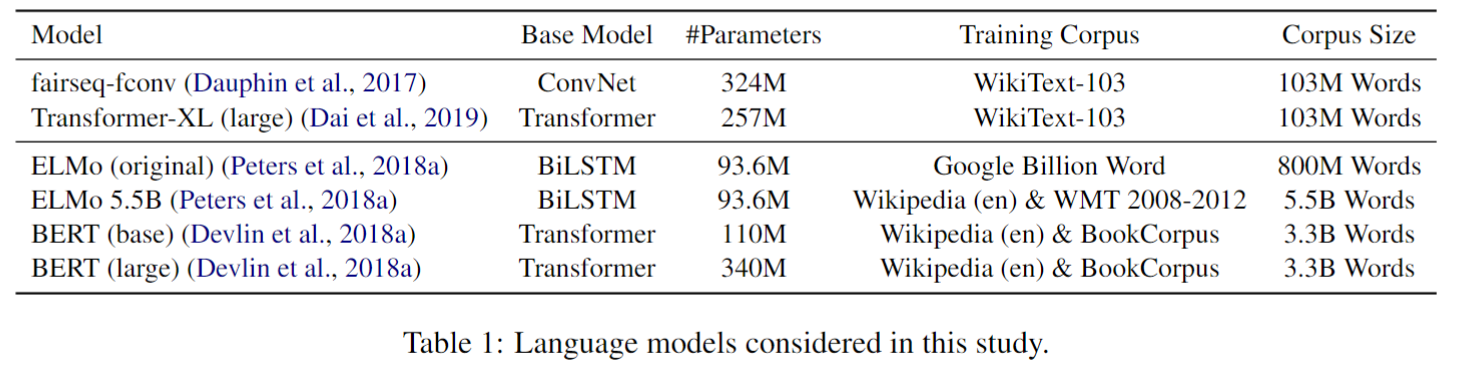
实验用的LM:
单向LM & 双向LM
baseline包括纯统计学习的、预训练的关系抽取模型、DrQA(先检索相似文档,再做阅读理解)
实验用的事实数据集来自关系数据集Google-RE、T-REx、ConceptNet,将每一种关系手工转换为填空题。原数据集中就有三元组对应的文本。
再加上QA数据集SQuAD
仅选择只有一个token的场景。
↑注意这里,模版的选择会影响结果。所以本文认为手工制作模版只能说是给出了一个LM知识的下限水平。
指标:P@k
P@1:
P@k:
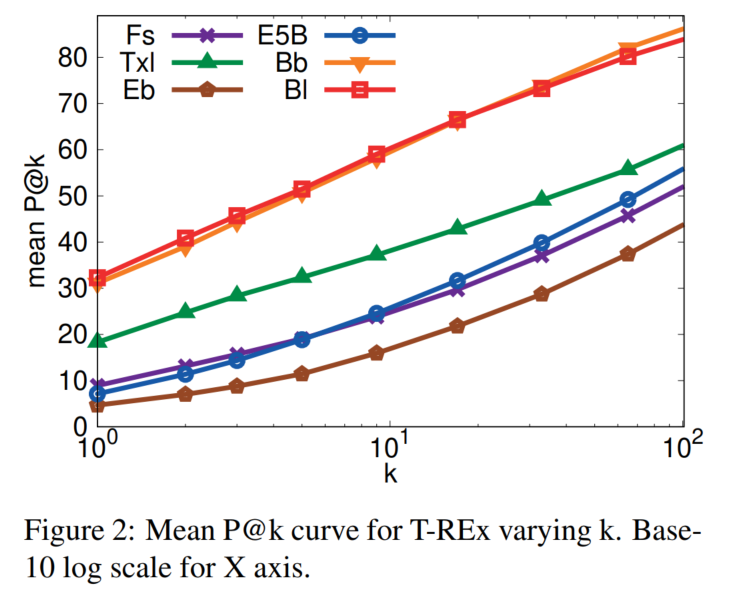
出现频率越高、实体越相似、subject越长,指标越高
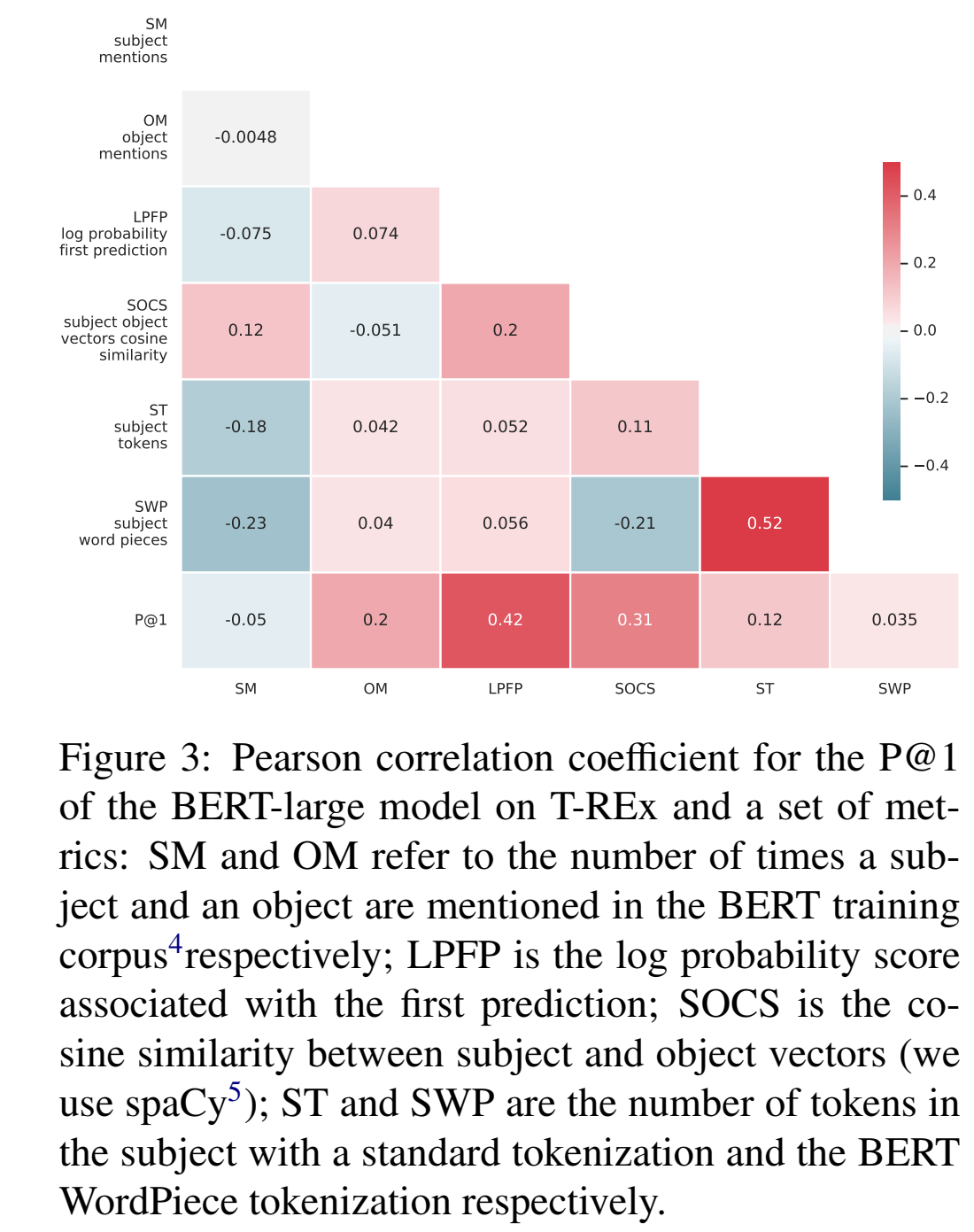
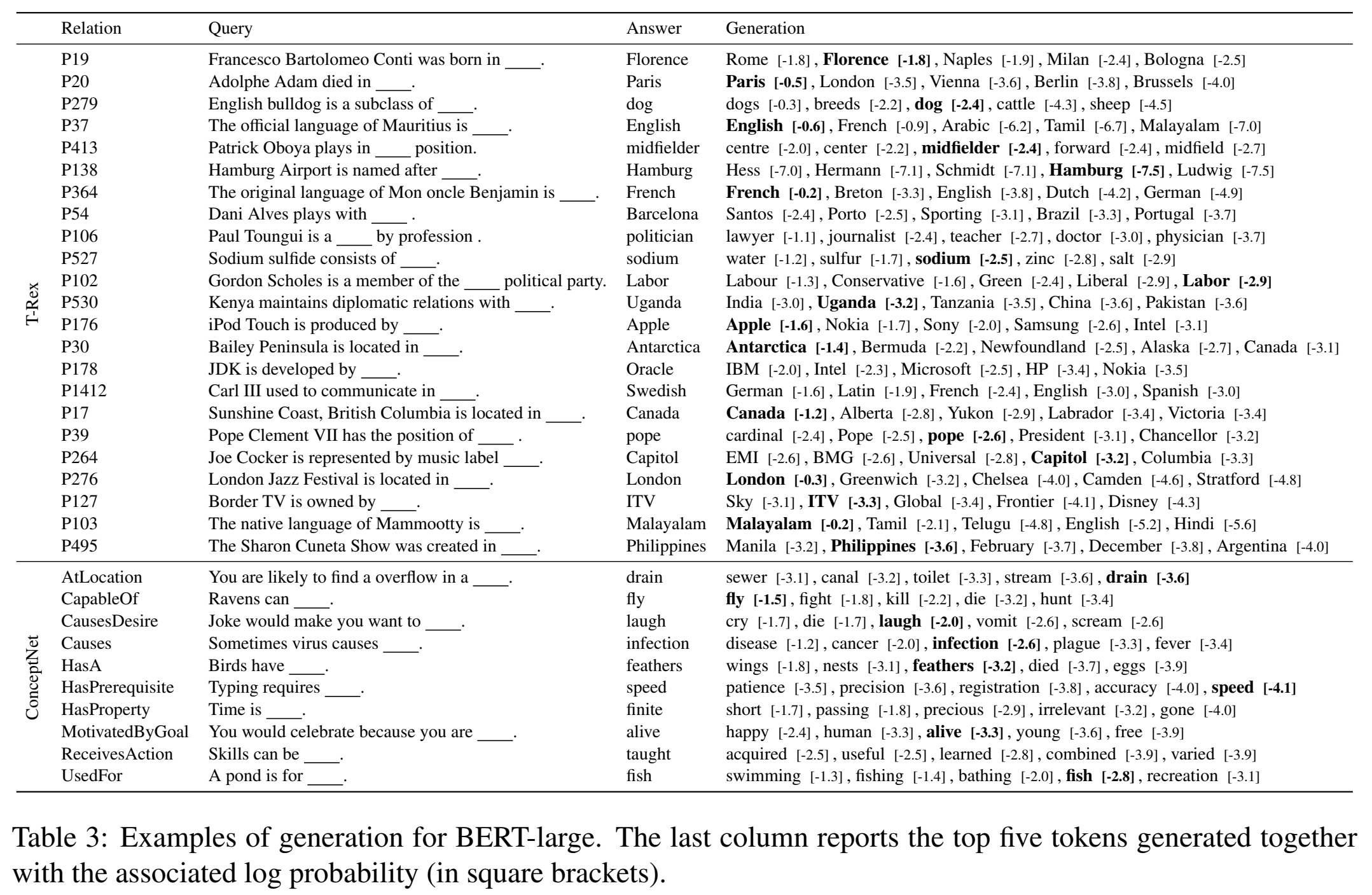
案例分析:
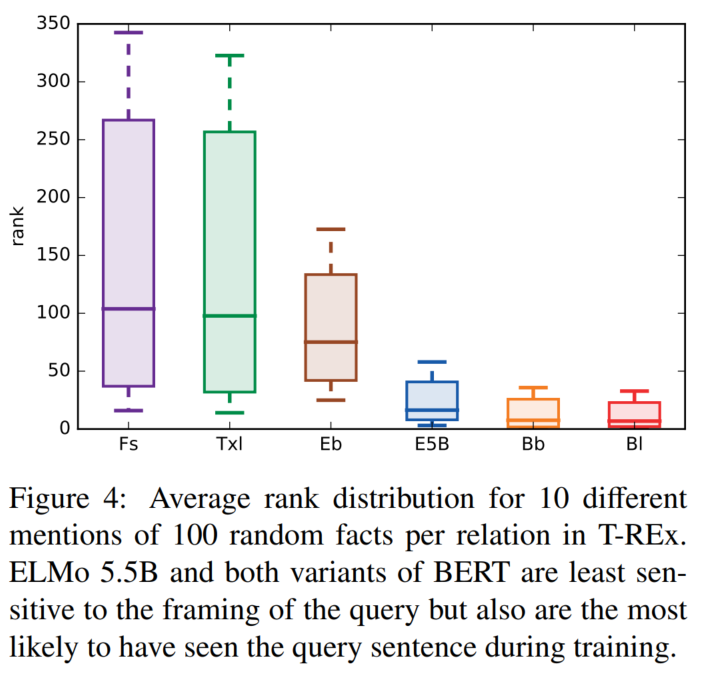
这篇关于Re51:读论文 Language Models as Knowledge Bases?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

