本文主要是介绍【论文复现】RoSteALS: Robust Steganography using Autoencoder Latent Space-2023-CVPR,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码链接:https://github.com/TuBui/RoSteALS
一定要按照dockerfile,requirements.txt和requirements2.txt配置环境
需要补充的库:
pip安装:omegaconf slack slackclient bchlib (0.14.0版本) einops imagenet-c
conda安装:scikit-image,matplotlib
按照作者git的dependency配置环境的话就不会出现下面的3和4问题
遇见的bug
- No module ‘xformers’. Proceeding without it.
参考官网Installing xFormers:https://github.com/facebookresearch/xformers
conda install xformers -c xformers
需要python版本>=3.9,这是个加速库,不装也可以运行(我没装)
-
Import Error: MagickWand shared library not found
解决方案:Ubuntu安装imagemagick这个软件,因为sudo apt-get install libmagickwand-dev一直报依赖的错装不上,我是在官网下载源码编译成功安装的, 此外还要装apt-get install python-wand官网链接:https://docs.wand-py.org/en/latest/guide/install.html#install-wand-on-debian-ubuntu
ModuleNotFoundError: No module named 'pytorch_lightning.utilities.distributed'
版本问题,pytorch_lightning如果高于1.6.5就会出现,可以降级到1.4.2
解决方案:将from pytorch_lightning.utilities.distributed import rank_zero_only
修改为:from pytorch_lightning.utilities.rank_zero import rank_zero_only
-
版本问题Traceback (most recent call last):File "/root/autodl-tmp/RoSteALS/train.py", line 133, in <module>app(args)File "/root/autodl-tmp/RoSteALS/train.py", line 118, in apptrainer_kwargs.update(trainer_settings(config, output))File "/root/autodl-tmp/RoSteALS/train.py", line 55, in trainer_settingslogger = instantiate_from_config(logger)File "/root/autodl-tmp/RoSteALS/ldm/util.py", line 79, in instantiate_from_configreturn get_obj_from_str(config["target"])(**config.get("params", dict()))File "/root/autodl-tmp/RoSteALS/ldm/util.py", line 87, in get_obj_from_strreturn getattr(importlib.import_module(module, package=None), cls) AttributeError: module 'pytorch_lightning.loggers' has no attribute 'TestTubeLogger'. Did you mean: 'NeptuneLogger'?
解决:https://github.com/Lightning-AI/lightning/issues/13958
使用CSVLogger
ImportError: cannot import name ‘VectorQuantizer2’ from ‘taming.modules.vqvae.quantize’ (/root/miniconda3/envs/RoSte/lib/python3.8/site-packages/taming/modules/vqvae/quantize.py)
解决方案:
按 https://github.com/CompVis/stable-diffusion/issues/72 中的方法处理,即用 https://github.com/CompVis/taming-transformers/blob/master/taming/modules/vqvae/quantize.py 新文件,替换错误提示文件中的全部内容即可。
注意bchlib的版本是0.14.0 ,不然运行inference的时候会出错
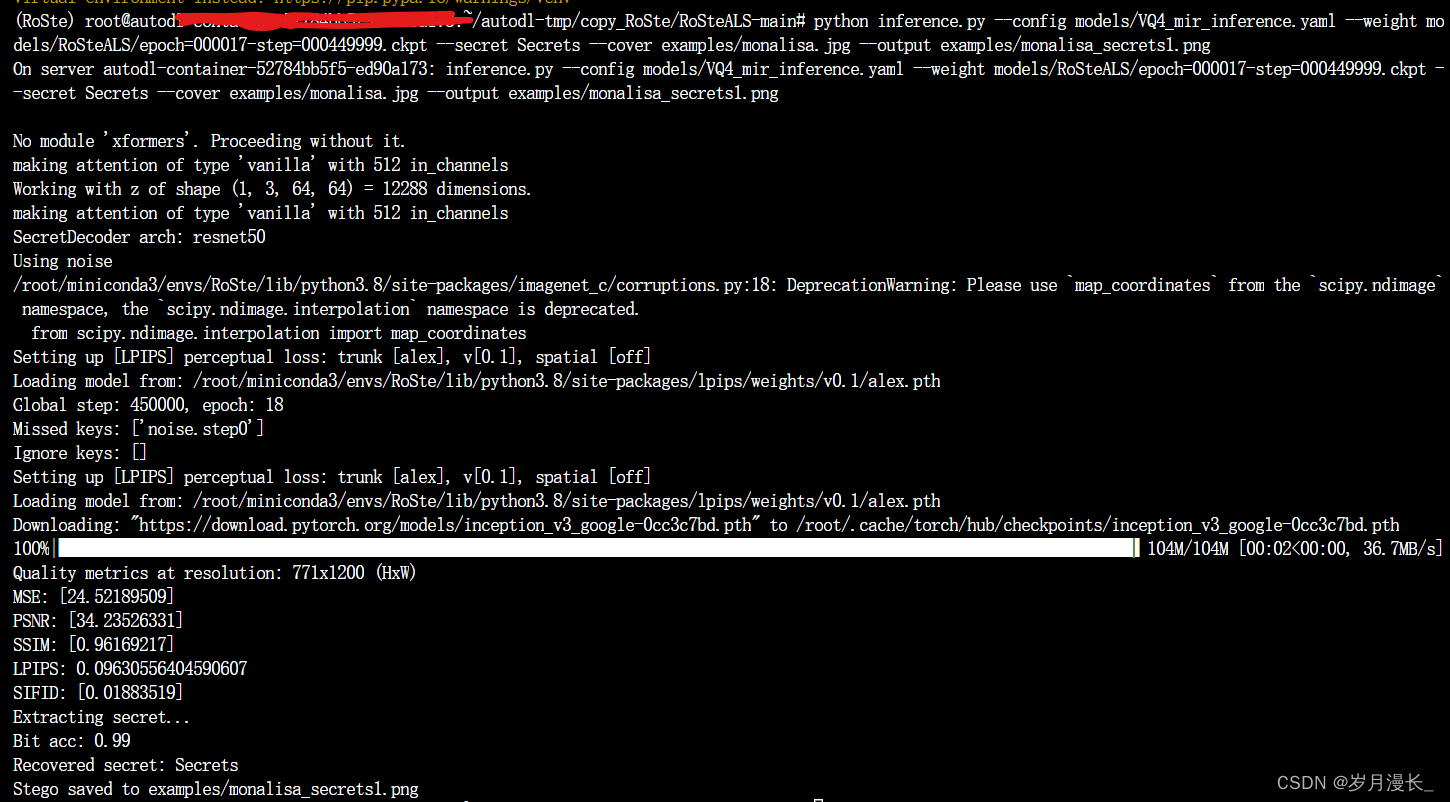
复现成功!
这篇关于【论文复现】RoSteALS: Robust Steganography using Autoencoder Latent Space-2023-CVPR的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
