本文主要是介绍YOLO改进系列之SKNet注意力机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
视皮层神经元的感受野大小受刺激的调节即对于不同的刺激,卷积核的大小应该不同,但在构建CNN时一般在同一层只采用一种卷积核,很少考虑因采用不同卷积核。于是SKNet被提出,在SKNet中,不同大小的感受视野(卷积核)对于不同尺度的目标会有不同的效果。尽管在Inception中使用多个卷积核来适应不同尺度图像,但是卷积核权重相同,也就是参数就是被计算好的了。而SKNet 对不同输入使用的卷积核感受野不同,参数权重也不同,可以根据输入大小自适应地进行处理。SKNet提出一种动态选择机制,允许每个神经元根据输入信息的多个尺度自适应调整其接受野的大小。设计了一种称为选择性内核(Selective Kernel)单元的构建模块,在该模块中,由不同内核大小的多个分支的信息引导,使用Softmax的注意力进行融合,从而对这些分支的不同关注导致融合层神经元有效感受野的大小不同。
论文地址:https://arxiv.org/pdf/1903.06586.pdf
代码地址:https://github.com/implus/SKNet
模型结构
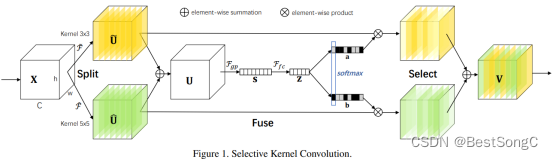
SKNet网络主要由三个部分组成:Split、Fuse、Select。其中,Split部分将输入信息分别输入不同的核大小(这里是2个卷积核,卷积核大小分别为:33 和 55);Fuse部分进行特征融合;Select部分根据计算得到的权重对相应的特征进行选择操作。
Split部分
对于输入信息X,在Split中分别输入两个卷积层(默认为2个,根据需要可以设计多个),两个卷积核的尺寸分别为33和55。其中,每个卷积层都是由高效的分组/深度卷积、批处理归一化和ReLU函数依次组成的。另外,为了进一步提高效率,将具有5*5核的传统卷积替换为具有3×3核和膨胀大小为2的扩展卷积。最终得到中间层输出特征图。
Fuse部分
基本思想是使用门来控制来自多个分支的信息流,这些分支携带不同尺度的信息到下一层的神经元中。为实现这一目标,门需要整合来自所有分支的信息。该模块首先通过Element-wise Summation操作来融合来自多个分支的结果,再使用全局平均池化以生成Channel-wise统计信息来生成全局信息,此外还创建一个紧凑的特征z以便为精确和自适应选择提供指导,这是通过一个简单的全连接层实现的,降低了维度同时提高效率。
Select部分
Select操作使用a和b两个权重矩阵分别对中间层输入特征图进行加权操作,然后求和得到最终的输出向量。
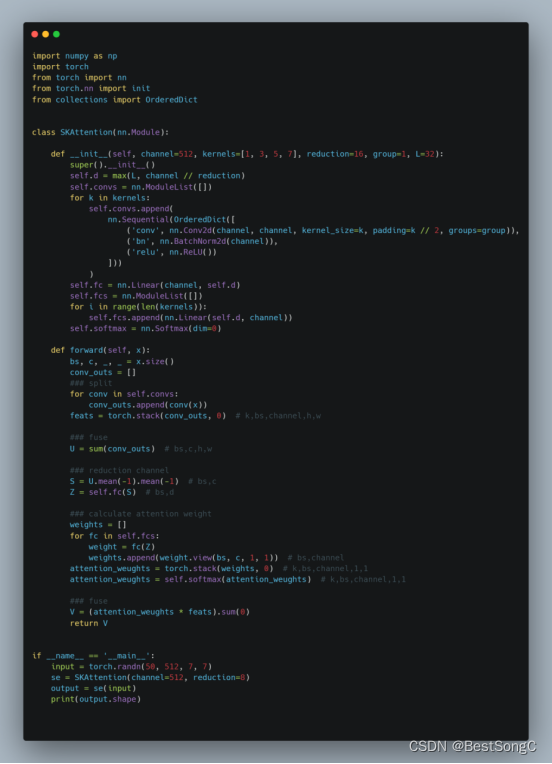
实现代码
YOLOv5模型改进
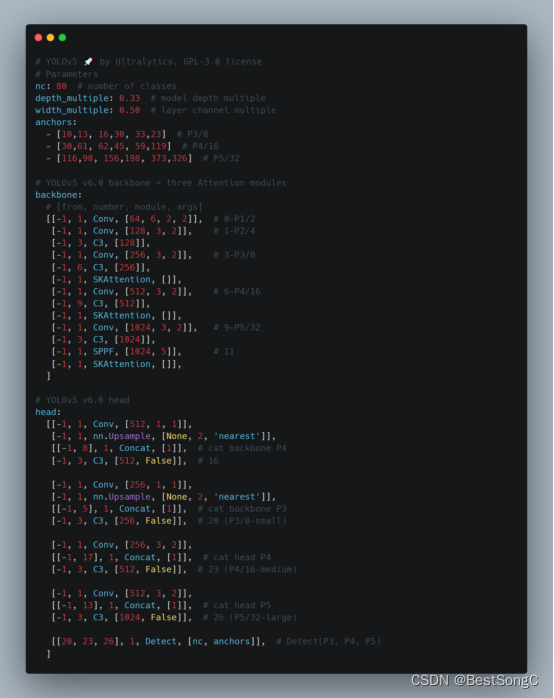
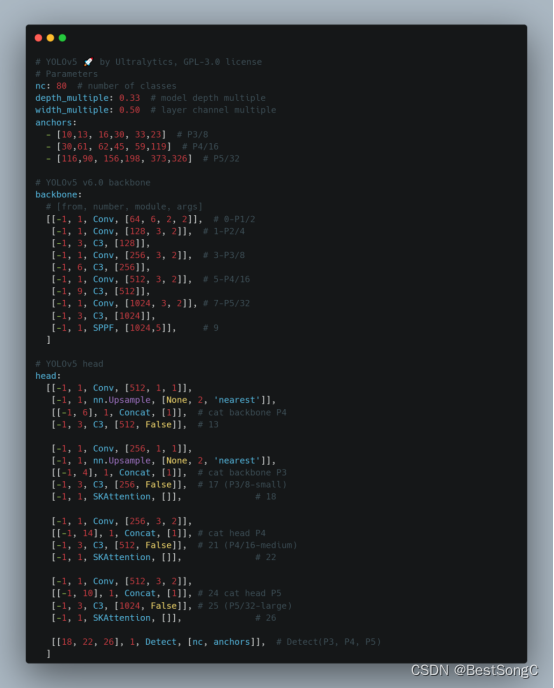
本文在YOLOv5目标检测算法的Backbone和Head部分分别加入SKAttention来增强目标提取能力,以下分别是在Backbone以及Head中改进的模型结构和参数(以YOLOv5s为例)。
在Backbone部分
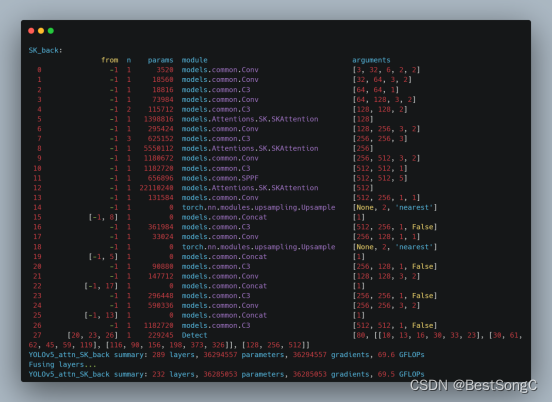
在Head部分
总结
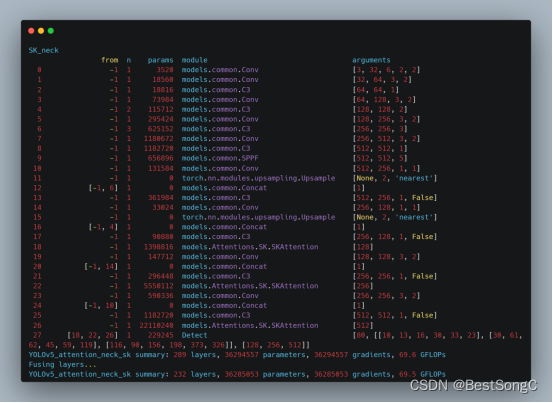
SKNet中使用了不同的卷积核,且卷积核权重是不同的,这有助于模型学习不同尺寸目标的特征信息,其被广泛应用于图像分类、目标检测、语义分割等计算机视觉任务。本文在YOLOv5目标检测算法基础上引入SKAttention来进一步增强模型对多尺寸目标的特征提取能力,并输出改进后模型每层的输出与模型参数、梯度和计算量。此外,SKAttention可进一步应用于YOLOv7、YOLOv8等模型中,欢迎大家关注本博主的微信公众号 BestSongC,后续更多的资源如模型改进、可视化界面等都会在此发布。另外,本博主最近也在MS COCO数据集上跑了一些YOLOv5的改进模型,实验表明改进后的模型能在MS COCO 2017验证集上分别涨点1-3%,感兴趣的朋友关注后回复YOLOv5改进
这篇关于YOLO改进系列之SKNet注意力机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





