本文主要是介绍tea加密 android,使用tea算法对数据进行加密,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对QQ协议进行分析过的同学可能知道,QQ的数据传输是使用tea算法进行的加密。
tea算法是一种对称加密算法,特点是速度快,代码量小(加密、解密的核心算法总共才20来行)。算法的安全性虽然不比AES,但其算法的破译难度取决于其迭代的次数。网上说QQ是16次迭代,推荐的迭代次数是64次。我就对这些简洁小巧的事物没有抗拒力,于是在网上搜索一下其代码,研究一下。
找到了一个别人封装好的类,很好用,我一会打包起来给大家。
我对代码进行了处理,写了一个简单的加密字符串的软件。
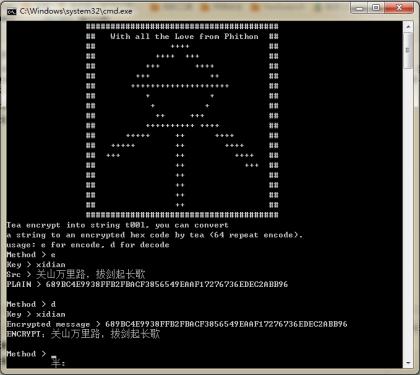
首先引用了网上的一个类,很简洁的90行代码,其中加密的方法是:
TEA tea(key, TIMES, false);
tea.encrypt(plain, crypt);
解密的方法是:
TEA tea(key, TIMES, false);
tea.decrypt(crypt, plain);
构造函数中传入密钥key,TIMES是迭代次数,我用的64次,第三个参数是“是否专为网络序”,如果加密完成后的密文不在网络上传输的话,就填false。
encrypt方法对密文进行加密,plain是明文,crypt是输出密文的缓冲区。而decrypt方法正好相反。
下面是几点要注意的:
第一,plain、key、crypt三个参数类型都是byte *,也就unsigned char *,里面保存的是二进制码,是不能直接输出在屏幕上的,所以你如果要加密字符串,输出hex,就得加一些代码处理一下。如果大家加密一个文件的话,就不用处理了。
第二,key长度16bit,所以我用了一个md5处理之。将我们输入的任意长度的字符串先hash成md5,再作为一个16bit的key传入tea的构造函数。
第三,加密时,明文长度必须是8bit,于是我把明文分成许多8bit的段,将每段密文加密。如果密文密文长度不是8的倍数,则我会在最后一段明文后面补随机二进制位,凑成8bit。所以一段明文加密出来的结果可能不相同,但不相同的一定是最后8bit,前面都应该是一样的。而最后8bit中有效长度,我就放在密文的第一位。所以密文一定是奇数长度。
我在网上看QQ的TEA加密是这样两个技巧:和我类似补随机二进制位补齐8的倍数,但采用了交织算法:消息被分为多个加密单元,每一个加密单元都是8字节,使用TEA进行加密,加密结果与下一个加密单元做异或运算后再作为待加密的明文。
这样感觉会更加复杂和安全一点,但我嫌麻烦就没这么处理了。如果对安全性要求更高的同学可以自己下去稍微一改。
我把源文件打包给大家,里面包含了我的整个工程。附件中自己下。大家可以根据自己的需要进行修改。
这篇关于tea加密 android,使用tea算法对数据进行加密的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




