本文主要是介绍Elasticsearch:ES|QL 查询中的元数据字段及多值字段,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在今天的文章里,我来介绍一下 ES|QL 里的元数据字段以及多值字段。我们可以利用这些元数据字段以及多值字段来针对我们的查询进行定制。这里例子的数据集,请参考文章 “Elasticsearch:ES|QL 快速入门”。
ES|QL 源数据字段
ES|QL 可以访问元数据字段。 目前支持的有:
- _index:文档所属的索引名称。 该字段的类型为关键字。
- _id:源文档的 ID。 该字段的类型为关键字。
- _version:源文档的版本。 该字段的类型为 long。
要启用对这些字段的访问,需要为 FROM source 命令提供专用指令:
FROM index [METADATA _index, _id]仅当数据源是索引时元数据字段才可用。 因此,FROM 是唯一支持 METADATA 指令的源命令。比如,
POST _query?format=txt
{"query": """FROM sample_data [METADATA _index, _id]| LIMIT 3"""
}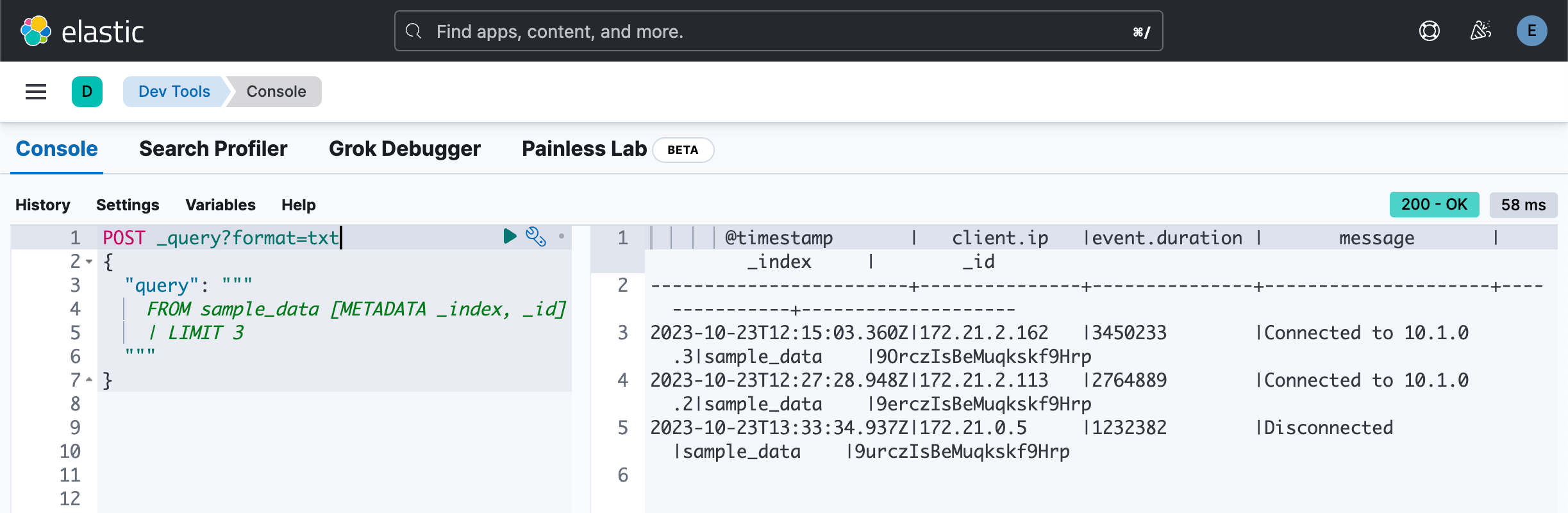
从上面的返回数据中,我们可以看到 _index 及 _id 返回索引名称 sample_data 及文档的 ID。
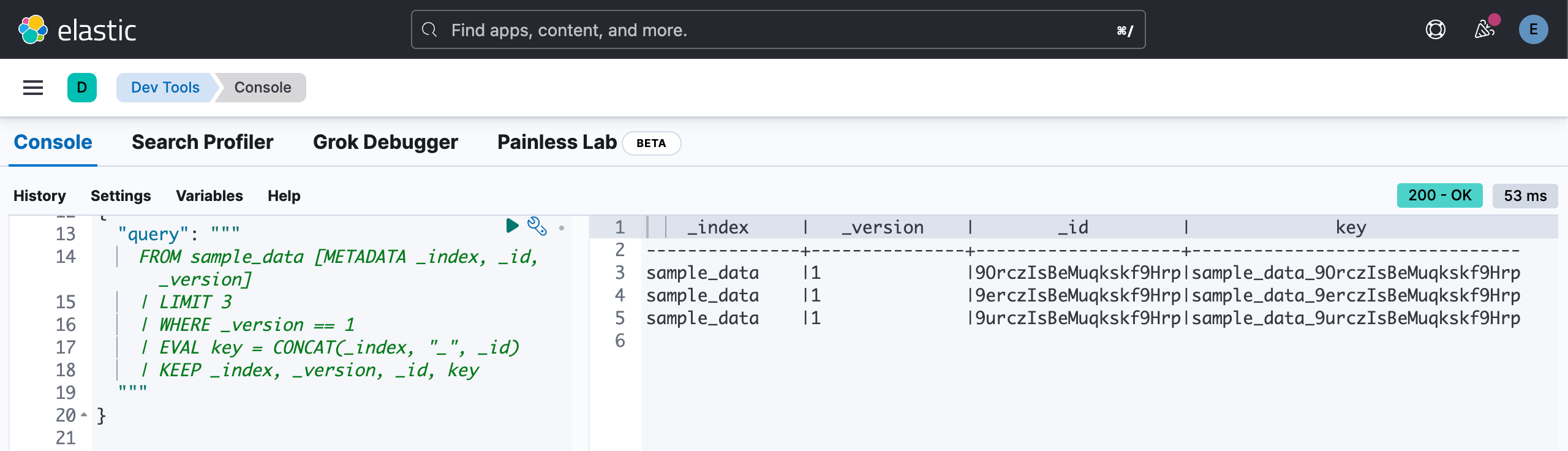
POST _query?format=txt
{"query": """FROM sample_data [METADATA _index, _id, _version]| LIMIT 3| WHERE _version == 1| EVAL key = CONCAT(_index, "_", _id)| KEEP _index, _version, _id, key"""
}
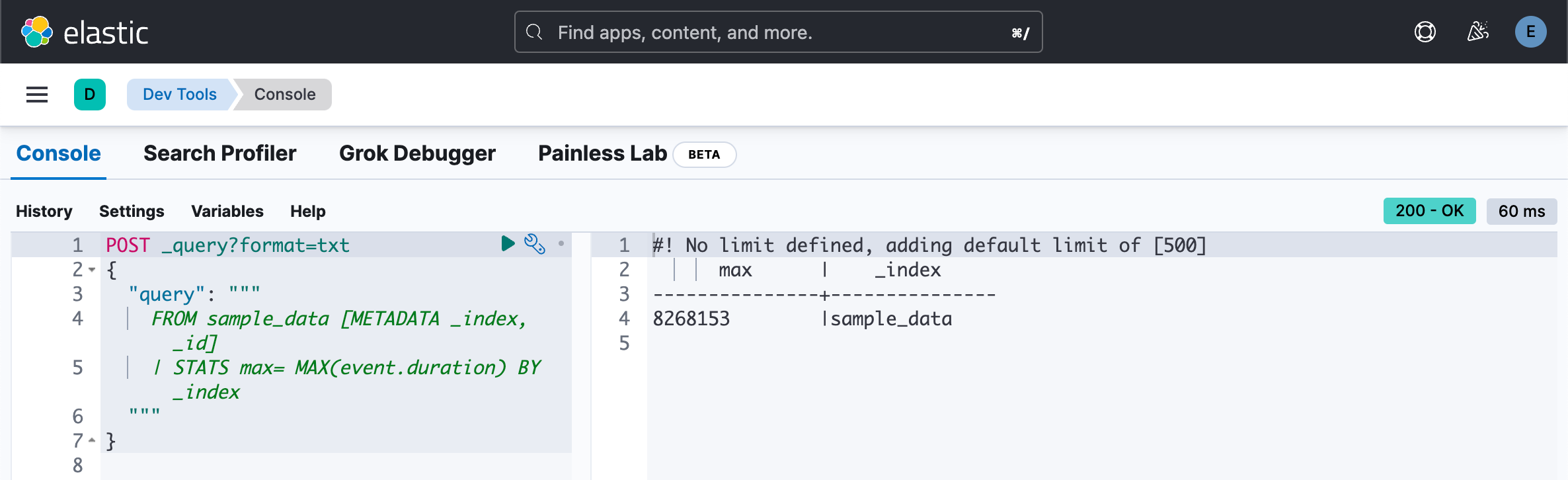
此外,与索引字段类似,一旦执行聚合,后续命令将无法再访问元数据字段,除非用作分组字段:
POST _query?format=txt
{"query": """FROM sample_data [METADATA _index, _id]| STATS max= MAX(event.duration) BY _index"""
}
ES|QL 多值字段
ES|QL 可以很好地读取多值字段。多值字段也就是在一个字段里有多个值。通常是以数组的形式出现。
POST /mv/_bulk?refresh
{"index":{}}
{"a":1,"b":[2,1]}
{"index":{}}
{"a":2,"b":3}多值字段以 txt 数组的形式返回:
POST /_query?format=txt
{"query": "FROM mv | LIMIT 2"
}
多值字段中值的相对顺序未定义。 它们通常会按升序排列,但不要依赖于此。
重复值
某些字段类型(例如关键字)在写入时删除重复值:
DELETE mv
PUT /mv
{"mappings": {"properties": {"b": {"type": "keyword"}}}
}POST /mv/_bulk?refresh
{"index":{}}
{"a":1,"b":["foo","foo","bar"]}
{"index":{}}
{"a":2,"b":["bar","bar"]}POST /_query?format=txt
{"query": "FROM mv | LIMIT 2"
}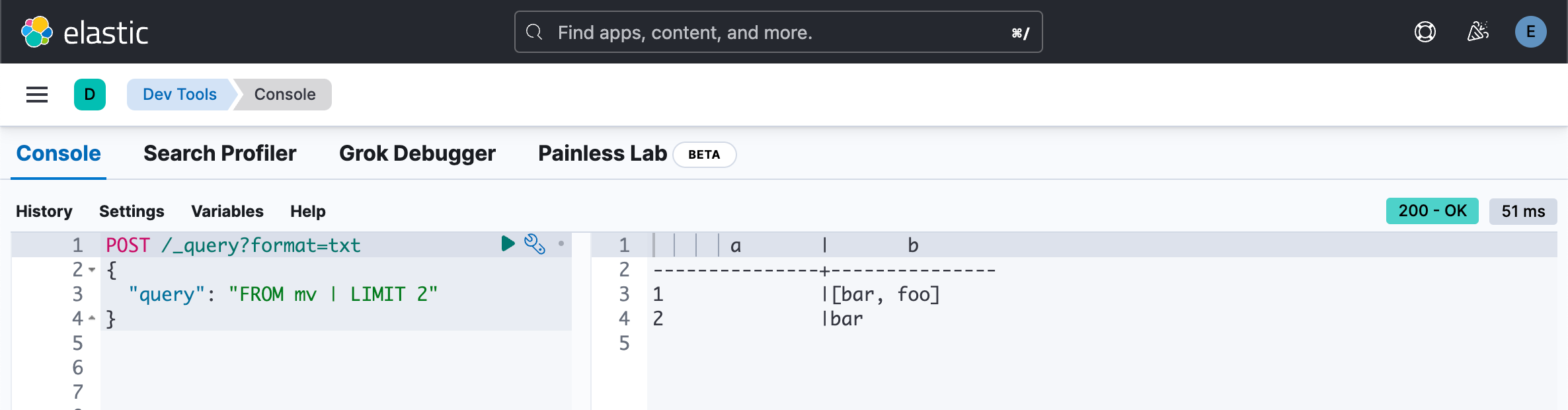
在 ES|QL 查询结果里,我们看到了该删除。
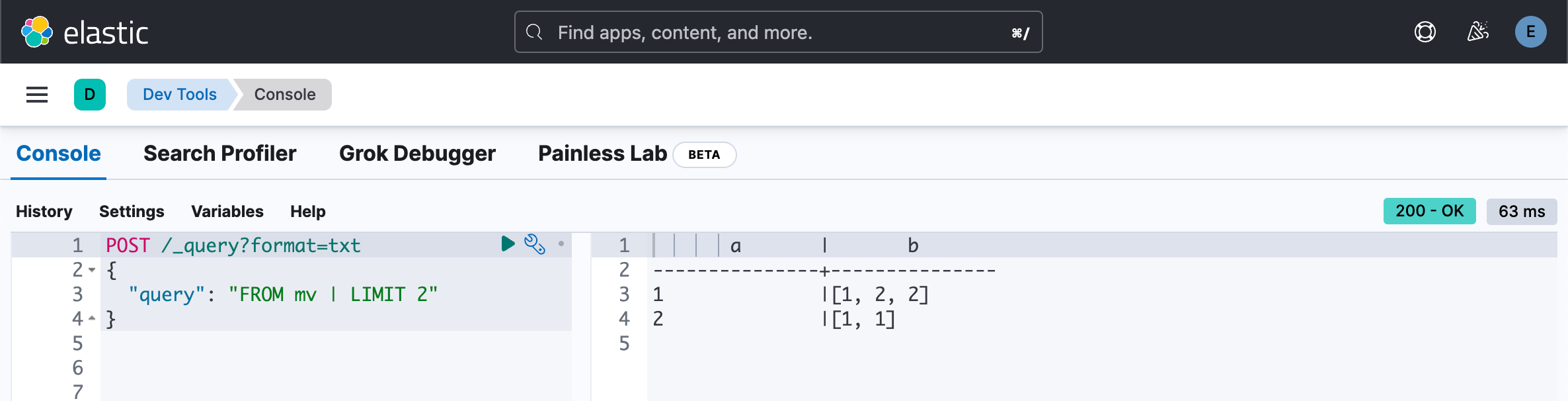
但其他类型(例如 long)不会删除重复项。
DELETE mv
PUT /mv
{"mappings": {"properties": {"b": {"type": "long"}}}
}POST /mv/_bulk?refresh
{"index":{}}
{"a":1,"b":[2,2,1]}
{"index":{}}
{"a":2,"b":[1,1]}POST /_query?format=txt
{"query": "FROM mv | LIMIT 2"
}
这都是在存储层。 如果你存储重复的 “long”,然后将它们转换为字符串,则重复项将保留:
DELETE mv
PUT /mv
{"mappings": {"properties": {"b": {"type": "long"}}}
}POST /mv/_bulk?refresh
{"index":{}}
{"a":1,"b":[2,2,1]}
{"index":{}}
{"a":2,"b":[1,1]}POST /_query?format=txt
{"query": "FROM mv | EVAL b=TO_STRING(b) | LIMIT 2"
}
函数
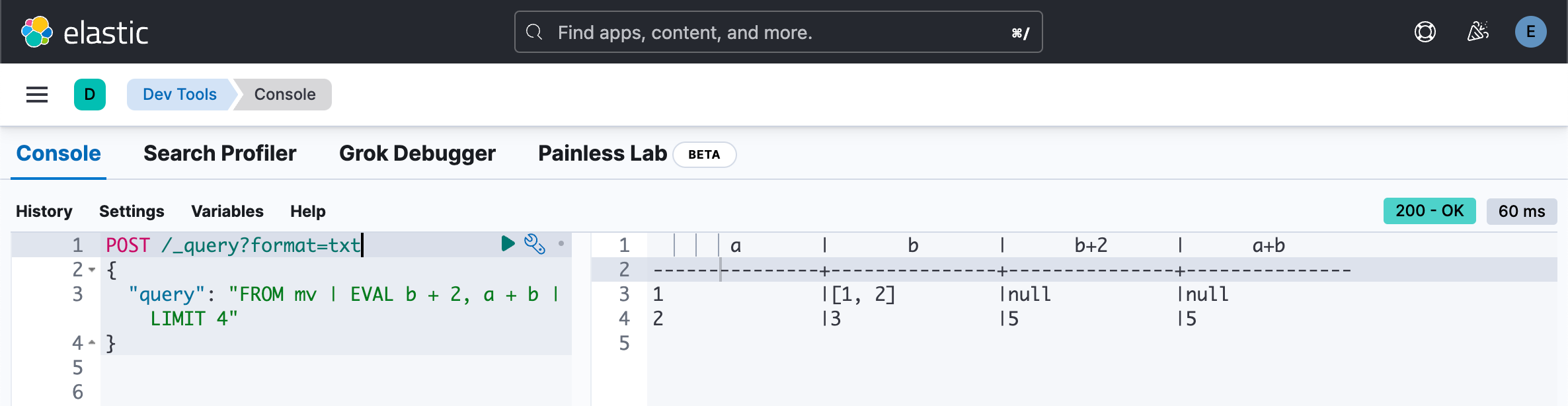
除非另有说明,函数在应用于多值字段时将返回 null。 此行为可能会在更高版本中改变。
DELETE mv
POST /mv/_bulk?refresh
{"index":{}}
{"a":1,"b":[2,1]}
{"index":{}}
{"a":2,"b":3}POST /_query?format=txt
{"query": "FROM mv | EVAL b + 2, a + b | LIMIT 4"
}
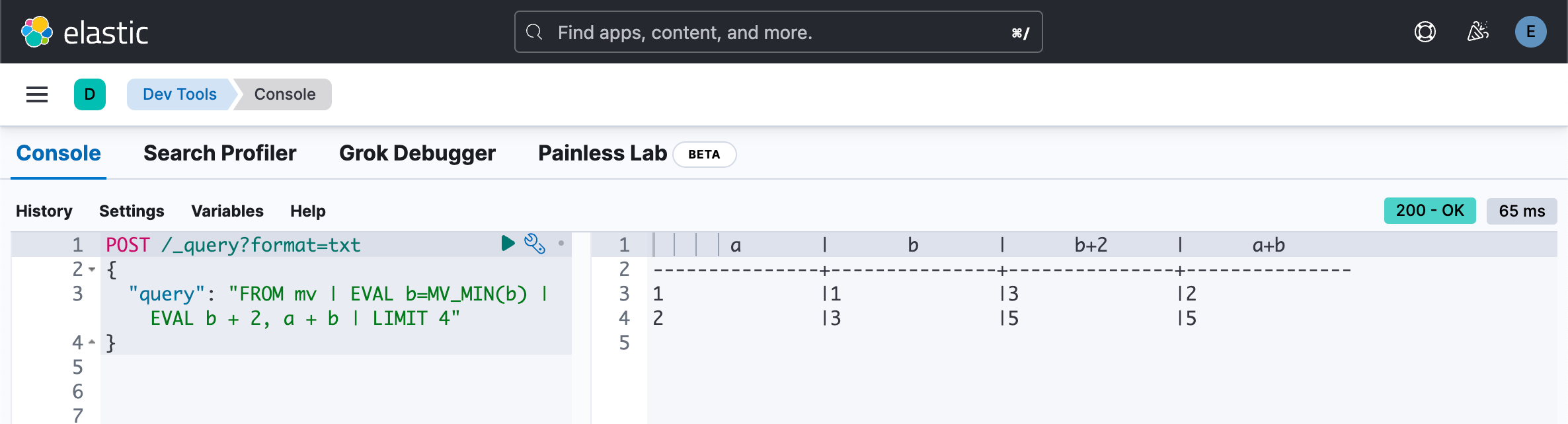
通过使用以下之一将字段转换为单个值来解决此限制:
- MV_AVG
- MV_CONCAT
- MV_COUNT
- MV_MAX
- MV_MEDIAN
- MV_MIN
- MV_SUM
POST /_query?format=txt
{"query": "FROM mv | EVAL b=MV_MIN(b) | EVAL b + 2, a + b | LIMIT 4"
}
这篇关于Elasticsearch:ES|QL 查询中的元数据字段及多值字段的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







