本文主要是介绍YOLOv5改进 | 添加SE注意力机制 + 更换NMS之EIoU-NMS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言:Hello大家好,我是小哥谈。为提高算法模型在不同环境下的目标识别准确率,提出一种基于改进 YOLOv5 深度学习的识别方法(SE-NMS-YOLOv5),该方法融合SE(Squeeze-and-Excitation)注意力机制模块和改进非极大值抑制对数据集进行训练和测试。研究表明,SE-NMS-YOLOv5 目标识别方法有效地解决了不同场景下的检测准确率低的问题,提升了检测和识别的整体效果。🌈
目录
🚀1.基础概念
🚀2.添加位置
🚀3.添加步骤
🚀4.改进方法
💥💥步骤1:common.py文件修改
💥💥步骤2:yolo.py文件修改
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:修改自定义yaml文件
💥💥步骤5:验证是否加入成功
💥💥步骤6:更改NMS
💥💥步骤7:修改默认参数

🚀1.基础概念
SE注意力机制:
SENet是由Momenta和牛津大学的胡杰等人提出的一种新的网络结构,目标是通过显式的建模卷积特征通道之间的相互依赖关系来提高网络的表示能力。在2017年最后一届ImageNet 比赛classification任务上获得第一名。SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块。
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
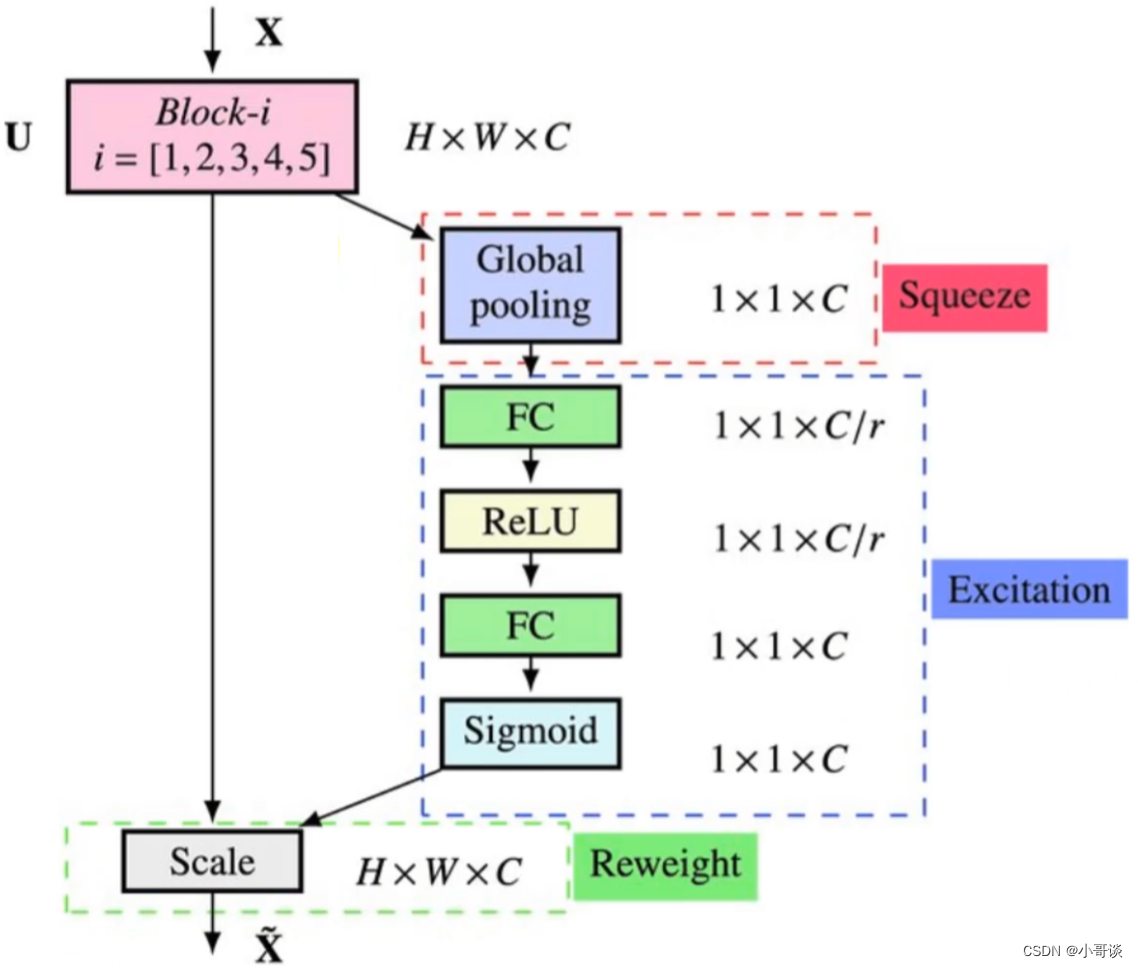
SENet结构图如下图所示:
🍀步骤1:squeeze操作,将各通道的全局空间特征作为该通道的表示,形成一个通道描述符;
🍀步骤2:excitation操作,学习对各通道的依赖程度,并根据依赖程度的不同对特征图进行调整,调整后的特征图就是SE block的输出。

EIoU-NMS:
EIoU-NMS是一种新的非极大值抑制算法,它是YOLOv5中提出的一种改进算法。EIoU-NMS是在DIoU-NMS的基础上进行改进的。EIoU-NMS的主要思想是将检测框之间的距离嵌入到嵌入空间中,然后计算嵌入空间中的距离来代替传统的IoU计算。这种方法可以更好地处理检测框之间的重叠情况,从而提高目标检测的准确性。
🚀2.添加位置
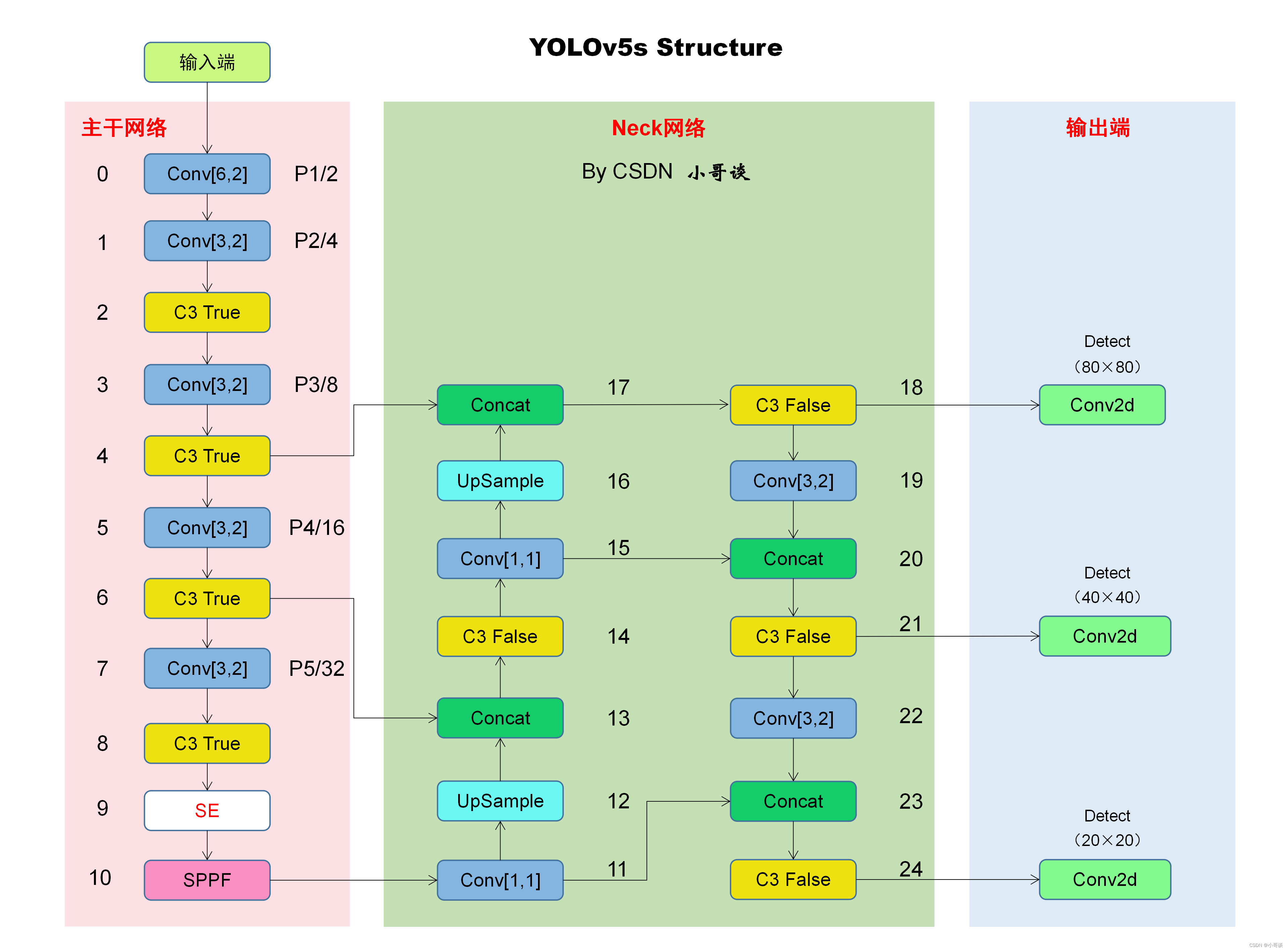
本文的改进是基于YOLOv5-6.0版本,关于其网络结构具体如下图所示:

为了使网络能够更好地拟合通道之间的相关性,增加更重要的通道特征的权重,引入了SE模块,注意力机制是一种神经网络资源分配方案,用于将计算资源分配给更重要的任务,
本文的改进是将SE注意力机制添加在主干网络中,具体添加位置如下图所示:

关于NMS的改进,直接体现在代码中,所以,本节课改进后的网络结构图具体如下图所示:
🚀3.添加步骤
针对本文的改进,具体步骤如下所示:👇
步骤1:common.py文件修改
步骤2:yolo.py文件修改
步骤3:创建自定义yaml文件
步骤4:修改自定义yaml文件
步骤5:验证是否加入成功
步骤6:更改NMS
步骤7:修改默认参数
🚀4.改进方法
💥💥步骤1:common.py文件修改
在common.py中添加SE注意力机制模块,所要添加模块的代码如下所示,将其复制粘贴到common.py文件末尾的位置。
SE注意力机制模块代码:
# SE
class SE(nn.Module):def __init__(self, c1, c2, ratio=16):super(SE, self).__init__()#c*1*1self.avgpool = nn.AdaptiveAvgPool2d(1)self.l1 = nn.Linear(c1, c1 // ratio, bias=False)self.relu = nn.ReLU(inplace=True)self.l2 = nn.Linear(c1 // ratio, c1, bias=False)self.sig = nn.Sigmoid()def forward(self, x):b, c, _, _ = x.size()y = self.avgpool(x).view(b, c)y = self.l1(y)y = self.relu(y)y = self.l2(y)y = self.sig(y)y = y.view(b, c, 1, 1)return x * y.expand_as(x)💥💥步骤2:yolo.py文件修改
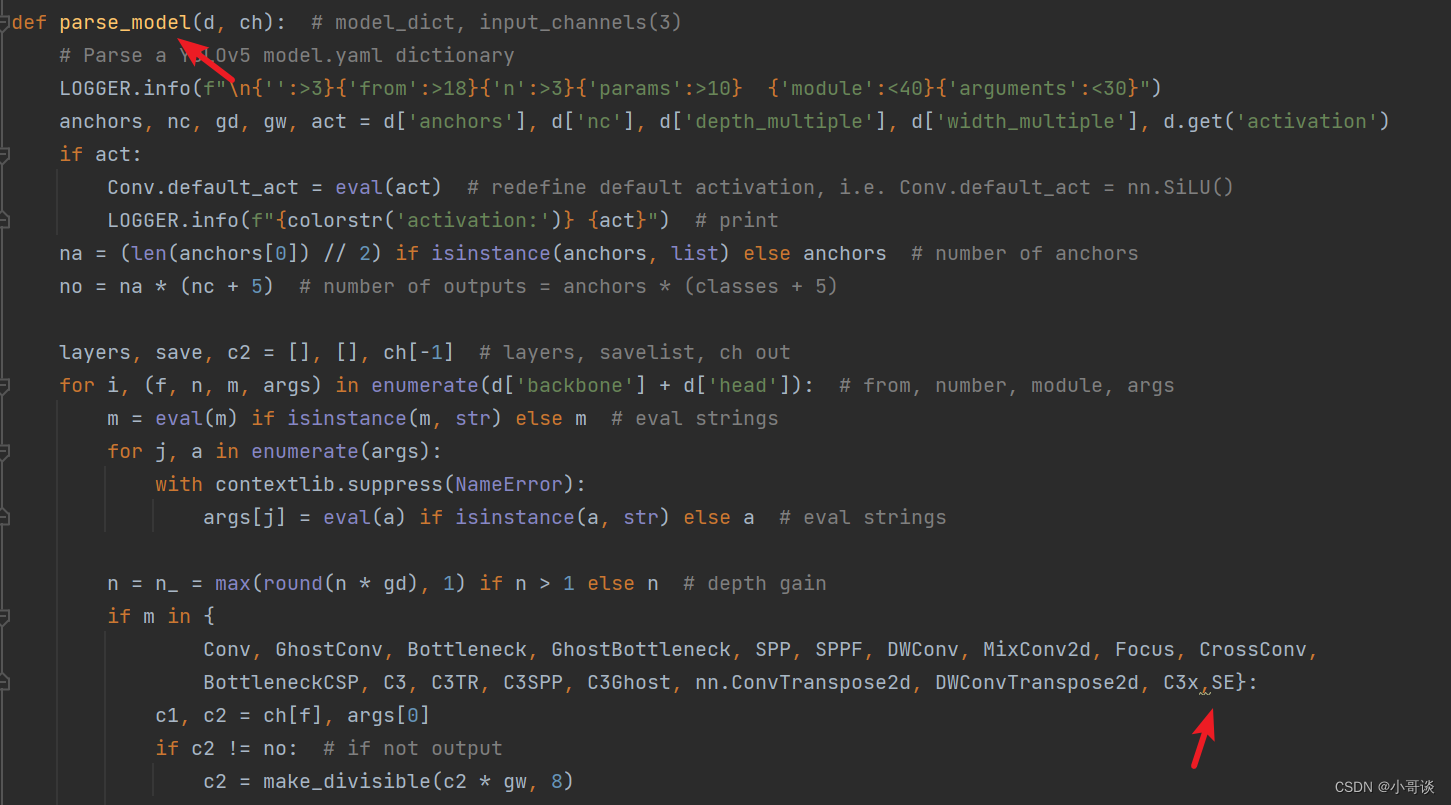
首先在yolo.py文件中找到parse_model函数这一行,加入SE。具体如下图所示:
💥💥步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_SE_ENMS.yaml。具体如下图所示:

💥💥步骤4:修改自定义yaml文件
本步骤是修改yolov5s_SE_ENMS.yaml,根据改进后的网络结构图进行修改。
由下面这张图可知,当添加SE注意力机制之后,后面的层数会发生相应的变化,需要修改相关参数。
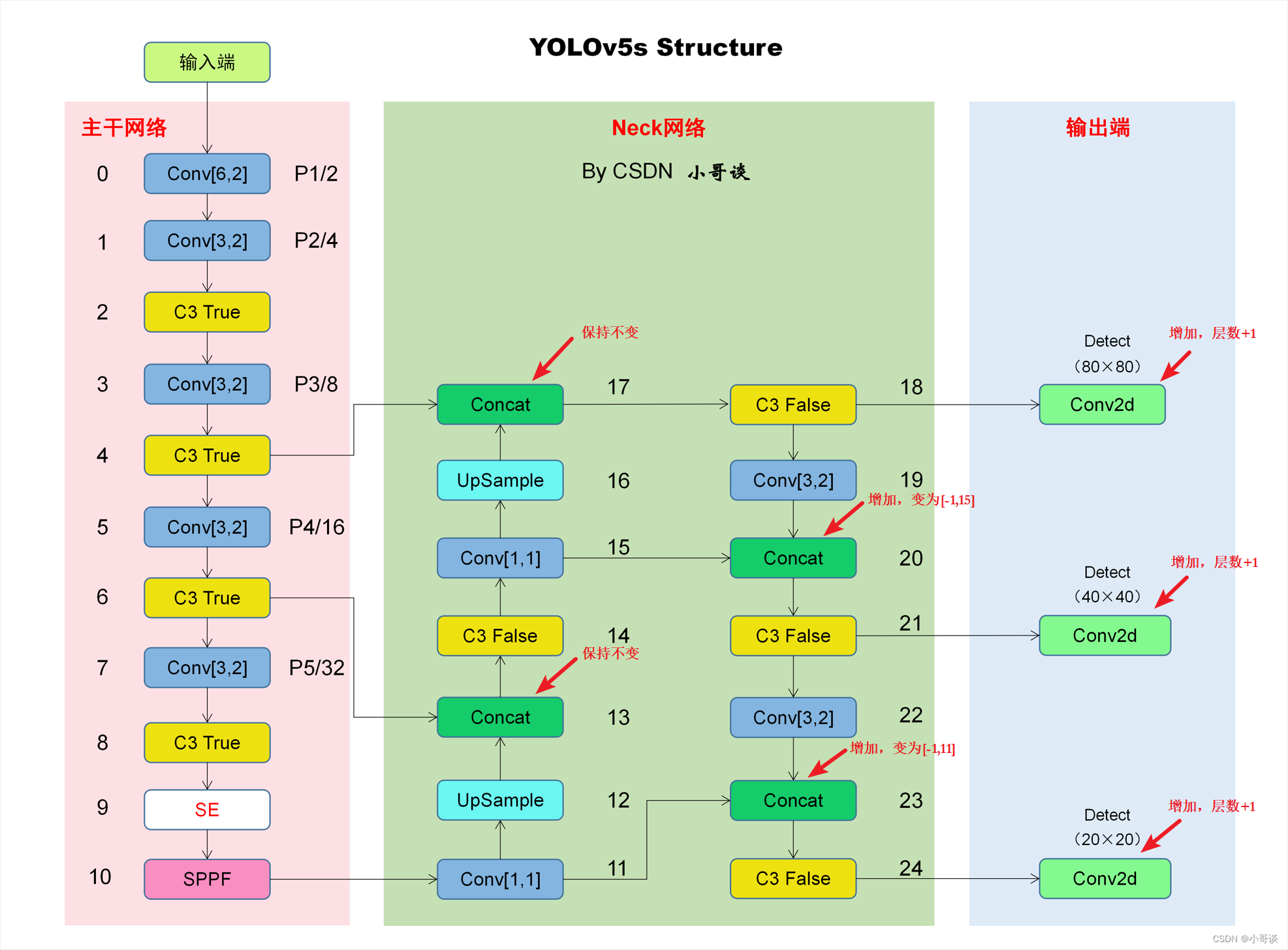
备注:层数从0开始计算,比如第0层、第1层、第2层......🍉 🍓 🍑 🍈 🍌 🍐
综上所述,修改后的完整yaml文件如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SE, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 15], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
💥💥步骤5:验证是否加入成功
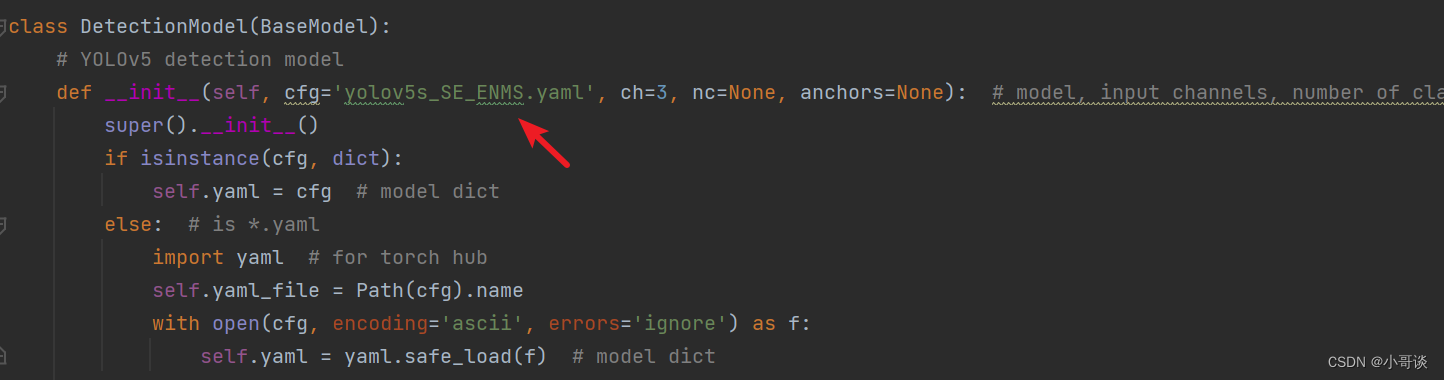
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_SE_ENMS.yaml。
修改1,位置位于yolo.py文件165行左右,具体如图所示:
修改2,位置位于yolo.py文件363行左右,具体如下图所示:
配置完毕之后,点击“运行”,结果如下图所示:

由运行结果可知,与我们前面更改后的网络结构图相一致,证明添加成功了!✅
💥💥步骤6:更改NMS
本文需要更改NMS为EIoU-NMS。
将下面非极大值抑制NMS核心代码复制粘贴到 utils / general.py 的末尾位置。当复制粘贴后,会有报错提示,具体如下图所示:
# NMS实现代码
def NMS(boxes, scores, iou_thres, GIoU=False, DIoU=True, CIoU=False, EIoU=False, SIoU=False):B = torch.argsort(scores, dim=-1, descending=True)keep = []while B.numel() > 0:index = B[0]keep.append(index)if B.numel() == 1: breakiou = bbox_iou(boxes[index, :], boxes[B[1:], :], GIoU=GIoU, DIoU=DIoU, CIoU=CIoU, EIoU=EIoU, SIoU=SIoU)inds = torch.nonzero(iou <= iou_thres).reshape(-1)B = B[inds + 1]return torch.tensor(keep)def soft_nms(bboxes, scores, iou_thresh=0.5, sigma=0.5, score_threshold=0.25):order = scores.argsort(descending=True).to(bboxes.device)keep = []while order.numel() > 1:if order.numel() == 1:keep.append(order[0])breakelse:i = order[0]keep.append(i)iou = bbox_iou(bboxes[i], bboxes[order[1:]]).squeeze()idx = (iou > iou_thresh).nonzero().squeeze()if idx.numel() > 0:iou = iou[idx]new_scores = torch.exp(-torch.pow(iou, 2) / sigma)scores[order[idx + 1]] *= new_scoresnew_order = (scores[order[1:]] > score_threshold).nonzero().squeeze()if new_order.numel() == 0:breakelse:max_score_index = torch.argmax(scores[order[new_order + 1]])if max_score_index != 0:new_order[[0, max_score_index],] = new_order[[max_score_index, 0],]order = order[new_order + 1]return torch.LongTensor(keep)
然后,解决报错提示,需要导入下列代码:
from utils.metrics import box_iou, fitness, bbox_iou最后,在utils / general.py中找到non_max_suppression函数(大约885行左右),将non_max_suppression函数中的代码:

替换为:
i = NMS(boxes, scores, iou_thres, class_nms='EIoU')💥💥步骤7:修改默认参数
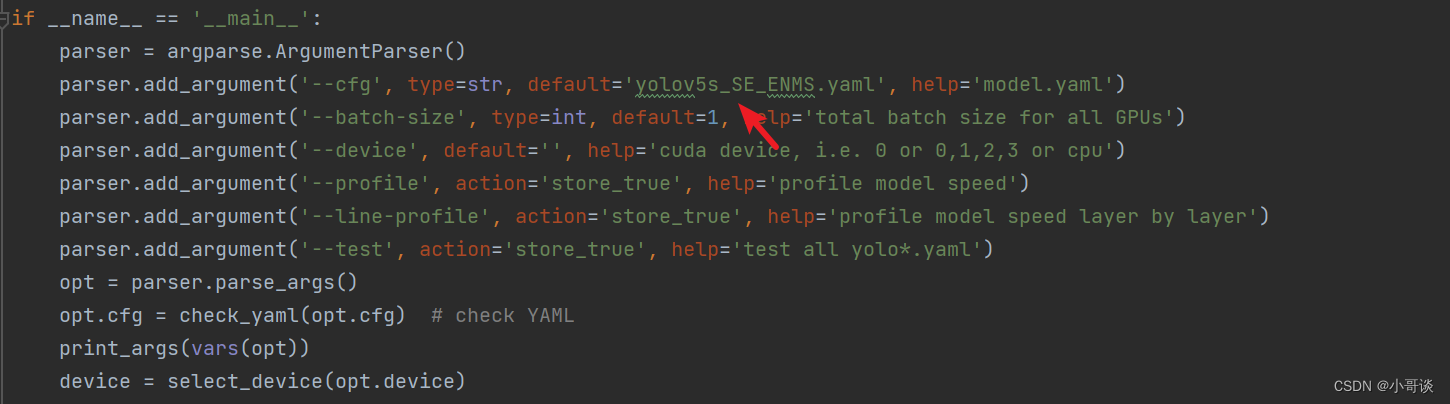
在train.py文件中找到parse_opt函数,然后将第二行 '--cfg' 的default改为 'models/yolov5s_SE_ENMS.yaml',然后就可以开始进行训练了。🎈🎈🎈

结束语:关于更多YOLOv5学习知识,可参考专栏:《YOLOv5:从入门到实战》🍉 🍓 🍑 🍈 🍌 🍐

这篇关于YOLOv5改进 | 添加SE注意力机制 + 更换NMS之EIoU-NMS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






