本文主要是介绍论文阅读《Dual-Awareness Attention for Few-Shot Object Detection》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Background & Motivation
小样本分类模型分为两类:optimization-based 的元学习方法和 metric-based 的度量学习方法。而小样本检测模型大多使用迁移学习和度量学习的方法来实现跨域学习,大多都采用平均特征来作为类的表征与模型输出的 Query 表征进行 concatenation 或 element-wise product 等来计算相似度。
Motivation 是现有的小样本检测模型在 base 类数据上精度普遍降低,此前直接将小样本分类模型的思想用在检测任务上的做法存在不恰当的地方并且 Support 的质量直接影响了模型的精度。因此本文聚焦到了两个问题:Support 的质量和怎么更好的建立 Support 和 Query 之间的联系。为了解决这些问题提出了 Dual-Awareness Attention(DAnA),包含两个模块:Background Attenuation(BA)和 Cross-image Spatial Attention(CISA)。
而这两个模块的 Motivation 分别是物理学中的 interference 现象和我们人类判断两个物体是否是同一类别的方法,即我们会找到最有代表性的特征来判断它。
文章中解释了这些不恰当的原因:
(a)中采用全局平均池化的方法来降低运算复杂度,但是不可避免的损失了 Support 中携带的空间信息。
比如《Few-shot object detection via feature reweighting》中(红色箭头):
《Meta R-CNN: Towards general solver for instance-level low-shot learning》中:
(b)中用 convolution-based 的注意力操作将 Query 中带上 Support 的信息,但是没有考虑到局部信息的错位。或者不采用全局池化,也将导致局部信息的错位。
(c)采用类平均的思想计算出每一类的表征,但是每类表征的计算方法很有可能导致表征的偏差。



Dual-Awareness Attention(DAnA)
- Background Attenuation(BA)

BA 针对 Support image 而言,图中 Y 代表 Support image 的特征图(这里假设只有一张 Support image),只有这一个输入,We(C*1)是一个线性变换可学习的向量,计算公式如下:

其中 yi 是 1*C 的矩阵,代表着特征图每一个通道上同一像素的位置,经过 Softmax 得到特征图中每一位置的激活值。这些激活值可以看作 yi 的权重系数,再与 yi 相乘得到调整过各个通道每一像素权重的特征图 G(1*C,即图中画红色波浪线的地方)。每个特征图的特征向量 G(1*1*C)可以作为一个 specific pattern 的“信号”,这个 pattern 代表着局部信息。
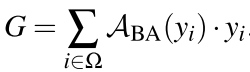
但是直接使用这个 G 反而影响了模型的精度,文章中认为原因是:
By visualization, it can be observed that only few narrow regions of support image contribute to the aggregated feature G. Such a naive attention process leads to a considerable loss of support information and would deteriorate the ability of models.
受物理学 interference 现象的启发,两个信号的叠加要么是振幅更大要么趋于平稳。将最开始的特征图 Y 看作一个信号,将特征图 G 施加到这个信号,其中 α 是一个常数,取0.5:
![]()
因此对图像中的各个 pattern,属于一个类别的 pattern 将会获得“信号”增强,而不同的类别则将被削弱。

BA 模块可以看作一种注意力机制,保留前景的特征而抑制背景的特征。模块足够轻便,只有 We 是需要学习的参数。
- Cross-image Spatial Attention(CISA)

CISA 中由两部分输入,第一部分是 BA 模块输出的不同 Support image 的特征图 Z1、Z2,第二部分是 Query image 的特征图 X。CISA 的核心思想是将 Support 中的特征转换成带有具体语义信息的 query-position-aware(QPA)特征,那些与 QPA 有着高响应的 Query 特征图的区域应被识别为目标。

(f) 中 Query 中的类别与 Support 中不相同时,CISA 更倾向于高亮最能描述一个对象最具有代表性的特征。
有 Transformer 类似的 QKV 参数,分别表示为![]() 和
和![]() ,Wq 和 Wk 是两个可学习的参数矩阵(C`*C,C` 是 C 的四分之一)。Query 和 Support 之间的相似性得分为:
,Wq 和 Wk 是两个可学习的参数矩阵(C`*C,C` 是 C 的四分之一)。Query 和 Support 之间的相似性得分为:
![]()
其中 μQ 和 μK 与 BA 模块中 yi 的含义相同,σ 是 softmax 函数。考虑最终的 attention map 应该不止与 Query 和 Support 有关,还应该与 Support 自身有关。
![]()
Wr 是 1*C 的矩阵,β 是常数,取0.1。输出的维度是 HQWQ*HSWS,可以看作 Query image 特征图(HQ*WQ)上不同空间位置的基于 Support image 的 attention map(HS*WS)。而 QPA 特征的计算如下:

pi 代表了 Query 特征图上对应空间位置的 QPA 特征(应对问题 a),如果 Support Set 不止一张图像的话,QPA 特征可变为每张图像 QPA 特征的平均值:
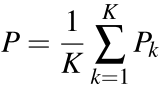
without the concern of entangled representations, because those QPA vectors pki of the same entry will represent relevant contextual information by taking the same query position i into consideration.(应对问题 c)
同样 CISA 打破了物理的限制不用考虑对齐的问题(应对问题 b),因为 QPA 不是由一个简单的 Support image 的特征图得来,而是经过类似于 Transformer 的注意力计算:

DAnA 将最后的输出 P 与原特征图 X 进行结合之后,可以直接输入到传统检测网络 Faster Rcnn 的 RPN 中。值得注意的是 DAnA 的输出与 Query image 的特征图大小是一样的,因此这一个即插即用的模块:

也可以加入到一阶段的检测网络中:

Experiments
TABLE Ⅰ中模型的训练都采用了两个 Trick:
- two-way contrastive 训练策略。
- 将多分类损失换成了二分类损失。
Support image 用 zero-padding 成320*320。COCO 中与 PASCAL VOC 类别相同的20类作为 Novel 类,其余60类作为 Base 类。采用元学习的训练方法,每个 episode 中包含一个或多个 Support set,一张 Query image 以及他们的标注,每个 episode 选择目标类别中的一个类别作为训练目标。
Note that all the annotations belonging to the novel categories have been removed in order the prevent models from peeking at the novel task.
N-way K-shot 的定义是训练时每一个类别都应包含 K 个目标,不论多少张图片。

TABLE Ⅱ 和 TABLE Ⅲ 的精度对比中的 1-shot、5-shot 是说 Support image 的数量。
Furthermore, we are the first to conduct zero-shot evaluation for FSOD, where models are trained from the source domain and directly tested on the target domain without fine-tuning.



从 PASCAL VOC 跨域到 COCO:

对模块进行了消融实验:

Mask 是用 CNN 取代 BA 模块来实现注意力机制并与原特征图叠加,同时也证明了 RPN 对本文提出的 DAnA 的重要性。

Conclusion
DAnA 是一个计算 Query 和 Support 之间语义信息的模块,提出了应对 Motivation 中几个问题的方法。
这篇关于论文阅读《Dual-Awareness Attention for Few-Shot Object Detection》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








