本文主要是介绍mmaction2-时空动作检测slowfast笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
slowfast 介绍
目前使用mmaction2开发时空动作识别的算法,检测识别出项目视频中人是否有“打架”、“扔垃圾”、“抽烟”,“打电话”等行为动作。故写了对视频识别网络slowfast的一些理解和笔记。
论文地址:链接: https://arxiv.org/pdf/1812.03982.pdf
一、SlowFast Networks for Video Recognition是怎么来的?
在图片处理中人们习惯将xy两个维度对称的对待(symmetrically),当然由于各向异性和移位不变性(shift-invariant)这是可以的,但是,如果对于视频(x,y,t)呢?因为光流孔径问题,我们不能将时间维度与空间维度对称的处理(而这正是时空卷积的视频方法所默认的《learning spatiotemporal features with 3D convolutional networks》),在我们一般所见的世界中的某一个特定时刻,世界一般是静止的,空间的语义信息一般是不变的,或者是及其缓慢的(slow)但是在对于一些动作,比如“拍手”,“跑步”,他们渴望的是更加迅速(fast)的帧数(更高的时间分辨率)去有效的建模快速运动的状态改变(ues fast refreshing frames(high temproal resolution) to effectively model the potentialy fast chaning motion).
基于这个想法,论文作者设计出了一种基于双通道的SlowFast model来做动作检测,用来提取视频信息。
二、是怎么实现的?
在图片中,I(x,y)I(x,y)I(x,y) 有各向同性 (isotropic), 那么视频信号中是否有呢?
空域和时域显然是不具备向同性的。所以想法就是将空域和时域分开来处理,分别通过低采样和高采样来实现。
基于这种想法就构建了两条通路, 一条用来检测图片语义,使用低帧率。另一条用来检测移动,动作(motion)通过高帧率。
这两条路径我们根据处理时间速度(temporal speed)的差异,将它们命名为slow和fast路径。他们通过侧向连接融合。
SlowFast与我们传统的视频处理模型——双流结构(two-stream)最大的区别在于,双流结构没有探索不同的时间速度(different temporal speeds),并且对两个流而言,它们的采用完全相同的骨干网络(Bone net), 然而Fast路径更加快,更加轻量,因为没有计算光流等等(potical flow), 并且还是端到端(end-to-end from raw data)
*低采样:提取空间语义(spacial sematics)**高采样:提取时域上的运动*
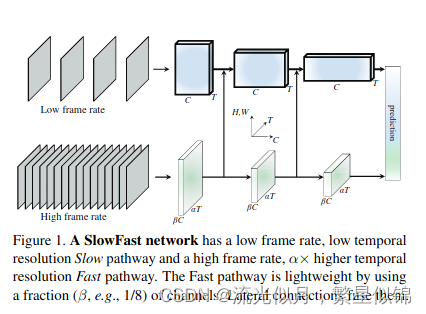
Slow Pathway:
Slow pathway 可以使任何一种可以在一段剪辑过得视频上工作的时空卷积模型,重点在于 T,γ。
γ是采样步长,即将原始视频按照该步长取样,一般取16, 即16帧取一张关键帧,
T是采样次数,即一共采样多少次。
所以慢通道的一次输入总帧数为 T × γ 。
Fast Pathway:
与之平行的Fast pathway拥有以下属性:
- 高帧率(High frams rate)
- 高时间分辨率特征(High temporal resolution)
- 较低的通道容量(low channel capacity)
第一点:
α 是 帧 采 样 倍 数 , β 是 通 道 倍 数
对于快通道来说,他的采样步长是γ/α ,采样次数是 α T
第二点:
除了输入是时间高分辨的输入,对于时间特征我们也是使用的高分辨。
从始至终在fast中,我们使用的都是不降低时间采样率的层(而不是时间池化或者时域跨度卷积)
第三点:
fast的卷积核个数是慢通道的 1/ β 倍,较小的卷积核降低了其在空间语义上的表达能力,但是却提高了它在时域上的表达能力,这正是Fast通道所要做的,同时它在论文中也提到了根据实验的进行,使用各种方式减少fast通道中空间语义的表达也能带来准确率的提升:
侧向链接
侧向链接主要是用来融合不同通路的时间与空间的语义信息的,他经常被用于上面所提到的基于双流和光流的结构。
它被应用于两条通路的每一层上,尤其是Resnets的pool1, res2, res3, and res4.这些链接紧随其后。
链接是单向的,从fast流融合进Slow流,测试过双流结构,但是效果差不多
最后,来自两条通路的信息池化成为特征向量之后通过同通过一个全连接分类层
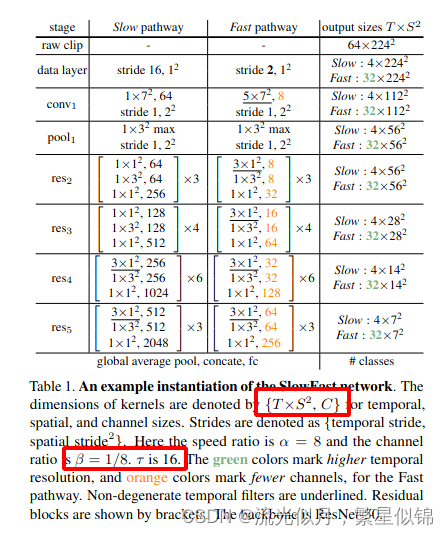
上面是一个实例对象,T代表采样的次数,S代表空间的分辨率
stride 16 1^2 代表{时间步长,空间步长}
对于卷积核来说 {T×S^2, C} ,代表时空卷积核大小,以及数量
对于Slow通道来说,在较早的层中使用时间卷积会降低准确性。我们认为这是因为当对象快速移动且时间步长很大时,除非空间感受野足够大),否则非时间感受野内几乎没有相关性。
对于fast通道来说,每个块都有非退化的时间卷积。
对于侧向链接:
特征图的形状可以写作:
Slow pathway as{T,S2,C},
Fast pathway is{αT,S2,βC}.
他们采用了一下三种方案:
1、将所有的a帧打包到一帧中
2、从每个a帧中随机采样一帧
3、使用 2βC 输出通道和 stride=α 执行5×1^2 核的 3D 卷积
最后发现,是第三种方法最好。
三、实现了什么目标?
在动作识别以及检测都有很显著提升测试集:Kinetics, Charades, AVA
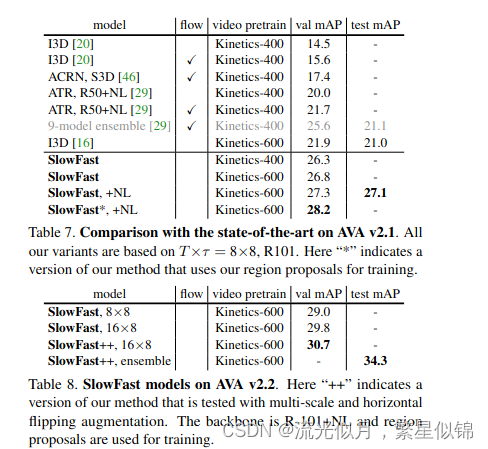
在AVA2.1和2.2上都进行了实验验证
1.结果在最佳的3d卷积上sf有3.0%的提升。
2.同时确定了三个有可能的改进方向或者说问题:
削弱Fast 路径的空间输入,半空间输入,更大的 β (FLOPS 几乎一致),灰度处理。
“时间差帧”,通过用前一帧减去当前帧来计算。
输入光流。
3.Fast通道的低通道容量
表现最好的 β 值是 1/6 和 1/8(默认值)。然而,令人惊讶的是,我们的 SlowFast 模型中从 β=1/32 到 1/4 的所有值都可以改进仅慢速模型。特别是,当 β=1/32 时,Fast 通路仅增加了 1.3 GFLOPs(相对 ∼5%),但导致了 1.6% 的改进
有趣的是,仅仅只有Fast路径的话只有51.7左右的acc,但是他却可以为Slow路径带来3.0%的提升,说明由Fast路径建模的底层表征在很大程度上是互补的。
在AVA的训练中,使用了kinetic的权重作为初始化,采用的学习率调整策略是warm-up(是一种学习率调整策略,简单来说就是在一开始使用较小的学习率,然后慢慢变大),但验证集损失变化趋于饱和的时候就10倍的减少学习率。

将SO基线与其 SlowFast 对应物进行了比较,每个类别的 AP 显示在图 3 中。SF从 19.0 到 24.2 大幅提高了 5.2mAP(相对 28%)。。在类别方面(图 3),我们的 SlowFast 模型在 60 个类别中的 57 个类别中有所改进,与它的仅慢速对应物。 “拍手”(+27.7AP)、“游泳”(+27.4 AP)、“跑步/慢跑”(+18.8 AP)、“跳舞”(+15.9 AP)和“吃”( +12.5 接入点)。我们还观察到“跳跃/跳跃”、“挥手”、“放下”、“投掷”、“命中”或“切入”的较大相对增加。这些是建模动力学至关重要的类别。 SlowFast 模型仅在“接听电话”(-0.1 AP)、“谎言/睡眠”(-0.2 AP)、“射击”(-0.4 AP) 3 个类别中较差,并且它们的减少相对于其他人的增加较小。
这篇关于mmaction2-时空动作检测slowfast笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








