本文主要是介绍SpringCloud Alibaba实战第六课 分布式事务Seata和异步通信RocketMQ,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
16 分布式事务:Alibaba Seata 如何实现分布式事务
上一讲咱们了解了 APM 系统与 SkyWalking 的配置使用方法。本讲咱们要解决分布式事务这一技术难题,这一讲咱们将介绍三方面内容:
-
讲解分布式事务的解决方案;
-
介绍 Alibaba Seata 分布式事务中间件;
-
分析 Seata 的 AT 模式实现原理。
分布式事务的解决方案
下面咱们先聊一下为什么会产生分布式事务。咱们举个例子,某线上商城会员在购买商品的同时产生相应的消费积分,消费积分在下一次购物时可以抵用现金。这个业务的逻辑如果放在以前的单点应用是很简单的,如下所示。
开启数据库事务
创建订单
会员积分增加
商品库存减少
提交数据库事务
在这个过程中,因为程序操作的是单点数据库,所以在一个数据库事务中便可完成所有操作,利用数据库事务自带的原子性保证了所有数据要么全部处理成功,要么全部回滚撤销。但是放在以微服务为代表的分布式架构下问题就没那么简单了,我们来看一下示意图。
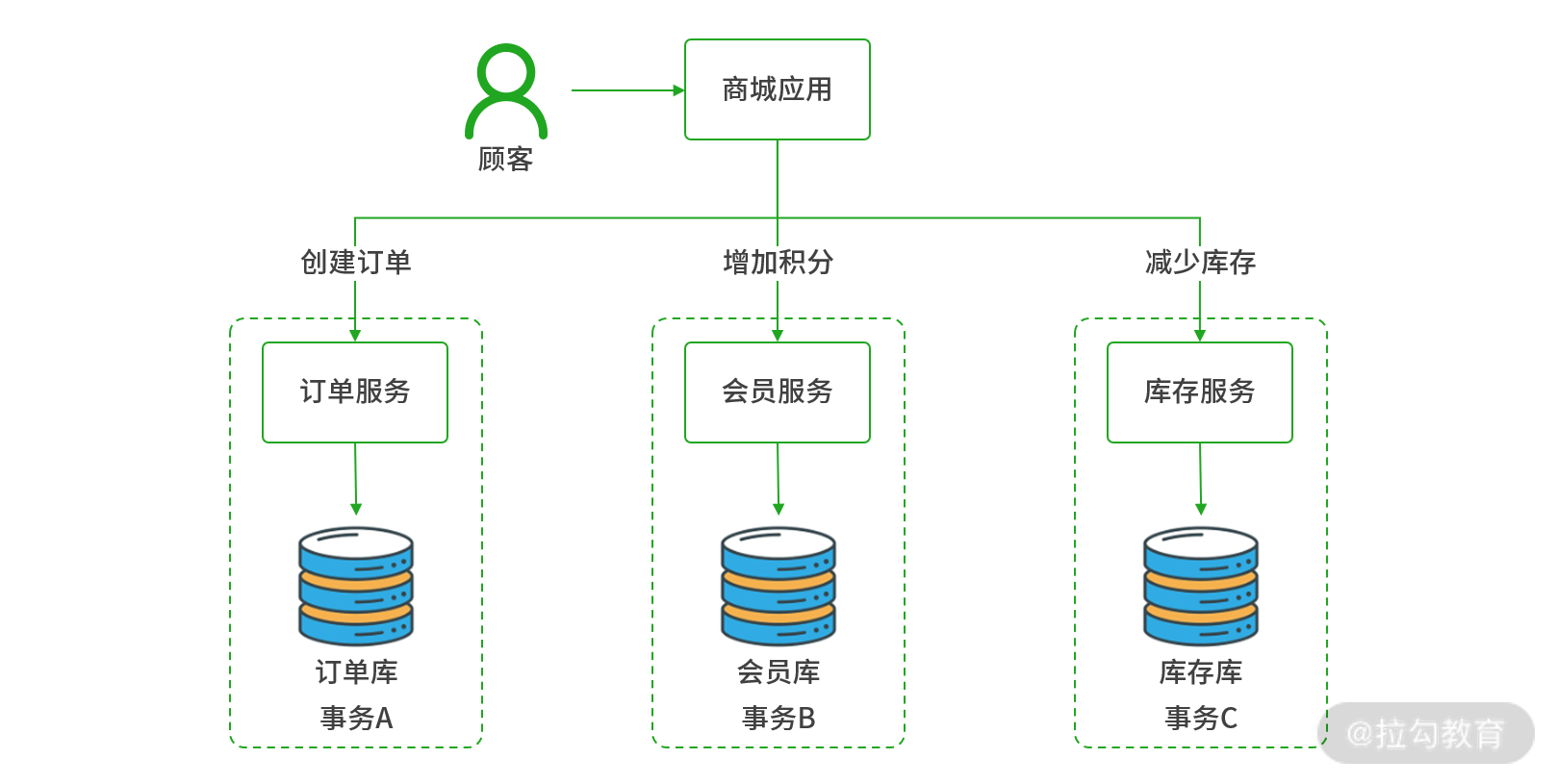
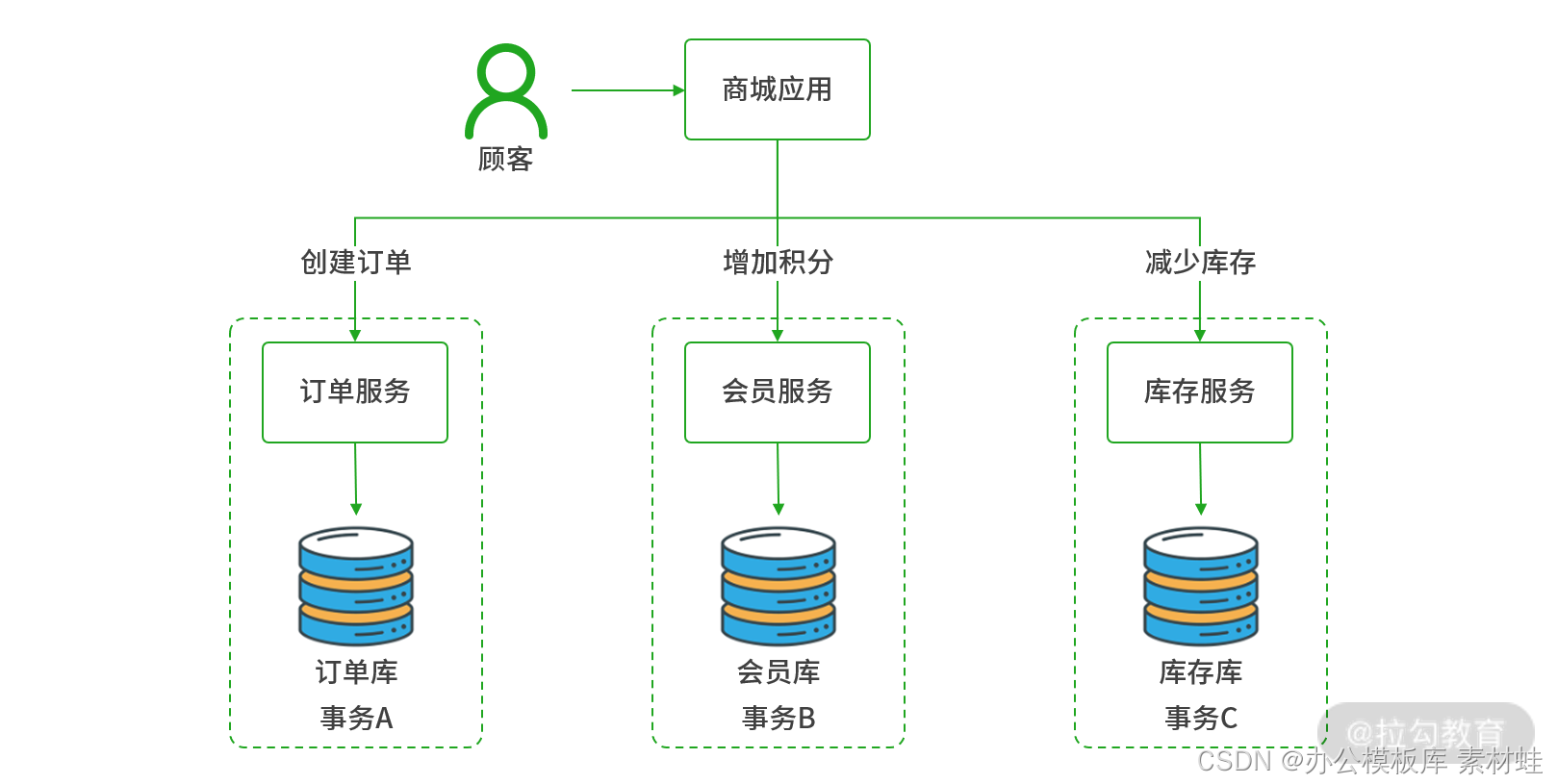
分布式架构下调用关系图
可以看到,商城应用作为业务的发起者分别向订单、会员、库存服务发起了调用,而这些服务又拥有自己独立的数据存储,因为在物理上各个数据库服务器都是独立的,每一个步骤的操作都会创建独立的事务,这就意味着在分布式处理时无法通过单点数据库利用一个事务保证数据的完整性,我们必须引入某种额外的机制来协调多个事务要么全部提交、要么全部回滚,以此保证数据的完整性,这便是“分布式事务”的由来。
在分布式架构中有两种经典的分布式事务解决方案:二阶段提交(2PC)与三阶段提交(3PC)。
二阶段提交
首先咱们分析下二阶段提交的处理过程,下面是二阶段提交中的第一个阶段:事务预处理阶段。
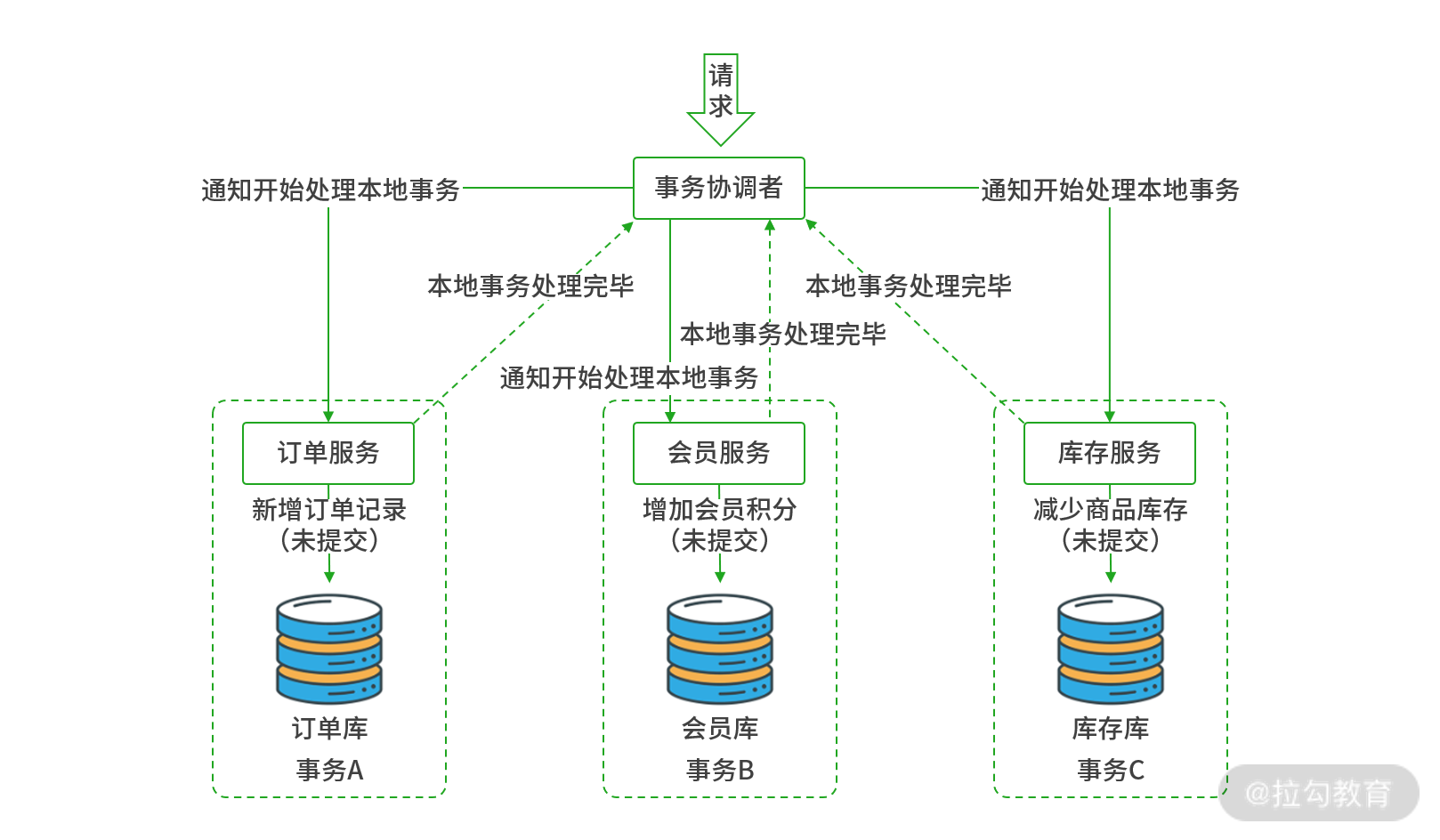
2PC 阶段一:事务预处理阶段
可以看到,相比单点事务,分布式事务中增加了一个新的角色:事务协调者(Coordinator),它的职责就是协调各个分支事务的开启与提交、回滚的处理。以上图为例,当商城应用订单创建后,首先事务协调者会向各服务下达“处理本地事务”的通知,所谓本地事务就是每个服务应该做的事情,如订单服务中负责创建新的订单记录;会员服务负责增加会员的积分;库存服务负责减少库存数量。在这个阶段,被操作的所有数据都处于未提交(uncommit)的状态,会被排它锁锁定。当本地事务都处理完成后,会通知事务协调者“本地事务处理完毕”。当事务协调者陆续收到订单、会员、库存服务的处理完毕通知后,便进入“阶段二:提交阶段”。
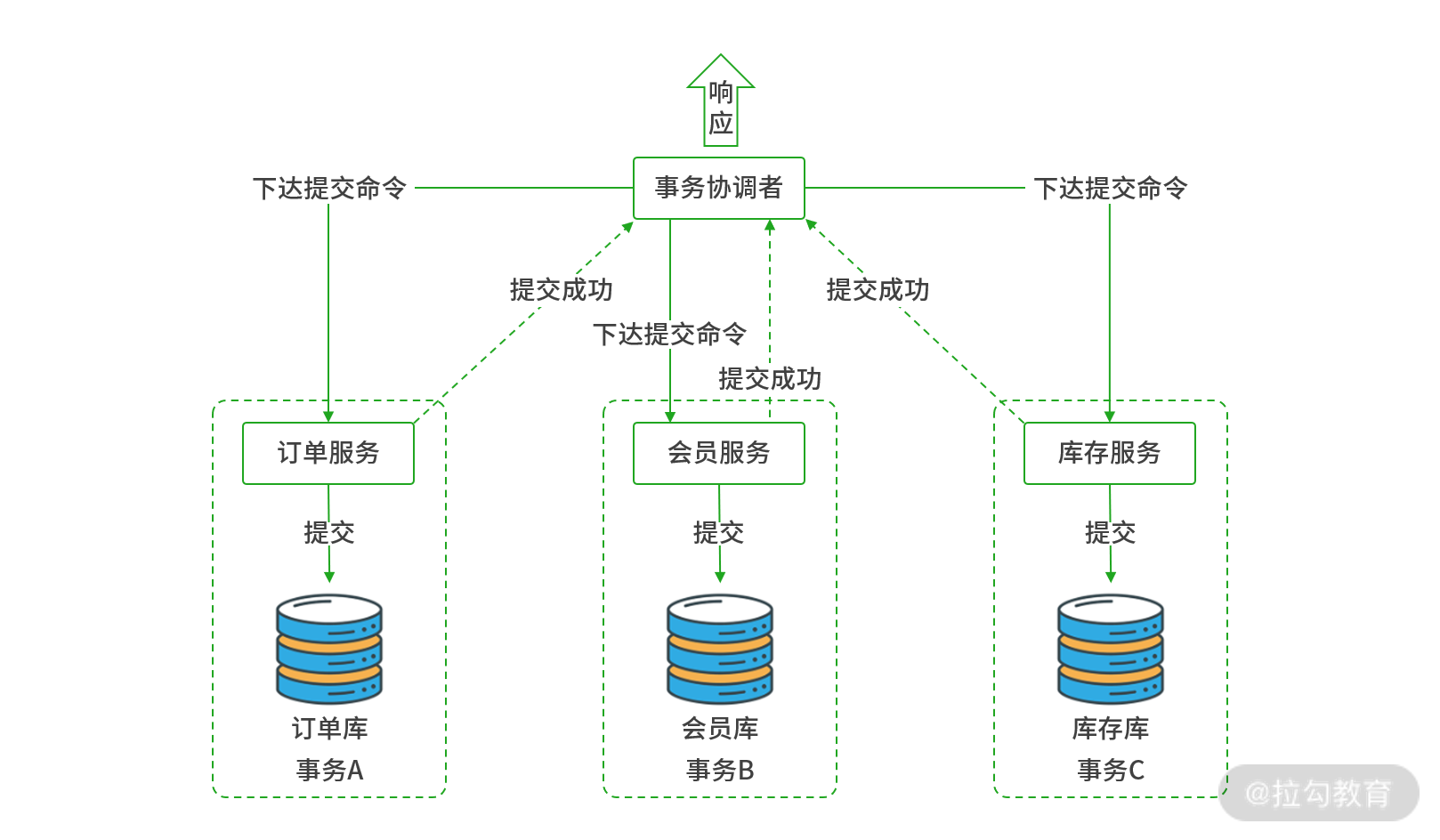
2PC 阶段二:提交阶段
在提交阶段,事务协调者会向每一个服务下达提交命令,每个服务收到提交命令后在本地事务中对阶段一未提交的数据执行 Commit 提交以完成数据最终的写入,之后服务便向事务协调者上报“提交成功”的通知。当事务协调者收到所有服务“提交成功”的通知后,就意味着一次分布式事务处理已完成。
这便是二阶段提交的正常执行过程,但假设在阶段一有任何一个服务因某种原因向事务协调者上报“事务处理失败”,就意味着整体业务处理出现问题,阶段二的操作就自动改为回滚(Rollback)处理,将所有未提交的数据撤销,使数据还原以保证完整性。
对于二阶段提交来说,它有一个致命问题,当阶段二某个服务因为网络原因无法收到协调者下达的提交命令,则未提交的数据就会被长时间阻塞,可能导致系统崩溃。
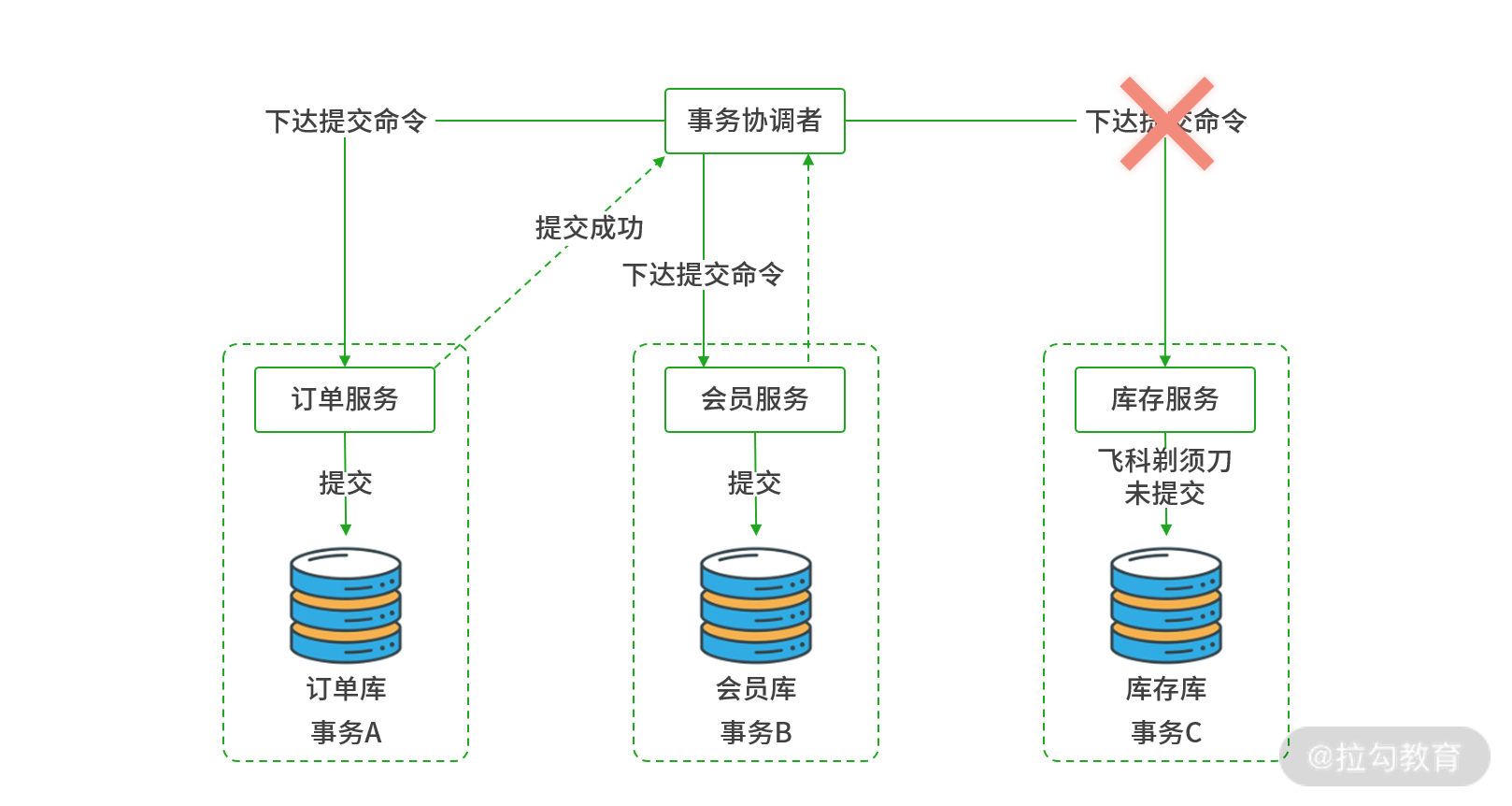
二阶段提交的缺陷
以上图为例,假如在提交阶段,库存服务实例与事务协调者之间断网。提交指令无法下达,这会导致库存中的“飞科剃须刀”商品库存记录会长期处于未提交的状态,因为这条记录被数据库排他锁长期独占,之后再有其他线程要访问“飞科剃须刀”库存数据,该线程就会长期处于阻塞状态,随着阻塞线程的不断增加,库存服务会面临崩溃的风险。
那这个问题要怎么解决呢?其实只要在服务这一侧增加超时机制,过一段时间被锁定的“飞科剃须刀”数据因超时自动执行提交操作,释放锁定资源。尽管这样做会导致数据不一致,但也比线程积压导致服务崩溃要好,出于此目的,三阶段提交(3PC)便应运而生。
三阶段提交
三阶段提交实质是将二阶段中的提交阶段拆分为“预提交阶段”与“提交阶段”,同时在服务端都引入超时机制,保证数据库资源不会被长时间锁定。下面是三阶段提交的示意流程:
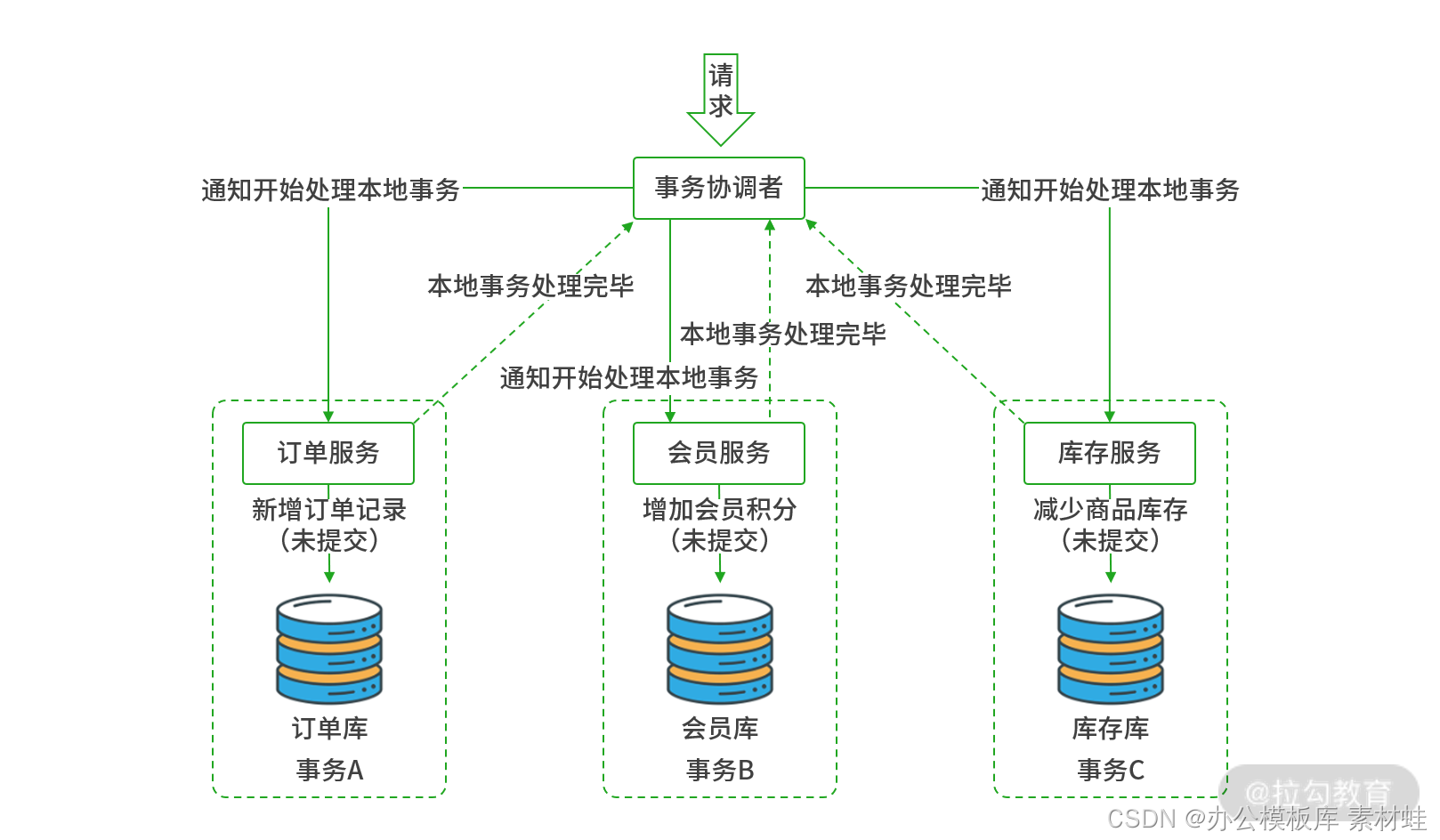
3PC 阶段一:事务预处理阶段
-
阶段一:事务预处理阶段。
3PC 的事务预处理阶段与 2PC 是一样的,用于处理本地事务,锁定数据库资源,当所有服务返回成功后,进入阶段二。
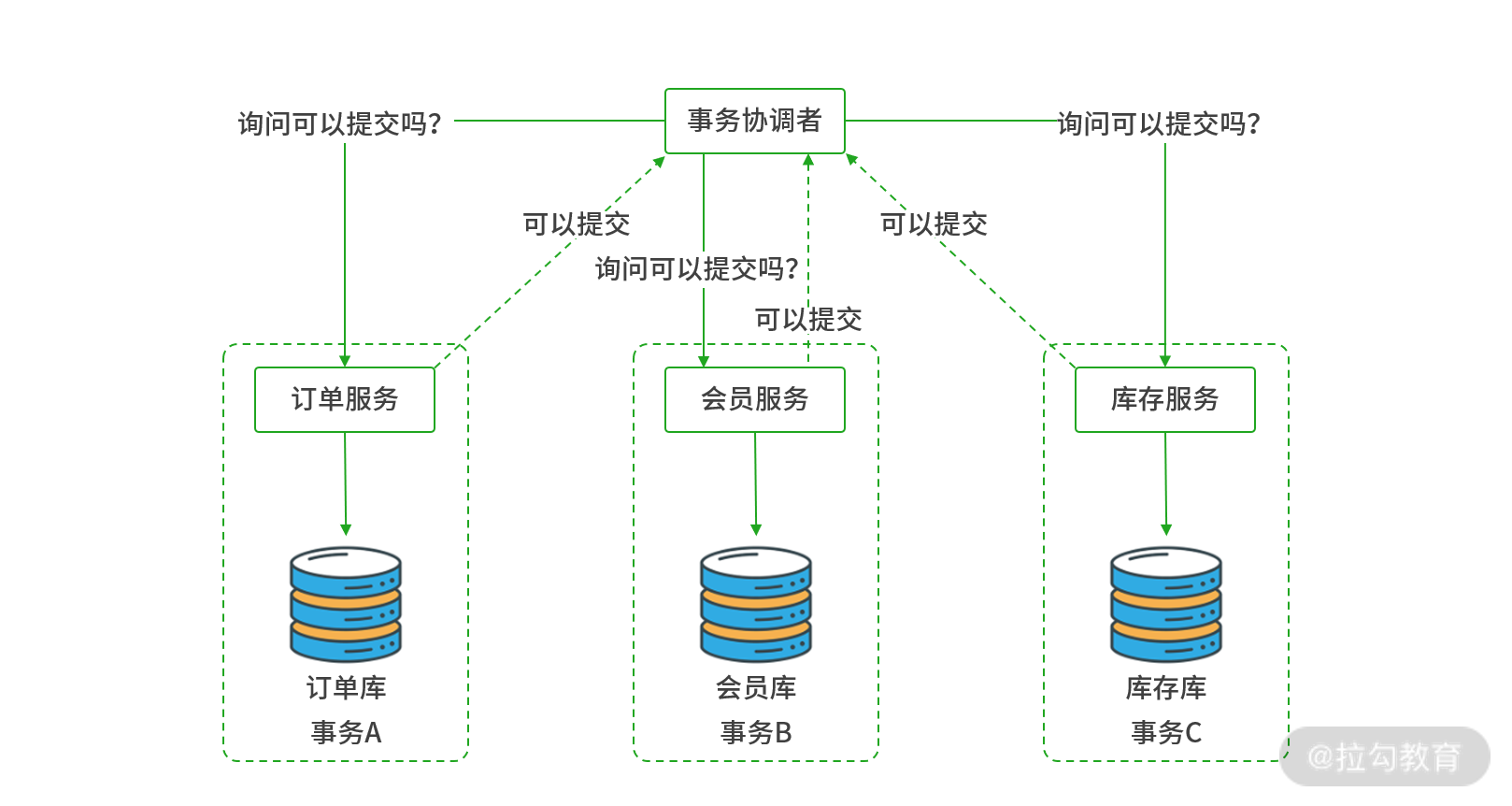
3PC 阶段二:预提交阶段
-
阶段二:预提交阶段。
预提交阶段只是一个询问机制,以确认所有服务都已准备好,同时在此阶段协调者和参与者都设置了超时时间以防止出现长时间资源锁定。当阶段二所有服务返回“可以提交”,进入阶段三“提交阶段”。
-
阶段三:提交阶段。
3PC 的提交阶段与 2PC 的提交阶段是一致的,在每一个数据库中执行提交实现数据的资源写入,如果协调者与服务通信中断导致无法提交,在服务端超时后在也会自动执行提交操作来保证资源释放。
通过对比我们发现,三阶段提交是二阶段提交的优化版本,主要通过加入预提交阶段引入了超时机制,让数据库资源不会被长期锁定,但这也会带来一个新问题,数据一致性也很可能因为超时后的强制提交被破坏,对于这个问题各大软件公司都在各显神通,常见的做法有:增加异步的数据补偿任务、日终跑批前的数据补偿、更完善的业务数据完整性的校验代码、引入数据监控及时通知人工补录这些都是不错的补救措施。
讲到这,相比你对 2PC 与 3PC 的分布式事务方案应该有了初步的了解,这里我还是要强调下,无论是 2PC 与 3PC 都是一种方案,是一种宏观的设计。如果要落地就要依托具体的软件产品,在 Java 开源领域能够提供完善的分布式事务解决方案的产品并不多,比较有代表性的产品有 ByteTCC、TX-LCN、EasyTransaction、Alibaba Seata,其中无论从成熟度、厂商背景、更新频度、社区活跃度各维度比较,Alibaba Seata都是数一数二的分布式事务中间件产品,本讲后面的内容将围绕Alibaba Seata的AT模式展开,探讨Alibaba Seata是如何实现自动化的分布式事务处理的。
Alibaba Seata 分布式事务中间件
Alibaba Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。它的官网是http://seata.io/,截止到目前 Seata 在 GitHub 已有 18564 star,最新版本已迭代到 1.4.0,阿里多年的技术沉淀让 Seata 的内部版本平稳渡过了多次双 11 的考验。2019 年 1 月为了打造更加完善的技术生态和普惠技术成果,Seata 正式宣布对外开源,未来 Seata 将以社区共建的形式帮助其技术更加可靠与完备,按官方的说法Seata目前已具备了在生产环境使用的条件。
Seata 提供了多种分布式事务的解决方案,包含 AT 模式、TCC 模式、SAGA 模式以及 XA 模式。其中 AT 模式提供了最简单易用且无侵入的事务处理机制,通过自动生成反向 SQL 实现事务回滚。从 AT 模式入手使用,使我们理解分布式事务处理机制是非常好的学习办法。

Seata 的特色功能
AT 模式是 Seata 独创的模式,它是基于 2PC 的方案,核心理念是利用数据库 JDBC 加上 Oracle、MySQL 自带的事务方式来对我们分布式事务进行管理。说起来有点晦涩,下边我就结合这张 AT 模式方案图给大家介绍,在 Seata 中关于分布式事务到底需要哪些组件,以及他们都起到了什么样的职能。
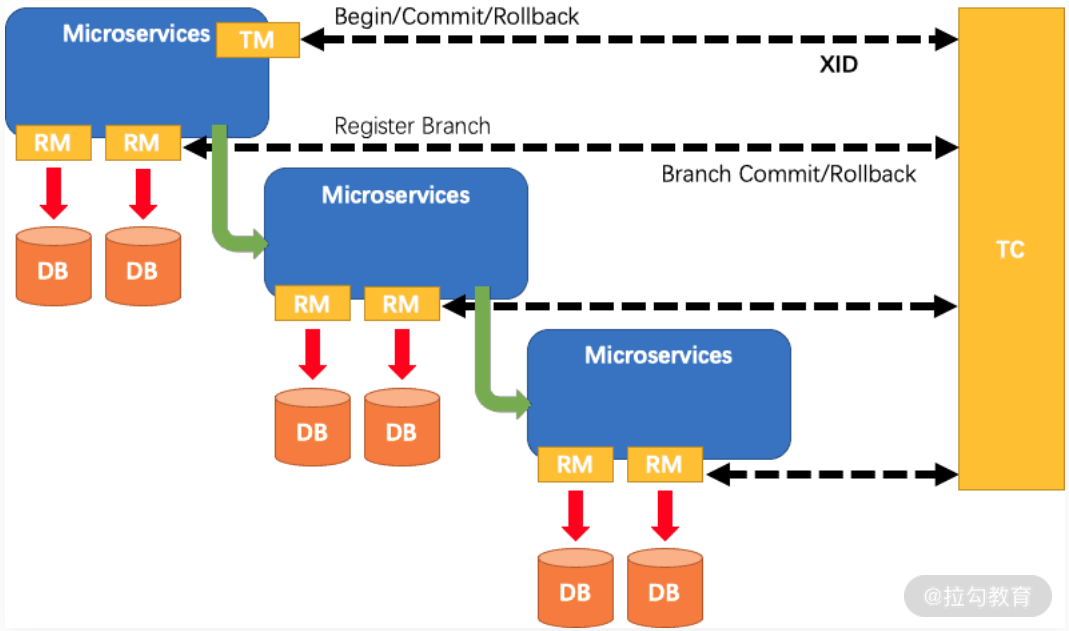
Seata 组件图
通过Seata组件图我们可以看到三个组成部分:
-
第一个是事务协调者(TC),它的作用是维护全局和分支事务的状态,驱动全局事务提交或者回滚,这正是前面讲解 2PC 或者 3PC 方案时提到的事务协调者组件的具体实现,TC 由 SEATA 官方提供。
-
第二个是事务管理器(TM),事务管理器用于定义全局事务的范围,开始全局事务提交或者回滚全局事务都是由 TM 来决定。
-
第三个是资源管理器(RM),他用于管理分支事务处理的资源,并且报告分支事务的状态,并驱动分支事务提交或者回滚。
这些概念可能有些晦涩,我们通过前面商城会员采购积分的例子进行讲解。
Seata AT 模式执行过程
创建订单调用逻辑
这里我先给出商城应用中会员采购业务的伪代码。
会员采购(){订单服务.创建订单();积分服务.增加积分();库存服务.减少库存();
}
在会员采购方法中,需要分别执行创建订单、增加积分、减少库存三个步骤完成业务,对于“会员采购”来说方法执行成功,则代表这个全局分布式事务需要提交,如果中间过程出错,则需要全局回滚,这个业务方法本身就决定了全局提交、回滚的时机以及决定了哪些服务需要参与业务处理,因此商城应用的会员采购方法就充当起事务管理器(TM)的角色。
而与之对应的在订单服务中创建订单、会员服务中增加积分、库存服务减少库存这些实际产生的数据处理的服务模块,则被称为资源管理器(RM)。
最后就是由Seata提供的Seata-Server中间件则提供事务协调者(TC)这个角色,实施全局事务1的提交、回滚命令下发。
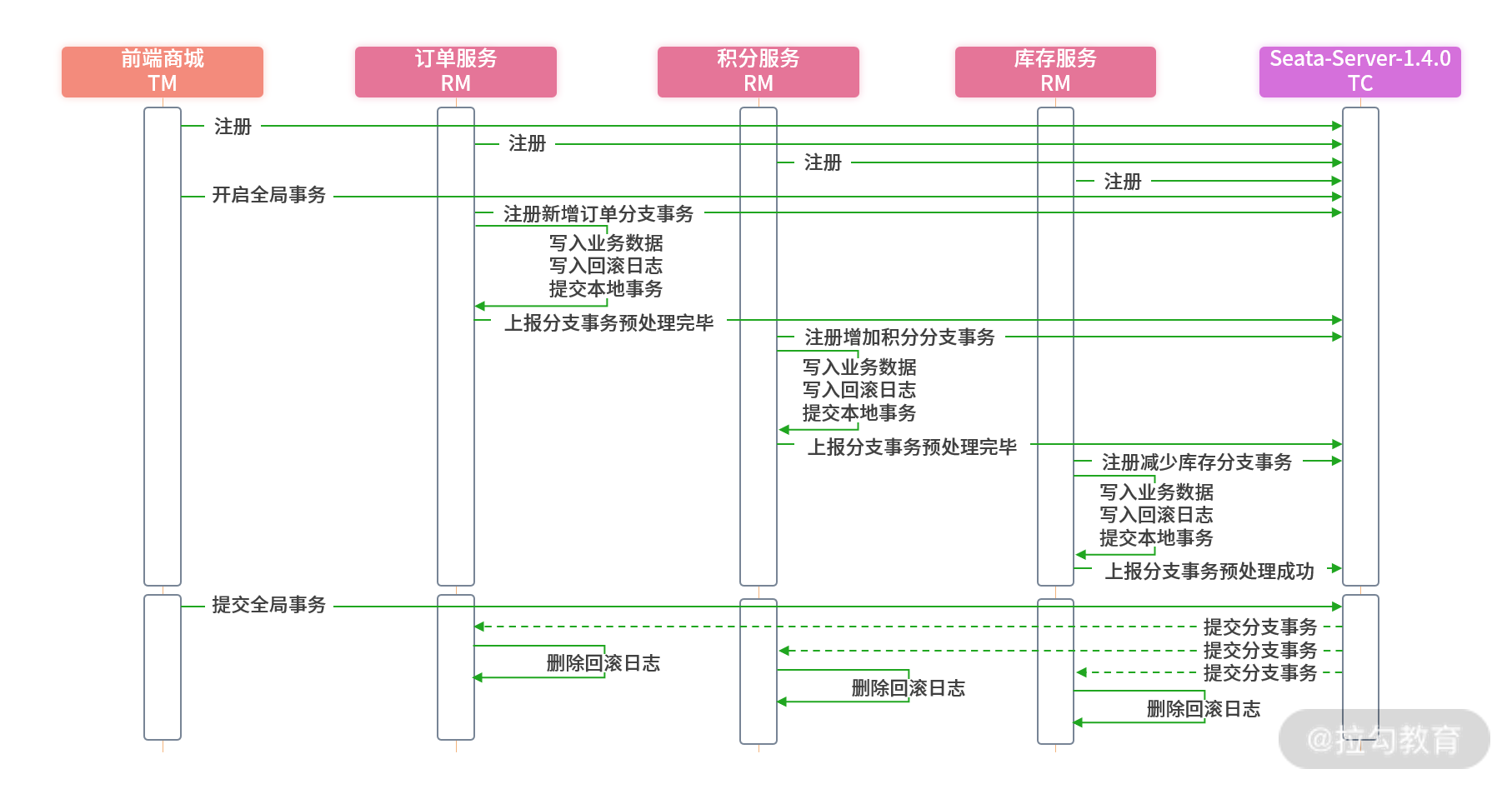
为了方便理解,我画了时序图介绍 Seata 的执行过程。
Seata 时序图
第一步,在商城应用(TM)与三个服务(RM)启动后自动向事务协调者Seata-Server(TC)进行注册,让 TC 知晓各个组件的详细信息。
第二步,当会员购物时会执行 TM 的“会员采购”方法,当进入方法前 Seata 为 TM 提供的客户端会自动生效,向 TC 发出开启全局事务的请求。
第三步,会员采购方法开始执行,会依次执行 3 个服务的新增订单、增加积分、减少库存,在请求送往新的 RM 时,都会向 TC 注册新的分支事务。这些分支事务在处理时不但向业务表写入数据,还会自动向 Seata 强制要求的 UNDO_LOG 回滚日志表写入回滚 SQL 日志。
以新增订单事务为例:新增订单时执行的 SQL 语句如下:
INSERT INTO order(id,...) values(1001,...)
与之对应的,Seata 的回滚日志是基于 SQL 反向生成,新增订单创建了 1001 订单,那 Seata会对 SQL 进行解析生成反向的回滚 SQL 日志保存在 UNDO_LOG 表,如下所示:
DELETE FROM order WHERE id = 1001
与之类似会员积分会生成加积分的业务 SQL 以及减积分的回滚 SQL。
#加积分
UPDATE FROM points SET point = 180 + 20 WHERE mid = 182
#UNDO_LOG表中的减积分SQL
UPDATE FROM points SET point = 200 - 20 WHERE mid = 182
第四步,当 RM 的分支事务执行成功后,会自动向 TC 上报分支事务处理成功。
第五步,当会员采购方法正确执行,所有 RM 也向 TC 上报分支事务处理成功,在“会员采购”方法退出前,TM 内置的 Seata 客户端会向 TC 自动发起“提交全局事务”请求。TC 收到“提交全局事务”请求,向所有 RM 下达提交分支事务的命令,每一个 RM 在收到提交命令后,会删除之前保存在 UNDO_LOG 表中的回滚日志。
但是事情总会有意外,假设某个 RM 分支事务处理失败,此时 TM 便不再向 TC 发起“提交全局事务”,转而发送“回滚全局事务”,TC 收到后,通知所有之前已处理成功的 RM 执行回滚 SQL 将数据回滚。
比如 1001 订单在第三步“减少库存”时发现库存不足导致库存服务预处理失败,那全局回滚时第一步订单服务会自动执行删除 1001 订单的回滚 SQL。
DELETE FROM order WHERE id = 1001
以及第二步积分服务会自动执行减少积分的回滚 SQL。
UPDATE FROM points SET point = 200 - 20 WHERE mid = 182
Seata AT模式就是通过执行反向 SQL 达到数据还原的目的,当反向 SQL 执行后便自动从 UNDO_LOG 表中删除。这便是 Seata AT 模式的大致执行过程,在这个过程中我们发现 Seata AT 模式设计的巧妙之处,Seata 为了能做到无侵入的自动实现全局事务提交与回滚,它在 TM端利用了类似于“Spring 声明式事务”的设计,在进入 TM 方法前通知 TC 开启全局事务,在成功执行后自动提交全局事务,执行失败后进行全局回滚。同时在 RM 端也巧妙的采用了 SQL 解析技术自动生成了反向的回滚 SQL 来实现数据还原。
在这我也思考过,为什么 Seata 要生成反向 SQL,而不是利用数据库自带的排他锁机制处理呢?翻阅资料后理解到它的设计意图,如果采用排它锁机制会导致数据资源被锁死,可能会产生大量的数据资源阻塞,进而存在应用崩溃的风险。而生成反向 SQL 的方案则是在预处理阶段事务便已提交,不会出现长时间数据资源锁定的情况,这样能有效提高并发量。但这样做也有弊端,在研究时发现 Seata 是工作在“读未提交”的隔离级别,高并发环境下容易产生脏读、幻读的情况,这也是需要特别注意的地方。
小结与预告
本讲我们首先针对分布式事务的 2PC 与 3PC 方案进行讲解,了解了分布式事务的执行过程与两者之间的区别;之后咱们认识了 Alibaba 出品的分布式事务中间件 Seata,最后通过电商会员采购的案例讲解了 Seata AT 模式的处理过程,让我们对 Seata 有了初步了解。在后面的实践篇,我们将本节偏理论的内容进行落地实现,看通过代码如何使用 Seata 处理分布式事务。
这里我为你留一道讨论题:既然分布式事务相比单点式事务要复杂得多,在项目中有什么好办法可以规避分布式事务呢?欢迎你把自己的想法写在评论区和大家一起分享。
下一讲我们讲解 Spring Cloud Alibaba 体系下的消息队列中间件 Alibaba RocketMQ,看通过 RocketMQ 如何解决服务间异步通信的问题。
17 消息队列:基于 RocketMQ 实现服务异步通信
上一讲,我们讲解了分布式事务的解决方案以及 Seata 分布式事务中间件AT模式的实现原理,在后面的实战篇,我们还将围绕 Seata 进行进一步的学习。本讲我们先来介绍分布式架构下另外一块重要拼图:消息队列 RocketMQ。
本讲咱们将学习以下三方面内容:
-
介绍消息队列与 Alibaba RocketMQ;
-
掌握 RocketMQ 的部署方式;
-
讲解微服务接入 RocketMQ 的开发技巧;
首先咱们先来认识什么是消息队列 MQ 呢?
消息队列与 RocketMQ
消息队列 MQ
消息队列(Message Queue)简称 MQ,是一种跨进程的通信机制,通常用于应用程序间进行数据的异步传输,MQ 产品在架构中通常也被叫作“消息中间件”。它的最主要职责就是保证服务间进行可靠的数据传输,同时实现服务间的解耦。
这么说太过学术,我们看一个项目的实际案例,假设市级税务系统向省级税务系统上报本年度税务汇总数据,按以往的设计市级税务系统作为数据的生产者需要了解省级税务系统的 IP、端口、接口等诸多细节,然后通过 RPC、RESTful 等方式同步向省级税务系统发送数据,省级税务系统作为数据的消费者接受后响应“数据已接收”。
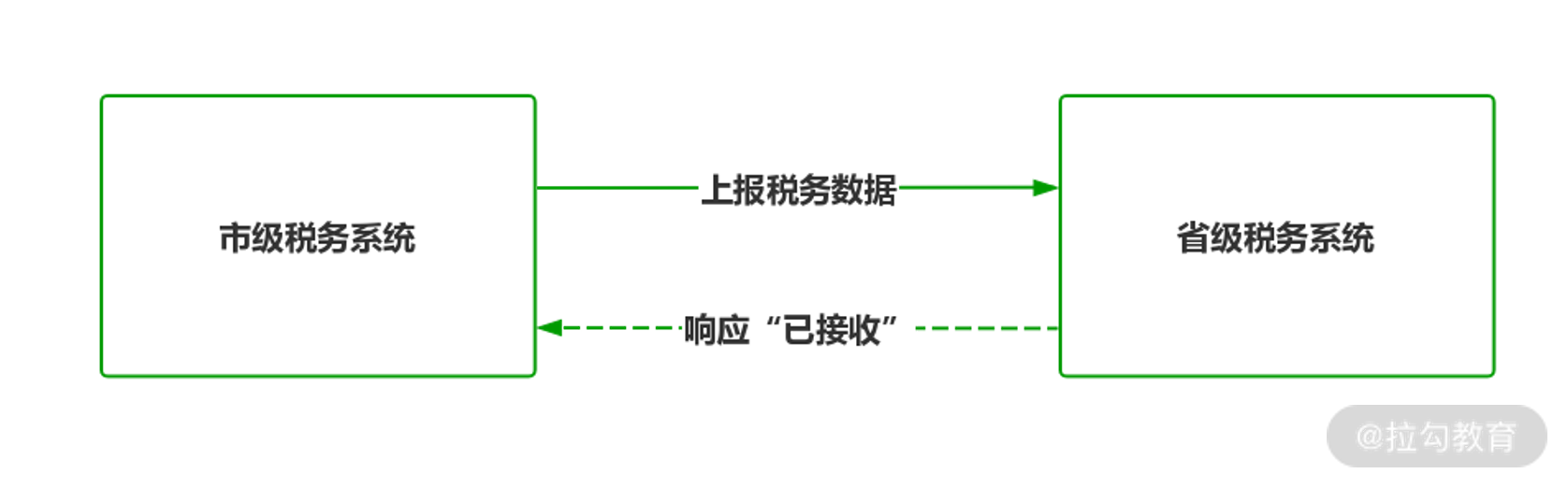
系统间跨进程通信
虽然从逻辑上是没有问题的,但是从技术层面却衍生出三个新问题:
-
假如上报时省级税务系统正在升级维护,市级税务系统就必须设计额外的重发机制保证数据的完整性;
-
假如省级税务系统接收数据需要 1 分钟处理时间,市级税务系统采用同步通信,则市级税务系统传输线程就要阻塞 1 分钟,在高并发场景下如此长时间的阻塞很容易造成系统的崩溃;
-
假如省级税务系统接口的调用方式、接口、IP、端口有任何改变,都必须立即通知市级税务系统进行调整,否则就会出现通信失败。
从以上三个问题可以看出,省级系统产生的变化直接影响到市级税务系统的执行,两者产生了强耦合,如果问题放在互联网的微服务架构中,几十个服务进行串联调用,每个服务间如果都产生类似的强耦合,系统必然难以维护。
为了解决这种情况,我们需要在架构中部署消息中间件,这个组件应提供可靠的、稳定的、与业务无关的特性,使进程间通信解耦,而这一类消息中间件的代表产品就是 MQ 消息队列。当引入 MQ 消息队列后,消息传递过程会产生以下变化。
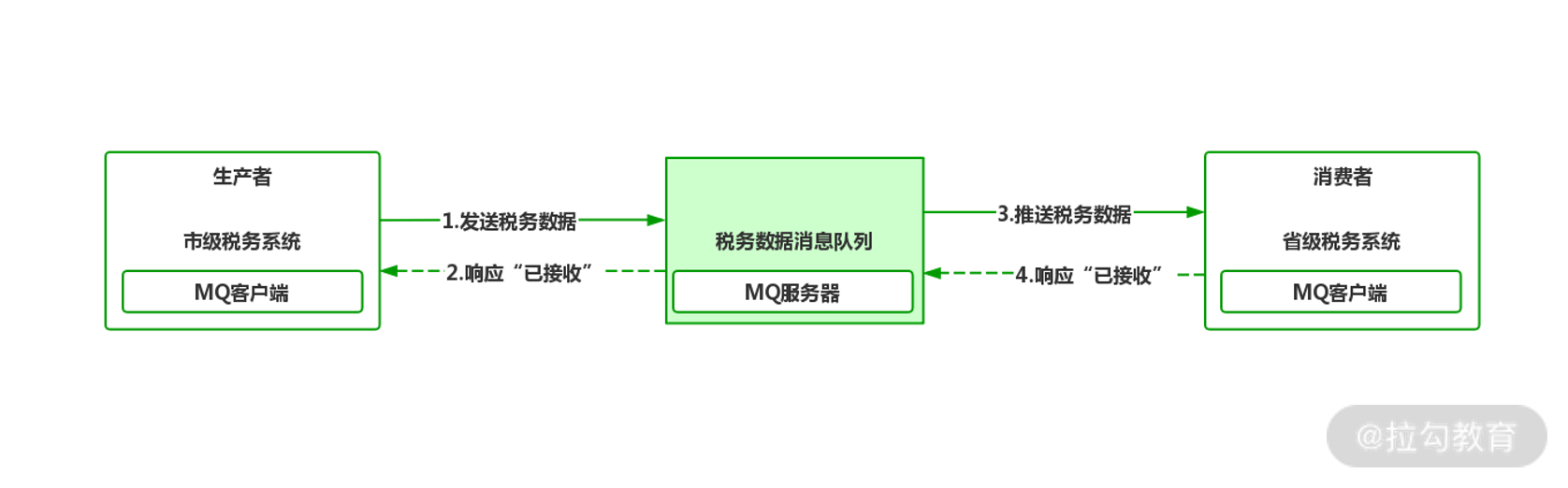
引入 MQ 后通信过程
可以看到,引入消息队列后,生产者与消费者都只面向消息队列进行数据处理,数据生产者根本不需要了解具体消费者的信息,只要把数据按事先约定放在指定的队列中即可。而消费者也是一样的,消费者端监听消息队列,如果队列中产生新的数据,MQ 就会通过“推送 PUSH”或者“抽取 PULL”的方式让消费者获取到新数据进行后续处理。
通过示意图可以看到,只要消息队列产品是稳定可靠的,那消息通信的过程就是有保障的。在架构领域,很多厂商都开发了自己的 MQ 产品,最具代表性的开源产品有:
-
Kafka
-
ActiveMQ
-
ZeroMQ
-
RabbitMQ
-
RocketMQ
每一种产品都有自己不同的设计与实现原理,但根本的目标都是相同的:为进程间通信提供可靠的异步传输机制。RocketMQ 作为阿里系产品天然被整合进 Spring Cloud Alibaba 生态,在经历过多次双 11 的考验后,RocketMQ 在性能、可靠性、易用性方面都是非常优秀的,下面咱们来了解下 RocketMQ 吧。
RocketMQ
RocketMQ 是一款分布式消息队列中间件,官方地址为http://rocketmq.apache.org/,目前最新版本为4.8.0。RocketMQ 最初设计是为了满足阿里巴巴自身业务对异步消息传递的需要,在 3.X 版本后正式开源并捐献给 Apache,目前已孵化为 Apache 顶级项目,同时也是国内使用最广泛、使用人数最多的 MQ 产品之一。
RocketMQ 有很多优秀的特性,在可用性方面,RocketMQ 强调集群无单点,任意一点高可用,客户端具备负载均衡能力,可以轻松实现水平扩容;在性能方面,在天猫双 11 大促背后的亿级消息处理就是通过 RocketMQ 提供的保障;在 API 方面,提供了丰富的功能,可以实现异步消息、同步消息、顺序消息、事务消息等丰富的功能,能满足大多数应用场景;在可靠性方面,提供了消息持久化、失败重试机制、消息查询追溯的功能,进一步为可靠性提供保障。
了解 RocketMQ 的诸多特性后,咱们来理解 RocketMQ 几个重要的概念:
-
消息 Message:消息在广义上就是进程间传递的业务数据,在狭义上不同的 MQ 产品对消息又附加了额外属性如:Topic(主题)、Tags(标签)等;
-
消息生产者 Producer:指代负责生产数据的角色,在前面案例中市级税务系统就充当了消息生产者的角色;
-
消息消费者 Consumer:指代使用数据的角色,前面案例的省级税务系统就是消息消费者;
-
MQ消息服务 Broker:MQ 消息服务器的统称,用于消息存储与消息转发;
-
生产者组 Producer Group:对于发送同一类消息的生产者,RocketMQ 对其分组,成为生产者组;
-
消费者组 Consumer Group:对于消费同一类消息的消费者,RocketMQ 对其分组,成为消费者组。
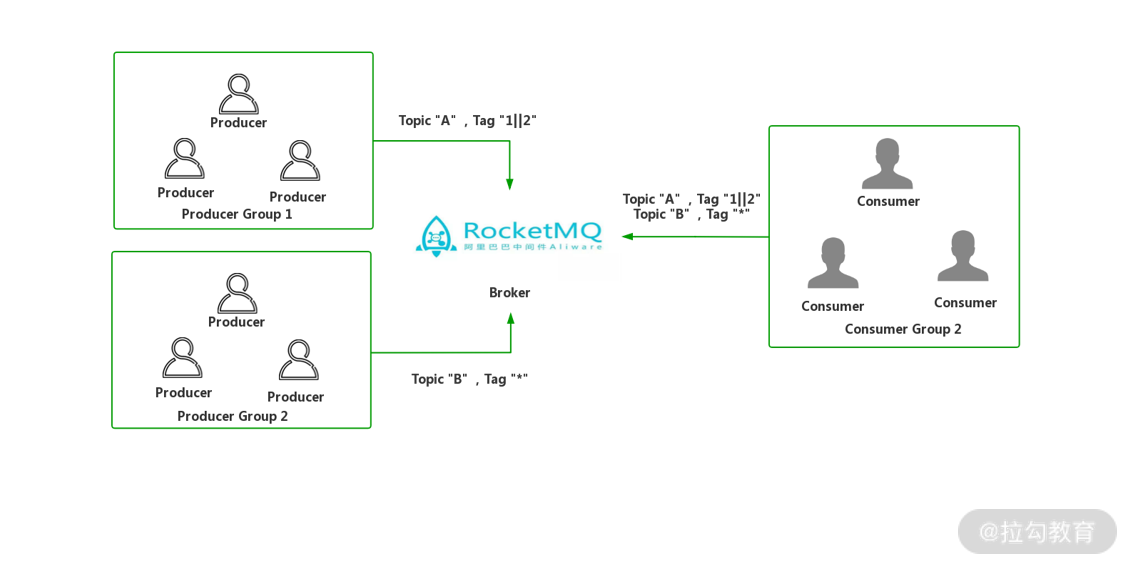
RocketMQ 组成示意图
在理解这些基本概念后,咱们正式进入 RocketMQ 的部署与使用环节,通过案例代码理解 RocketMQ 的执行过程。对于 RocketMQ 来说,使用它需要两个阶段:搭建 RocketMQ 服务器集群与应用接入 RocketMQ 队列,首先咱们来部署 RocketMQ 集群。
部署 RocketMQ 集群
RocketMQ 天然采用集群模式,常见的 RocketMQ 集群有三种形式:多 Master 模式、多 Master 多 Slave- 异步复制模式、多 Master 多 Slave- 同步双写模式,这三种模式各自的优缺点如下。
-
多 Master 模式是配置最简单的模式,同时也是使用最多的形式。优点是单个 Master 宕机或重启维护对应用无影响,在磁盘配置为 RAID10 时,即使机器宕机不可恢复情况下,由于 RAID10 磁盘非常可靠,同步刷盘消息也不会丢失,性能也是最高的;缺点是单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
-
多 Master 多 Slave 异步复制模式。每个 Master 配置一个 Slave,有多对 Master-Slave,HA 采用异步复制方式,主备有短暂消息毫秒级延迟,即使磁盘损坏只会丢失少量消息,且消息实时性不会受影响。同时 Master 宕机后,消费者仍然可以从 Slave 消费,而且此过程对应用透明,不需要人工干预,性能同多 Master 模式几乎一样;缺点是 Master 宕机,磁盘损坏情况下会丢失少量消息。
-
多 Master 多 Slave 同步双写模式,HA 采用同步双写方式,即只有主备都写成功,才向应用返回成功,该模式数据与服务都无单点故障,Master 宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;缺点是性能比异步复制模式低 10% 左右,发送单个消息的执行时间会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。
本讲我们将搭建一个双 Master 服务器集群,首先来看一下部署架构图:
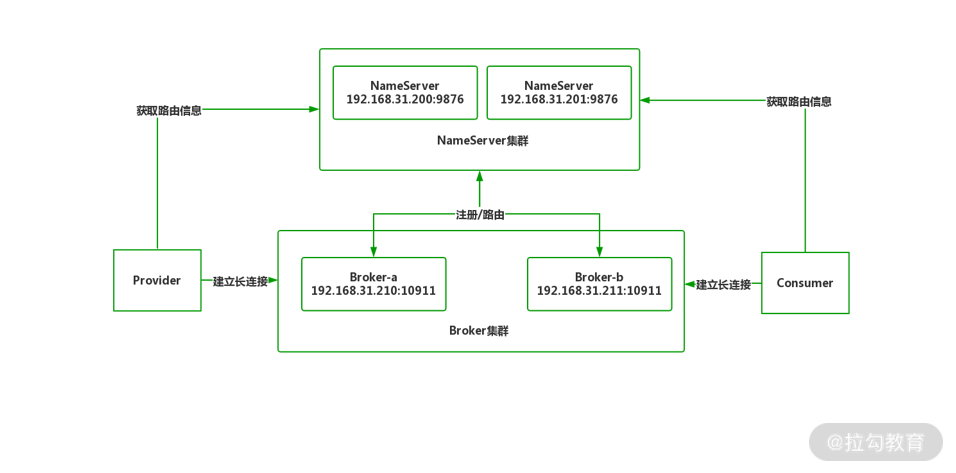
双 Master 架构图
在双 Master 架构中,出现了一个新角色 NameServer(命名服务器),NameServer 是 RocketMQ 自带的轻量级路由注册中心,支持 Broker 的动态注册与发现。在 Broker 启动后会自动向 NameServer 发送心跳包,通知 Broker 上线。当 Provider 向 NameServer 获取路由信息,然后向指定 Broker 建立长连接完成数据发送。
为了避免单节点瓶颈,通常 NameServer 会部署两台以上作为高可用冗余。NameServer 本身是无状态的,各实例间不进行通信,因此在 Broker 集群配置时要配置所有 NameServer 节点以保证状态同步。
部署 RocketMQ 集群要分两步:部署 NameServer 与部署 Broker 集群。
第一步,部署 NameServer 集群。
我们创建两台 CentOS7 虚拟机,IP 地址分别为 192.168.31.200 与 192.168.31.201,要求这两台虚拟机内存大于 2G,并安装好 64 位 JDK1.8,具体过程不再演示。
之后访问 Apache RocketMQ 下载页:
https://www.apache.org/dyn/closer.cgi?path=rocketmq/4.8.0/rocketmq-all-4.8.0-bin-release.zip
获取 RocketMQ 最新版 rocketmq-all-4.8.0-bin-release.zip,解压后编辑 rocketmq-all-4.8.0-bin-release/bin/runserver.sh 文件,因为 RocketMQ 是服务器软件,默认为其配置 8G 内存,这是 PC 机及或者笔记本吃不消的,所以在 82 行附近将 JVM 内存缩小到 1GB 以方便演示。
修改前:
JAVA_OPT="${JAVA_OPT} -server -Xms8g -Xmx8g -Xmn4g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
修改后:
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn512m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
修改完毕,将 rocketmq-all-4.8.0-bin-release 上传到两台 NameServer 虚拟机的 /usr/local 目录下,执行 bin 目录下的 mqnamesrv 命令。
cd /usr/local/rocketmq-all-4.8.0-bin-release/bin/
sh mqnamesrv
mqnamesrv 是 RocketMQ 自带 NameServer 的启动命令,执行后看到 The Name Server boot success. serializeType=JSON 就代表 NameServer 启动成功,NameServer 将占用 9876 端口提供服务,不要忘记在防火墙设置放行。之后如法炮制在另一台 201 设备上部署 NameServer,构成 NameServer 集群。
第二步,部署 Broker 集群。
我们再额外创建两台 CentOS7 虚拟机,IP 地址分别为 192.168.31.210 与 192.168.31.211,同样要求这两台虚拟机内存大于 2G,并安装好 64 位 JDK1.8。
打开 rocketmq-all-4.8.0-bin-release 目录,编辑 /bin/runbroker.sh 文件,同样将启动 Broker 默认占用内存从 8G 缩小到 1G,将 64 行调整为以下内容:
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn512m"
在 conf 目录下,RocketMQ 已经给我们贴心的准备好三组集群配置模板:
-
2m-2s-async 代表双主双从异步复制模式;
-
2m-2s-sync 代表双主双从同步双写模式;
-
2m-noslave 代表双主模式。
我们在 2m-noslave 双主模式目录中,在 broker-a.properties 与 broker-b.properties 末尾追加 NameServer 集群的地址,为了方便理解我也将模板里面每一项的含义进行注释,首先是 broker-a.properties 的完整内容如下:
#集群名称,同一个集群下的 broker 要求统一
brokerClusterName=DefaultCluster
#broker 名称
brokerName=broker-a
#brokerId=0 代表主节点,大于零代表从节点
brokerId=0
#删除日志文件时间点,默认凌晨 4 点
deleteWhen=04
#日志文件保留时间,默认 48 小时
fileReservedTime=48
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
brokerRole=ASYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘,性能好宕机会丢数
#- SYNC_FLUSH 同步刷盘,性能较差不会丢数
flushDiskType=ASYNC_FLUSH
#末尾追加,NameServer 节点列表,使用分号分割
namesrvAddr=192.168.31.200:9876;192.168.31.201:9876
broker-b.properties 只有 brokerName 不同,如下所示:
brokerClusterName=DefaultCluster
brokerName=broker-b
brokerId=0
deleteWhen=04
fileReservedTime=48
brokerRole=ASYNC_MASTER
flushDiskType=ASYNC_FLUSH
#末尾追加,NameServer 节点列表,使用分号分割
namesrvAddr=192.168.31.200:9876;192.168.31.201:9876
之后将 rocketmq-all-4.8.0-bin-release 目录上传到 /usr/local 目录,运行下面命令启动 broker 节点 a。
cd /usr/local/rocketmq-all-4.8.0-bin-release/
sh bin/mqbroker -c ./conf/2m-noslave/broker-a.properties
在 mqbroker 启动命令后增加 c 参数说明要加载哪个 Broker 配置文件。
启动成功会看到下面的日志,Broker 将占用 10911 端口提供服务,请设置防火墙放行。
The broker[broker-a, 192.168.31.210:10911] boot success. serializeType=JSON and name server is 192.168.31.200:9876;192.168.31.201:9876
同样的,在另一台 Master 执行下面命令,启动并加载 broker-b 配置文件。
cd /usr/local/rocketmq-all-4.8.0-bin-release/
sh bin/mqbroker -c ./conf/2m-noslave/broker-b.properties
到这里 NameServer 集群与 Broker 集群就部署好了,下面执行两个命令验证下。
第一个,使用 mqadmin 命令查看集群状态。
在 bin 目录下存在 mqadmin 命令用于管理 RocketMQ 集群,我们可以使用 clusterList 查看集群节点,命令如下:
sh mqadmin clusterList -n 192.168.31.200:9876
通过查询 NameServer 上的注册信息,得到以下结果。

Broker 集群信息
可以看到在 DefaultCluster 集群中存在两个 Broker,因为 BID 编号为 0,代表它们都是 Master 主节点。
第二个,利用 RocketMQ 自带的 tools.sh 工具通过生成演示数据来测试 MQ 实际的运行情况。在 bin 目录下使用下面命令。
export NAMESRV_ADDR=192.168.31.200:9876
sh tools.sh org.apache.rocketmq.example.quickstart.Producer
你会看到屏幕输出日志:
SendResult [sendStatus=SEND_OK, msgId=7F0000010B664DC639969F28CF540000, offsetMsgId=C0A81FD200002A9F00000000000413B6, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-a, queueId=1], queueOffset=0]
SendResult [sendStatus=SEND_OK, msgId=7F0000010B664DC639969F28CF9B0001, offsetMsgId=C0A81FD200002A9F000000000004147F, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-a, queueId=2], queueOffset=0]
SendResult [sendStatus=SEND_OK, msgId=7F0000010B664DC639969F28CFA30002, offsetMsgId=C0A81FD200002A9F0000000000041548, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-a, queueId=3], queueOffset=0]
SendResult [sendStatus=SEND_OK, msgId=7F0000010B664DC639969F28CFA70003, offsetMsgId=C0A81FD300002A9F0000000000033C56, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-b, queueId=0], queueOffset=0]
SendResult [sendStatus=SEND_OK, msgId=7F0000010B664DC639969F28CFD60004, offsetMsgId=C0A81FD300002A9F0000000000033D1F, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-b, queueId=1], queueOffset=0]
SendResult [sendStatus=SEND_OK, msgId=7F0000010B664DC639969F28CFDB0005, offsetMsgId=C0A81FD300002A9F0000000000033DE8, messageQueue=MessageQueue [topic=TopicTest, brokerName=broker-b, queueId=2], queueOffset=0]
...
其中broker-a、broker-b 交替出现说明集群生效了。
前面测试的是服务提供者,下面测试消费者,运行下面命令:
export NAMESRV_ADDR=192.168.31.200:9876
sh tools.sh org.apache.rocketmq.example.quickstart.Consumer
会看到消费者也获取到数据,到这里 RocketMQ 双 Master 集群的搭建就完成了,至于多 Master 多 Slave 的配置也是相似的,大家查阅官方文档相信也能很快上手。
ConsumeMessageThread_11 Receive New Messages: [MessageExt [brokerName=broker-b, queueId=2, storeSize=203, queueOffset=157, sysFlag=0, bornTimestamp=1612100880154, bornHost=/192.168.31.210:54104, storeTimestamp=1612100880159, storeHost=/192.168.31.211:10911, msgId=C0A81FD300002A9F0000000000053509, commitLogOffset=341257, bodyCRC=1116443590, reconsumeTimes=0, preparedTransactionOffset=0, toString()=Message{topic='TopicTest', flag=0, properties={MIN_OFFSET=0, MAX_OFFSET=158, CONSUME_START_TIME=1612100880161, UNIQ_KEY=7F0000010DA64DC639969F2C4B1A0314, CLUSTER=DefaultCluster, WAIT=true, TAGS=TagA}, body=[72, 101, 108, 108, 111, 32, 82, 111, 99, 107, 101, 116, 77, 81, 32, 55, 56, 56], transactionId='null'}]]
ConsumeMessageThread_12 Receive New Messages: [MessageExt [brokerName=broker-b, queueId=3, storeSize=203, queueOffset=157, sysFlag=0, bornTimestamp=1612100880161, bornHost=/192.168.31.210:54104, storeTimestamp=1612100880162, storeHost=/192.168.31.211:10911, msgId=C0A81FD300002A9F00000000000535D4, commitLogOffset=341460, bodyCRC=898409296, reconsumeTimes=0, preparedTransactionOffset=0, toString()=Message{topic='TopicTest', flag=0, properties={MIN_OFFSET=0, MAX_OFFSET=158, CONSUME_START_TIME=1612100880164, UNIQ_KEY=7F0000010DA64DC639969F2C4B210315, CLUSTER=DefaultCluster, WAIT=true, TAGS=TagA}, body=[72, 101, 108, 108, 111, 32, 82, 111, 99, 107, 101, 116, 77, 81, 32, 55, 56, 57], transactionId='null'}]]
集群部署好,那如何使用 RocketMQ 进行消息收发呢?我们结合 Spring Boot 代码进行讲解。
应用接入 RocketMQ 集群
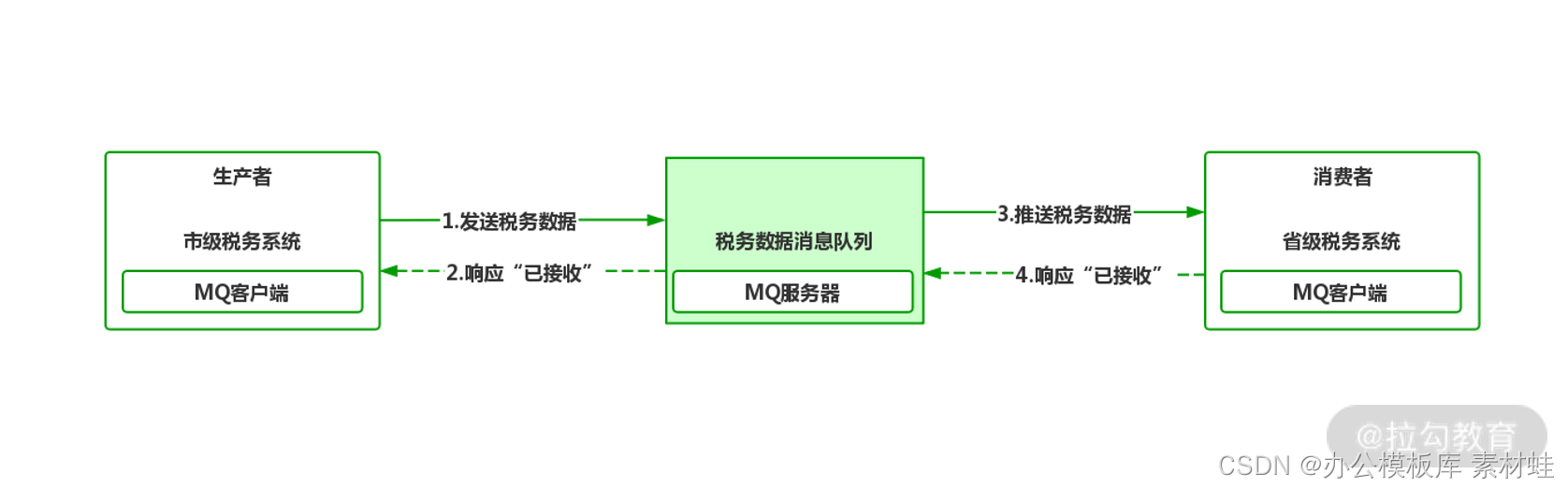
案例说明
我们以前面的报税为例,利用 Spring Boot 集成 MQ 客户端实现消息收发,首先咱们模拟生产者 Producer。
生产者 Producer 发送消息
第一步,利用 Spring Initializr 向导创建 rocketmq-provider 工程,确保 pom.xml 引入以下依赖。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- RocketMQ客户端,版本与Broker保持一致 -->
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId><version>4.8.0</version>
</dependency>
第二步,配置应用 application.yml。
rocketmq-client 主要通过编码实现通信,因此无须在 application.yml 做额外配置。
server:port: 8000
spring:application:name: rocketmq-producer
第三步,创建 Controller,生产者发送消息。
@RestController
public class ProviderController {Logger logger = LoggerFactory.getLogger(ProviderController.class);@GetMapping(value = "/send_s1_tax")public String send1() throws MQClientException {//创建DefaultMQProducer消息生产者对象DefaultMQProducer producer = new DefaultMQProducer("producer-group");//设置NameServer节点地址,多个节点间用分号分割producer.setNamesrvAddr("192.168.31.200:9876;192.168.31.201:9876");//与NameServer建立长连接producer.start();try {//发送一百条数据for(int i = 0 ; i< 100 ; i++) {//数据正文String data = "{\"title\":\"X市2021年度第一季度税务汇总数据\"}";/*创建消息Message消息三个参数topic 代表消息主题,自定义为tax-data-topic说明是税务数据tags 代表标志,用于消费者接收数据时进行数据筛选。2021S1代表2021年第一季度数据body 代表消息内容*/Message message = new Message("tax-data-topic", "2021S1", data.getBytes());//发送消息,获取发送结果SendResult result = producer.send(message);//将发送结果对象打印在控制台logger.info("消息已发送:MsgId:" + result.getMsgId() + ",发送状态:" + result.getSendStatus());}} catch (RemotingException e) {e.printStackTrace();} catch (MQBrokerException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();} finally {producer.shutdown();}return "success";}
}
在程序运行后,访问http://localhost:8000/send_s1_tax,在控制台会看到如下输出说明数据已被 Broker 接收,Broker 接收后 Producer 端任务已完成。
消息已发送:MsgId:7F00000144E018B4AAC29F3B7B280062,发送状态:SEND_OK
消息已发送:MsgId:7F00000144E018B4AAC29F3B7B2A0063,发送状态:SEND_OK
下面咱们开发消费者 Consumer。
消费者 Consumer 接收消息
第一步,利用 Spring Initializr 向导创建 rocketmq-consumer 工程,确保 pom.xml 引入以下依赖。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- RocketMQ客户端,版本与Broker保持一致 -->
<dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-client</artifactId><version>4.8.0</version>
</dependency>
第二步,application.yml 同样无须做额外设置。
server:port: 9000
spring:application:name: rocketmq-consumer
第三步,在应用启动入口 RocketmqConsumerApplication 增加消费者监听代码,关键的代码都已做好注释。
@SpringBootApplication
public class RocketmqConsumerApplication {private static Logger logger = LoggerFactory.getLogger(RocketmqConsumerApplication.class);public static void main(String[] args) throws MQClientException {SpringApplication.run(RocketmqConsumerApplication.class, args);//创建消费者对象DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer-group");//设置NameServer节点consumer.setNamesrvAddr("192.168.31.200:9876;192.168.31.201:9876");/*订阅主题,consumer.subscribe包含两个参数:topic: 说明消费者从Broker订阅哪一个主题,这一项要与Provider保持一致。subExpression: 子表达式用于筛选tags。同一个主题下可以包含很多不同的tags,subExpression用于筛选符合条件的tags进行接收。例如:设置为*,则代表接收所有tags数据。例如:设置为2020S1,则Broker中只有tags=2020S1的消息会被接收,而2020S2就会被排除在外。*/consumer.subscribe("tax-data-topic", "*");//创建监听,当有新的消息监听程序会及时捕捉并加以处理。consumer.registerMessageListener(new MessageListenerConcurrently() {public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {//批量数据处理for (MessageExt msg : msgs) {logger.info("消费者消费数据:"+new String(msg.getBody()));}//返回数据已接收标识return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});//启动消费者,与Broker建立长连接,开始监听。consumer.start();}
}
当应用启动后,Provider 产生新消息的同时,Consumer 端就会立即消费掉,控制台产生输出。
2021-01-31 22:25:14.212 INFO 17328 --- [MessageThread_3] c.l.r.RocketmqConsumerApplication : 消费者消费数据:{"title":"X市2021年度第一季度税务汇总数据"}
2021-01-31 22:25:14.217 INFO 17328 --- [MessageThread_2] c.l.r.RocketmqConsumerApplication : 消费者消费数据:{"title":"X市2021年度第一季度税务汇总数据"}
以上便是 Spring Boot 接入 RocketMQ 集群的过程。对于当前的案例我们是通过代码方式控制消息收发,在 Spring Cloud 生态中还提供了 Spring Cloud Stream 模块,允许程序员采用“声明式”的开发方式实现与 MQ 更轻松的接入,但 Spring Cloud Stream 本身封装度太高,很多 RocketMQ 的细节也被隐藏了,这对于入门来说并不是一件好事。在掌握 RocketMQ 的相关内容后再去学习 Spring Cloud Stream 你会理解得更加透彻。
小结与预告
本讲咱们学习了三方面内容,首先介绍了什么是 MQ 以及 Alibaba RocketMQ 的特性;其次详细讲解了 RocketMQ 双主集群的部署过程;最后通过 Spring Boot 应用中引入 RocketMQ-Client 实现消息的收发。
这里为你留一道思考题:目前主流的 MQ 产品有 RocketMQ、RabbitMQ、Kafka、ActiveMQ、ZeroMQ……不同的产品有不同的设计,假设在银行的金融交易基于 MQ 实现,对 MQ 的可靠性与一致性要求较高,但对数据的响应时间不敏感。如果你是架构师该如何选型,欢迎你把自己的思考写在评论区和大家一起分享。
下一讲我们将开始一个新的篇章,将之前学过的 Spring Cloud Alibaba 综合运用,看在实际项目中有哪些成熟的经验可以为我所用。
这篇关于SpringCloud Alibaba实战第六课 分布式事务Seata和异步通信RocketMQ的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





