本文主要是介绍Visual Tracking with Online Multiple Instance Learning(MIL),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Visual Tracking with Online Multiple Instance Learning[paper]
目标跟踪算法MIL是2009年的CVPR,官方称其算法即将集成到openCV中,因此官方不再提供代码支持.
下面只针对其paper内容做个人阅读总结,有不正确之处还请批评指正.
摘要
- 一般目标跟踪系统由三部分组成:image representation, appearance model, motion model. 本文集中研究目标跟踪自适应外观模型。
- 跟踪技术:tracking by detection——通过训练一个在线 discriminative classifier, 用来将跟踪目标从背景中分离出来。
- 传统的监督学习当跟踪过程中出现轻微错误时就能导致训练失误,降低分类正确率,甚至发生极大地漂移。MIL算法就是解决上述问题,使跟踪器在少量参数调整情况下拥有更好地鲁棒性。
- 本文主要讨论外观模型问题,并且文中提到“默认使用Haar-like特征对于适度的旋转与尺度变化下是不变的”,所以本文设计默认特征旋转与尺度是不变的。
- 本文中 image representation 由一组 Haar-like特征组成(使用Haar筛选器筛选出图像的边缘、线条、中心圆等信息,Andrew Ng在deeplearning课程中讲过 ); appearance model 是一个discriminative classifier, 其返回p(y=1|x),其中x是一个patch,y是0或1;运动模型使用贪心策略更新跟踪器位置,即在上一帧跟踪器的半径s内取一系列patches,然后计算所有p(y=1|x),p(y=1|x)取最大值的x即为本帧的跟踪器位置(运动模型更新如下图所示)。

整体思路
在进行自适应外观模型的更新时,正负样本的选择是一个重要的问题。在本文中,样本的选择使用bag的形式,这也正是MIL的关键所在。

使用上述代码是进行正负样本的选择:
- 在时刻t输入第k帧图像
- 在第k-1帧(t-1时刻帧)的半径s内随机剪切出一系列patches(Haar-like特征),同时计算出其向量值
- 使用MIL分类器得出每一个x片段(patch)p(y=1|x)的概率
- 选取p(y=1|x)最大值的patch作为当前帧目标的位置
- 以当前目标位置为中心在其半径r内随机剪切出一系列patches作为正样本bags,在大于半径r小于半径 β \beta β内随机剪切出一系列patches作为负样本bags
- 使用选取的正负样本集对外观模型进行更新
注:
1.正负样本集{( X 1 , y 1 X_1,y_1 X1,y1)…( X n , y n X_n,y_n Xn,yn)},其中 X i X_i Xi={ x i 1 , . . . x i n x_{i1},...x_{in} xi1,...xin}是样本bags, x i j x_{ij} xij是剪切出的每一个patch,而 y i y_i yi并不是每个样本标签,而是包标签,文中对于 y i y_i yi的定义为: y i y_i yi= max j \max \limits_{j} jmax( y i j y_{ij} yij)。
2.文中提出如果一个bag内所有patch中至少有一个正样本,那么bag标签就为positive,若bag内所有patch为负样本,那么bag标签为negative。如此就解决了传统监督学习在训练期间对每一个具体的patch的标签未知,无法打标签情况。
discriminative classifier
1.文中使用的discriminative classifier并不是一个简单的弱分类器,而是通过boosting将许多弱分类器组合成一个强分类器,即将弱分类器线性叠加,形成Haar级联分类器:
H(x) = ∑ k = 1 K \sum_{k=1}^K ∑k=1K a k h k ( x ) a_kh_k(x) akhk(x)
其中 a k a_k ak为权重标量, h k h_k hk是弱分类器,K为选取的要级联的弱分类器数(文中提到可以将每个弱分类器作为一个特征,选取K个特征训练模型,K一般远小于全部弱分类器的个数M)。
2.由于AdaBoost的指数损失函数特性不能很容易的适应MIL问题,因此本文采用增强的统计视图方式优化损失函数J,在此视图下,弱分类器按如下式进行更新:
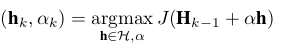 (1)
(1)
其中 H k − 1 H_{k-1} Hk−1是第k-1个由弱分类器组成的强分类器
3.当进行弱分类器更新时,我们更新所有的弱分类器,然后按照下面公式从中依次选出K个弱分类器h:
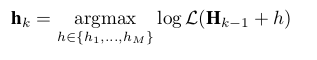 (2)
(2)
文中,对于当前视频帧的训练集{( X 1 , y 1 X_1,y_1 X1,y1)…( X n , y n X_n,y_n Xn,yn)},其中 X i X_i Xi={ x i 1 , . . . x i n x_{i1},...x_{in} xi1,...xin},使用最大似然函数求解每一个bag为正样本概率,好处是可以减少正样本bag中存在负样本对模型的影响,同时可以将cost function变成凸函数,方便求最值:
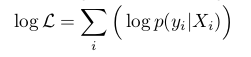 (3)
(3)
其中:
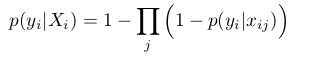 (4)
(4)
文中提到此模型为Noisy-OR模型,用以求取正样本bag概率
而:
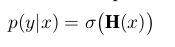 (5)
(5)
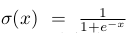 (6)
(6)
综合以上三点,文中判别模型更新伪代码如下:

- 输入训练数据集{ X i , y i X_i,y_i Xi,yi},即我们在上面提到的:以当前目标位置为中心在其半径r内随机剪切出一系列patches作为正样本bags,在大于半径r小于半径 β \beta β内随机剪切出一系列patches作为负样本bags
- 第3-8行:求每一个弱分类器的损失函数(cost function)
( a )第5行求样本 x i j x_{ij} xij在第m个弱分类器上的概率值
( b )第6行求bag样本 X i X_i Xi在第m个弱分类上的概率值
( c )第7行求第m个弱分类器在所有bags上的cost(这里实际上取得是cost的负数,也就是-cost,关于cost函数的介绍及推导Andrew Ng在machine learning课程中有详细讲解) - 第8行是依次从M个弱分类器中选取K个最大弱分类器(在上面第7步,求取的是-cost,那么想要得到最小cost,即是取第7行的最大值)
- 第10行使用 h m ( x ) h_m(x) hm(x)更新 h k ( x ) h_k(x) hk(x),更新规则以公式2形式。
- 第11行使用得到的 h k ( x ) h_k(x) hk(x)更新 H i j H_{ij} Hij,从而进行 h K + 1 ( x ) h_{K+1}(x) hK+1(x)的求取
- 输出为K个弱分类器线性组合成的强分类器
注:弱分类器实现细节
本文中每一个弱分类器 h k h_k hk都由一个Haar-like特征 f k f_k fk与四个参数( μ 1 , σ 1 , μ 2 , σ 2 \mu_1,\sigma_1,\mu_2,\sigma_2 μ1,σ1,μ2,σ2)组成,其返回的是一个对数概率值。
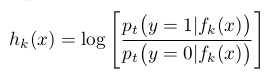 (7)
(7)
其中 p t p_t pt( f t ( x ) ∣ f_t(x)| ft(x)∣y=1)服从二项分布( μ 1 , σ 1 \mu_1,\sigma_1 μ1,σ1), p t p_t pt( f t ( x ) ∣ f_t(x)| ft(x)∣y=0)服从二项分布( μ 2 , σ 2 \mu_2,\sigma_2 μ2,σ2)。
文中假设p(y=1) = p(y=0) ,使用贝叶斯来计算上式 h k ( x ) h_k(x) hk(x),当接收到新数据{( x 1 , y 1 x_1,y_1 x1,y1)…( x n , y n x_n,y_n xn,yn)}时,使用如下规则进行参数更新:
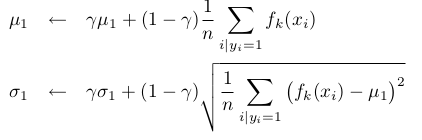 (8)
(8)
其中 γ \gamma γ是学习率参数, μ 0 \mu_0 μ0与 σ 0 \sigma_0 σ0更新方式类似。
Discussion
文中列出了需要特意注意的几个问题:
1.使用带有正样本的包标签训练弱分类器并不是最优办法,因为正样本包中有些patch可能是负样本。本文中使用最大似然函数求解每一个bag为正样本概率( 公式(3) )
2.在统计视图下弱分类器的更新公式为(1),而模型中使用的为公式(2),因为在实际应用中,二者对于分类器性能上没有差别。
3.文中提出,公式(2)的优化仅在当前实例中计算,并没有保留以前的观察数据,因此存在过拟合风险。使用弱分类器就可以避免这类情况,因为这些分类器保留了先前的观察数据,从而平衡当前数据与历史数据。
参考博客:越野者、 小小菜鸟一只、HEscop、Qiang Wang
这篇关于Visual Tracking with Online Multiple Instance Learning(MIL)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[VC] Visual Studio中读写权限冲突](/front/images/it_default.jpg)

