本文主要是介绍ACL2023 | 知识引导下的因果感知概念抽取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来自:知识工场
进NLP群—>加入NLP交流群
本文介绍的研究工作来自于复旦大学知识工场实验室发表在自然语言处理顶级学术会议ACL2023的最新论文《Causality-aware Concept Extraction based on Knowledge-guided Prompting》。近年来,预训练语言模型PLM在基于文本的概念抽取中得到了广泛的应用。然而,PLM倾向于将预训练阶段中从语料库中挖掘的共生关联作为视为正确的知识而忽略token间的因果效应,该预训练知识会使PLM基于虚假的共生相关性提取出偏差概念。该篇论文的工作不仅证明了基于PLM的概念抽取模型易产生概念偏差,而且设计了一个结构因果模型对概念偏差进行深入分析,同时提出一种基于知识引导提示(prompt)的概念抽取框架KPCE。该框架采用KG现有知识中给定实体的主题作为prompt,通过前门调整降低实体和偏差概念之间的虚假共现相关性从而缓解概念偏差。在多语言KG数据集上进行的大量实验证明了本文提出的prompt可以有效缓解概念偏差并且提升基于PLM的抽取模型的性能。该研究工作被作为ACL2023的主会长文接收,主要完成人为复旦大学大数据学院的21级卓博生员司雨,主要指导教师为阳德青副教授。

Paper: https://arxiv.org/abs/2305.01876
一、研究背景
知识图谱(KG)中的概念能够使机器更好地理解自然语言,但现有知识图谱(KG)中的概念,尤其是细粒度的概念,仍然不够完整。例如,大型中文知识图谱CN-DBpedia中有近1700万个实体,但总共只有27万个概念,甚至超过20%的实体没有概念;Probase中包含两个或多个修饰符的细粒度概念仅占30%。
从文本中抽取多粒度概念可以有效补全KG,但现有的基于PLM的概念抽取方法存在概念偏差。在预训练期间,实体和偏差概念经常在许多文本中同时出现。PLM倾向于从大量语料库中挖掘统计关联,而不是它们之间的真正因果效应,这会在实体和偏差概念之间引发虚假的共现相关性。例如图1,即使明确地将实体“Louisa May Alcott”输入模型,基于PLM的抽取模型仍会错误地抽取到概念“novel”。
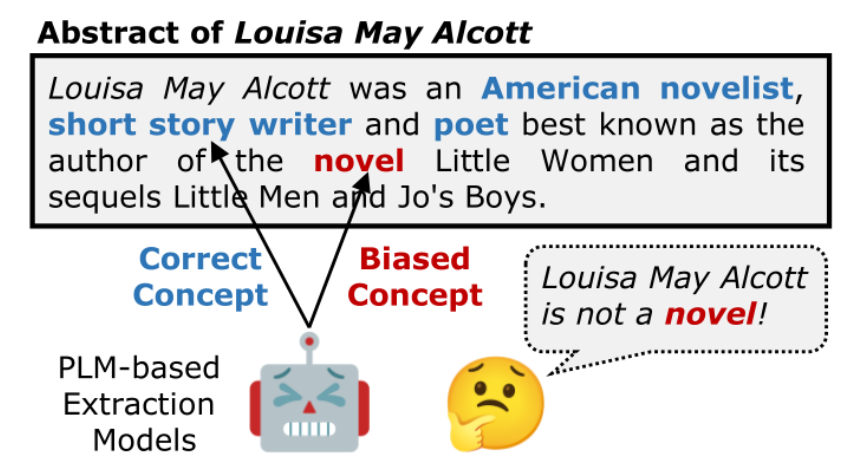
图1:概念偏差示例图
二、概念偏差的实证研究
为了证明概念偏差的存在,作者对CN-DBpedia进行了实证研究。首先从CN-DBpedia中随机抽取100万个实体及其概念,并选择前100个具有最多实体的概念作为典型概念集,然后随机选择100个实体和它们对每个典型概念的摘要来构建输入文本,并通过基于vanilla BERT的概念抽取来获得概念。为了量化概念偏差的程度,概念A对另一个概念B的偏差率计算为:
偏差率生成模型错误地生成了或的子概念的实体的数量的实体总数
26个典型概念的偏差率如图2所示,其中同一主题的概念聚集在一个矩形中。从图中可以得出结论,在基于PLM的CE系统中概念偏差普遍存在,并对抽取结果产生负面影响。

图2:CN-DBpedia的概念偏差图
三、结构因果模型
问题建模:
给定实体E的输入文本X和概念S,结构因果模型需要识别给定实体E的输入文本X和概念S之间的因果效应并从因果的角度分析概念偏差。
模型框架:
本文提出的结构因果模型主要包括混淆变量K的提出和基于prompt的因果干预,图3是结构因果模型框架图,图中空心圆圈表示变量是潜在的,阴影圆圈表示变量可以被观察到。
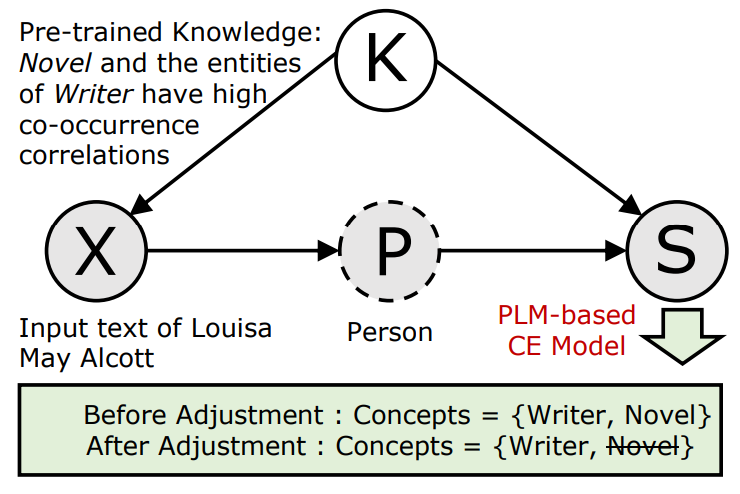
图3:结构因果模型框架图
混淆变量K
给定实体E的输入文本X和概念span S之间的因果效应可以表示为X→ S,在预训练过程中,一个token的上下文embedding取决于语料库中频繁出现在附近的tokens。作者推断,在预先训练的知识中,真实概念(如writer)的实体和偏差概念(如novel)之间的高度共现会导致实体(如Louisa May Alcott)和偏差概念(如novel)之间的虚假相关性。因此,即使X中明确提到了实体,基于PLM的CE模型也可能错误地提取有偏见的概念。
基于上述分析,作者将来自基于PLM的提取模型的预训练知识K定义为混淆变量K,K会打开X→ S的后门路径,由于混淆变量K的存在,基于PLM的CE模型会因为实体和概念之间的虚假相关性而提取偏差概念。
基于prompt的因果干预
因为无法直接观察PLM的潜在空间,后门调节不适用于我们的情况。因此采用前门调节。为了减轻概念偏差,作者构造了一个prompt P作为X→ S的中介,构建的中介变量P可以阻断X的后门路径→ S(由K打开)。具体来说,为了使PLM减轻虚假的共现相关性(例如,novel和Louisa May Alcott),将一个主题指定为输入文本X的知识引导prompt P(例如 person),从KGs获得的主题独立于预训练的知识,因此P满足前门标准。
对于因果效应X→ P,可以观察到X→ P→ S← K是一个阻止P和K之间关联的碰撞器,而且X→ P没有后门路径。因此,可以直接依赖于对X应用do算子后的条件概率为:
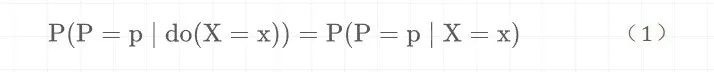
接下来,对于因果效应P→ S, P← X← K→ S是从P到S的后门路径,需要切断。由于K是一个未观察到的变量,可以通过X阻断后门路径:

因此,CE任务的潜在因果机制是等式(1)和等式(2)的组合,可以公式化为:
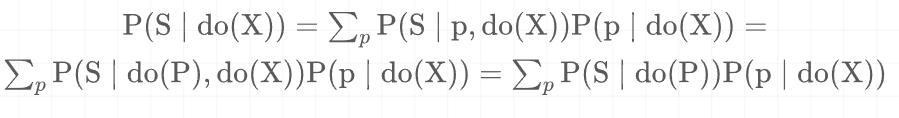
作者假设了强可忽略性,即X和S之间只有一个混杂因素K。前门标准的一个假设是,输入文本X影响S的唯一方式是通过中介P。因此,X→ P→ S必须是唯一的路径。否则,前车门调整无法支撑。因为K表示来自PLM中预先训练的数据的所有知识,所以通过前门调整可以阻断从输入文本到概念的后门路径,并减轻混杂因素(即预训练的知识)引起的虚假相关性。
四、概念抽取框架KPCE介绍
问题定义:
给定实体 以及相关文本 ,其中 和 是一个word token,本文提出的KPCE框架从T中提取一个或多个span作为实体E的概念。
模型框架:
KPCE的总体框架如图4所示,它由两个主要模块组成:1)prompt构造器:将从实体的KGs中获得的主题分配为知识引导prompt,以估计等式(1);2) 概念抽取器:使用构造的prompt训练基于BERT的提取器,以估计等(2)并从输入文本中提取多粒度概念。
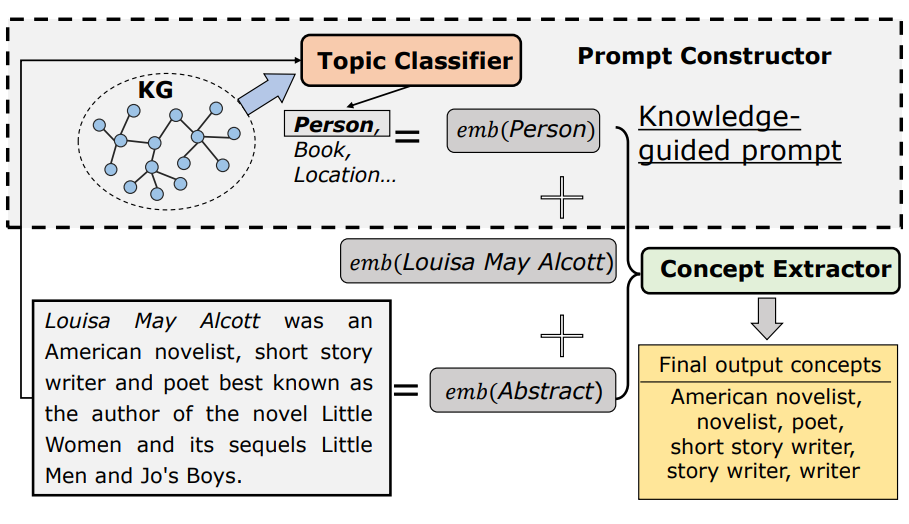
图4:概念抽取框架图
1、prompt构造器
1.1
知识引导的prompt构建
框架使用给定实体的主题作为知识引导prompt,它是基于现有KGs的外部知识来识别的。以CN-DBpedia为例,从中随机抽取了一百万个实体,并获得了它们现有的概念。然后选择实体最多的前100个概念来构成典型概念集,该概念集可以覆盖KG中99.80%以上的实体。接下来,使用光谱聚类和自适应K-means算法将这些典型概念聚类为几个组,每个组对应一个主题。为了实现光谱聚类,使用以下重叠系数来测量两个概念之间的相似性:
其中 和 分别是概念 和概念 的实体集。然后,作者构建了一个典型概念的相似矩阵来实现光谱聚类。为了确定最佳集群数量,计算了3到30个集群的Silhouette系数(SC)和Calinski Harabaz指数(CHI)。得分如图5所示,可以发现聚类的最佳数量是17。因此,作者将典型的概念分为17组,并为每组定义一个主题名称。
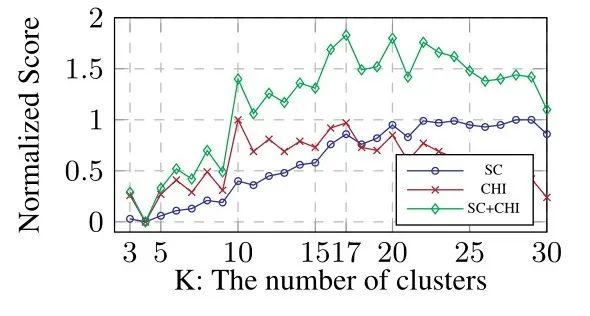
图5:SC和CHI在不同聚类数下的得分图
1.2
识别每个实体的主题prompt
作者采用主题分类器将主题prompt(17个典型主题之一)分配给输入文本X,为了构建训练数据,随机提取40000个实体及其抽象文本和KG中现有的概念。根据概念聚类结果,可以将每个主题分配给这些实体。作者采用transformer encoder后接由激活函数为ReLU的双层感知机作为我们的主题分类器。通过训练主题分类器来预测X的主题prompt ,计算公式为:
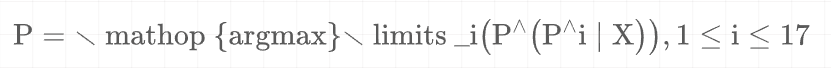
其中 是17个典型主题中的第i个主题。通过人工评估,主题分类器在500个样本中达到了97.8%以上的准确率。通过训练主题分类器,可以估计方程1,以确定因果效应X→ P。
2、概念抽取器
2.1
基于prompt的BERT
概念抽取器是采用指针网络的基于prompt的BERT,指针网络用于提取多粒度概念。首先将token序列与token P和X连接起来以构成输入,即 ,采用多头自我注意力机制,BERT输出的最终隐藏层 。其中 是向量维度, 是层数。指针网络预测一个token是所提取span的开始位置和结束位置的概率,从而估计等式2中的因果效应。如下公式,使用 , 来表示存储所有token作为开始位置和结束位置概率的向量:
其中 和 都是可训练参数。在此,只考虑文本T中token的概率。给定一个以 和 作为起始标记和结束标记的span,其置信度 为:
模型输出候选概念(spans)的排序列表及其置信度得分,保留置信度分数大于阈值的概念。
2.2
模型训练
作者采用交叉熵函数CE(·)作为模型的损失函数。假设 (或 )包含每个输入token是概念起始(结束)位置的真实标签(0/1),那么有以下两个训练损失:
总的训练损失为:
其中 是控制参数。我们使用Adam来优化 。
五、实验与分析
数据集:
CN-DBpedia:从最新版本的CN DBpedia和维基百科中随机抽取了100000个实例来构建样本池。样本池中的每个实例都由一个实体及其概念和抽象文本组成。然后,作者从池中抽取500个实例作为测试集,并根据9:1将其余实例划分为训练集和验证集。
Probase:从Probase和维基百科获得了50000个实例的英文样本池。训练、验证和测试集的构建方式与中文数据集相同。
评估指标:
提取的概念可能已经存在于给定实体的KG中,将其表示为 (现有概念)。然而,作者期望提取正确但新的概念(KG中不存在)来补全 ,将其称为 (新概念)。
因此,记录新概念的数量( ),并将正确概念的比例( 和 )显示为精度( )。由于很难知道输入文本中所有正确的概念,引入了相对召回率( )和相对F1( ),假设 是所有模型提取的新概念的总数,则有:
此外,作者还记录了新概念的平均长度( )来验证指针网络的有效性。
实验结果:
作者将KPCE与七个基线进行了比较,包括模式匹配方法(Hearst pattern),由于一些提取的概念在KG中不存在,不能自动评估。因此,作者邀请人工注释者来评估提取的概念是否正确。由表1可知,本文方法在很大程度上优于以前的基线(然而基于模式的方法在精度上仍然优于基于学习的方法)。还发现,KPCE在提取新概念方面取得了更显著的改进,表明KPCE可以用于实现KG补全。作者还将KPCE与其消融变体进行了比较,结果表明,添加知识引导prompt可以指导BERT获得准确的CE结果。其次,与基于学习的基线相比,KPCE可以提取更多细粒度的概念。尽管Hearst pattern也可以提取细粒度概念,但当一个粗粒度概念是另一个细粒度概念的子序列时,则不能同时提取多粒度概念。例如,在图4中,如果Hearst pattern提取American novelist作为一个概念,它就无法同时提取novelist。KPCE在指针网络的帮助下提取到了更多细粒度概念,并实现了更高的召回率。
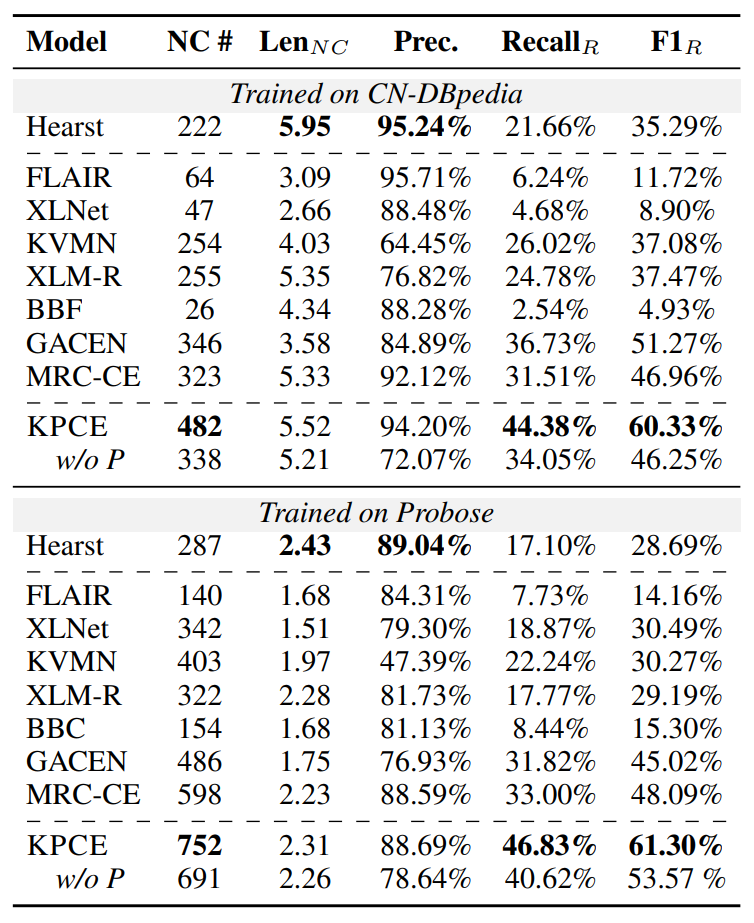
表1:500个测试样本的概念提取性能比较表(w/o P是KPCE在没有知识引导prompt的情况下的消融变体(P))
作者还注意到几乎所有模型在中文数据集上的提取精度都高于英文数据集。这是因为在汉语句法结构中,修饰语通常放在名词之前,因此更容易识别这些修饰语并将它们与粗粒度的概念一起提取出来,形成细粒度的概念。然而,对于英语数据集,不仅形容词,从句也修饰粗粒度的概念,因此识别这些修饰语更加困难。
分析:
KPCE如何缓解概念偏差?
为了证明KPCE可以在prompt的帮助下缓解概念偏差,作者还随机选择了5个典型概念,并运行KPCE及其消融变体,从5个概念中的每一个概念中随机选择100个实体来抽取概念,然后计算了每个概念的偏差率,表2中的结果表明,KPCE的偏差比基于vanilla BERT的概念抽取低得多。因此,知识引导的prompt可以显著缓解概念偏差。
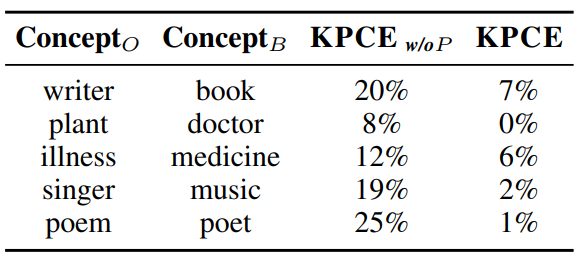
表2:五个典型概念在KPCE w/o P和KPCE下的偏差率表( 是最初的概念, 是有偏见的概念)
此外,通过表3所示的实体韩语字母表可以发现,prompt可以通过降低偏差概念(即language和alphabet)的置信度得分和增加正确概念(即system和writing system)的得分来缓解实体和偏差概念之间的虚假共现相关性。因此,知识引导的prompt可以显著缓解概念偏差,并产生更准确的CE结果。
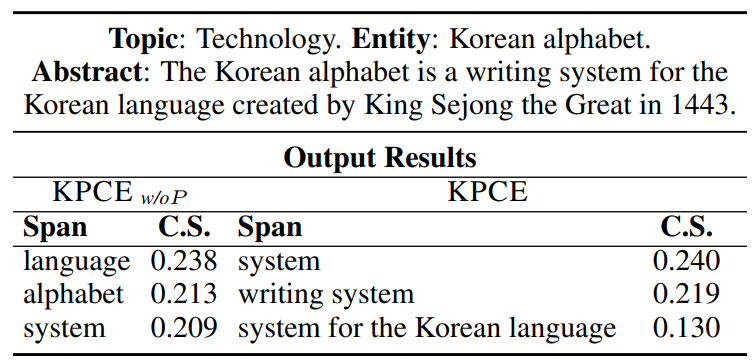
表3:实体韩语字母表(验证prompt在解决概念偏见方面的有效性的案例,其中包含前3个提取的spans和置信度分数C.S.)
Prompt如何影响虚假的共现相关性?
为了探索基于prompt的中介背后的基本原理,作者将重点放在特殊标记[CLS]的注意力分布上,因为它是序列的聚合表示,可以捕捉句子级别的语义。作者通过对最后一层中的12个注意力头中的注意力值进行平均和归一化,计算出[CLS]对其他tokens的注意力概率。如图6所示,在基于vanilla BERT的概念抽取中,writer和novel都受到了高度关注。然而,在采用知识引导prompt后,novel的注意概率比以前更低,因此可以帮助模型减少预训练知识导致的虚假共现相关性。
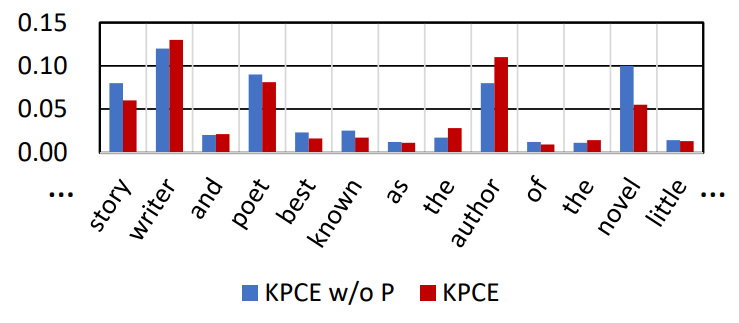
图6:KPCE及其消融变体中[CLS]对其他tokens的注意力分布可视化图
如果采用其它知识注入方法呢?
作者认为在引导BERT实现CE任务上,外部KGs获得的主题比文本中获得的基于关键字的主题更好。为了证明这一点,作者将KPCE与另一个变体,即 进行了比较,其中主题是通过在所有实体的摘要上运行潜在狄利克雷分配(LDA)获得的关键字。此外,作者还将KPCE与ERNIE进行了比较,ERNIE在预训练期间隐式学习实体的知识。比较结果由表4所示,可以看出KPCE中设计的知识引导prompt比其余两种方案更充分地利用了外部知识的价值,从而在概念抽取上有更好的性能。
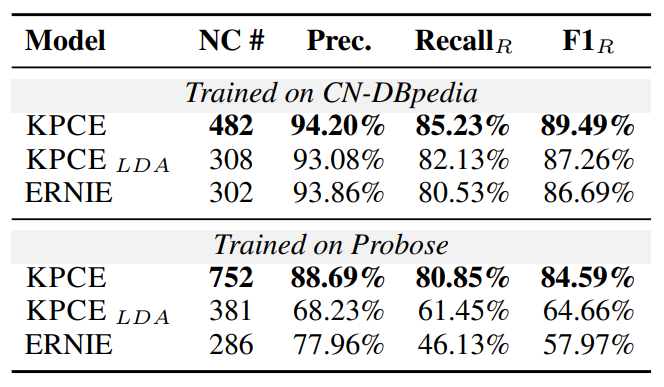
表4:采用不同知识的概念抽取结果表
六、应 用
KG补全:
KPCE框架可以为现有的KGs实现大规模的概念补全。作者使用KPCE为CN-DBpedia中的600万个实体提取了7623111个新概念。
领域概念获取:
作者从美团收集了117489个Food & Delight实体及其描述性文本,并探索了两种应用方法。第一种是直接使用KPCE,第二种是随机选择300个样本作为小训练集来微调KPCE。表5中的结果表明:1)在prompt的帮助下,KPCE的迁移能力大大提高;2) KPCE只需使用一小部分训练样本就可以在新领域中提取高质量的概念。此外,在直接使用后,KPCE提取了81800个新概念,准确率为82.66%。因此,作者的知识引导prompt可以显著提高PLM在领域CE任务上的转移能力。
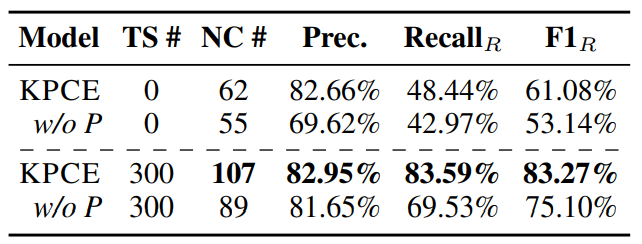
表5:KPCE作用在美团实体上的结果表( 是训练样本的数量)
七、总 结
本文的作者提出了基于PLM的CE系统中的概念偏差并设计了一个结构因果模型进行偏差分析,同时提出了一种具有知识引导prompt的模型抽取框架KPCE来缓解概念偏差。大量的实验证明了KPCE可以显著减轻概念偏差,并且在概念获取方面具有优异的性能。
进NLP群—>加入NLP交流群
这篇关于ACL2023 | 知识引导下的因果感知概念抽取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








