acl2023专题

多语言生成式语言模型用于零样本跨语言事件论证提取(ACL2023)
1、写作动机: 经过预训练的生成式语言模型更好地捕捉实体之间的结构和依赖关系,因为模板提供了额外的声明性信息。先前工作中模板的设计是依赖于语言的,这使得很难将其扩展到零样本跨语言转移设置。 2、主要贡献: 作者提出了一项研究,利用多语言预训练生成模型进行零样本跨语言事件论证提取,并提出了X-GEAR模型。 3、零样本跨语言事件论元抽取: 4、X-GEAR方法: 图如上所示。
多语言历史报纸广告事件抽取(ACL2023)
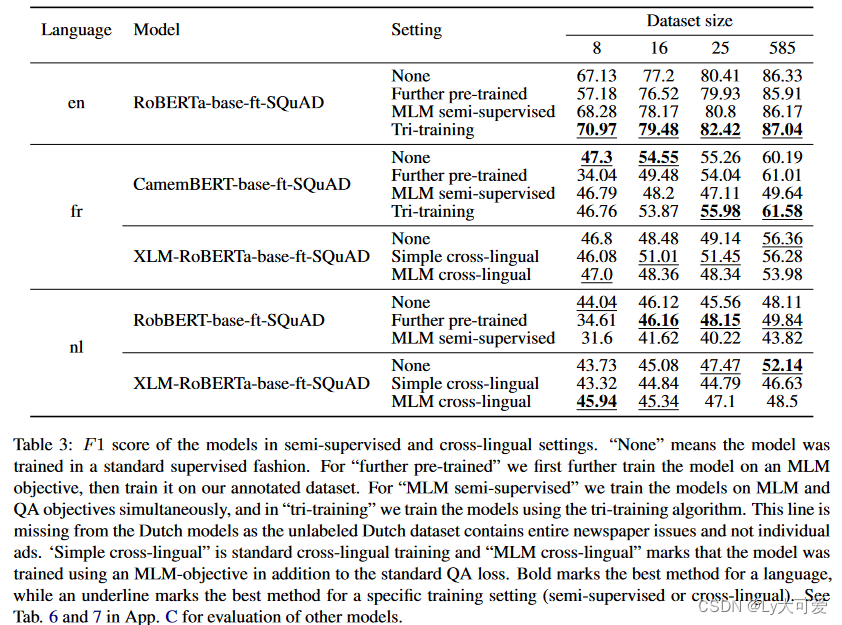
1、写作动机: 首先,获取大规模的、有注释的历史数据集是困难的,因为只有领域专家才能可靠地为它们打标签。其次,大多数现成的NLP模型是在现代语言文本上训练的,这使得它们在应用于历史语料库时效果显著降低。这对于研究较少的任务以及非英语语言尤为棘手。 2、主要贡献: •构建了一个新的多语言数据集,包括英语、法语和荷兰语的“寻求自由事件”,由奴隶主发布的广告,报道了试图通过逃离奴役寻求自由的被
ACL2023 | 知识引导下的因果感知概念抽取
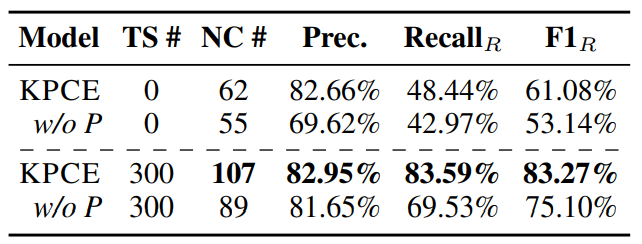
来自:知识工场 进NLP群—>加入NLP交流群 本文介绍的研究工作来自于复旦大学知识工场实验室发表在自然语言处理顶级学术会议ACL2023的最新论文《Causality-aware Concept Extraction based on Knowledge-guided Prompting》。近年来,预训练语言模型PLM在基于文本的概念抽取中得到了广泛的应用。然而,PLM倾向于将预训练阶段中从语