本文主要是介绍2023暑期培训【week 3】——ResNet+ResNeXt,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.ResNet+ResNeXt
1.1 ResNet
1.2 ResNeXt
2.猫狗大战代码练习
2.1 LeNet
2.2 ResNet
3.问题理解
1 ResNet+ResNeXt
1.1 ResNet
ResNet(残差网络)是一种深度残差神经网络结构,由Microsoft Research团队于2015年提出。它是针对训练非常深的神经网络时遇到的梯度消失(gradient vanishing)和梯度爆炸(gradient exploding)问题的解决方案之一。
在传统的深度神经网络中,随着网络层数的增加,梯度会以指数级的方式衰减,导致难以训练非常深的网络。ResNet通过引入了“残差块”(residual block)的概念来解决这个问题。
残差模块如下图所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
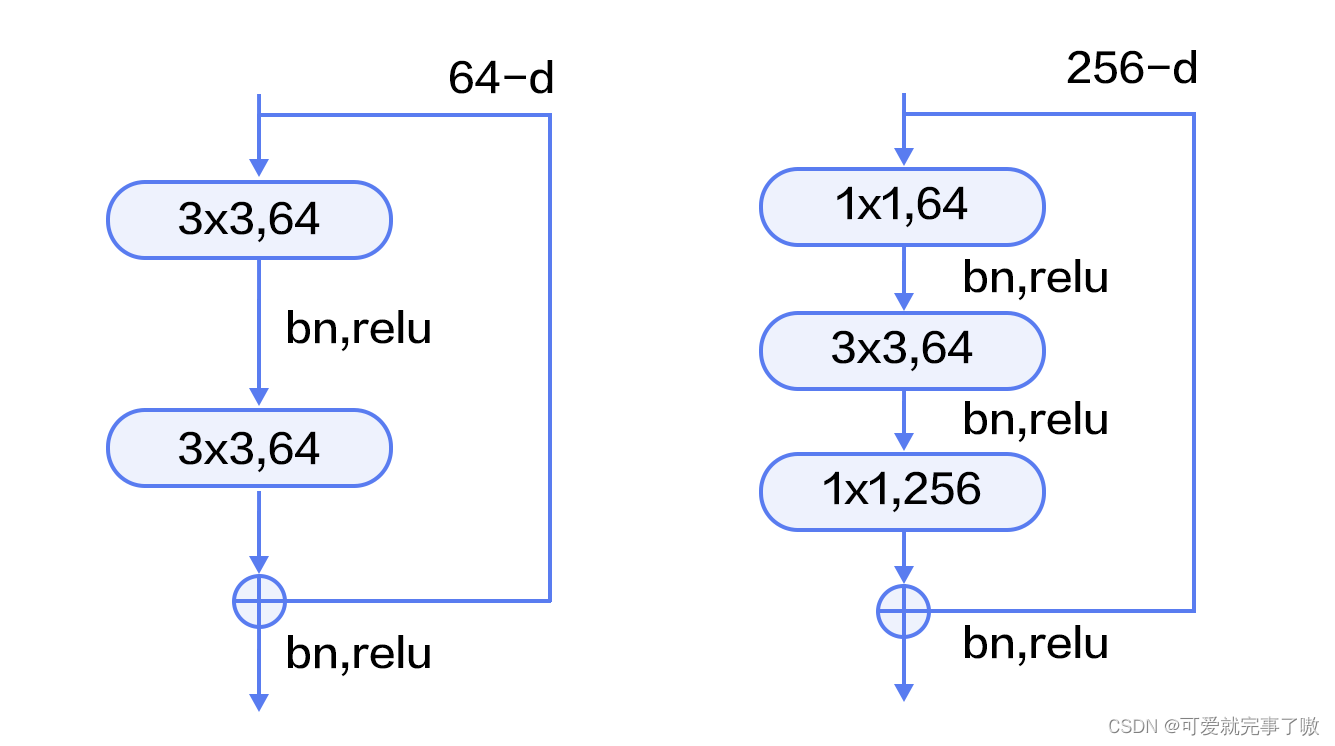
残差块通过跨层连接(shortcut connection)将输入信号直接传递到后续层,使得网络可以学习残差映射(residual mapping),即将输入信号与期望输出之间的差异。这种跨层连接允许梯度直接在残差路径上传播,有效地改善了梯度传播问题。
具体而言,残差块由两个主要部分组成:主路径(主要卷积路径)和残差连接(跨层连接)。在主路径中,输入通过一系列的卷积层、激活函数和归一化层进行处理。然后,将主路径的输出与输入进行逐元素相加,形成残差连接。最后,将残差连接传递给下一层,并经过激活函数进行处理。
ResNet的核心思想是通过残差块构建深层网络,使得网络可以学习残差,从而更容易地优化网络的性能。此外,ResNet还引入了不同深度的网络架构(如ResNet-50、ResNet-101和ResNet-152),通过不断增加残差块的数量,进一步提升了网络的性能。
(提醒一下自己 涉及到深度网络退化和残差学习部分可以看菠萝学姐的github)
1.2 ResNeXt
ResNeXt(Residual Next)是在ResNet的基础上进一步发展的一种神经网络结构,由Facebook AI Research团队在2017年提出。它旨在进一步提高网络的表达能力和性能。
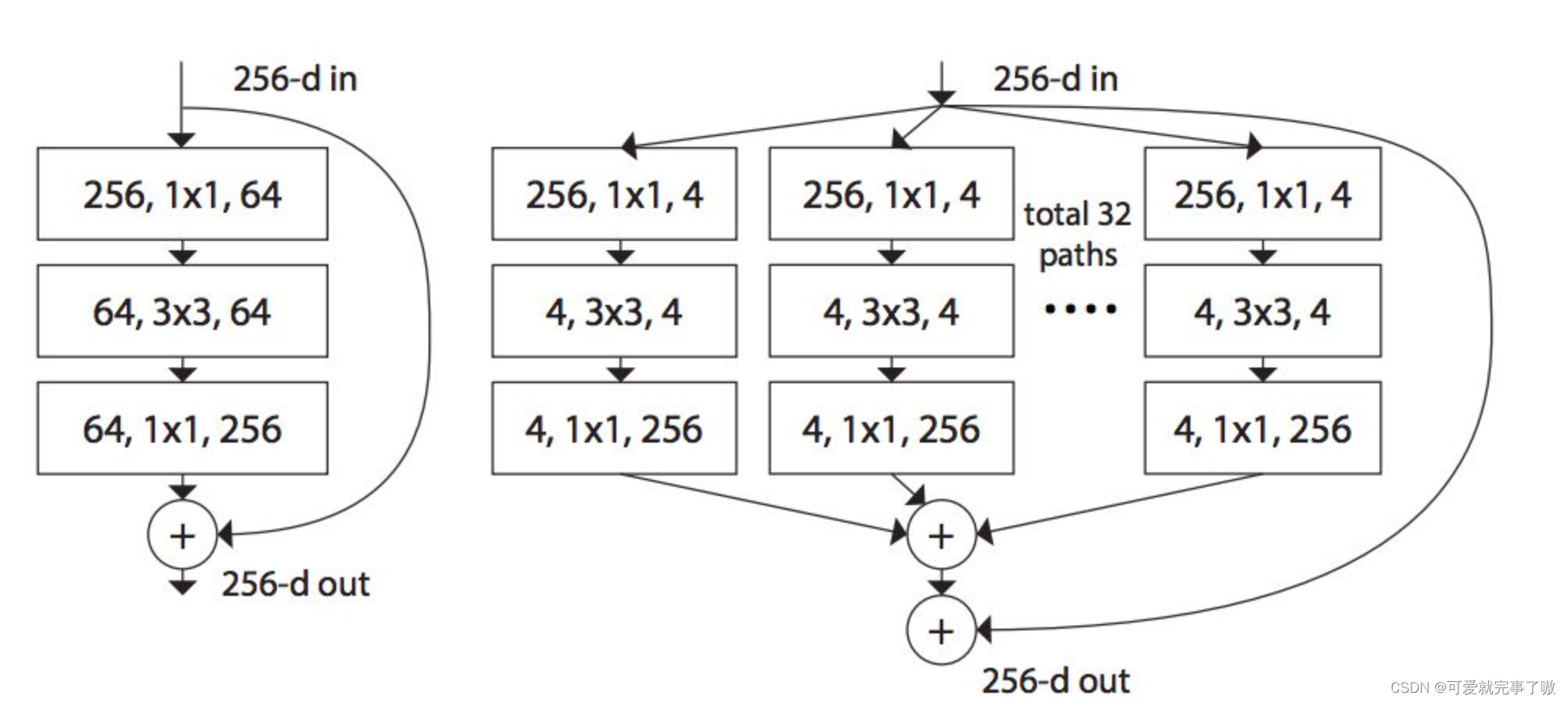
ResNeXt基于残差块的架构,但引入了一个新的概念,即“组卷积”(group convolution)。在传统的卷积操作中,输入特征图被分为若干个通道,每个通道应用单独的卷积核进行处理。而在组卷积中,输入特征图同样被分为若干个通道,但每个通道组内共享同一个卷积核。
具体而言,ResNeXt的主要创新在于将通道分组作为一种并行策略,增加了网络的宽度。通过增加通道分组的数量,可以增加网络中的非线性变换数量,提升网络的表达能力。同时,组卷积能够降低计算和参数量,减轻了网络的复杂性。
ResNeXt的结构由一系列相同的模块构成,每个模块包含若干个组卷积层,以及跨层连接和激活函数。模块之间的跨层连接保证了梯度的有效传播,使得网络能够训练非常深的层次。
左边是ResNet的基本结构,右边是ResNeXt的基本结构:
2 猫狗大战代码练习
2.1 LeNet
代码如下:
!wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
!unzip dogscats.zipimport torchimport torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
import torchvision as tv
from torch.autograd import Variable
from torch.utils.data import DataLoaderfrom tqdm import tqdm, tqdm_notebook# 设置全局参数
lr = 0.0001
batchsize = 64
epochs = 100
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')# 数据预处理,数据增广
transform = transforms.Compose([transforms.RandomResizedCrop(28),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
transform_test = transforms.Compose([transforms.RandomResizedCrop(28),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 读取数据
dataset_train = datasets.ImageFolder(r'/content/dogscats/train', transform)
#训练集标签对齐cat对应0,dog对应1
for i in tqdm(range(len(dataset_train))):str_tmp = dataset_train.imgs[i][0]# print(str_tmp[24:27]+'\n')if str_tmp[24:27]=='dog':dataset_train.imgs[i]=(str_tmp,1)else:dataset_train.imgs[i]=(str_tmp,0)
dataset_test = datasets.ImageFolder('/content/dogscats/valid', transform_test)
# 对应文件夹的label
#训练集标签对齐cat对应0,dog对应1
for i in tqdm(range(len(dataset_test))):str_tmp = dataset_test.imgs[i][0]# print(str_tmp[24:27]+'\n')if str_tmp[24:27]=='dog':dataset_test.imgs[i]=(str_tmp,1)else:dataset_test.imgs[i]=(str_tmp,0)# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=batchsize, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=batchsize, shuffle=False)class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Sequential( #input_size=(1*28*28)nn.Conv2d(3, 6, 5, 1, 2), #padding=2保证输入输出尺寸相同nn.BatchNorm2d(6),nn.ReLU(), #input_size=(6*28*28)nn.MaxPool2d(kernel_size=2, stride=2),#output_size=(6*14*14))self.conv2 = nn.Sequential(nn.Conv2d(6, 16, 5),nn.BatchNorm2d(16),nn.ReLU(), #input_size=(16*10*10)nn.MaxPool2d(2, 2) #output_size=(16*5*5))self.fc1 = nn.Sequential(nn.Linear(400, 120),nn.ReLU())self.fc2 = nn.Sequential(nn.Linear(120, 84),nn.ReLU())self.fc3 = nn.Linear(84, 2)# 定义前向传播过程,输入为xdef forward(self, x):x = self.conv1(x)x = self.conv2(x)# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维x = x.view(x.size()[0], -1)x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return xmodel=LeNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr)def train(model, device, train_loader, optimizer, epoch):best_loss = 100model.train()sum_loss = 0total_num = len(train_loader.dataset)# print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = Variable(data).to(device), Variable(target).to(device)output = model(data)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()print_loss = loss.data.item()sum_loss += print_lossave_loss = sum_loss / len(train_loader)print('epoch:{}, loss:{}'.format(epoch, ave_loss))if ave_loss < best_loss:best_loss = ave_loss# print('Find better model in Epoch {0}, saving model.'.format(epoch))torch.save(model, '\model.pkl')#将最优模型保存def val(model, device, test_loader):model.eval()with torch.no_grad():correct = 0total = 0for images,labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_,predicted = torch.max(outputs.data,1)total+=labels.size(0) #数据总数correct +=(predicted == labels).sum().item() #总的准确个数print('Acc:{}%'.format(100*correct/total))for epoch in tqdm(range(1, epochs + 1)):train(model, device, train_loader, optimizer, epoch)val(model, device, test_loader)
torch.save(model, 'model.pth')结果如下:

2.2 ResNet
代码如下:
!wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
!unzip dogscats.zipimport torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models
from torch.autograd import Variable# 设置超参数
BATCH_SIZE = 64
EPOCHS = 100
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 数据预处理
transforms = transforms.Compose([transforms.RandomResizedCrop(224), # 图片将被整理成 224 × 224 × 3 的大小transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 读取数据
dataset_train = datasets.ImageFolder('/content/dogscats/train', transforms)
dataset_test = datasets.ImageFolder('/content/dogscats/valid', transforms)# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
modellr = 0.0001# 实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
model = torchvision.models.resnet18(weights=None)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
model.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model.parameters(), lr=modellr)# 定义训练过程
def train(model, device, train_loader, optimizer, epoch):best_loss = 100model.train()sum_loss = 0total_num = len(train_loader.dataset)# print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = Variable(data).to(device), Variable(target).to(device)output = model(data)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()print_loss = loss.data.item()sum_loss += print_lossave_loss = sum_loss / len(train_loader)print('epoch: {}, loss: {}'.format(epoch, ave_loss))if ave_loss < best_loss:best_loss = ave_losstorch.save(model, '\model.pkl')#将最优模型保存def val(model, device, test_loader):model.eval()test_loss = 0correct = 0total_num = len(test_loader.dataset)# print(total_num, len(test_loader))with torch.no_grad():for data, target in test_loader:data, target = Variable(data).to(device), Variable(target).to(device)output = model(data)loss = criterion(output, target)_, pred = torch.max(output.data, 1)correct += torch.sum(pred == target)print_loss = loss.data.item()test_loss += print_losscorrect = correct.data.item()acc = correct / total_numavgloss = test_loss / len(test_loader)print('Val set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(avgloss, correct, len(test_loader.dataset), 100 * acc))# 训练
for epoch in range(1, EPOCHS + 1):train(model, DEVICE, train_loader, optimizer, epoch)val(model, DEVICE, test_loader)
torch.save(model, 'model.pth')结果如下:

(训练太慢所以偷了一张学姐的图QAQ)
3 问题理解
1、Residual learning 的基本原理?
Residual Learning(残差学习)是一种深度神经网络的学习方法,其基本原理是通过添加残差连接(residual connection)来改进传统的深度神经网络结构。传统的深度神经网络通常采用层次结构,即每一层接收前一层的输出,并将其作为输入传递给下一层。但是,这种结构在深度网络中容易产生梯度消失或梯度爆炸的问题,从而导致难以优化网络。
残差学习的基本思想是避免在深度网络中丢失信息的积累,通过添加残差连接,将输入信息直接传递到网络的输出层。这样,网络不仅学习到特征表示,还学习到输入信息的残差表示。
具体来说,残差连接将前向传播中的输入加到后续层的特征表示中,形式化表示为:
其中xI和xI+1分别表示的是第I个残差单元的输入和输出,注意每个残差单元一般包含多层结构。F是残差函数,表示学习到的残差。残差连接的形式可以是直接连接、跳跃连接、卷积层等。
2、Batch Normailization 的原理,思考 BN、LN、IN 的主要区别。
Batch Normalization(批标准化)是一种深度神经网络的正则化技术,它通过对每一批数据中的每个神经元的输入进行标准化,来调整神经网络的权重和偏置,以加速训练并提高泛化能力。
具体来说,Batch Normalization是对每一批数据中的每个神经元的输入进行标准化,将其转换为零均值和单位方差的形式。这个过程通过计算每个神经元的均值和方差,使用一个缩放因子和一个平移因子对输入进行转换。
Batch Normalization的作用是使网络更加稳定,可以减少梯度消失的问题,并提高模型的训练速度和泛化能力。它还可以减少模型对初始权重的敏感性,使得随机初始化后的权重能够更快地达到一个好的点,从而提高训练的效率。
Batch Normalization与Layer Normalization(层标准化)和Instance Normalization(实例标准化)的主要区别在于它们的计算方式和应用场景。Batch Normalization是针对每一批数据中的每个神经元进行标准化,需要存储大量的均值和方差参数,计算开销较大,不适合处理小批量数据。Layer Normalization是针对每一层神经元进行标准化,不需要存储大量参数,计算开销较小,适合处理小批量数据。Instance Normalization是针对每个输入样本进行标准化,不需要存储任何参数,计算开销最小,适合处理风格转换等任务。

3、为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
分组卷积可以提升准确率的原因是因为它能够减少模型的参数数量,从而提高模型的泛化能力。这是因为分组卷积可以将多个卷积层合并成一组卷积层,从而减少模型的参数量和计算量,同时保持模型的深度和宽度不变。
分组卷积可以减少模型的参数量和计算量,但是它并不是将所有的卷积层都合并成一组卷积层。相反,它只是将多个卷积层合并成一组卷积层,从而减少参数量和计算量。这样,模型仍然具有足够的卷积层来提取特征和传递信息。分组数需要合适,因为组间信息不能互通,无法交流学习。如果特征图的像素具有局部相关性,分组卷积学习可能无法利用局部信息进行学习。
这篇关于2023暑期培训【week 3】——ResNet+ResNeXt的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!