本文主要是介绍Sharding-Sphere的新一代Zookeeper注册中心实现剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文章转载自公众号:LetITGolang,欢迎关注!

李东博
厚泽贷系统架构师
二次元资深宅
原本是做.net的,跟着公司转型误打误撞开始做互联网,做着JAVA架构的工作,干着运维的活。对逻辑和技术感兴趣,希望能在这条路上越走越远。对未知的技术方向有很强的好奇心,包括开源框架的实现,以公司架构选型为契机接触了sharding sphere社区,如果能在对社区参与中不断提升自己也是很好的。
最近的业余时间多用于做这件事:
https://github.com/sharding-sphere/sharding-sphere/issues/717
由于是以完成现有功能为目标的,同时业余时间也不太充足,所以其中有些用不到地方处理的有些粗糙,另外还有原本打算用上,但最后没用上的,还有干脆就没做的部分,比如zk的一些一步回调执行的接口。我打算在这里把开发的过程,思路介绍一下,大家如果有兴趣,大家一起来把它做好。
组成结构
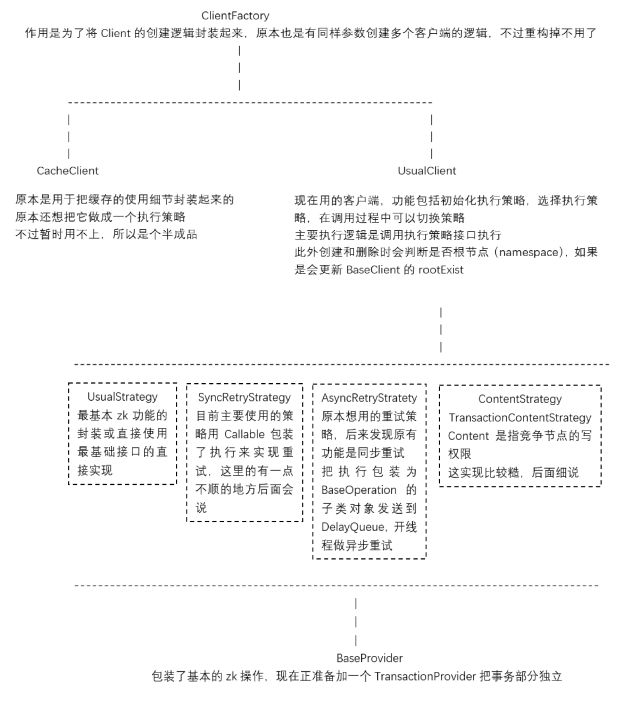
包结构

开发细节
Holder
UsualClient的基类BaseClient中有一个比较重要的类型Holder,因为没有顺眼的地方现在放在base包里。
最开始是没有这个类型的,zk的连接由BaseClient维护,但是在做重试功能的时候觉得怎么实现怎么别扭,因为重试功能按说是在Client内部实现,但是如果连接由Client维护,那重试策略势必要操作Client,这引用关系就相当凌乱了。而且由于先做的异步重试(其实同步重试一样),在重试过程中会涉及到连接和监听,如果传递Client,重试的Operation立场就会十分尴尬。
于是,根据书上有别扭就必然是因为有隐含的概念没有抽取出来的理论,寻找一个合适解耦的中间层抽取出来,那就比较明显了。把zk连接的维护独立出来,Client中只负责对节点的操作,由Holder来维护节点连接。同时在Client中创建Provider实例的时候可以把Holder实例传递给Provider,这样重试策略Provider就完全hold得住了。
Watcher
Holder里还有一个比较重要的部分是Watcher。一般情况下zk原生的Watcher功能只能使用一次,不过有一个地方除外,就是new的时候通过zk构造传进去的那个Watcher,由于是用于监听连接状态的,所以一直存在。于是我就通过Client提供一个registerWatch方法,把注册的监听放到一个Map里,有新的event的时候会遍历Map执行监听,此处有一个需要完善的地方,就是遍历Map时候的判断,现在只是简单的判断了路径为null或者匹配,并没有根据对应的事件类型过滤监听器,这个后续一定会有过滤的需要。这里看代码会发现还有个全局监听,主要是在测试的时候用的,什么事件都会走一遍。
Context
另外Client里会看到有Context的使用,但是其实这玩意是做重试功能时候,怎么试怎么不顺眼,就拿来传参数用了,其实抽出Holder以后我本来是有想法把它去掉的,不过看着也不太讨厌就留下了,如果能优雅的去掉,我也是欢迎的。
BaseClient
BaseClient主要功能有start、close、注册、认证和创建删除根节点。start这有一个blockUntilConnected方法,主要功能是如果在一定时间内启动不成功就返回启动失败。这个方法是在curator同名方法上稍微简化了一下,我比较不喜欢这种实现方式,holder里实现的start是用CountDownLatch阻塞的,CountDownLatch的await本身就有时间参数的重载,我现在在准备用await的重载方法替代blockUntilConnected,功能是没问题了,只是两个单元测试出现了互相影响的现象,还没调好。创建和删除根节点是为了实现namespace的功能的,使用namespace做根节点,不同的namespace下的节点就不会互相影响了。
同步重试策略
现在注册中心的Client使用的执行策略是同步重试SyncRetryStrategy,是用Callable实现的。Callable会从section包移到retry包里去的。主要逻辑就是根据延迟策略创建延迟策略的执行者,每次执行失败先判断失败的异常是否是需要重新连接zk server的,如果是resetConnection后延迟重试,否则直接延迟重试期待延迟过程中zk自动重连,之后由执行者判断是否还有下一次执行。这里有一个暂时没有场景所以先没处理的地方,就是只支持延迟策略,需要抽象一个策略基类,并且支持更多的重试方式。
异步重试策略
异步重试策略AsyncRetryStrategy是由AsyncRetryCenter执行的,在该策略的api执行时,如果捕捉到需要重试的异常,就创建当前操作的对象加入到延迟队列中。操作类的基类BaseOperation派生自java.util.concurrent.Delayd,并且与上面的同步重试一样都是使用延迟策略的执行者来判断下一次执行的。DelayQueue的消费是在RetryThread中。
先跑个题,这里可以看到有一些常数,其实是应该抽出来了,utility包里还有一些常量,虽然目前没什么用,不过其实是应该做成配置文件的。
接着说消费,消费就是一个for (;;)不停的take,take出来提交给线程池执行,这里使用线程池是防备会在一个时间节点有很多个操作到期,我测试zk 3.3.x版本时发现连接失败是比较容易出现的。
竞争策略
然后说竞争策略ContentionStrategy和TransactionContentionStrategy,竞争的逻辑在抽象类LeaderElection中,就是竞争者发起创建一个临时节点的请求,如果报NodeExistsException就注册一个该临时节点删除的事件监听,一旦监听触发就再次发起创建请求直到成功。这里有两个todo,一是创建节点的时候并没有使用节点序列号,如果需要选举功能,这一点是需要的;另外一个是目前只对根节点竞争,并不是对指定节点,这也需要补完。
BaseProvider
BaseProvider里不止有草图中说的拆分事务专用Provider,还有一个比较大的事没做,就是zk的回调类api,我是准备增加一个ICallbackProvider的接口,如:

将zk事务和非事务分成两个是因为没事务的部分是可以支持全版本的zk,我排除掉事务测试过3.3.0开始的所有版本都可以支持。但是事务是3.4.0才有的功能。ZKTransaction也是为了排除事务方便做的包装。
缓存
CacheStrategy是因为最开始使用的是定时启动线程全量的缓存数据更新,但是后来感觉直接根据订阅的事件更新更好,于是就两种都留下来了。PathStatus是用来在更新的时候判断是否有正在执行的其他更新用的。
缓存的主要功能是由PathTree和PathNode实现的。PathTree里有一个根节点,节点是PathNode类型,用了Map<String, PathNode>保存子节点,与zk的逻辑结构对应(我有时候在想这里是不是应该直接抄zk,回头了解一下),其他就是实现了CRUD。这里要说的是获取节点的get是用了个Iterator对深度做迭代了,这里其实用sharding语法解析的那个token感觉更好,其实最开始是类似思路做的,但是写的不顺眼就改成这样了,之后是想参考语法解析的部分改了这个get的。里面还有个todo,就是那里代码不顺眼。定时全量更新缓存是调用refreshPeriodic就可以了。订阅更新的话代码是watch方法,这个watch方法的调用我也感觉有些别扭,一定得先调用load之后跟着调用watch,可能没描述清楚,但是借助IDE的查找所有引用应该能明白我的意思。
版本号
最后还有一个非常大,但平时没怎么用过的功能,就是版本号,zk的api是有版本号差异的,虽然目前用的代码里并没有用上这个特点,但是不做总是不完整的,而且未来也未必用不上,版本号的维护在大量高频的对zk的写时是很必要的,这一点后面是要重点做的。
除了以上列出的这些,应该还是有其他不完善的地方,希望大家也能和我一起做好它。当然,也不止是这一部分,大家贡献自己的一点力量,sharding-sphere发展的更好,同时对自己的提升也是很有帮助的。
Sharding-Sphere
Sharding-Sphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。他们均提供标准化的数据分片、读写分离、柔性事务和数据治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
亦步亦趋,开源不易,您对我们最大支持,就是在github上留下一个star。
项目地址:
https://github.com/sharding-sphere/sharding-sphere/
https://gitee.com/sharding-sphere/sharding-sphere/
更多信息请浏览官网:
http://shardingsphere.io/
或加入Sharding-Sphere官方讨论群
感谢您的支持与关注
我们将不忘初心,不负众望!
这篇关于Sharding-Sphere的新一代Zookeeper注册中心实现剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





