本文主要是介绍yolov7训练数据集详细流程bike-car-person,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、准备深度学习环境
下载yolov7代码
下载完成解压放在自己的主目录
命名yolov7-4
二、 准备自己的数据集
1.进入主目录
2.进入data目录下把你的xml文件夹命名为Annotations,把你的存放图片文件夹命名为images
3.分别新建ImageSets、imagtest(里面存放测试图片)、labels(里面存放转换之后的yolo格式文件)
三、 1.2.在data目录下新建split_train_val.py文件
里面内容如下
# coding:utf-8import os
import random
import argparseparser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):os.makedirs(txtsavepath)num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')for i in list_index:name = total_xml[i][:-4] + '\n'if i in trainval:file_trainval.write(name)if i in train:file_train.write(name)else:file_val.write(name)else:file_test.write(name)file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行之后会在ImageSets/Main下生成四个.txt文件
2.在data目录下新建voc_label.py文件,里面存放代码,里面classes需要改成自己的类别
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwdsets = ['train', 'val', 'test']
classes = ['bike','carsgraz','person'] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('./Annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open('./labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists('./labels/'):os.makedirs('./labels/')image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()list_file = open('./%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + '/images/%s.png\n' % (image_id)) # 注意你的图片格式,如果是.jpg记得修改convert_annotation(image_id)list_file.close()
3.拷贝一份coco.yaml文件里面改成自己的类别和data目录下三个txt文件路径
代码如下
# COCO 2017 dataset http://cocodataset.org# download command/URL (optional)
# download: bash ./scripts/get_coco.sh# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /home/sxj/yolov7-4/data/train.txt # 118287 images
val: /home/sxj/yolov7-4/data/val.txt # 5000 images
test: /home/sxj/yolov7-4/data/test.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794# number of classes
nc: 3# class names
names: ['bike','carsgraz','person']4.修改cfg目录下/home/sxj/yolov7-4/cfg/deploy/yolov7.yaml,yolov7.yaml文件里面改成自己类别数
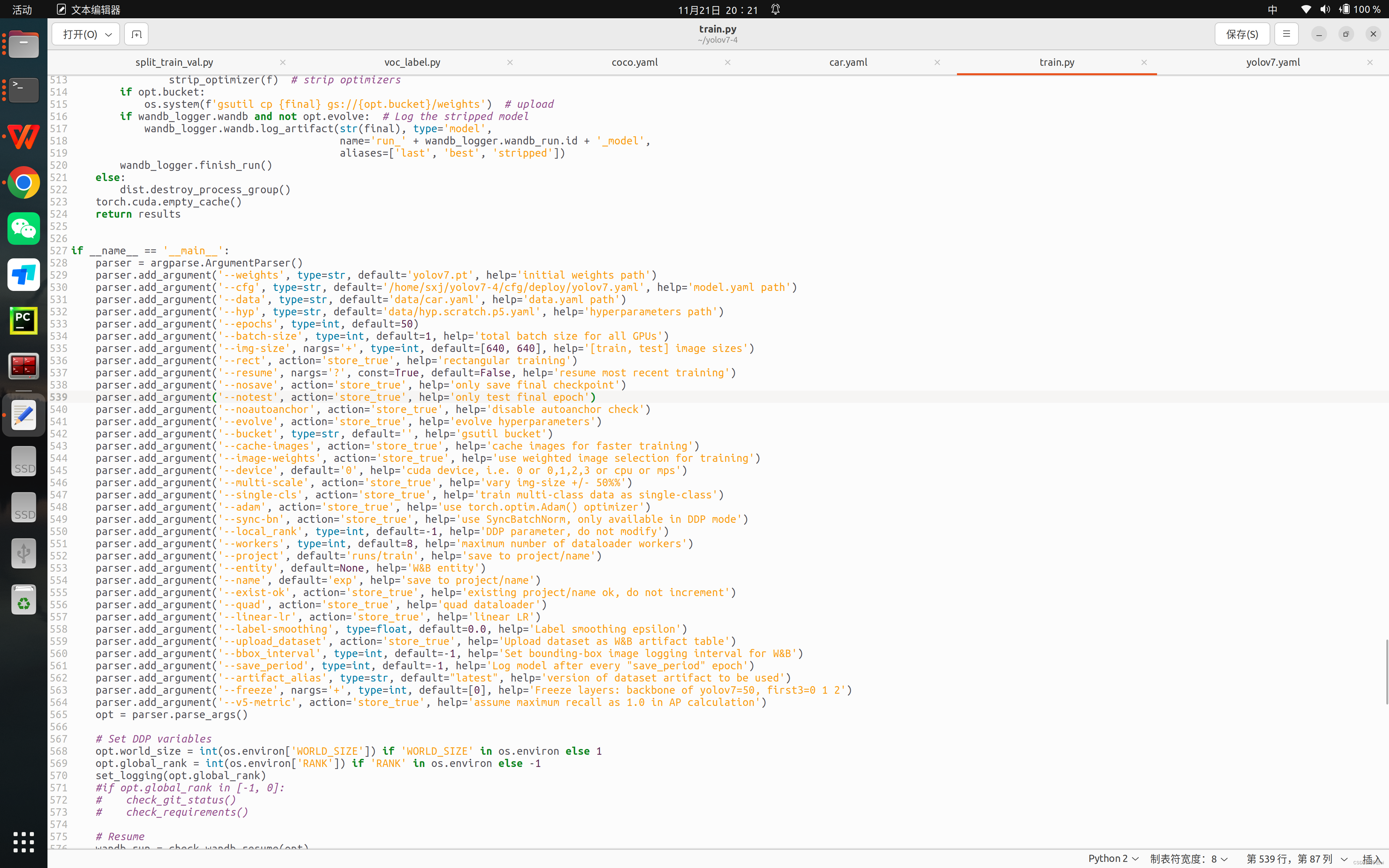
四、返回yolov7主目录修改train.py文件
其中 --weights', type=str, default='yolov7.pt', help='initial weights path'改成yolov7.pt文件路径
'--cfg', type=str, default='/home/sxj/yolov7-4/cfg/deploy/yolov7.yaml', help='model.yaml path')改成yolov7.yaml路径
'--data', type=str, default='data/car.yaml', help='data.yaml path'把data目录下的coco.yaml文件改成自己的路径
里面'--epochs', type=int, default=50
'--batch-size', type=int, default=1, help='total batch size for all GPUs'
'--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu or mps'
参数根据需要调整
五、完成之后运行python train.py
出现如下报错及解决方法:YOLO7报错:indices should be either on cpu or on the same device as the indexed tensor (cpu)
YOLO7报错:indices should be either on cpu or on the same device as the indexed tensor (cpu)
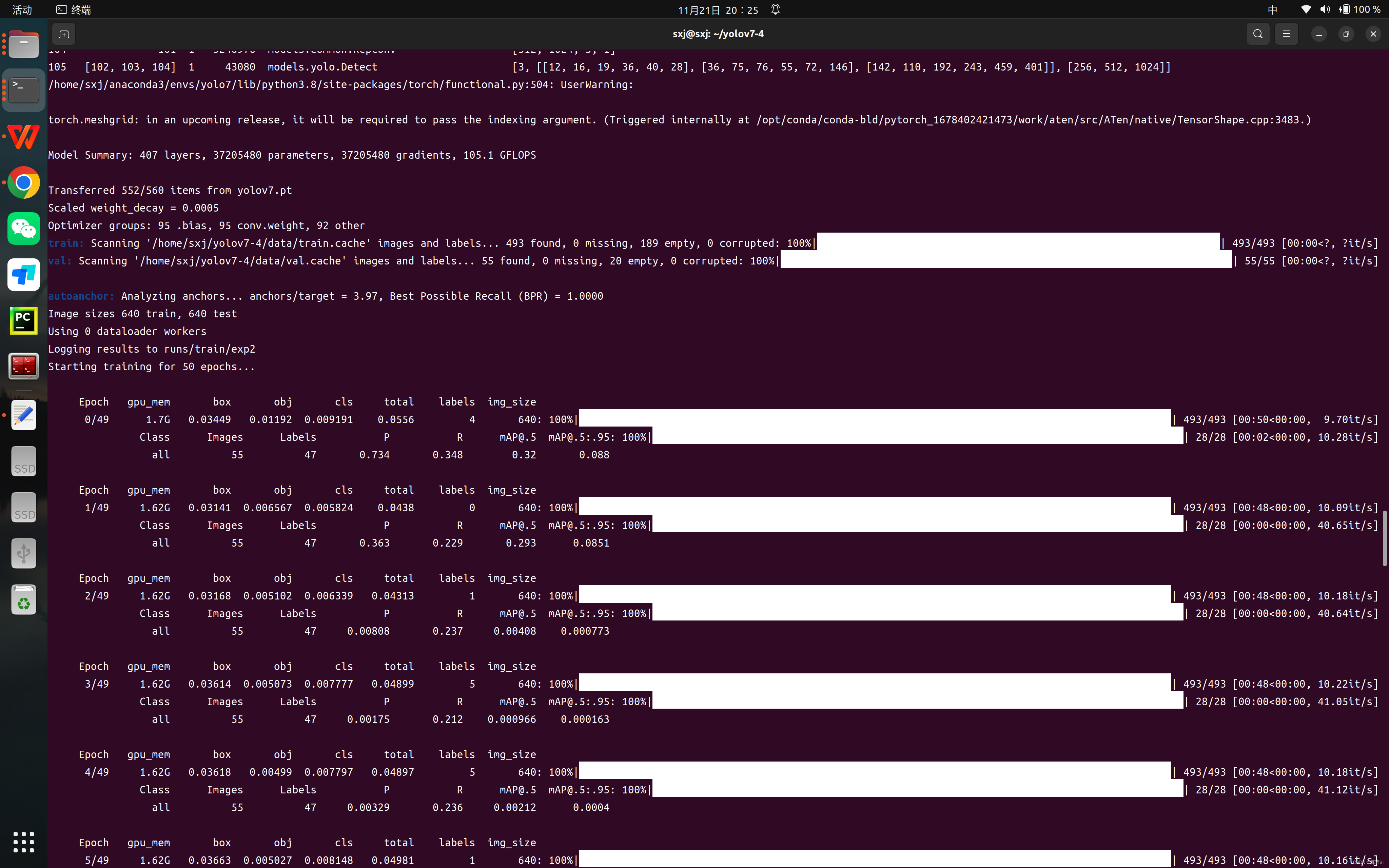
运行之后在runs里面找到best.pt权重文件
拷贝一份放在主目录下,打开detect.py改成自己best.pt权重文件和测试图片路径
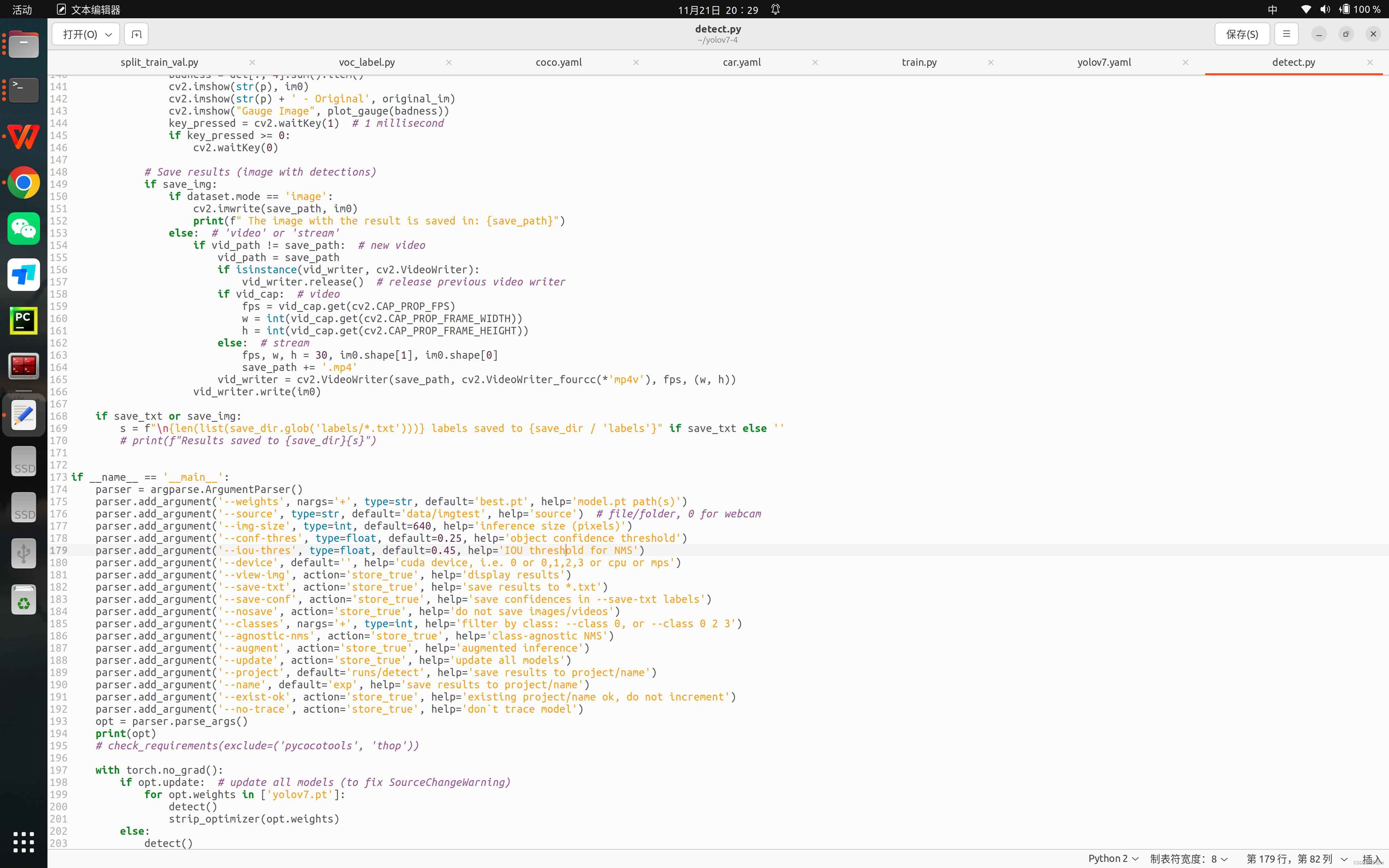
在运行
python detect.py在 runs/detect/exp下可查看自己模型文件测试效果即可
到此全部完成
这篇关于yolov7训练数据集详细流程bike-car-person的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






