本文主要是介绍机器(深度)学习算法原理与案例实现暨Python 大数据综合应用研修班,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、课程简介
课程强调动手操作;内容以代码落地为主,以理论讲解为根,以公式推导为辅。共4天8节,讲解机器学习和深度学习的模型理论和代码实践,梳理机器学习、深度学习、计算机视觉的技术框架,从根本上解决如何使用模型、优化模型的问题;每次课中,首先阐述算法理论和少量公式推导,然后使用真实数据做数据挖掘、机器学习、深度学习的数据分析、特征选择、调参和结果比较。
二、课程目标
通过课程学习,可以理解机器学习的思维方式和关键技术;了解深度学习和机器学习在当前工业界的落地应用;能够根据数据分布选择合适的算法模型并书写代码,初步胜任使用Python进行数据挖掘、机器学习、深度学习等工作。
三、讲师简介
邹博,中国科学院副研究员,天津大学软件学院创业导师,成立中国科学院邹博人工智能研究中心(杭州站),在翔创、天识、睿客邦等公司担任技术顾问,研究方向机器学习、深度学习、计算几何,应用于大型气象设备图像与文本挖掘、股票交易与预测、量子化学医药路径寻优、传统农资产品价格预测和决策等领域。
尹老师,数据科学家,浙江大学物理学博士,浙江某高校数据科学专业负责人,兼任某网络科技上市公司大数据总监,受聘担任多家大数据教学机构主讲教师,开发多套python高级编程、机器学习、网络爬虫与文本挖掘系列课程,10+年python软件开发数据产品经验,熟悉R \Javascript等多种编程语言,具有丰富的python统计建模、数据挖掘、大数据技术教学经验,先后为中国交通银行,平安保险公司等数十家知名机构主讲python课程。

2017年成立中科院邹博人工智能研究中心(杭州站)

2017年9月22日-24日 京东方集团机器学习与计算机视觉企业内训

2017年9月11日-14日 中国电信2017年数据分析与挖掘人才技能评价训练营

2017年8月3日-7日 北京理工大学机器学习和深度学习高校师资培训

四、课程模块
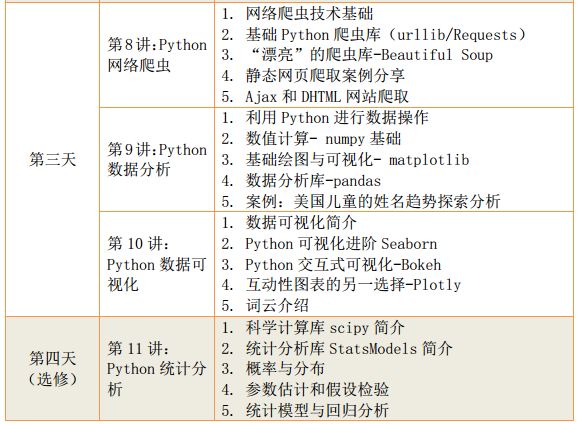
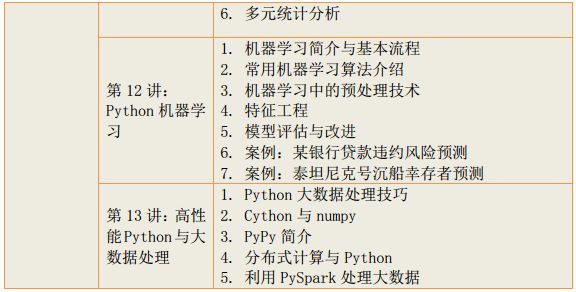
1、机器学习、深度学习算法原理及案例实现


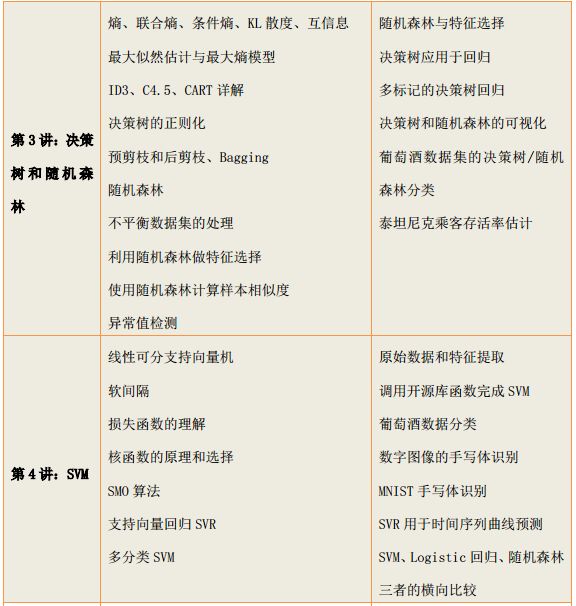
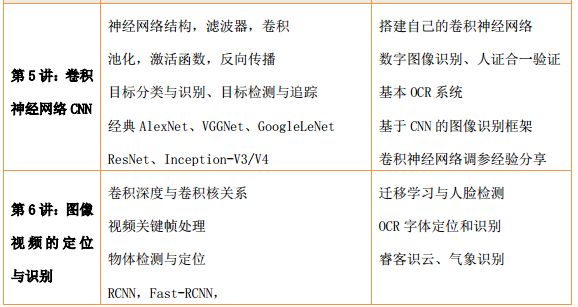

2、python高级编程与大数据综合应用
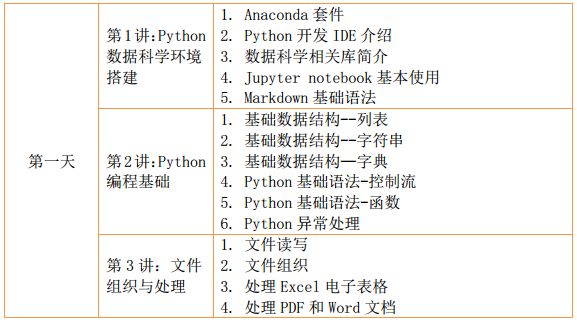
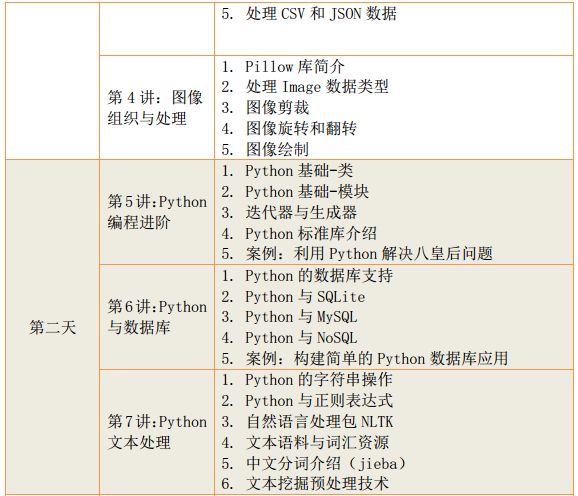
五、颁发证书
经考核合格可获得国家工信部全国通信和信息技术创新人才培养工程《大数据挖掘与分析应用高级工程师》职业技术水平证书。该证表明持有者已通过相关考核,具备相应的专业知识和专业技能,并作为聘用、任职、定级和晋升的重要参考依据,全国通用。
六、时间与地点
模块一: 2018年4月18日~22日 杭 州
模块二: 2018年4月11日~15日 上 海
七、费用标准
参会费4900元/人(含专家授课费、教材考试费、证书申报、
场地等),食宿统一安排,费用自理。
八、联系方式
联系电话: 13021034702
微 信: 13021034702
联 系 人: 李老师
邮 箱: 136312782@qq.com
附件:报名回执表
机器学习、深度学习暨python高级编程高级研修班报名回执表
(经研究我单位选派以下同志参加此次学习)
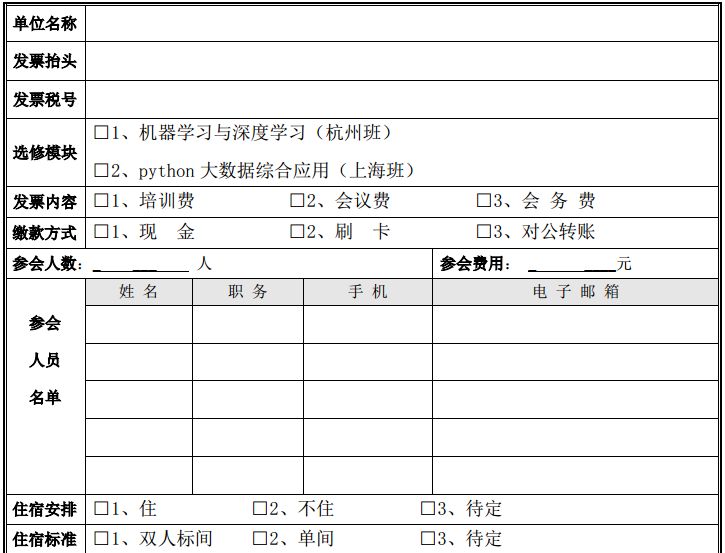

注:请确定参加人员从速报名,培训报到前7日我们将以电子邮件的方式给您发送《报到通知》及学习软件、课件,告知具体培训地点、乘车路线等事宜。
这篇关于机器(深度)学习算法原理与案例实现暨Python 大数据综合应用研修班的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





