·习题
#
2.12 ③
设A=(a1,...,an)和B=(b1,...,bn)均为顺序表,A'和B'分别为A和B中除去最大共同前缀后的子表(例如,A=(x,y,y,z,x,z),B=(x,y,y,z,y,x,x,z),
则两者中最大的共同前缀为(x,y,y,z),在两表中除去最大共同前缀后的子表分别为A'=(x,z)和B'=(y,x,x,z))。
若A'=B'=空表,则A=B;若A'=空表,而B'≠空表,或者两者均不为空表,且A'的首元小于B'的首元,则A<B;否则A>B。
试写一个比较A,B大小的算法(请注意:在算法中,不要破坏原表A和B,并且,也不一定先求得A'和B'才进行比较)。
这道题目的题干中,有一个很明确的算法:
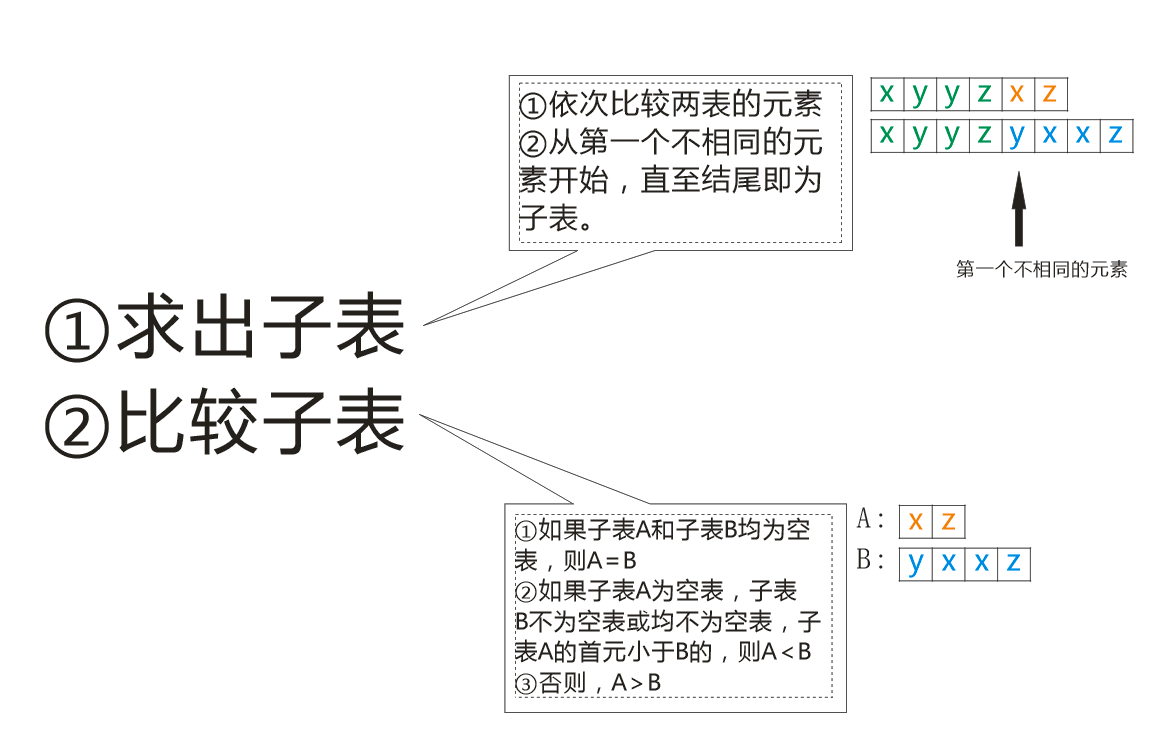
依照这个算法可以写两个函数来完成这两个主要的步骤:
getSubL()——求出子表
cmpSubL()——比较子表
点击查看线性表的声明
1 void getSubL(SqList *sqlA, SqList *sqlB, SqList *sublA, SqList *sublB){ 2 int lenA,lenB,minLen; 3 lenA = sql_getLen(sqlA); 4 lenB = sql_getLen(sqlB); 5 minLen = (lenA>lenB)?lenB:lenA; //得到较小的线性表的长度:minLen 6 7 int i = 0; 8 while( i < minLen && sql_get(sqlA,i)==sql_get(sqlB,i) ){ //寻找第一个不相同元素的位置:i 9 i++; 10 } 11 12 int j = 0, temp1 = i; 13 while( temp1 < lenA ){ //从第一个不相同的元素开始构建子表:sublA 14 sql_insert(sublA,j,sql_get(sqlA,temp1)); 15 16 temp1++; 17 j++; 18 } 19 20 int k = 0, temp2 = i; 21 while( temp2 < lenB ){ //从第一个不相同的元素开始构建子表:sublB 22 sql_insert(sublB,k,sql_get(sqlB,temp2)); 23 24 temp2++; 25 k++; 26 } 27 }
1 int cmpSubL(SqList *sublA, SqList *sublB){ 2 int result; 3 if( sql_isEmpty(sublA) && sql_isEmpty(sublB) ){ //两子表均为空:A=B 4 result = 0; 5 }else if( (sql_isEmpty(sublA)&&!sql_isEmpty(sublB)) 6 || (!sql_isEmpty(sublA)&&!sql_isEmpty(sublB)&&sql_get(sublA,0)<sql_get(sublB,0)) ){ 7 //子表A为空表且子表B不为空表 或者 均不为空表且子表A的首元素小于子表B的首元素:A<B 8 9 result = -1; 10 }else{ //否则:A>B 11 result = 1; 12 } 13 14 return result; 15 }
嗯,这样确实可以思路清晰地解决问题。
可是总觉得哪里怪怪的...
这时我注意到题目最后的小括号里的内容:并且,也不一定先求得A'和B'才进行比较。
这句话的意思就是,求子表A和子表B是没有必要的?
求子表是为了比较两线性表不同部分的关系,这样的话...为什么不能在找到第一个不同元素位置的时候就作比较呢?
完全可以啊!
在getSubL()里,
int i = 0; while( i < minLen && sql_get(sqlA,i)==sql_get(sqlB,i) ){ //寻找第一个不相同元素的位置:ii++; }
当这个循环结束的时候,变量 i 就是第一个不同元素的位置。
反观上边的比较算法,我发现比较其实主要是基于子表长度或子表中第一个元素进行的。
那我们完全可以只用变量 i 来完成比较!
int result; if( i == sql_getLen(sqlA)&& i == sql_getLen(sqlB) ){ //i和表长相等就意味着子表长度为0,子表为空 result = 0; }else if( (i==sql_getLen(sqlA)&&i!=sql_getLen(sqlB)) //同样是用i和表长作比较来判空|| (i!=sql_getLen(sqlA)&&i!=sql_getLen(sqlB)&&sql_get(sqlA,i)<sql_get(sqlB,i)) ){ //子表首元素就是i位置的元素 result = -1; }else{result = 1; }
这样我们就省去了很多步骤(构建子表的循环),而且省去了很多额外空间(构建子表所需的空间),使得算法的时间复杂的和空间复杂度都大大减小。
而且,我们几乎丝毫没有改变逻辑的清晰性以及代码的可读性。所以,这是一个十分飘逸的改进过程!~
最终,将两线性表的比较整合成一个函数sqlist_Cmp():
1 int sqlist_Cmp(SqList *sql1, SqList *sql2){ 2 int i = 0; 3 while( sql_get(sql1,i) == sql_get(sql2,i) 4 && i < sql_getLen(sql1) 5 && i < sql_getLen(sql2) ){ 6 7 i++; 8 } 9 10 int result; 11 if( i == sql_getLen(sql1) 12 && i == sql_getLen(sql2) ){ 13 14 result = 0; 15 }else if( (i==sql_getLen(sql1)&&i!=sql_getLen(sql2)) 16 || (i!=sql_getLen(sql1)&&i!=sql_getLen(sql2)&&sql_get(sql1,i)<sql_get(sql2,i)) ){ 17 18 result = -1; 19 }else{ 20 result = 1; 21 } 22 23 return result; 24 }
哇,这时候的代码和最初的比起来可以说是漂亮的一匹了!
通过这个题我发现:
1. 书上的提示还是很重要的呀!
2. 很多时候,有些东西是逻辑上的,为了方便思考而准备的概念;到了真正实现的时候可以根据实际,进行优化。
//2017.11.14 10:04
·思路
#
关于链表带不带头结点的思考
点击查看链表的声明
从网上看到很多文章都说,链表之所以要带头结点就是因为如果不带头结点,那第一个节点就和之后的别的节点操作不一样,这样容易引发bug什么的。开始看到时不是很理解,现在懂了和大家分享一下。

假设我们现在在函数中,参考上图,先来看这样两个操作:插入到当前节点之前和删除当前节点。
这两个操作有一个共同点,那就是我们必须要改变前一个节点的指针域。
那如果这两个操作发生在第一个节点身上的话,那它所谓的“前一个节点的指针域”就是头指针。
这时,我们就已经触及到我们所说的那个“不一样的操作”了。因为在函数中,指向当前元素的指针虽都是临时变量,但是通过指针操作所得到的指针域就是确确实实的左值指针域变量了(即我们可以在函数里确确实实地改变函数外的变量本身,而不是改变它的副本了)。然而,因为头指针并不是真正的指针域,它不是链表节点的一部分,只是一个单纯的指针,所以我们无法通过一般的指针操作得到左值形式的它(得不到左值就不能对它的实体进行赋值,也就无法实际改变它的值)。故,我们用一般的传入“指向节点指针的参数”的方式无法对其完成赋值。
假设这是我们链表插入函数的声明
void insert(Node *listNode, int value)
一般情况下,这个listNode就是链表头指针的副本(因为我们一般通过insert(llist1,10)调用它),它指向的就是第一个节点。
故listNode->next操作后,如上文所说,它就是第一个节点的指针域的左值了。所以,这也就是说,我们对除第一个节点之外的节点的改变前一个节点指针域的操作都可以完成了,因为我们得到了所需指针域的左值(好长的一句话…)。

可是,我们却不能对第一个节点做“改变前一个节点指针域”操作(废话,它是第一个节点,哪有前一个节点啊…)这也就是说,我们无法用刚才的逻辑完成第一个结点的删除和在它之前插入元素(因为这两个操作都用到了前一个节点指针域的左值)。
这样我们就无法为链表写出一个通用的插入和删除函数了。然后我们有两种解决思路:
1. 改变逻辑,即改变做插入操作和删除操作的逻辑,不用“前一个节点指针域”了,换一种新方法。
2. 改变链表结构,即本题目讨论的重点:给没有头结点的链表加上头结点。
我们已经知道了结果,我们选择的是第2种解决思路。重点在于选择的原因,而这正是头结点存在的意义。
一般情况下,我们更倾向于觉得:为了给一个容器写操作函数而改变容器本身的结构是反常的。
可事实是,我们果真这么做了。为什么?因为前边那个结论成立是有个前提的:不改变结构而改变逻辑的成本低于或等于改变结构的成本。即是说,写一个不用给链表加头结点就能完成“第一个节点的删除和在它之前插入元素”操作的算法,是十分困难、麻烦并且不方便使用、难于维护的。
你可能很惊讶,为啥一个算法会有这么可怕的描述,不就是不加头结点吗,有啥难的。。。
你可以先不看下边我给出的代码自己先试着写一下。我反正觉得我写这样的代码,是愣头青的行为…
.
.
.
.
.
.
.
.
.
.
好,现在我们就假装我们选择了第1种解决思路,我们头铁,我们开始写算法:
嗯…先思考,不论是删除第一个节点还是在第一个节点前插入元素,我们始终逃不过一件事,那就是要打破头指针和第一个节点之间的连接。嗯,这不难,只要改了头指针的值就行了呗。emmmm…头指针的值,好吧它是个指针,不管他是个啥吧,我们要在函数里改变它的值,只能通过取它的地址把它的地址传进来,然后通过指针运算符改那块内存的值。所以,我们就需要把头指针的地址传进来,嗯,那传进来的就是一个指向链表节点类型指针的指针了。好吧,绕是绕点,我们不管,我们头铁!写!
1 void insert(Node **headpp, elem_type value){ //headpp是指向头指针的指针 2 Node **prevnextp = headpp; //prevnextp是指向前一个节点指针域的指针 3 Node *current = *prevnextp; //current是指向当前元素的指针 4 5 while( current != NULL 6 && current->value < value ){ //按值递增插入链表,循环找合适位置 7 8 prevnextp = &(current->next); 9 current = current->next; 10 } 11 12 Node *newNode = (Node*)malloc(sizeof(Node)); //创建要插入的新节点 13 if( newNode != NULL ){ //检查是否创建成功 14 newNode->value = value; 15 newNode->next = current; //连接新节点和当前节点 16 }else{ 17 //报错终止,具体细节略 18 } 19 20 *prevnextp = newNode; //连接前一个节点和新节点 21 }
嗯…好吧这就是代码。说实话…其实也还好。好吧,它还是困难、麻烦、不方便使用、难于维护的。
为什么呢?说实话,我现在并没有觉得它有多么麻烦。可是,我怎么能保证我在不那么清醒的时候能理解它呢?这并不只是一个玩笑,因为这个函数的第一个参数是个二级指针,而链表除了init()函数之外都是传的一级指针,所以很容易在使用的时候产生误解,这是它的“不方便使用”。而它的“困难”是在于它是基于二级指针进行值操作的,基于“指针层数越多越难理解”的共识,它比起一级指针操作更难于马上理解。正是由于它的“困难”,在以后维护的过程中则会“难于维护”。而它的“麻烦”在于,本来我们是可以基于一级指针、基于已经设计好的指针域进行链表的拆解和连接的(除第一个节点),而我们就为了第一个节点的方便造成了除第一个节点外所有节点的麻烦,这并不理智。
经验告诉我们:把复杂的事情变成简单的事情而解决之比直接解决复杂的事情更优。
所以,我们选择给链表加上一个头结点。对于其他的操作函数,只需要稍加调整就可以适应它,并且依旧不会改变原来的逻辑。并且我们只是加了1个头结点,所以并不会带来任何过分的浪费,却使我们的代码翻倍地易于理解,易于维护,何乐而不为?
有了头结点,我们的第一个节点便不再孤独,因为它也和大家一样了,它也有了前一个节点——头结点。
这样我们一开始的那个逻辑又行得通了,因为我们始终可以用listNode->next来取得我们需要的左值了。
这样我们便不需要再绞尽脑汁去考虑复杂的新解决办法了,简单的办法大家都容易想到,所以代码的可读性也就提高了。终成圆满!
附代码:
1 void insert(Node *headp, elem_type value){ //headp是头指针 2 Node *prev = headp; //prev是指向前一个节点的指针,初始指向头结点 3 Node *current = prev->next; //current是指向当前元素的指针 4 5 while( current != NULL 6 && current->value < value ){ //按值递增插入链表,循环找合适位置 7 8 prev = current; 9 current = current->next; 10 } 11 12 Node *newNode = (Node*)malloc(sizeof(Node)); //创建要插入的新节点 13 if( newNode != NULL ){ //检查是否创建成功 14 newNode->value = value; 15 newNode->next = current; //连接新节点和当前节点 16 }else{ 17 //报错终止,具体细节略 18 } 19 20 prev->next = newNode; //连接前一个节点和新节点 21 }
//2017.11.18 20:02








