本文主要是介绍数据结构中的堆和栈与内存分配中的堆区和栈区分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考链接:
https://www.cnblogs.com/jzssuanfa/p/7068147.html
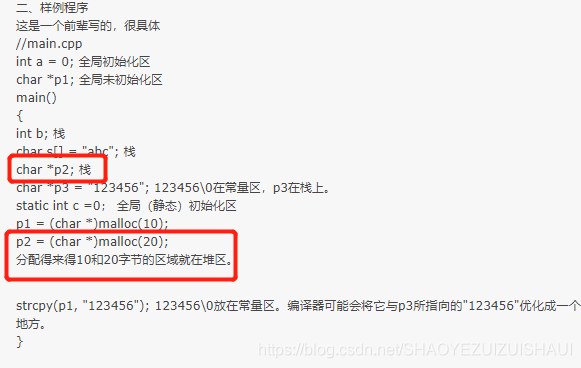
内存分配中的栈区和堆区:
栈区:
在Windows下,栈是向低地址扩展的数据结构。是一块连续的内存的区域
处于相对较高的地址以地址的增长方向为上的话,栈地址是向下增长的。栈中分配局部变量空间
由编译器自己主动分配释放 。存放函数的參数值,局部变量的值
堆区:
堆是向高地址扩展的数据结构,是不连续的内存区域。这是因为系统是用链表来存储的空暇内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址
一般由程序猿分配释放。 例如:new和malloc,若程序猿不释放,程序结束时可能由OS回收
动态数组的指针是在栈区,分配的空间在堆区
这篇关于数据结构中的堆和栈与内存分配中的堆区和栈区分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





