本文主要是介绍数据仓库 | 从买菜这件小事来聊聊数据仓库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
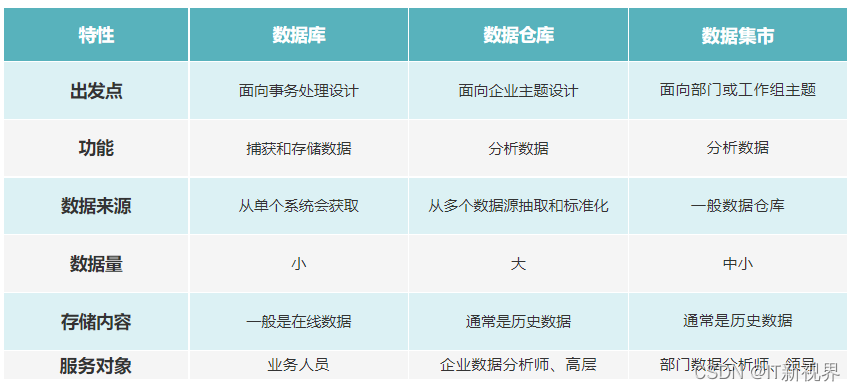
最近几个新入职的同学说被数据库,数据集市,数据仓库整的有点懵,不太清楚它们之间的关系和区别。周末小编在买菜的过程中灵光一闪,决定从买菜这件小事来聊聊数据仓库。
当我们想做饭时首先需要考虑的就是想做的菜需要买什么材料,比如小炒肉,我们需要青椒和猪肉。早期的时候,我们需要分别去蔬菜店买青椒,去肉铺买猪肉。这个过程我们需要花费很多的时间和精力,甚至有的时候跑了一大段路却发现店里没有我想买的东西,或者我买到了青椒,却发现肉铺没有肉卖了这种尴尬的情况。后来逐渐建设了农贸市场,由每个材料供货商供货,种类齐全,并按照一定的规则摆放整齐,我们想要买什么菜按照指示牌就可以快速地定位。
我们可以把数据库比作一个个小店铺或者供货商,他们的强项在于事务处理,比如从农民伯伯手上去收购蔬菜,从屠宰厂批发猪肉等,将这些原材料汇总起来,至于怎么摆放供客户挑选,通过各种市场分析去增长销量等不是他们擅长的。数据库主要就是面向事务设计的,与ERP,CRM,OA等各类业务系统集成并完成业务过程数据的组织管理,他们解决的是基本的业务流程管理,通过数据的录入,删除,修改,查询及用户在业务系统操作界面中做的增删改查操作,和业务系统底层的数据库例如MySQL,Oracle,SQL Server完成数据的交互,数据也沉淀在这些数据库中。
那聪明的同学已经知道数据仓库其实就像“农贸市场”,把各种供货商手上的货源收集起来,按照一定的规则摆放整齐供客户挑选,同时可以通过整个农贸市场的销售经营情况进行一些细致的分析,对整个市场有更好的了解,从而促销相应的采购,销售策略等等。数据仓库是构建面向分析的集成化数据环境,为企业提供决策支持,它出于分析性报告和决策支持的目的而创建。
那什么是数据集市呢?数据集市可以比喻成各种专区,卖蔬菜农产品的,卖水产海鲜的,卖肉禽的等等。数据集市其实就是一个面向小型的部门或工作组级别的小型数据仓库,只专注于某一个方面的主题分析。
图片来源:包图网
数据仓库本身并不生产数据,数据来源于外部,并且开放给外部应用,这也是为什么叫仓库,不叫工厂的原因。例如农贸市场并不种植蔬菜、养殖各种水产禽类,而是从各供货商获取材料。数据集市可以从自己的数据源获取数据,也可以从数据仓库中获取某一主题的数据。
那从供货商到农贸市场的中间过程,其实就是所谓的“ETL”过程。ETL就是extract,Transform和load,指的是清洗,转换和加载。我们都知道,供货商提供的货不是什么都要的,我们要筛选出有价值的,畅销的品种,有些坏的,不新鲜的菜在进农贸市场的过程中就需要去除掉。而不同的供货商提供的货可能也存在一些一样的种类,那么在搬运到农贸市场中就需要做一些归类合并,按照更好的一种陈列方式摆放整齐供客户挑选。这个从供货商搬运,清洗,转换,加载各种菜的过程就是ETL过程。
在这个过程中,还涉及到ETL的方式和频率。比如水产海鲜,很多都是速冻空运过来的,一些需求量比较小的比如澳龙可能几天才送一次,而一些蔬菜是人们日常需要的,大都是周边蔬菜大棚产的,就会由货车每天运输进农贸市场。
这些菜被运送到农贸市场后,会根据一定的规则进行摆放让客户挑选。我们可以根据不同的规则对这些菜进行管理,就像数据仓库的技术框架一样,我们可以选择一般的技术框架或者大数据技术框架,不同的选择最终决定了我们数据仓库的使用效果和投入成本。
因此,数据仓库的本质还是一个数据库,它将各个异构的数据源,数据库的数据统一管理起来,并且完成了相应数据的剔除,格式转换,最终按照一种合理的建模方式来完成源数据的组织形式的转变,以更好的支持前端的可视化分析。
关于数据库和数据集市,数据仓库的区别,我们简单做个总结一下:
那数据仓库有什么价值呢?咱们先来说一个啤酒和尿布的故事。某超市货架上将啤酒与尿布放在一起售卖,这看似不相关的两个东西,为什么会放在一起售卖呢?原来在早期的时候,该店面经理发现每周啤酒和尿布的销量都会有一次同比增长,但一直搞不清楚原因。后来商家通过对原始交易记录进行长期的详细分析后发现,很多年轻的父亲在下班后给孩子买完尿布后,大都会顺便买一点自己爱喝的啤酒。于是该商家将尿布与啤酒摆放在一起售卖,通过它们的潜在关联性,互相促进销售。“啤酒与尿布”的故事一度成为营销界的神话。
从上面可以看出,数据仓库除了将各数据源抽取集成到一起为数据管理和运用提供方便外,还可以按照不同的主题,将不同种类的数据进行归类组织,从多维度、多角度挖掘出一些有价值的东西,为了企业的分析和决策提供数据依据。而一般数据库主要是面向事务处理,对数据分析性能不佳。此外,通常一个公司的业务系统会有很多,不同的业务系统往往管理部门不同,地域不同,各个数据库系统之间是相互隔离的,无法从这些不同系统的数据之间挖掘出关联关系。因此基于这些特性,数据仓库可用于人工智能、机器学习、风险控制、无人驾驶,数据化运营、精准运营,广告精准投放等场景。
星环科技是国内领先的大数据基础软件公司,围绕数据的集成、存储、治理、建模、分析、挖掘和流通等数据全生命周期提供基础软件与服务,于2016年被国际知名分析机构 Gartner 选入数据仓库及数据管理分析魔力象限,位于远见者象限,在前瞻性维度上优于 Cloudera、Hortonworks 等美国主流大数据平台厂商,是Gartner 发布该魔力象限以来首个进入该魔力象限的中国公司。
Transwarp ArgoDB是星环科技面向数据分析型业务场景的分布式闪存数据库产品,主要用于构建离线数据仓库、实时数据仓库、数据集市等数据分析系统。2019年8月,ArgoDB成为全球第四个通过TPC-DS基准测试并经过TPC官方审计的数据库产品。
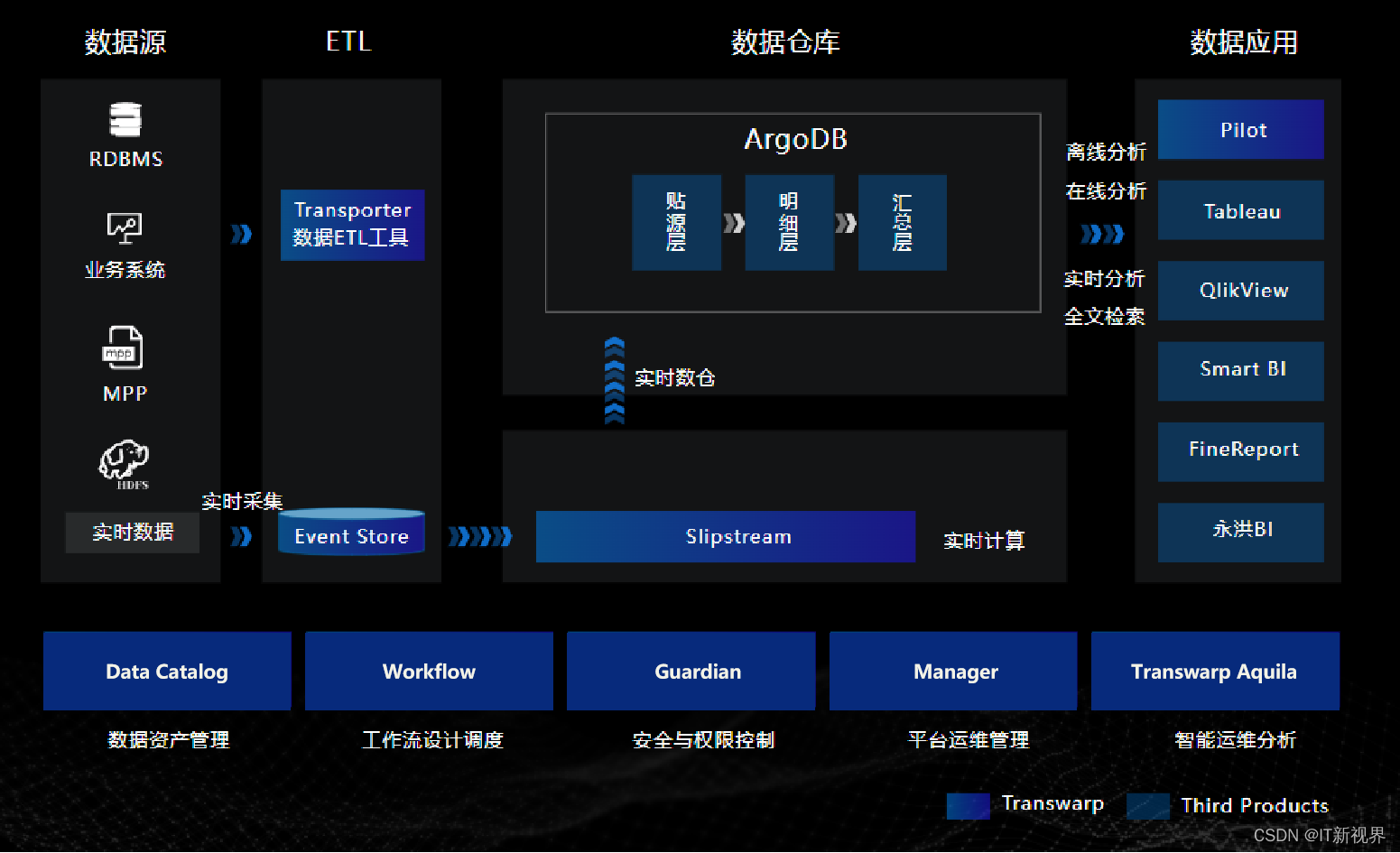
基于星环科技ArgoDB的数据仓库解决方案,通过对数据的清洗、治理、建模、管理、分析,形成数据仓库,为业务人员和管理人员提供管理决策服务。结合星环科技事件存储库Event Store和实时流计算引擎构建实时数据仓库,可以高速接入实时消息数据(吞吐量可以达到数百万记录/秒),或者从交易型数据库实时同步数据到ArgoDB,并对数据进行实时增删改查,以及高速的数据复杂加工和统计分析。
基于星环科技ArgoDB的数据仓库解决方案特性:
多模型数据库
支持关系型、搜索、文本、对象等数据模型
完整的SQL支持
支持完整的SQL标准语法,兼容Oracle、IBM DB2、Teradata方言,兼容Oracle和DB2的存储过程,支持业务平滑迁移
支持超大规模集群
天然分布式架构,集群节点规模无上限,数据存储容量随节点规模线性扩容,可支持2000+节点集群
混合负载支持
支持实时数据与混合负载,支持海量数据的离线批量处理、在线实时分析和多维度的复杂关联统计等功能
分布式事务保障
支持完整4种事务隔离级别,保障事务在分布式系统下正常运转,高吞吐的,确保数据强一致,高可用的事务保证
典型案例
某农商行基于ArgoDB构建了新一代数据仓库,通过支持Oracle方言,极大降低了原先Oracle数据库业务数据和现有分析型业务的迁移成本。在分析型业务方面以更低成本、更高性能完整替代了传统Oracle数据仓库,确保分析型业务与交易型业务的隔离。平台满足了行内包括历史明细数据查询、交易流水查询、实时交易大屏、大额交易提醒等十多个关键查询业务场景需求。针对各类分析型业务的自动性能优化,保障了多用户高并发场景下的性能要求。结合实时流引擎Slipstream,将源数据库Oracle的增量数据以秒级延时快速同步到ArgoDB数仓,尤其确保了对源系统数据有删改的经常性调账退款业务数据能即时反映在分析系统中。平台基于实时落库的业务数据实现了多流水表多维度数据整合的交互式复杂分析能力,将原本基于Oracle的离线级分析能力提升到秒级的准实时级交互式分析能力,为行内未来多种复杂的分析型业务应用的拓展与更高的实时性要求打下坚实的技术基础。
数据仓库: 数据仓库-数据仓库解决方案-星环科技
这篇关于数据仓库 | 从买菜这件小事来聊聊数据仓库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!