本文主要是介绍2020年泰迪杯C题智慧政务中的文本数据挖掘应用--含全部源码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.摘要
本文是针对智慧政务中的文本数据挖掘应用的研究。通过建立基于三层网络结构的fastText文本分类模型,聚类量化模型,熵权评估模型解决了群众留言分类,热点问题挖掘,答复意见评价等问题。
针对群众留言分类问题,本文利用所给数据进行词频统计和词云图分析。得到所给训练集是一种不平衡数据集,我们对已有的数据集进行采样,从而扩充训练集,解决数据不平衡问题。为了方便应用分类模型,我们对文本数据进行正则预处理,去停用词,jieba智能分词来获取特征文本。分词部分,我们利用逆向最大匹配分词算法BMM和jieba分词实现了更好的分词效果。对于分类模型的建立,我们考虑基于TFIDF关键词抽取和最大相似度匹配的无监督分类模型,最终在验证集上的F1得分为0.56。为了得到更加精准的分类模型,利用表征学习进行文本词嵌入,结合fastText文本分类模型实现了有监督聚类,最终的验证集F1评分为0.93。该模型的分类效果较好,基本满足分类需求。
针对热点问题挖掘,本文通过建立k-means聚类量化模型实现了问题热度指数的量化。首先量化留言关注度,将一条留言所有的点赞数和反对数相加作为一个留言关注度量化评分。我们考虑从留言具体内容的角度来研究留言热度。我们利用词频共现算法来获取关键词指数,然后利用文本相关系数构建k-means聚类量化模型,文本热度指数可以根据留言到中心簇的距离公式来量化。综合考虑点赞数与反对数指标,从而加权归一化得到整体的留言热度指数。最终根据留言热度指数量化结果排序,获取了排名前五的热点问题。进一步利用聚类算法对热点问题进行归类,得到的最终热点问题结果表见正文表3。其中前五的热点问题中有三条是关于A市58车贷案,这也说明该问题引起了广泛关注。
针对答复意见的评价问题,本文通过量化相关性,完整性,可解释性来综合量化留言质量。对于相关性,我们利用莱文斯坦相似度计算留言和答复的文本相似性来量化。对于答复意见的完整性指标量化,我们考虑利用文本分词算法,通过文本分词数来衡量。可解释性指标,我们利用字符串匹配结合高频词统计来获取。根据量化的三个指标,我们建立了熵权综合评估模型,利用python编程,最终给出了每个答复的熵权评分作为答复意见质量评分。最终给出了排名前10的留言答复意见结果表,具体见正文表4。
2.思路分析
2.1问题一的分析
本题要求针对文本留言内容建立一个一级标签分类模型。从而实现群众留言的自动化分类。我们首先针对附件二多给的文本数据进行定性的分析,包括文本词频统计,词云图绘制等。
为了能够较好的应用分类模型,我们首先针对文本数据进行特征预处理,利用正则替换,jieba分词,去除停止词等手段来清洗数据。进一步利用清洗之后的特征数据进行分类建模。对于分词部分,虽然利用了jieba智能分词模块,但仍旧有很多比较长的专业词很难完整的划分出来,因此我们利用逆向最大匹配分词算法BMM借助自建词表实现最佳分词。利用预处理之后的分类特征,我们首先尝试利用关键词提取以及关键词和标签词的最大相似度匹配来实现文本分类。关键词提取主要采用TFIDF算法来实现文本关键词抽取。
但是考虑到这种方法是一种无监督的分类算法,准确率可能比较低,因此我们考虑利用表征学习进行词嵌入,进一步利用开源Fasttext文本分类框架构建分类模型,从而实现有监督训练的文本分类。我们还提出了利用word2vec对文本进行表征学习,并且构建LGB最大提升树模型来实现文本分类的有监督训练。并且对比主流模型在测试集评分结果,从而得到较好的分类结果。
2.2问题二的分析
本题要求针对热点问题进行挖掘,主要目的是从群众留言中挖掘出热点问题。也就是给每一条留言都量化一个热度指数。并且根据热度指数进行排序,从而获取热度较高的评价问题。
对于热度指数的量化,我们通过对附件3数据可以发现问题的点赞数与反对数可以在一定程度上反应这个问题的关注度情况。因此问题的点赞数与反对数也是衡量问题热度的一个重要指标。比如问题的点赞数越多,就越说明这个问题反应人民群众的心声。进一步我们考虑从留言具体内容的角度来研究留言热度。首先对文本数据进行预处理,同样包括正则字符处理,jieba分词,然后针对预处理之后留言文本进行词频统计分析。进一步根据词频共现算法来获取关键词指数。根据关键词指数量化文本之间的相关关系,然后根据文本相关系数进行聚类。从而将距离聚类中心簇较远的留言视为热点问题。
文本热度指数可以根据留言到中心簇的距离公式来量化,再综合考虑点赞数与反对数指标,从而加权归一化得到整体的留言热度指数。进一步排序获取最终的结果。
2.3问题三的分析
本题要求根据部门对于留言的答复意见给出一套意见的质量评价。我们尝试从各种角度来评估答复意见的质量,主要包括从相关性,完整性以及可解释性等角度。
对于答复意见的相关性质量,我们考虑利用文本相似度计算来衡量,通过利用前文的关键词抽取算法,抽取出留言的关键词文本和答复意见文本计算余弦相似度或者是莱文斯坦相似度。其中,莱文斯坦相似度描述的是两端文本之间的形体相似性。最终利用上述相似度计算结果归一化获取答复意见与问题的相关性系数。对于答复意见的完整性评价,我们利用前文的文本分词算法,通过文本词长度统计来衡量,一般来说文本含有的词语越多,回复意见越完整。此外对于答复意见的可解释性评估,主要考虑利用字符串匹配来获取,主要是统计答复意见中高频词出现在问题中高频词的次数进行统计。最终量化出三个评价指标,然后建立熵权综合评价模型,最终给出每个答复意见的质量评价得分。
3.解题过程
本题要求针对文本留言内容建立一个一级标签分类模型。从而实现群众留言的自动化分类。我们首先针对附件二给的文本数据进行定性的分析,包括文本词频统计,词云图绘制等。
对于文本标签的分类,我们结合无监督相似性识别和有监督聚类来实现最终的多分类模型构建,从而训练一个更加准确的分类器。
根据上述分析,我们给出了问题一解题思路流程图如下:
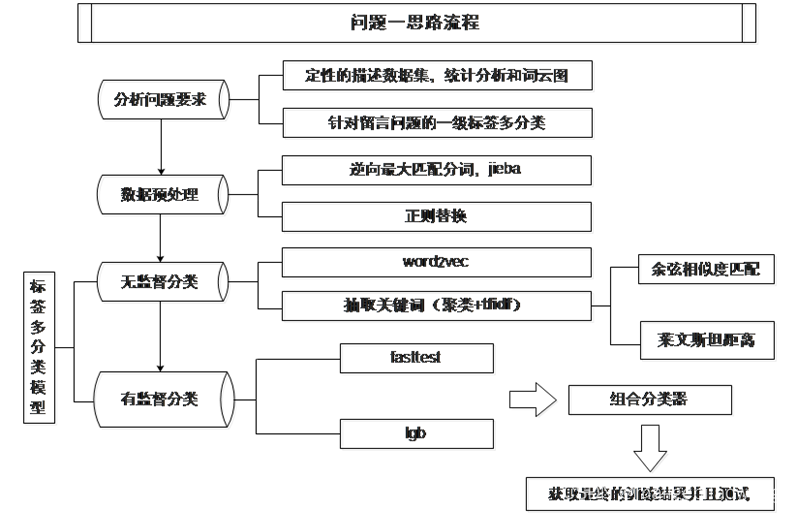
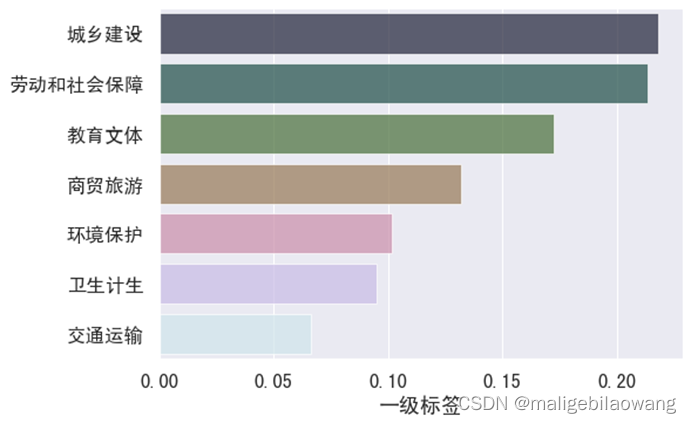
图2 一级标签留言的占比情况

图3 附件二所有文本词云图
根据上述的词云图,我们也可以得到政府留言问题多数是关于城乡建设问题。而且学校,房屋,医院,工作等是群众问政留言记录中的高频词汇。这也从很大程度上说明老板姓真正关心的还是衣食住行等问题。
为了能够较好的应用分类模型,我们首先针对文本数据进行特征预处理,利用正则替换,jieba分词,去除停止词等手段来清洗数据。进一步利用清洗之后的特征数据进行分类建模。

图4 只使用jieba分词

图5 jieba分词结合BMM算法
根据上图对比,我们可以得到,只利用jieba分词,文本分的比较细。有一些长词很难准确的分出来。比如‘未管所’表示未成年管教所,只采用jieba分词的结果为未管,很难理解它是什么意思。而采用基于词典的BMM结合结巴分词之后的效过相对较好。很多长词都能够较好的分割出来。
我们利用预处理之后的文本再来研究文本分类,最终的目的是建立一个多标签的文本分类模型。
4.源码分享
附上2020年泰迪杯C题一等奖论文+源码,链接如下:
2020年泰迪杯C题全部源码
这篇关于2020年泰迪杯C题智慧政务中的文本数据挖掘应用--含全部源码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






