本文主要是介绍STRCF:earning Spatial-Temporal Regularized Correlation Filters for Visual Tracking,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
STRCF论文![]() https://paperswithcode.com/paper/learning-spatial-temporal-regularized
https://paperswithcode.com/paper/learning-spatial-temporal-regularized
STRDF代码![]() https://github.com/lifeng9472/STRCF
https://github.com/lifeng9472/STRCF
本文是在SRDCF的基础上进行的改进,如果没看过这篇论文,建议先看一下;
SRDCF![]() https://paperswithcode.com/paper/learning-spatially-regularized-correlation
https://paperswithcode.com/paper/learning-spatially-regularized-correlation
首先作者分析了导致SRDCF速度慢的问题,主要总结的三个方面:
(1)尺度估计
(2)空间正则化
(3)大训练集的公式化(利用历史样本模板进行训练更新)
作者在这里进行了一个实验;
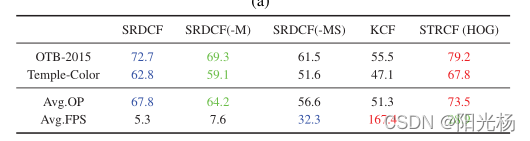
-M表示去掉了 第三项,采用插值的方式进行迭代更新,-MS表示去掉了第二和第三项,从结果可以看出,跟踪的效率的确与上面三项有关。(之所以没有进行取掉第一项(尺度估计)的实验,是因为,加上它也可以达到实时跟踪的要求(大于30帧每秒))。
针对以上问题,作者在单个图片样本中引入了一个时间正则化去优化效率,,作者的这种想法主要来自于passive-aggressive algorithms(PA:被动攻击算法)。
通过引入时间正则化,多幅图像上的公式可以简化为单幅图像上的STRCF模型,怎么理解这句话呢,我们可以从下面这两个公式入手:
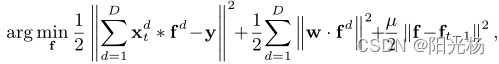
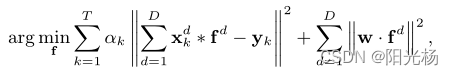
上面是STRCF的目标函数,下面是SRDCF的目标函数,可以看出,STRCF多了一个时间正则化![]() ,但是少了权重系数
,但是少了权重系数,SRDCF就是利用相邻历史帧(也就是多个训练图像)去训练滤波器,而STRCDF由于没有权重
,所以只对单帧进行处理。
但是作者是怎么引入时间正则化![]() 的呢?那就必须的说一下PA算法的思想了。可以参考一下这篇文章Passive Aggressive Algorithms
的呢?那就必须的说一下PA算法的思想了。可以参考一下这篇文章Passive Aggressive Algorithms
![]() 表示前一帧的滤波器模型。f表示当前帧的滤波器模型。
表示前一帧的滤波器模型。f表示当前帧的滤波器模型。
STRCF也可以从两个方面看做在线PA的扩展:(I)STRCF不是分类,而是线性回归的在线学习;(ii)STRCF中的样本不是逐实例更新,而是在每一轮的批处理级别(即图像的所有移位版本)出现。因此,STRCF自然地继承了在线PA在自适应地平衡主动和被动模型学习之间的折衷上的优点,从而在大的外观变化的情况下产生更鲁棒的模型。如下图所示:
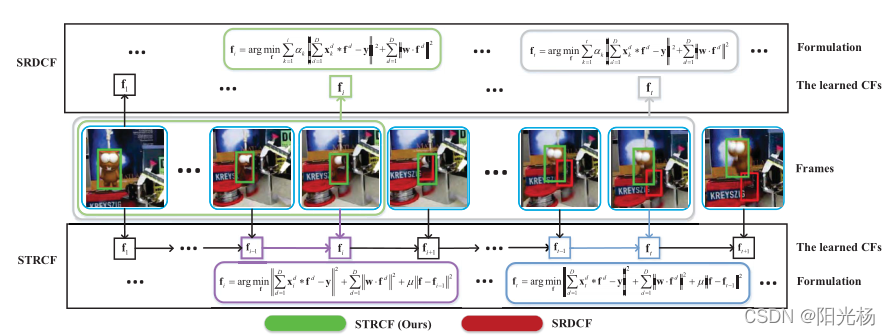
与SRDCF类似,STRCF也通过引入时间正则化子实现了同时的DCF学习和模型更新,因此可以作为SRDCF的多训练样本的合理近似;(ii)在遮挡的情况下,虽然SRDCF遭受对最近被破坏的样本的过度拟合,但是STRCF可以通过被动地更新CFs以使其接近先前的CFs来减轻这种情况。也就是说在遮挡或变形的情况下表现良好。
我认为,![]() 表示的是移位样本所对应的滤波器的相似性,这个值越小,说明两者是正样本的概率就越大,这样就可以把那些负样本给剔除掉,当差别过大时,就对f进行调整,而差别不大时,此项近乎为0,也不用做太大调整,这样就可以与PA算法的思想对应起来(个人理解,不喜勿喷)
表示的是移位样本所对应的滤波器的相似性,这个值越小,说明两者是正样本的概率就越大,这样就可以把那些负样本给剔除掉,当差别过大时,就对f进行调整,而差别不大时,此项近乎为0,也不用做太大调整,这样就可以与PA算法的思想对应起来(个人理解,不喜勿喷)
本文利用了ADMM的方式去优化目标函数:
通过一个辅助变量f=g,去构造拉格朗日乘子:
s表示拉格朗日乘数,表示罚因子,
表示步长参数,再引进一个
![]() 上式可变为
上式可变为
子问题为:
下面分别求解f和g
求解 f :
![]() 表示沿所有D通道由f的第j个元素组成的向量,上式对x(M,N,D)分解成MN个子问题求解,即对每个像素位置进行求解,所以总的时间复杂度为O(DMN)。由于上式是凸函数,所以对其求导可以求出全局最优解;
表示沿所有D通道由f的第j个元素组成的向量,上式对x(M,N,D)分解成MN个子问题求解,即对每个像素位置进行求解,所以总的时间复杂度为O(DMN)。由于上式是凸函数,所以对其求导可以求出全局最优解;
![]()
![]()
利用谢尔曼莫森公式求解得:
求解 g :
![]()
直接对其求导得:
w表示与D个对角矩阵Diag(w)级联的DM N × DM N个对角矩阵
通过如下更新:
![]()
原理到此外结束,实验细节和数据可以自行看论文
这篇关于STRCF:earning Spatial-Temporal Regularized Correlation Filters for Visual Tracking的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[VC] Visual Studio中读写权限冲突](/front/images/it_default2.jpg)

