本文主要是介绍入门通俗易懂的神经网络语言模型(NNLM)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 神经网络语言模型(NNLM)
- 输入层(投射层)
- 隐藏层
- 输出层
- 计算复杂度
神经网络语言模型(NNLM)
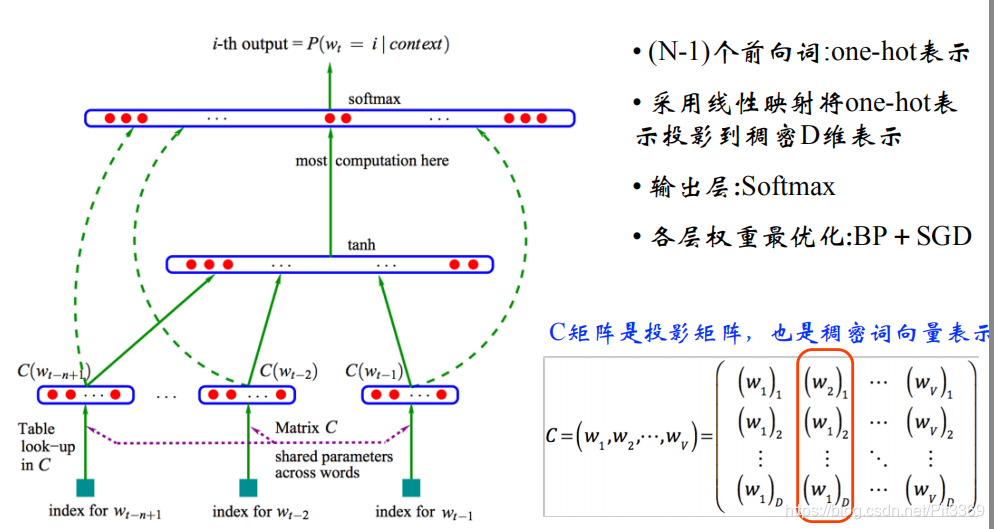
输入层(投射层)
一个文本,由N个词语组成,现在呢:想根据 前N个词语 来预测 第N个词语 是啥?
我们采用的语料库V(也就是我们最大限度能想到的的所有词语集合)包含10万个词语
词向量W:是一个one-hot向量,大小=[10W,1],W(t)表示第t个词语的one hot(一个元素为1,其余全为0
投影矩阵C:维度[D*V],V=10W,参数D根据文本大小不同来设定:谷歌测试时选取D=300
- 计算时:投影矩阵C[300 * 10W] X 词向量W(t)[10W *1] 得到= 矩阵[300 * 1]
- 比如根据前3个词来预测第4个词语,那么上述操作会重复三次,得到3个[300*1]的矩阵
- 将这3个[300*1]的矩阵按行拼接,得到[900x1]的矩阵。
隐藏层
存在一个向量矩阵[Hx1],H根据文本集合情况设定(谷歌测试时选取H=500)
该层完成的功能主要是全连接!
说通俗一些:把输入层计算得到的矩阵[900x1],转换为矩阵[Hx1],完成输入层到隐藏层的数据传输,并且在全连接的过程中存在计算的权重。
最终得到矩阵[500x1]
输出层
我们的词语大小为V=10W,隐藏层计算得到矩阵[500x1],要将这[500x1]的计算结果转化为[10Wx1],以此来预测第4个词语是什么?
得到矩阵[10Wx1],也就是所谓第4个词ont-hot,最终经过SoftMax激活函数,选取行向量最大值,就是预测词语。
计算复杂度
(NxD )+ (NxDxH) + (HxV)
文本词语集大小N,投影矩阵维度D、隐藏层维度H、词库大小V
这篇关于入门通俗易懂的神经网络语言模型(NNLM)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






