本文主要是介绍R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全文链接:http://tecdat.cn/?p=32316
我们常说的中药挖掘,一般是用药挖掘,还有穴位的挖掘,主要是想找出一些用药的规律(点击文末“阅读原文”获取完整代码数据)。
相关视频
在中医挖掘中,数据的来源比较广泛,有的是通过临床收集用药处方,比如,一个著名老中医针对某一疾病的用药情况;有的是通过古籍,古代流传下来的药方;还有一种情况是在论文数据框里查找专门治疗某一疾病的文献,从中找到处方,用来分析。
Apriori算法是一种最有影响的挖掘关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则,Apriori 算法采用了逐层搜索的迭代的方法,算法简单明了,没有复杂的理论推导,也易于实现。
由于Apriori算法的特性,十分适合中药处方、膏方、方剂的挖掘,甚至于穴位的挖掘。
本文帮助客户得出不同处方的药物组合和频率,挖掘出药方内在的规律。
中药处方数据
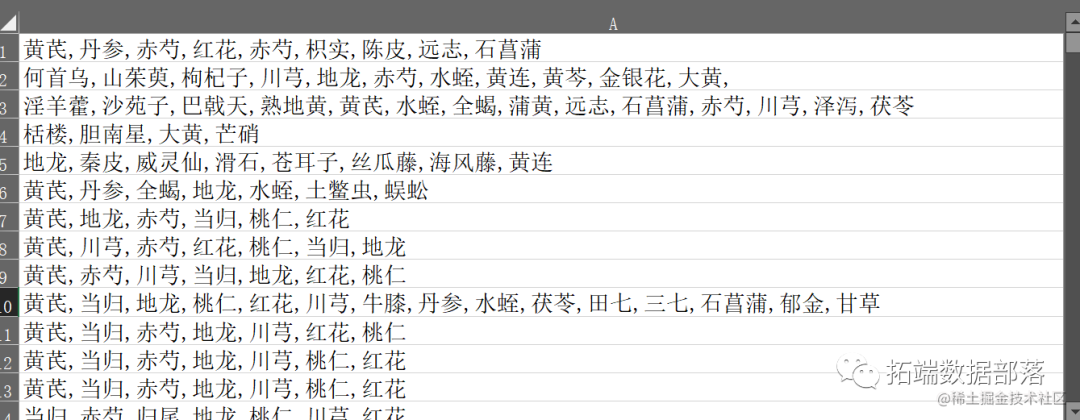
读取数据
a_df3=read.xlsx("挖掘用.xlsx",startRow=0, colNames = F)
转换数据结构
a_list=list(0)
for(i in 1:nrow(a_df3)){ ##删除事务中的重复项目a_list[[i]]= unique(strsplit(a_df3[i,],",")[[1]])
将数据转换成事务类型
trans2 <- as(a_list, "tran查看每个商品的出现频率
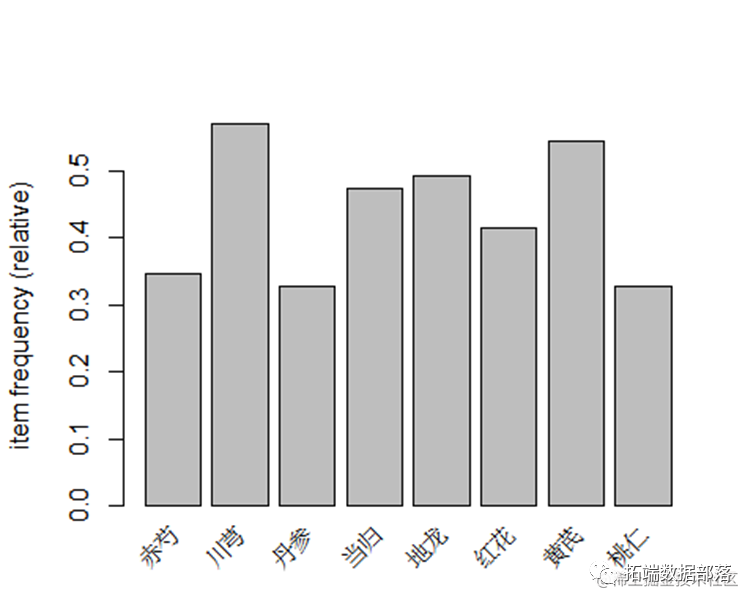
可以看到每个物品出现的频率,从而判断哪些物品的支持度较高。
关联规则挖掘
药对挖掘
at(dat1,parameter=list(support=0.3,minlen=2,maxle
得到频繁规则挖掘
inspect(frequent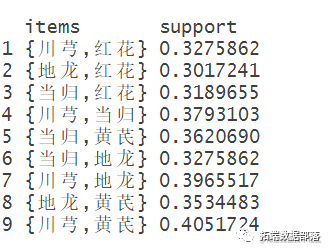
查看求得的频繁项集
spect(sort(frequentsets,by="suppo
根据支持度对求得的频繁项集排序并查看(等价于inspect(sort(frequentsets)[1:10])。
建立模型
apriori(dat1,parame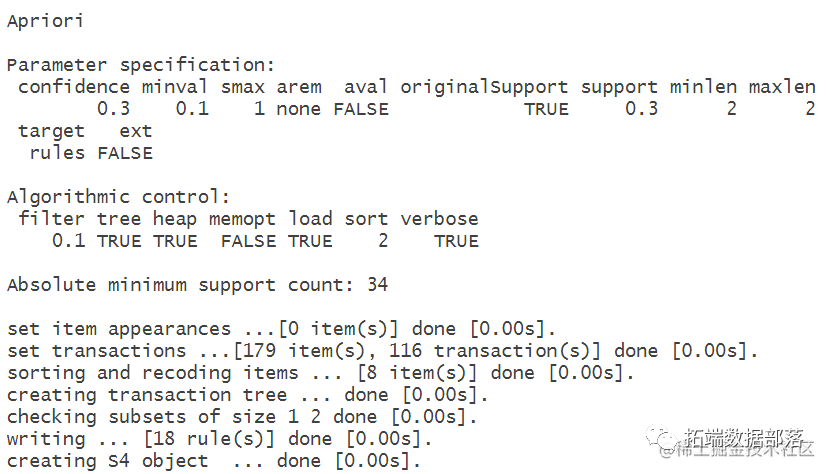
设置支持度为0.01,置信度为0.3
summary(rules)#查看规则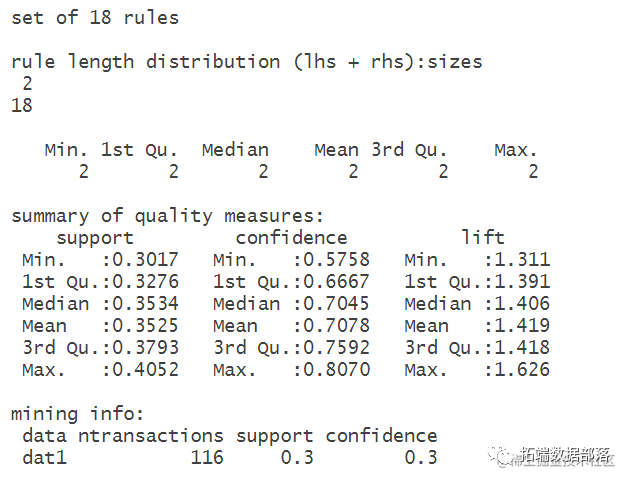
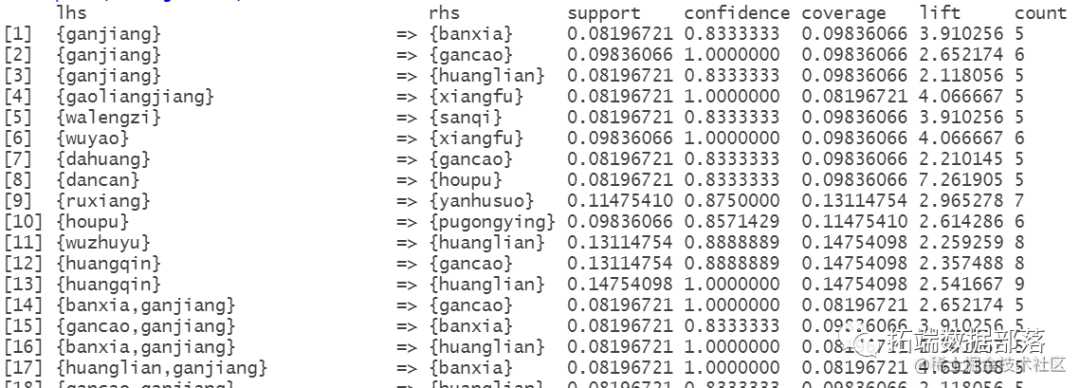
查看部分规则

查看置信度 支持度和提升度
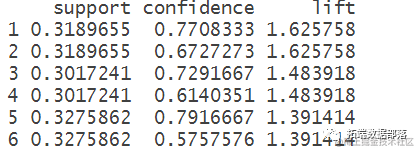
可视化
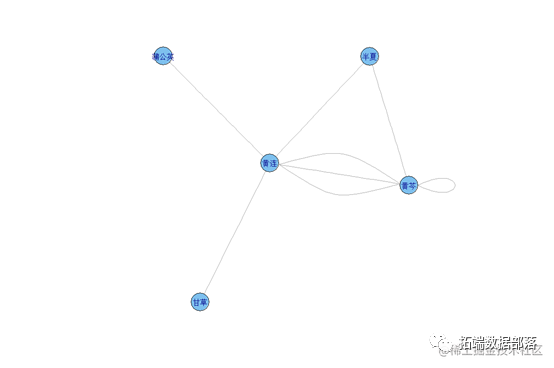
绘制不同规则图形来表示支持度,置信度和提升度。

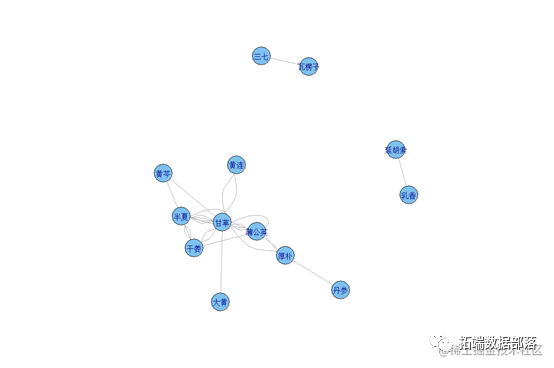
通过该图可以看到规则前项和规则后项分别有哪些物品 以及每个物品的支持度大小,支持度越大则圆圈越大。
点击标题查阅往期内容

R语言APRIORI关联规则、K-MEANS均值聚类分析中药专利复方治疗用药规律网络可视化

左右滑动查看更多
01
02
03

04

ules, method = NULL, measure = "support", shading = "lift", int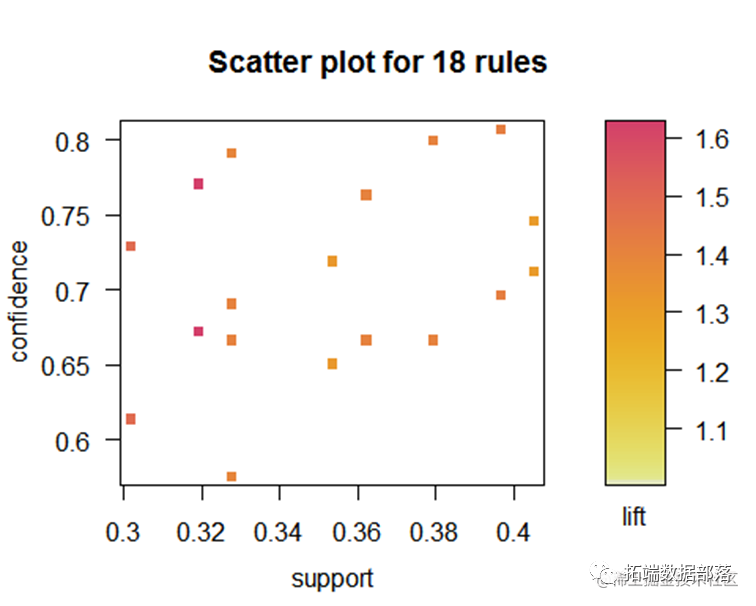
从该图可以看到支持度和置信度的关系,置信度越高提升度也越高。
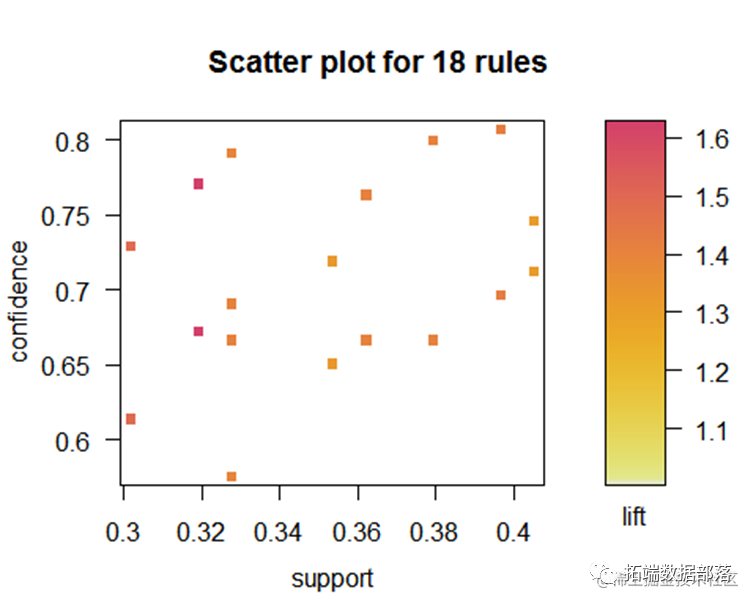
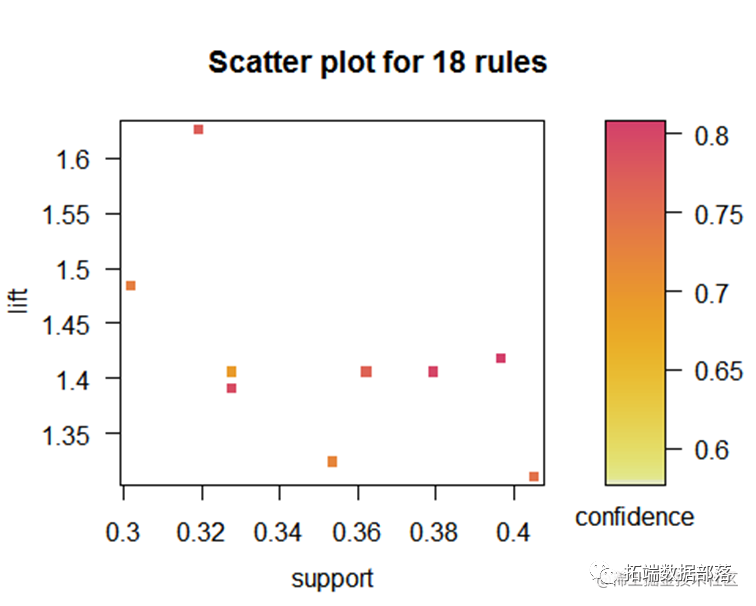
从该图可以看到支持度和置信度的关系,提升度越高置信度也越高。
ules, method="matrix3D", measure="lift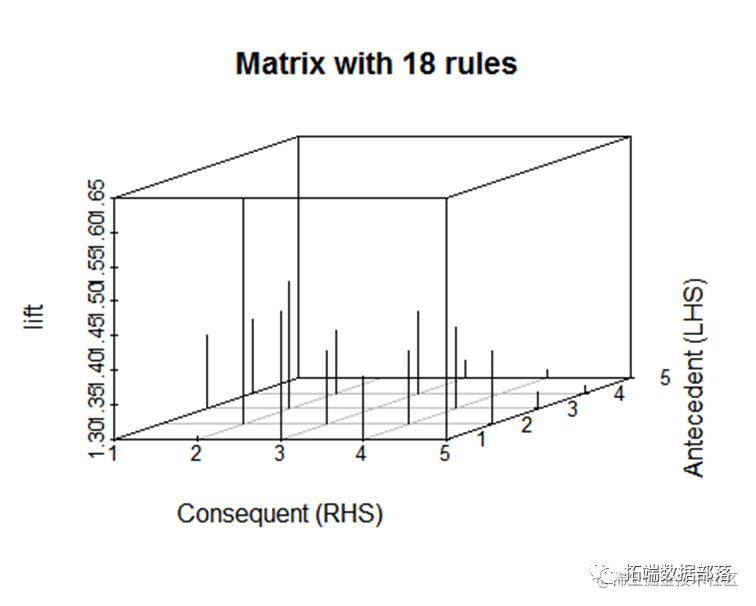

从上图可以看到不同物品之间的关联关系,图中的点越大说明该物品的支持度越高,颜色越深说明该物品的提升度越高。
plot(rules, method="doubledecker" )查看最高的支持度样本规则
ules::inspect(head(rules
查看最高置信度样本规则
sort(rules, by="confidenc
nspect(head(rules
sort(rules, by="lift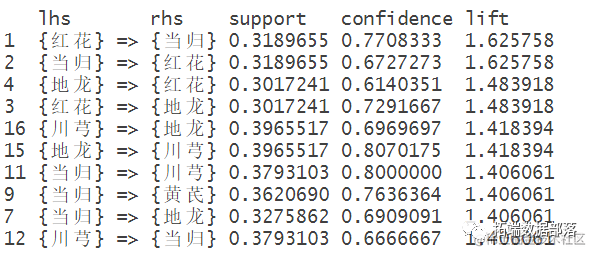
得到有价值规则子集
rules,subset=confidence>0.3 & support>0.2 & lift>=1
summary(x)
按照支持度排序
sort(x,by="support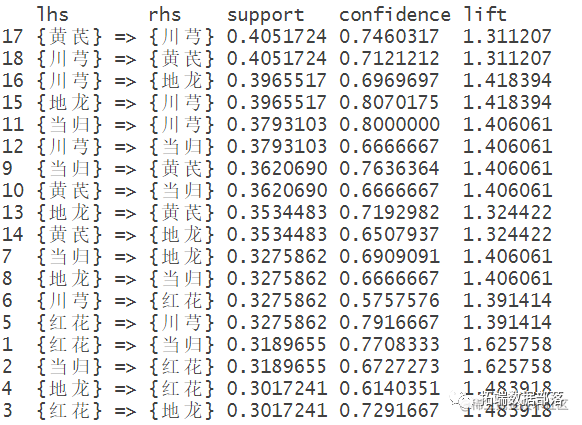
按照置信度排序
inspect(sort(x,by="confide
对有价值的x集合进行数据可视化。
method="grouped")
组合挖掘
at(dat1,parameter=list(support=0.22,minlen=3,maxle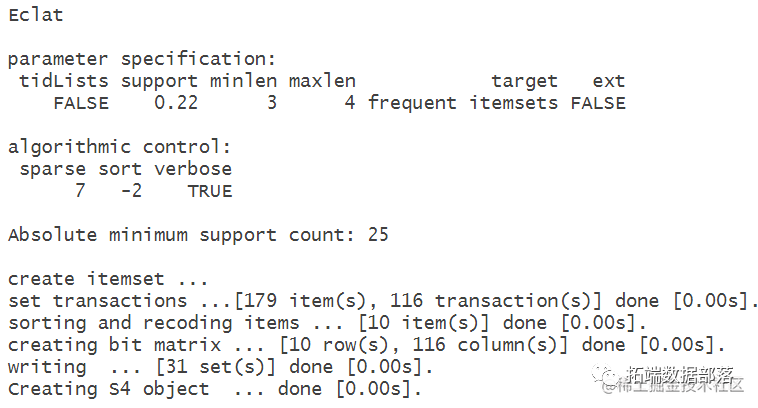
得到频繁规则挖掘
nspect(frequents
查看求得的频繁项集
nspect(sort(frequentsets,by="sup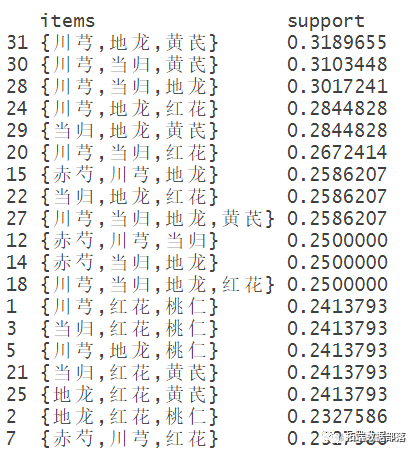
根据支持度对求得的频繁项集排序并查看(等价于inspect(sort(frequentsets)[1:10])
建立模型
apriori(dat1,parameter=list(support=0.24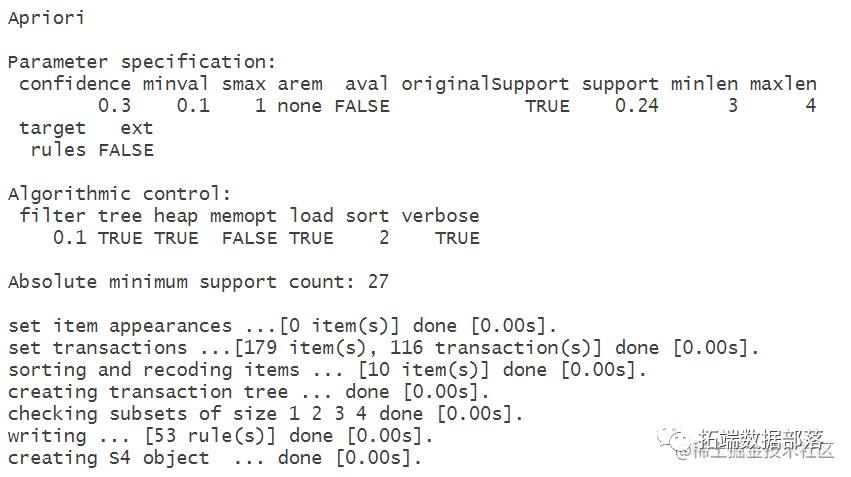
设置支持度为0.01,置信度为0.3。
summary(rules)#查看规则
查看部分规则

查看置信度、支持度和提升度
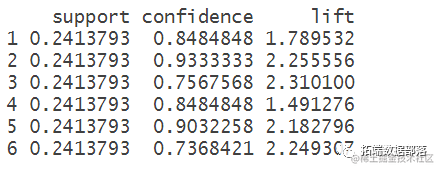
可视化

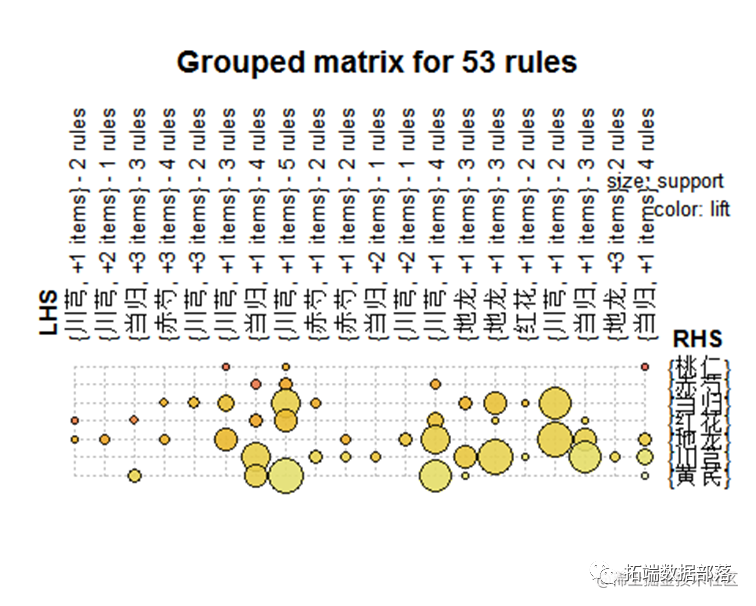

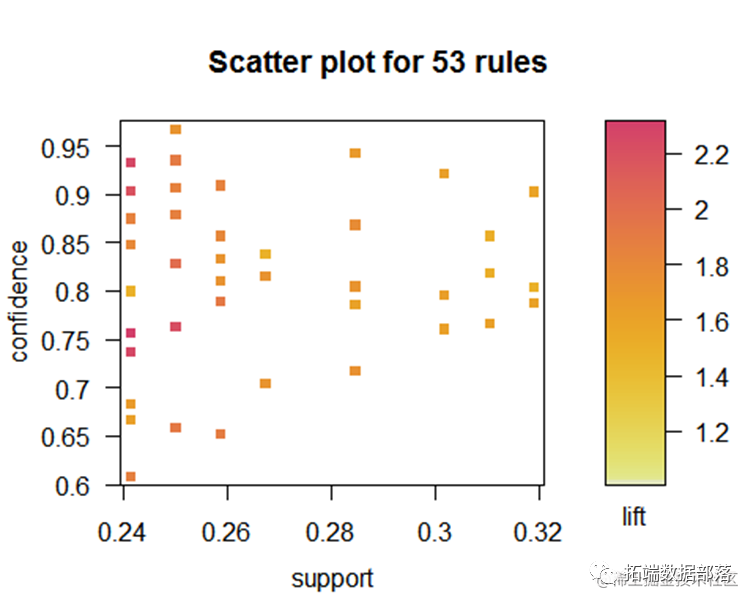
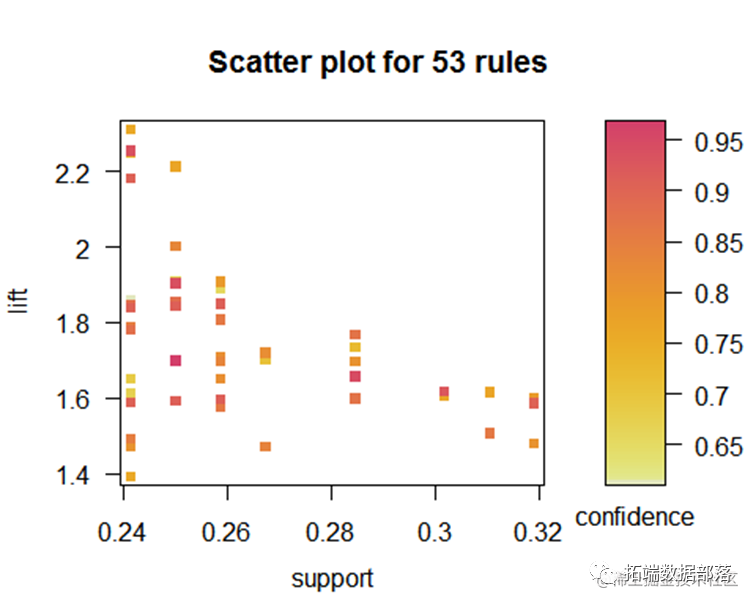
从该图可以看到支持度和置信度的关系,提升度越高置信度也越高。

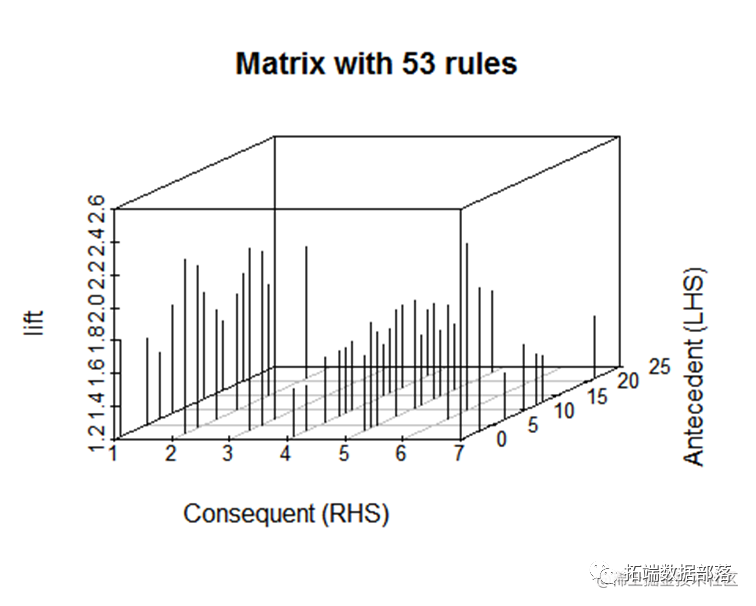
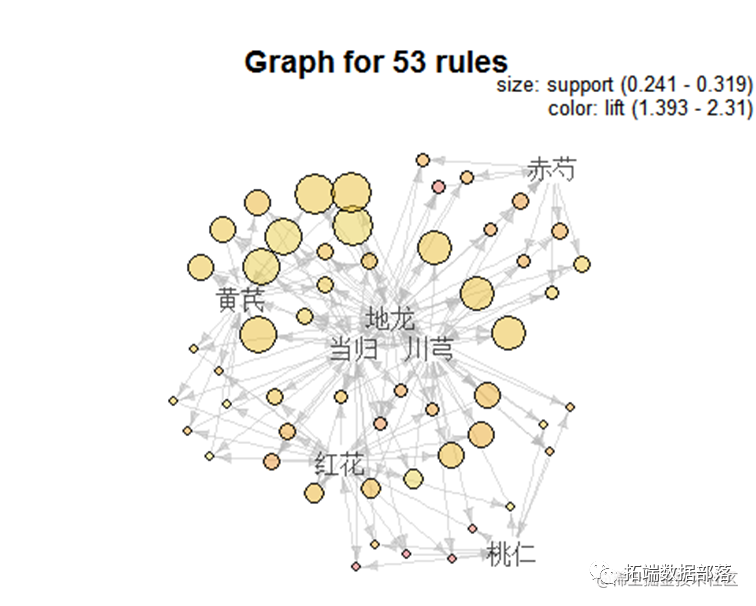
查看最高的支持度样本规则

查看最高置信度样本规则

查看最高提升度样本规则

confidence>0.3 & support>0.3 & lift>=1) #得到有价值规则子集
summary(x)
aspect(sort(x,by="support")) #按照支持度排序## lhs rhs support confidence lift
## 45 {川芎,黄芪} => {地龙} 0.3189655 0.7872340 1.602090
## 43 {地龙,黄芪} => {川芎} 0.3189655 0.9024390 1.586105
## 44 {川芎,地龙} => {黄芪} 0.3189655 0.8043478 1.481021
## 42 {川芎,黄芪} => {当归} 0.3103448 0.7659574 1.615474
## 41 {川芎,当归} => {黄芪} 0.3103448 0.8181818 1.506494
## 40 {当归,黄芪} => {川芎} 0.3103448 0.8571429 1.506494
## 37 {当归,地龙} => {川芎} 0.3017241 0.9210526 1.618820
## 38 {川芎,当归} => {地龙} 0.3017241 0.7954545 1.618820
## 39 {川芎,地龙} => {当归} 0.3017241 0.7608696 1.604743pect(sort(x,by="confidence")) #按照置信度排序## lhs rhs support confidence lift
## 37 {当归,地龙} => {川芎} 0.3017241 0.9210526 1.618820
## 43 {地龙,黄芪} => {川芎} 0.3189655 0.9024390 1.586105
## 40 {当归,黄芪} => {川芎} 0.3103448 0.8571429 1.506494
## 41 {川芎,当归} => {黄芪} 0.3103448 0.8181818 1.506494
## 44 {川芎,地龙} => {黄芪} 0.3189655 0.8043478 1.481021
## 38 {川芎,当归} => {地龙} 0.3017241 0.7954545 1.618820
## 45 {川芎,黄芪} => {地龙} 0.3189655 0.7872340 1.602090
## 42 {川芎,黄芪} => {当归} 0.3103448 0.7659574 1.615474
## 39 {川芎,地龙} => {当归} 0.3017241 0.7608696 1.604743对有价值的x集合进行数据可视化



点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化》。
点击标题查阅往期内容
非线性混合效应 NLME模型对抗哮喘药物茶碱动力学研究
Python面板时间序列数据预测:格兰杰因果关系检验Granger causality test药品销售实例与可视化
R语言用关联规则和聚类模型挖掘处方数据探索药物配伍中的规律
用SPSS Modeler的Web复杂网络对所有腧穴进行关联规则分析
PYTHON在线零售数据关联规则挖掘APRIORI算法数据可视化
R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
R语言关联挖掘实例(购物篮分析)
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
基于R的FP树fp growth 关联数据挖掘技术在煤矿隐患管理
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
通过Python中的Apriori算法进行关联规则挖掘
Python中的Apriori关联算法-市场购物篮分析
R语言用关联规则和聚类模型挖掘处方数据探索药物配伍中的规律
在R语言中轻松创建关联网络
python主题建模可视化LDA和T-SNE交互式可视化
R语言时间序列数据指数平滑法分析交互式动态可视化
用R语言制作交互式图表和地图
如何用r语言制作交互可视化报告图表
K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
PYTHON实现谱聚类算法和改变聚类簇数结果可视化比较
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据
r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化
Python Monte Carlo K-Means聚类实战研究
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言谱聚类、K-MEANS聚类分析非线性环状数据比较
R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化
Python、R对小说进行文本挖掘和层次聚类可视化分析案例
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
R语言复杂网络分析:聚类(社区检测)和可视化
R语言中的划分聚类模型
基于模型的聚类和R语言中的高斯混合模型
r语言聚类分析:k-means和层次聚类
SAS用K-Means 聚类最优k值的选取和分析
用R语言进行网站评论文本挖掘聚类
基于LDA主题模型聚类的商品评论文本挖掘
R语言鸢尾花iris数据集的层次聚类分析
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言聚类算法的应用实例

![]()

这篇关于R语言Apriori算法关联规则对中药用药复方配伍规律药方挖掘可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








