本文主要是介绍第06章 移动端微量神经网络模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序言
1. 内容介绍
本章介绍深度学习算法-卷积神经网络用于 图片分类 的应用,主要介绍主流微型卷积神经网络 (CNN) 模型,包括 SqueezeNet ShuffleNet 的算法模型、数学推理、模型实现 以及 PyTorch框架 的实现。并能够把它应用于现实世界的 数据集 实现分类效果。
2. 理论目标
- 移动端微型卷积神经网络的通用设计准则
- SqueezeNet 的基础模型架构、训练细节与数学推理
- ShuffleNet 的基础模型架构、训练细节与数学推理
3. 实践目标
- 掌握PyTorch框架下SqueezeNet ShuffleNetV2 的实现
- 掌握迁移学习与特征提取
- 熟悉各经典算法在图像分类应用上的优缺点
4. 实践数据集
- Flower 数据集分类
- Oxford-IIIT 数据集分类
- CIFAR-10 数据集分类
5. 内容目录
- 1.微型神经网络简介
- 2.卷积神经网络模型详解 SqueezeNet
- 3.卷积神经网络模型详解 ShuffleNet
- 4.PyTorch 实践
- 5.图像分类实例 Flower 数据集
- 6.图像分类实例 Oxford-IIIT 数据集
- 7.图像分类实例 CIFAR-10 数据集
第1节 微型神经网络简介
目前神经网络领域的研究基本可以概括为两个方向:探索模型更好的 预测能力,关注模型在实际应用中的难点。事实上卷积神经网络在图像识别领域超越了人类的表现,但是这些先进的网络需要较高的计算资源。这些资源需求超出了很多移动设备和嵌入式设备的能力(如无人驾驶),导致实际应用中难以在这些设备上应用。小型网络就是为解决这个难点来设计的。
小型网络的设计和优化目标并不是模型的准确率,而是在满足一定准确率的条件下,尽可能的使得模型小,从而降低对计算资源的需求,降低计算延迟。小型高效的神经网络的构建方法大致可以归为两类:对已经训练好的网络进行压缩,直接训练小网络模型。模型参数的数量决定了模型的大小,所谓的 微型网络 指的是网络的参数数量较少
-
较小的模型具有更高效的 分布式训练效率: Worker 与 PS 以及 Worker 与 Worker 之间的通信是神经网络分布式训练的重要限制因素。在分布式数据并行训练中,通信开销与模型的参数数量成正比。较小的模型需要更少的通信,从而可以更快的训练
-
较小的模型在 模型导出 时开销更低:当在tensorflow 等框架中训练好模型并准备部署时,需要将模型导出。如将训练好的模型导出到自动驾驶汽车上。模型越小,则数据导出需要传输的数据量越少,这样可以支持更频繁的模型更新
-
较小的模型可以在 FPGA 和 嵌入式硬件 上部署:FPGA 通常只有小于10MB 的片上内存,并且没有外部存储。因此如果希望在FPGA 上部署模型,则要求模型足够小从而满足内存限制
1.1 微型网络通用设计准则
目前衡量模型推断速度的一个通用指标是 FLOPs (即乘-加 计算量)。事实上这是一个间接指标,因为它不完全等同于推断速度。如 MobileNet V2 和 NASNET-A 的FLOPs 相差无几,但是 MobileNet V2 的推断速度要快得多。
如下所示为几种模型在 GPU 和 ARM 上的准确率 (在 ImageNet 验证集上的测试结果)、模型推断速度 (通过 Batch/秒 来衡量)、计算复杂度 (通过 FLOPs 衡量) 的关系
-
在 ARM 平台上 batchsize=1, 在 GPU 平台上 batchsize = 8
-
准确率与模型容量成正比,而模型容量与模型计算复杂度成成比、计算复杂度与推断速度成反比
因此模型准确率越高,则推断速度越低;模型计算复杂度越高,则推断速度越低
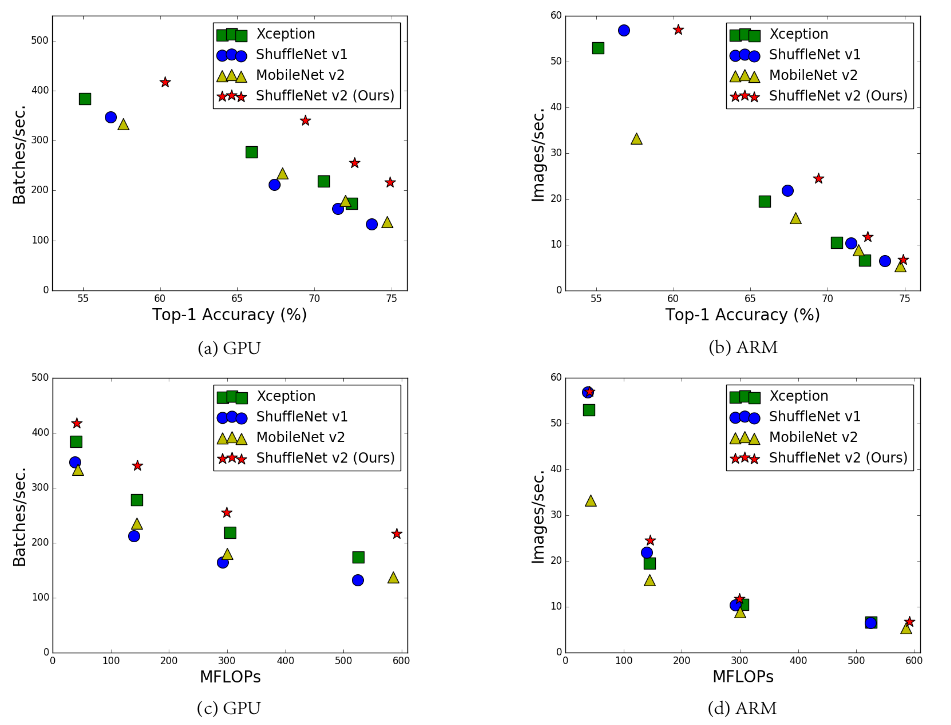
高效网络设计的几个通用准则
- 准则一:输入通道数和输出通道数 相等 时,MAC 指标最小
假设输入 feature map 尺寸为 W\times HW×H、通道数为 C_ICI ,输出通道数为 C_OCO, 假设为 1\times11×1 卷积,则 FLOPs 为 B = C_I \times 1 \times 1 \times W \times H \times C_O = WHC_IC_OB=CI×1×1×W×H×CO=WHCICO
其内存访问量为输入 featuremap 内存访问量 + 输出 featuremap 内存访问量+ 卷积核内存访问量。因此有 MAC = WHC_I + WHC_O + C_I \times 1 \times 1 \times C_O = WH(C_I + C_O)MAC=WHCI+WHCO+CI×1×1×CO=WH(CI+CO) 。根据不等式 C_I + C_O \ge 2\sqrt{C_IC_O}CI+CO≥2CICO,以及 C_IC_O = \frac{B}{WH}CICO=WHB,则有 MAC \ge 2 \sqrt{WHB} + \frac{B}{WH}MAC≥2WHB+WHB 。当 C_I = C_OCI=CO 时等式成立
- 准则二:大量使用 分组卷积 会增加 MAC
分组卷积可以降低 FLOPs, 可以在 FLOPs 固定的情况下,增大 featuremap 的通道数从而提高模型的容量。但是采用分组卷积可能增加MAC
对于 1\times11×1 卷积,设分组数为 gg ,则 FLOPs 数为 B = \frac{WHC_IC_O}{g}B=gWHCICO, 内存访问量为 MAC = WH(C_I + C_O) + \frac{C_IC_O}{g}MAC=WH(CI+CO)+gCICO
当 C_I = C_OCI=CO 时,MAC = 2\sqrt{WHBg} + \frac{B}{WH}MAC=2WHBg+WHB 最小。因此 MACMAC 随着 gg 的增加而增加
- 准则三:网络分支 降低 并行度
虽然网络中采用分支(如Inception系列、ResNet系列)有利于提高模型的准确率,但是它对 GPU 等具有高并行计算能力的设备不友好,因此会降低计算效率。另外它还带来了卷积核的 lauching 以及计算的同步等问题,这也是推断时间的开销
- 准则四:不能忽视 元素级 操作的影响
元素级操作包括 ReLU、AddTensor、AddBias 等,它们的 FLOPs 很小但是 MAC 很大。在 ResNet 中,实验发现如果去掉 ReLU 和旁路连接,则在 GPU 和 ARM 上大约有 20% 的推断速度的提升
第2节 卷积神经网络模型 SqueezeNet
2.1 SqueezeNet 简介
Squeezenet 提出了 Fire 模块,并通过该模型构成一种小型 CNN 网络,在满足 AlexNet 级别准确率的条件下大幅度降低参数数量。CNN 结构设计三个主要策略
-
部分的使用 1\times11×1 卷积替换 3\times33×3 卷积。因为 1\times11×1 卷积的参数数量比 3\times33×3 卷积的参数数量少了 9 倍
-
减少 3\times33×3 卷积输入通道的数量。这会进一步降低网络的参数数量
-
将网络中下采样的时机推迟到网络的后面。这会使得网络整体具有尺寸较大的 feature map, 基于在其它不变的情况下,尺寸大的feature map 具有更高的分类准确率。
策略 1、2 是关于在尽可能保持模型准确率的条件下减少模型的参数数量,策略 3 是关于在有限的参数数量下最大化准确率
2.2 SqueezeNet 模型结构
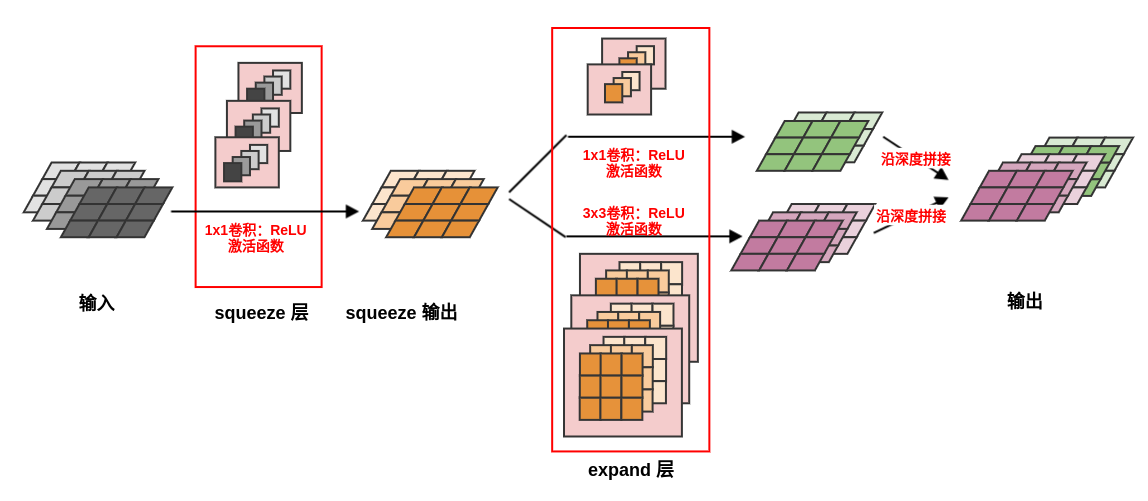
Fire 模块由一个 Squeeze 层 和一个 Expand 层 组成
-
Squeeze 层是一个 1\times11×1 卷积层,输出通道数为超参数 s_{1\times1}s1×1
- 通常选择超参数 s_{1\times1}s1×1 满足 e_{1\times1} + e_{3\times3}e1×1+e3×3
- 它用于减少expand 层的输入通道数,即应用策略 2
-
Expand 层是一个 1\times11×1 卷积层和一个 3\times33×3 卷积层,它们卷积的结果沿着深度进行拼接
- 1\times11×1 卷积输出通道数为超参数 e_{1\times1}e1×1,3\times33×3 卷积输出通道数为超参数 e_{3\times3}e3×3
- 选择 1\times11×1 卷积是应用策略 1
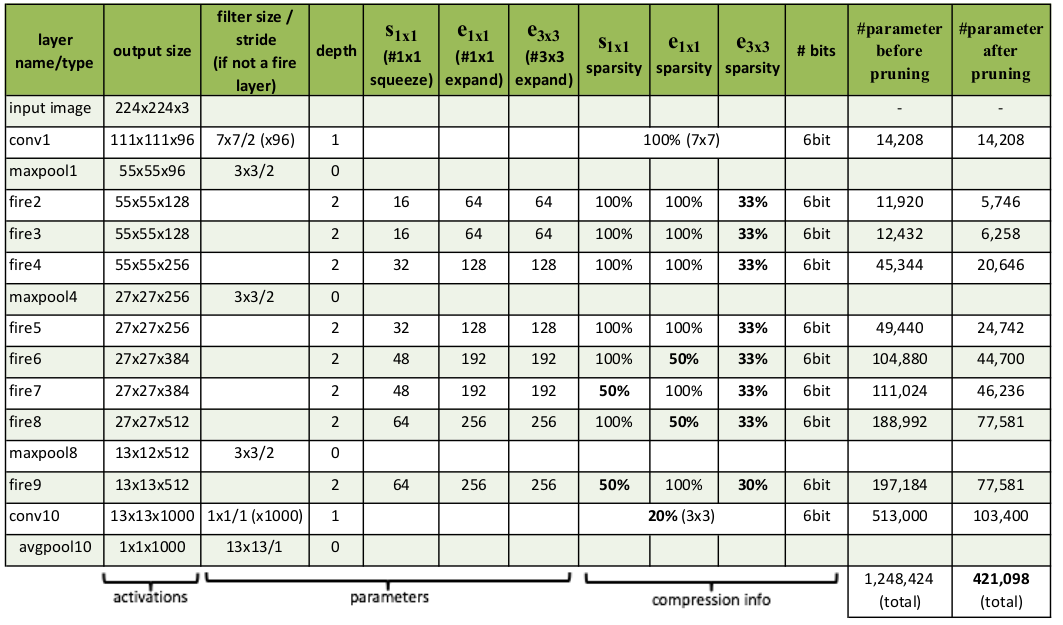
- SqueezeNet 从一个 独立 的卷积层(conv1)开始,后跟 8 个Fire 模块 (fire 2~9), 最后连接卷积层 conv10、全局平均池化层、softmax 输出层
- 从网络开始到末尾,每个 Fire 模块的输出通道数逐渐增加
- 在 conv1、fire4、fire8 之后执行最大池化,步长为 2。这种相对较晚的执行池化操作是采用了策略3
- 在 expand 层中的 3\times33×3 执行的是 same 卷积,即在原始输入上下左右各添加一个像素,使得输出的 feature map 尺寸不变
- 在 fire9 之后使用 Dropout,遗忘比例为 0.5

- s_{1\times1}s1×1 (1 x 1 Squeeze) 列给出了超参数 s_{1\times1}s1×1 ,e_{1\times1}e1×1 (1 x 1 Expand) 列给出了超参数 e_{3\times3}e3×3, (3 x 3 Expand) 列给出了超参数 e_{3\times3}e3×3
- s_{1\times1}s1×1 sparsity, e_{1\times1}e1×1 sparsity, e_{3\times3}e3×3 sparsity, bitbit 这四列给出了模型裁剪的参数
- Parameter before pruning 列给出了模型裁剪之前的参数数量
- Parameter after pruning 列给出了模型裁剪之后的参数数量
- 网络 压缩方法 列给出了网络裁剪方法,包括 SVD (Denton et al. 2014)、Network pruning (Han et al. 2015b)、Deep compression (Han et al. 2015a)
- 数据类型列给出了 计算精度
- 模型压缩比例列给出了模型相对于原始 AlexNet 的模型大小压缩的比例
- Top-1 Accuracy/Top-5 Accuracy 列给出了模型在 ImageNet 测试集上的评估结果
SqueezeNet 在满足同样准确率的情况下,模型大小比AlexNet 压缩了 50 倍。如果使用 Deep Compression 以及 6 bit 精度的情况下,模型大小比AlexNet 压缩了 510 倍
2.3 SqueezeNet PyTorch
# %load squeeze.py import torch import torch.nn as nn class Fire(nn.Module): def __init__(self,inplanes,outplane,ep1,ep3): super(Fire, self).__init__() self.squeeze = nn.Conv2d(inplanes, outplane, kernel_size=1) self.squeeze_relu = nn.ReLU(inplace=True) self.expand1x1 = nn.Conv2d(outplane,ep1,kernel_size=1) self.expand1x1_relu = nn.ReLU(inplace=True) self.expand3x3 = nn.Conv2d(outplane,ep3,kernel_size=3, padding=1) self.expand3x3_relu = nn.ReLU(inplace=True) def forward(self, x): x = self.squeeze_relu(self.squeeze(x)) output = [self.expand3x3_relu(self.expand1x1(x)), self.expand3x3_relu(self.expand3x3(x))] return torch.cat(output, 1) class SqueezeNet(nn.Module): def __init__(self,num_classes=1000): super(SqueezeNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, stride=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True), Fire(64, 16, 64, 64), Fire(128, 16, 64, 64), nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True), Fire(128, 32, 128, 128), Fire(256, 32, 128, 128), nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True), Fire(256, 48, 192, 192), Fire(384, 48, 192, 192), Fire(384, 64, 256, 256), Fire(512, 64, 256, 256), ) self.classifier = nn.Sequential( nn.Dropout(p=0.5), nn.Conv2d(512, num_classes, kernel_size=1), nn.ReLU(inplace=True), nn.AdaptiveAvgPool2d((1, 1)) ) def forward(self, x): x = self.features(x) x = self.classifier(x) return torch.flatten(x, 1) def build_squeeze(phase,num_classes,pretrained): if phase != "test" and phase != "train": print("ERROR: Phase: " + phase + " not recognized") return if not pretrained: model = SqueezeNet(num_classes=num_classes) else: model = SqueezeNet() model_weights_path = 'weights/squeezenet1_1-b8a52dc0.pth' model.load_state_dict(torch.load(model_weights_path), strict=False) for parma in model.parameters(): parma.requires_grad = False model.classifier = nn.Sequential( nn.Dropout(p=0.5), nn.Conv2d(512, num_classes, kernel_size=1), nn.ReLU(inplace=True), nn.AdaptiveAvgPool2d((1, 1)) ) return model
from torchsummary import summary net = build_squeeze('train',10,False) net.cuda() summary(net,(3,224,224))
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 111, 111] 1,792ReLU-2 [-1, 64, 111, 111] 0MaxPool2d-3 [-1, 64, 55, 55] 0Conv2d-4 [-1, 16, 55, 55] 1,040ReLU-5 [-1, 16, 55, 55] 0Conv2d-6 [-1, 64, 55, 55] 1,088ReLU-7 [-1, 64, 55, 55] 0Conv2d-8 [-1, 64, 55, 55] 9,280ReLU-9 [-1, 64, 55, 55] 0Fire-10 [-1, 128, 55, 55] 0Conv2d-11 [-1, 16, 55, 55] 2,064ReLU-12 [-1, 16, 55, 55] 0Conv2d-13 [-1, 64, 55, 55] 1,088ReLU-14 [-1, 64, 55, 55] 0Conv2d-15 [-1, 64, 55, 55] 9,280ReLU-16 [-1, 64, 55, 55] 0Fire-17 [-1, 128, 55, 55] 0MaxPool2d-18 [-1, 128, 27, 27] 0Conv2d-19 [-1, 32, 27, 27] 4,128ReLU-20 [-1, 32, 27, 27] 0Conv2d-21 [-1, 128, 27, 27] 4,224ReLU-22 [-1, 128, 27, 27] 0Conv2d-23 [-1, 128, 27, 27] 36,992ReLU-24 [-1, 128, 27, 27] 0Fire-25 [-1, 256, 27, 27] 0Conv2d-26 [-1, 32, 27, 27] 8,224ReLU-27 [-1, 32, 27, 27] 0Conv2d-28 [-1, 128, 27, 27] 4,224ReLU-29 [-1, 128, 27, 27] 0Conv2d-30 [-1, 128, 27, 27] 36,992ReLU-31 [-1, 128, 27, 27] 0Fire-32 [-1, 256, 27, 27] 0MaxPool2d-33 [-1, 256, 13, 13] 0Conv2d-34 [-1, 48, 13, 13] 12,336ReLU-35 [-1, 48, 13, 13] 0Conv2d-36 [-1, 192, 13, 13] 9,408ReLU-37 [-1, 192, 13, 13] 0Conv2d-38 [-1, 192, 13, 13] 83,136ReLU-39 [-1, 192, 13, 13] 0Fire-40 [-1, 384, 13, 13] 0Conv2d-41 [-1, 48, 13, 13] 18,480ReLU-42 [-1, 48, 13, 13] 0Conv2d-43 [-1, 192, 13, 13] 9,408ReLU-44 [-1, 192, 13, 13] 0Conv2d-45 [-1, 192, 13, 13] 83,136ReLU-46 [-1, 192, 13, 13] 0Fire-47 [-1, 384, 13, 13] 0Conv2d-48 [-1, 64, 13, 13] 24,640ReLU-49 [-1, 64, 13, 13] 0Conv2d-50 [-1, 256, 13, 13] 16,640ReLU-51 [-1, 256, 13, 13] 0Conv2d-52 [-1, 256, 13, 13] 147,712ReLU-53 [-1, 256, 13, 13] 0Fire-54 [-1, 512, 13, 13] 0Conv2d-55 [-1, 64, 13, 13] 32,832ReLU-56 [-1, 64, 13, 13] 0Conv2d-57 [-1, 256, 13, 13] 16,640ReLU-58 [-1, 256, 13, 13] 0Conv2d-59 [-1, 256, 13, 13] 147,712ReLU-60 [-1, 256, 13, 13] 0Fire-61 [-1, 512, 13, 13] 0Dropout-62 [-1, 512, 13, 13] 0Conv2d-63 [-1, 10, 13, 13] 5,130ReLU-64 [-1, 10, 13, 13] 0
AdaptiveAvgPool2d-65 [-1, 10, 1, 1] 0
================================================================
Total params: 727,626
Trainable params: 727,626
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 51.20
Params size (MB): 2.78
Estimated Total Size (MB): 54.55
----------------------------------------------------------------
2.4 SqueezeNet 设计技巧
定义 base_ebasee 为一个 Fire 模块的输出通道数,假设每 freqfreq 个 Fire 模块将 Fire 模块的输出通道数增加 incr_e \to freq = 2incre→freq=2, 则网络中所有 Fire 模块的输出通道数依次为
base_e,base_e,base_e + incr_e,base_e + incr_e,base_e + 2 * incr_e,base_e + 2 * incr_e,\dotsbasee,basee,basee+incre,basee+incre,basee+2∗incre,basee+2∗incre,…
因此第 ii 个 Fire 模块的输出通道数为
e_i = base_e + (incr_e \times [\frac{i-1}{freq}]), i = 1,2,\dots,9ei=basee+(incre×[freqi−1]),i=1,2,…,9
由于 Fire 模块的输出就是 Fire 模块中 Expand 层的输出,因此 e_iei 也就是第 ii 个 Fire 模块中 Expand 层的输出通道数
- 定义 pct_{3\times3}pct3×3 为所有 Fire 模块的 Expand 层中,3\times33×3 卷积数量的比例。这意味着不同 Fire 模块的 Expand 层中 3\times33×3 卷积数量的占比都是同一个比例
- 第 ii 个 Fire 模块的 Expand 层中的 1\times11×1 卷积数量
- 第 ii 个 Fire 模块的 Expand 层中的 3\times33×3 卷积数量
- 定义 squeeze ratiosqueezeratio 为所有 Fire 模块中,Squeeze 层的输出通道数与 Expand 层的输出通道数的比例称作压缩比, 这意味着不同 Fire 模块的压缩比都相同
- 第 ii 个 Fire 模块的 Squeeze 层的输出通道数为 s_{i,1\times1} = e_i \times SRsi,1×1=ei×SR
对于前面给到的 SqueezeNet 有 base_e = 128, freq = 2, incr_e = 128, pct_{3\times3} = 0.5, SR = 0.125basee=128,freq=2,incre=128,pct3×3=0.5,SR=0.125
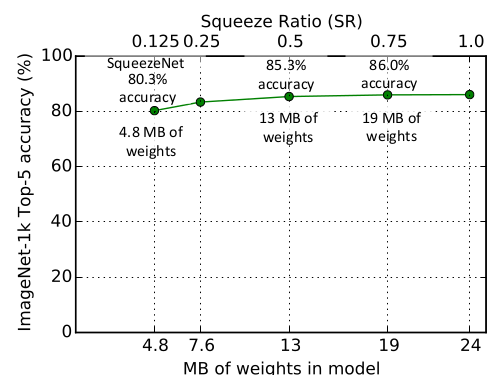
- 评估超参数 SR: base_e = 128, freq = 2, incr_e = 128, pct_{3\times3} = 0.5, SR \in \textbf{(0.15, 1.0)}SR:basee=128,freq=2,incre=128,pct3×3=0.5,SR∈(0.15, 1.0)
在 SR = 0.75SR=0.75 时, ImageNet top-5 准确率达到峰值 86.0% , 此时模型大小为 19MB, 此后进一步增加 SR 只会增加模型大小而不会提高模型准确率
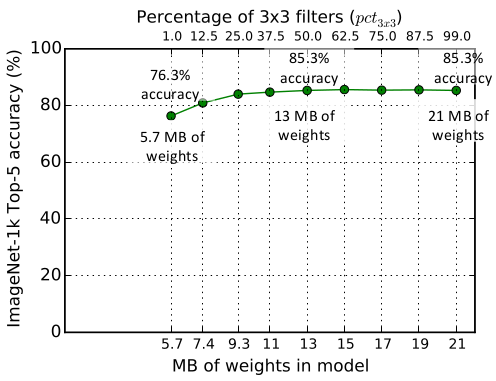
- 评估超参数 SR: base_e = 128, freq = 2, incr_e = 128, pct_{3\times3} = 0.5, SR \in \textbf{(1, 99)}SR:basee=128,freq=2,incre=128,pct3×3=0.5,SR∈(1, 99)
3\times33×3 卷积占比相对于 Expand 层的卷积数量的占比为 50% 时,ImageNet top-5 准确率达到 85.3% 。此后进一步增加 3\times33×3 卷积的占比只会增加模型大小而几乎不会提高模型准确率
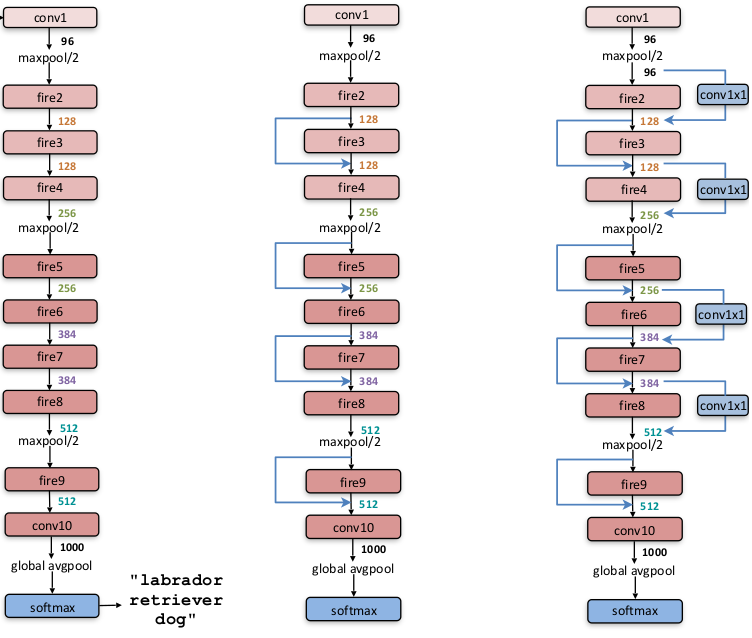
采用 ResNet 的思想,可以在 SqueezeNet 中添加旁路连接。下图中,左图为标准的 SqueezeNet ,中图为引入简单旁路连接的 SqueezeNet,右图为引入复杂旁路连接的SqueezeNet
- 简单旁路 连接:等同于恒等映射。此时要求输入 feature map 和残差 feature map 的通道数相等
- 复杂旁路 连接:针对输入 feature map 和残差 feature map 的通道数不等的情况,旁路采用一个 1\times11×1 卷积来调整旁路的输出通道数
在 ImageNet 测试集上的表现证明添加简单旁路连接能够 提升模型的准确率,还能保持模型的 大小不变
| 模型结构 | top-1准确率 | top-5准确率 | 模型大小 |
|---|---|---|---|
| SqueezeNet | 57.5% | 80.3% | 4.8MB |
| SqueezeNet + 简单旁路连接 | 60.4% | 82.5% | 4.8MB |
| SqueezeNet + 复杂旁路连接 | 58.8% | 82.0% | 7.7MB |
第3节 卷积神经网络模型 ShuffleNet
3.1 ShuffleNet 简介
-
ShuffleNet 提出了 1\times11×1 分组卷积 + 通道混洗 的策略,在保证准确率的同时大幅降低计算成本
-
ShuffleNet 专为 计算能力有限 的设备(10~150MFLOPs)设计。在基于 ARM 的移动设备上,ShuffleNet 与AlexNet 相比,在保持相当的准确率的同时,大约 13 倍 的加速
3.2 ShuffleNetV1 Block
在 Xception 和ResNeXt 中,有大量的 1\times11×1 卷积,所以整体而言 1\times11×1 卷积的计算开销较大。ResNeXt 的每个残差块中,1\times11×1 卷积占据了乘加运算的 93.4% (基数为32时), 在小型网络中,为了满足计算性能的约束 (因为计算资源不够) 需要控制计算量。虽然限制通道数量可以降低计算量,但这也可能会严重降低准确率
解决办法是对 1\times11×1 卷积应用分组卷积,将每个 1\times11×1 卷积仅仅在相应的通道分组上操作,这样就可以降低每个 1\times11×1 卷积的计算代价
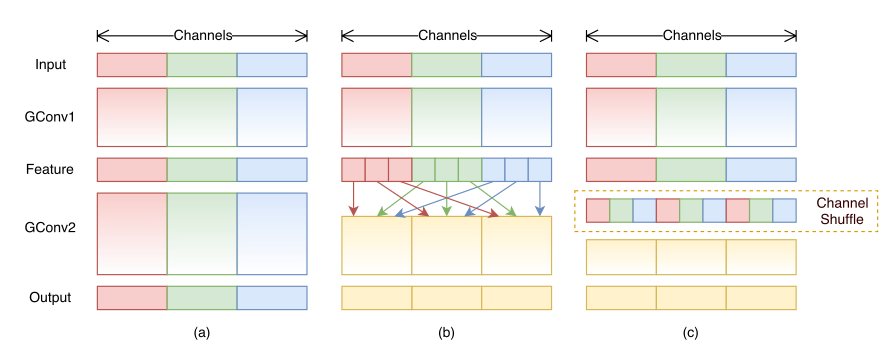
1\times11×1 卷积仅在相应的通道分组上操作会带来一个副作用, 每个通道的输出仅仅与该通道所在分组的输入(一般占总输入的比例较小)有关,与其它分组的输入(一般占总输入的比例较大)无关。这会阻止通道之间的信息流动,降低网络的表达能力
解决办法是采用通道混洗,允许分组卷积从不同分组中获取输入。由于通道混洗是可微的,因此它可以嵌入到网络中以进行端到端的训练
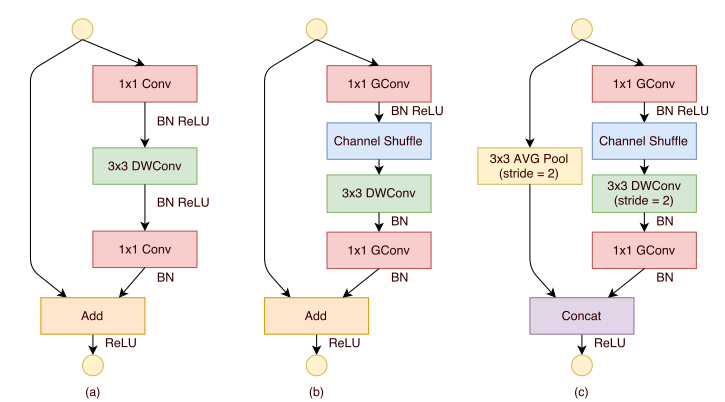
ShuffleNet 块的结构从 ResNeXt 块改进而来
-
第一个 1\times11×1 卷积替换为 1\times11×1 分组卷积+通道随机混洗
-
第二个 1\times11×1 卷积替换为 1\times11×1 分组卷积,但是并没有附加通道随机混洗。这是为了简单起见,因为不附加通道随机混洗已经有了很好的结果
-
在 3\times33×3 depthwise 卷积之后只有 BN 而没有 ReLU
-
当步长为2时
- 恒等映射直连替换为一个尺寸为 3x3 、步长为 2 的平均池化
- 3x3 depthwise 卷积的步长为 2
- 将残差部分与直连部分的 feature map 拼接,而不是相加, 因为当 feature map 减半时,为了缓解信息丢失需要将输出通道数加倍从而保持模型的有效容量
(a) 表示没有通道混洗的分组卷积;(b) 表示进行通道混洗的分组卷积;© 为(b) 的等效表示
3.3 ShuffleNetV2 Block
ShuffleNet V1 block 的分组卷积 违反准则二, 1\times11×1 卷积 违反准则一,旁路连接的元素级加法 违反准则四。而ShuffleNet V2 block 修正了这些违背的地方, 在 ShuffleNet V1 block 的基础上修改
-
步长为1 时,ShuffleNet V2 block 首先将输入 feature map 沿着通道进行拆分。设输入通道数为 C_ICI ,则拆分为 C''_ICI′′ 和 C_I - C''_ICI−CI′′
-
根据准则一,右路的三个卷积操作都保持通道数不变
-
根据准则二,右路的两个 1\times11×1 卷积不再是分组卷积,而是标准的卷积操作。因为分组已经由通道拆分操作执行了
-
根据准则三,左路分支保持不变,右路分支执行各种卷积操作
-
根据准则四,左右两路的featuremap 不再执行相加,而是执行特征拼接
-
-
步长为2时,ShuffleNet V2 block 不再拆分通道,因为通道数量需要翻倍从而保证模型的有效容量
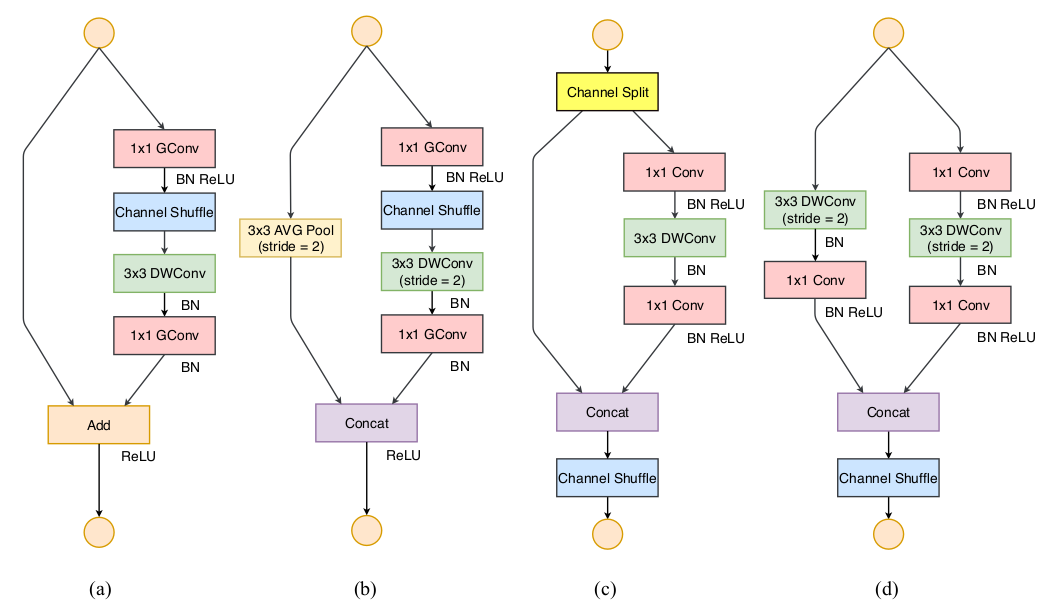
(a),(b) 表示ShuffleNet V1 block (步长分别为1、2),©,(d) 表示ShuffleNet V2 block (步长分别为1、2)。其中GConv 表示分组卷积,DWConv 表示depthwise 卷积
3.4 ShuffleNetV2 模型性能
ShuffleNet V2 的网络结构类似 ShuffleNet V1,主要有两个不同
- 用 ShuffleNet v2 block 代替 ShuffleNet v1 block
- 在 Global Pool 之前加入一个 1\times11×1 卷积
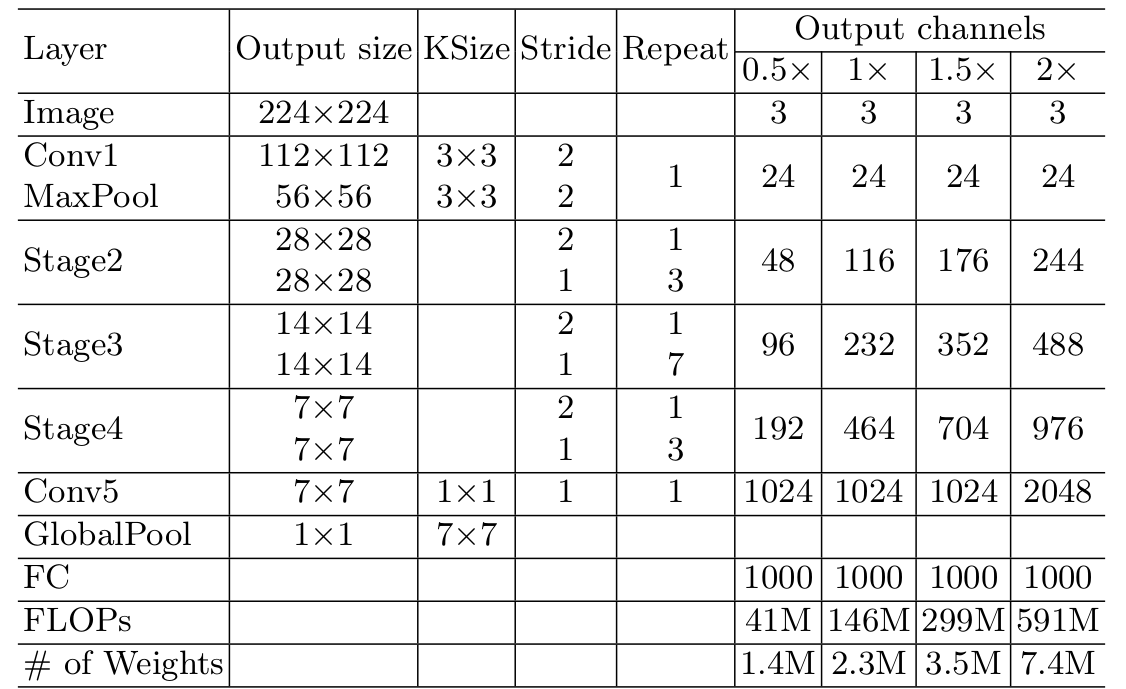
ShuffleNet V2 可以结合 SENet 的思想,也可以增加层数从而由小网络变身为大网络, 下表为几个模型在 ImageNet 验证集上的表现 (single-crop)

3.5 ShuffleNetV2 PyTorch
# %load shuffle.py import math import torch import torch.nn as nn def channel_shuffle(x, groups): N,C,H,W = x.size() return x.view(N,groups,int(C/groups),H,W).transpose(1,2).contiguous().view(N,-1,H,W) class InvertedResidual(nn.Module): def __init__(self,input_features,output_features,stride): super(InvertedResidual, self).__init__() branch_features = output_features//2 self.stride = stride self.branch1 = nn.Sequential() if stride > 1: self.branch1 = nn.Sequential( nn.Conv2d(input_features, input_features, kernel_size=3, stride=stride, padding=1, bias=False, groups=input_features), nn.BatchNorm2d(input_features), nn.Conv2d(input_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(branch_features), nn.ReLU(inplace=True), ) self.branch2 = nn.Sequential( nn.Conv2d(input_features if (stride > 1) else branch_features,branch_features, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(branch_features), nn.ReLU(inplace=True), nn.Conv2d(branch_features, branch_features, kernel_size=3, stride=stride, padding=1, bias=False, groups=branch_features), nn.BatchNorm2d(branch_features), nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(branch_features), nn.ReLU(inplace=True), ) def forward(self, x): if self.stride == 1: x1, x2 = x.chunk(2, 1) out = torch.cat((x1, self.branch2(x2)), 1) else: out = torch.cat((self.branch1(x), self.branch2(x)), 1) out = channel_shuffle(out, 2) return out class ShuffleNetV2(nn.Module): def __init__(self,num_classes=1000): super(ShuffleNetV2, self).__init__() self.input_channels = 24 self.conv1 = nn.Sequential( nn.Conv2d(3, self.input_channels, 3, 2, 1, bias=False), nn.BatchNorm2d(self.input_channels), nn.ReLU(inplace=True), ) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.stage2 = self._make_layer(116,4) self.stage3 = self._make_layer(232,8) self.stage4 = self._make_layer(464,4) self.conv5 = nn.Sequential( nn.Conv2d(self.input_channels, 1024, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(1024), nn.ReLU(inplace=True), ) self.fc = nn.Linear(1024, num_classes) def _make_layer(self, output_channels,num_blocks): layers = [] layers.append(InvertedResidual(self.input_channels,output_channels,2)) for i in range(num_blocks-1): layers.append(InvertedResidual(output_channels,output_channels,1)) self.input_channels = output_channels return nn.Sequential(*layers) def forward(self,x): x = self.conv1(x) x = self.maxpool(x) x = self.stage2(x) x = self.stage3(x) x = self.stage4(x) x = self.conv5(x) x = x.mean([2, 3]) x = self.fc(x) return x def build_shufflev2(phase,num_classes,pretrained): if phase != "test" and phase != "train": print("ERROR: Phase: " + phase + " not recognized") return if not pretrained: model = ShuffleNetV2(num_classes=num_classes) else: model = ShuffleNetV2() model_weights_path = 'weights/shufflenetv2_x1-5666bf0f80.pth.pth' model.load_state_dict(torch.load(model_weights_path), strict=False) for parma in model.parameters(): parma.requires_grad = False ratio = int(math.sqrt(1024/num_classes)) floor = math.floor(math.log2(ratio)) hidden_size = int(math.pow(2,10-floor)) model.fc = nn.Sequential(nn.Linear(1024, hidden_size), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(hidden_size, num_classes) ) return model
net = build_shufflev2('train',10,False) net.cuda() summary(net,(3,224,224))
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 24, 112, 112] 648BatchNorm2d-2 [-1, 24, 112, 112] 48ReLU-3 [-1, 24, 112, 112] 0MaxPool2d-4 [-1, 24, 56, 56] 0Conv2d-5 [-1, 24, 28, 28] 216BatchNorm2d-6 [-1, 24, 28, 28] 48Conv2d-7 [-1, 58, 28, 28] 1,392BatchNorm2d-8 [-1, 58, 28, 28] 116ReLU-9 [-1, 58, 28, 28] 0Conv2d-10 [-1, 58, 56, 56] 1,392BatchNorm2d-11 [-1, 58, 56, 56] 116ReLU-12 [-1, 58, 56, 56] 0Conv2d-13 [-1, 58, 28, 28] 522BatchNorm2d-14 [-1, 58, 28, 28] 116Conv2d-15 [-1, 58, 28, 28] 3,364BatchNorm2d-16 [-1, 58, 28, 28] 116ReLU-17 [-1, 58, 28, 28] 0InvertedResidual-18 [-1, 116, 28, 28] 0Conv2d-19 [-1, 58, 28, 28] 3,364BatchNorm2d-20 [-1, 58, 28, 28] 116ReLU-21 [-1, 58, 28, 28] 0Conv2d-22 [-1, 58, 28, 28] 522BatchNorm2d-23 [-1, 58, 28, 28] 116Conv2d-24 [-1, 58, 28, 28] 3,364BatchNorm2d-25 [-1, 58, 28, 28] 116ReLU-26 [-1, 58, 28, 28] 0InvertedResidual-27 [-1, 116, 28, 28] 0Conv2d-28 [-1, 58, 28, 28] 3,364BatchNorm2d-29 [-1, 58, 28, 28] 116ReLU-30 [-1, 58, 28, 28] 0Conv2d-31 [-1, 58, 28, 28] 522BatchNorm2d-32 [-1, 58, 28, 28] 116Conv2d-33 [-1, 58, 28, 28] 3,364BatchNorm2d-34 [-1, 58, 28, 28] 116ReLU-35 [-1, 58, 28, 28] 0InvertedResidual-36 [-1, 116, 28, 28] 0Conv2d-37 [-1, 58, 28, 28] 3,364BatchNorm2d-38 [-1, 58, 28, 28] 116ReLU-39 [-1, 58, 28, 28] 0Conv2d-40 [-1, 58, 28, 28] 522BatchNorm2d-41 [-1, 58, 28, 28] 116Conv2d-42 [-1, 58, 28, 28] 3,364BatchNorm2d-43 [-1, 58, 28, 28] 116ReLU-44 [-1, 58, 28, 28] 0InvertedResidual-45 [-1, 116, 28, 28] 0Conv2d-46 [-1, 116, 14, 14] 1,044BatchNorm2d-47 [-1, 116, 14, 14] 232Conv2d-48 [-1, 116, 14, 14] 13,456BatchNorm2d-49 [-1, 116, 14, 14] 232ReLU-50 [-1, 116, 14, 14] 0Conv2d-51 [-1, 116, 28, 28] 13,456BatchNorm2d-52 [-1, 116, 28, 28] 232ReLU-53 [-1, 116, 28, 28] 0Conv2d-54 [-1, 116, 14, 14] 1,044BatchNorm2d-55 [-1, 116, 14, 14] 232Conv2d-56 [-1, 116, 14, 14] 13,456BatchNorm2d-57 [-1, 116, 14, 14] 232ReLU-58 [-1, 116, 14, 14] 0InvertedResidual-59 [-1, 232, 14, 14] 0Conv2d-60 [-1, 116, 14, 14] 13,456BatchNorm2d-61 [-1, 116, 14, 14] 232ReLU-62 [-1, 116, 14, 14] 0Conv2d-63 [-1, 116, 14, 14] 1,044BatchNorm2d-64 [-1, 116, 14, 14] 232Conv2d-65 [-1, 116, 14, 14] 13,456BatchNorm2d-66 [-1, 116, 14, 14] 232ReLU-67 [-1, 116, 14, 14] 0InvertedResidual-68 [-1, 232, 14, 14] 0Conv2d-69 [-1, 116, 14, 14] 13,456BatchNorm2d-70 [-1, 116, 14, 14] 232ReLU-71 [-1, 116, 14, 14] 0Conv2d-72 [-1, 116, 14, 14] 1,044BatchNorm2d-73 [-1, 116, 14, 14] 232Conv2d-74 [-1, 116, 14, 14] 13,456BatchNorm2d-75 [-1, 116, 14, 14] 232ReLU-76 [-1, 116, 14, 14] 0InvertedResidual-77 [-1, 232, 14, 14] 0Conv2d-78 [-1, 116, 14, 14] 13,456BatchNorm2d-79 [-1, 116, 14, 14] 232ReLU-80 [-1, 116, 14, 14] 0Conv2d-81 [-1, 116, 14, 14] 1,044BatchNorm2d-82 [-1, 116, 14, 14] 232Conv2d-83 [-1, 116, 14, 14] 13,456BatchNorm2d-84 [-1, 116, 14, 14] 232ReLU-85 [-1, 116, 14, 14] 0InvertedResidual-86 [-1, 232, 14, 14] 0Conv2d-87 [-1, 116, 14, 14] 13,456BatchNorm2d-88 [-1, 116, 14, 14] 232ReLU-89 [-1, 116, 14, 14] 0Conv2d-90 [-1, 116, 14, 14] 1,044BatchNorm2d-91 [-1, 116, 14, 14] 232Conv2d-92 [-1, 116, 14, 14] 13,456BatchNorm2d-93 [-1, 116, 14, 14] 232ReLU-94 [-1, 116, 14, 14] 0InvertedResidual-95 [-1, 232, 14, 14] 0Conv2d-96 [-1, 116, 14, 14] 13,456BatchNorm2d-97 [-1, 116, 14, 14] 232ReLU-98 [-1, 116, 14, 14] 0Conv2d-99 [-1, 116, 14, 14] 1,044BatchNorm2d-100 [-1, 116, 14, 14] 232Conv2d-101 [-1, 116, 14, 14] 13,456BatchNorm2d-102 [-1, 116, 14, 14] 232ReLU-103 [-1, 116, 14, 14] 0
InvertedResidual-104 [-1, 232, 14, 14] 0Conv2d-105 [-1, 116, 14, 14] 13,456BatchNorm2d-106 [-1, 116, 14, 14] 232ReLU-107 [-1, 116, 14, 14] 0Conv2d-108 [-1, 116, 14, 14] 1,044BatchNorm2d-109 [-1, 116, 14, 14] 232Conv2d-110 [-1, 116, 14, 14] 13,456BatchNorm2d-111 [-1, 116, 14, 14] 232ReLU-112 [-1, 116, 14, 14] 0
InvertedResidual-113 [-1, 232, 14, 14] 0Conv2d-114 [-1, 116, 14, 14] 13,456BatchNorm2d-115 [-1, 116, 14, 14] 232ReLU-116 [-1, 116, 14, 14] 0Conv2d-117 [-1, 116, 14, 14] 1,044BatchNorm2d-118 [-1, 116, 14, 14] 232Conv2d-119 [-1, 116, 14, 14] 13,456BatchNorm2d-120 [-1, 116, 14, 14] 232ReLU-121 [-1, 116, 14, 14] 0
InvertedResidual-122 [-1, 232, 14, 14] 0Conv2d-123 [-1, 232, 7, 7] 2,088BatchNorm2d-124 [-1, 232, 7, 7] 464Conv2d-125 [-1, 232, 7, 7] 53,824BatchNorm2d-126 [-1, 232, 7, 7] 464ReLU-127 [-1, 232, 7, 7] 0Conv2d-128 [-1, 232, 14, 14] 53,824BatchNorm2d-129 [-1, 232, 14, 14] 464ReLU-130 [-1, 232, 14, 14] 0Conv2d-131 [-1, 232, 7, 7] 2,088BatchNorm2d-132 [-1, 232, 7, 7] 464Conv2d-133 [-1, 232, 7, 7] 53,824BatchNorm2d-134 [-1, 232, 7, 7] 464ReLU-135 [-1, 232, 7, 7] 0
InvertedResidual-136 [-1, 464, 7, 7] 0Conv2d-137 [-1, 232, 7, 7] 53,824BatchNorm2d-138 [-1, 232, 7, 7] 464ReLU-139 [-1, 232, 7, 7] 0Conv2d-140 [-1, 232, 7, 7] 2,088BatchNorm2d-141 [-1, 232, 7, 7] 464Conv2d-142 [-1, 232, 7, 7] 53,824BatchNorm2d-143 [-1, 232, 7, 7] 464ReLU-144 [-1, 232, 7, 7] 0
InvertedResidual-145 [-1, 464, 7, 7] 0Conv2d-146 [-1, 232, 7, 7] 53,824BatchNorm2d-147 [-1, 232, 7, 7] 464ReLU-148 [-1, 232, 7, 7] 0Conv2d-149 [-1, 232, 7, 7] 2,088BatchNorm2d-150 [-1, 232, 7, 7] 464Conv2d-151 [-1, 232, 7, 7] 53,824BatchNorm2d-152 [-1, 232, 7, 7] 464ReLU-153 [-1, 232, 7, 7] 0
InvertedResidual-154 [-1, 464, 7, 7] 0Conv2d-155 [-1, 232, 7, 7] 53,824BatchNorm2d-156 [-1, 232, 7, 7] 464ReLU-157 [-1, 232, 7, 7] 0Conv2d-158 [-1, 232, 7, 7] 2,088BatchNorm2d-159 [-1, 232, 7, 7] 464Conv2d-160 [-1, 232, 7, 7] 53,824BatchNorm2d-161 [-1, 232, 7, 7] 464ReLU-162 [-1, 232, 7, 7] 0
InvertedResidual-163 [-1, 464, 7, 7] 0Conv2d-164 [-1, 1024, 7, 7] 475,136BatchNorm2d-165 [-1, 1024, 7, 7] 2,048ReLU-166 [-1, 1024, 7, 7] 0Linear-167 [-1, 10] 10,250
================================================================
Total params: 1,263,854
Trainable params: 1,263,854
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 47.93
Params size (MB): 4.82
Estimated Total Size (MB): 53.32
----------------------------------------------------------------
第4节 PyTorch 实践
4.1 模型训练代码
加载同级目录下 train.py 程序代码
# %load train.py import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import time import argparse import sys import torch import torch.nn as nn import torch.optim as optim import torch.backends.cudnn as cudnn from torchvision import datasets, transforms from torch.autograd import Variable import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from shuffle import build_shufflev2 from squeeze import build_squeeze from datasets.config import * from datasets.cifar import CIFAR10 from datasets.flower import shuffle_flower from datasets.oxford_iiit import shuffle_oxford def str2bool(v): return v.lower() in ("yes", "true", "t", "1") parser = argparse.ArgumentParser( description='Image Classification Training With Pytorch') train_set = parser.add_mutually_exclusive_group() parser.add_argument('--dataset', default='Flower', choices=['Flower', 'Oxford-IIIT', 'CIFAR-10'], type=str, help='Flower, Oxford-IIIT, CIFAR-10') parser.add_argument('--dataset_root', default=FLOWER_ROOT, help='Dataset root directory path') parser.add_argument('--model', default='SqueezeNet', choices=['SqueezeNet', 'ShuffleNet'], type=str, help='SqueezeNet or ShuffleNet') parser.add_argument('--pretrained', default=True, type=str2bool, help='Using pretrained model weights') parser.add_argument('--crop_size', default=224, type=int, help='Resized crop value') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--epoch_size', default=20, type=int, help='Number of Epoches for training') parser.add_argument('--cuda', default=True, type=str2bool, help='Use CUDA to train model') parser.add_argument('--shuffle', default=False, type=str2bool, help='Shuffle new train and test folders') parser.add_argument('--lr', '--learning-rate', default=2e-4, type=float, help='initial learning rate') parser.add_argument('--save_folder', default='weights/', help='Directory for saving checkpoint models') parser.add_argument('--photo_folder', default='results/', help='Directory for saving photos') args = parser.parse_args() if not os.path.exists(args.save_folder): os.mkdir(args.save_folder) if not os.path.exists(args.photo_folder): os.mkdir(args.photo_folder) data_transform = transforms.Compose([transforms.RandomResizedCrop(args.crop_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) def train(): if args.dataset == 'Flower': if not os.path.exists(FLOWER_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = FLOWER_ROOT train_path = os.path.join(FLOWER_ROOT, 'train') if not os.path.exists(train_path) or args.shuffle: shuffle_flower() dataset = datasets.ImageFolder(root=train_path,transform=data_transform) if args.dataset == 'Oxford-IIIT': if not os.path.exists(OXFORD_IIIT_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = OXFORD_IIIT_ROOT train_path = os.path.join(OXFORD_IIIT_ROOT, 'train') if not os.path.exists(train_path) or args.shuffle: shuffle_oxford() dataset = datasets.ImageFolder(root=train_path,transform=data_transform) if args.dataset == 'CIFAR-10': if not os.path.exists(CIFAR_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = CIFAR_ROOT dataset = CIFAR10(train=True,transform=data_transform,target_transform=None) classes = dataset.classes if args.model == 'SqueezeNet': net = build_squeeze(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.model == 'ShuffleNet': net = build_shufflev2(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.cuda and torch.cuda.is_available(): net = torch.nn.DataParallel(net) cudnn.benchmark = True net.cuda() optimizer = optim.Adam(net.parameters(), lr=args.lr) criterion = nn.CrossEntropyLoss() epoch_size = args.epoch_size print('Loading the dataset...') data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) print('Training on:', args.dataset) print('Using model:', args.model) print('Using the specified args:') print(args) loss_list = [] acc_list = [] for epoch in range(epoch_size): net.train() train_loss = 0.0 correct = 0 total = len(dataset) t0 = time.perf_counter() for step, data in enumerate(data_loader, start=0): images, labels = data if args.cuda: images = Variable(images.cuda()) labels = Variable(labels.cuda()) else: images = Variable(images) labels = Variable(labels) # forward outputs = net(images) # backprop optimizer.zero_grad() loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics train_loss += loss.item() _, predicted = outputs.max(1) correct += predicted.eq(labels).sum().item() # print train process rate = (step + 1) / len(data_loader) a = "*" * int(rate * 50) b = "." * int((1 - rate) * 50) print("\rEpoch {}: {:^3.0f}%[{}->{}]{:.3f}".format(epoch+1, int(rate * 100), a, b, loss), end="") print(' Running time: %.3f' % (time.perf_counter() - t0)) acc = 100.*correct/ total loss = train_loss / step print('train loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) loss_list.append(loss) acc_list.append(acc/100) torch.save(net.state_dict(),args.save_folder + args.dataset + "_" + args.model + '.pth') plt.plot(range(epoch_size), loss_list, range(epoch_size), acc_list) plt.xlabel('Epoches') plt.ylabel('Sparse CrossEntropy Loss | Accuracy') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), args.photo_folder, args.dataset + "_" + args.model + "_train_details.png")) if __name__ == '__main__': train()
- dataset:
训练采用的数据集,目前提供 Flower, Oxford-IIIT, CIFAR-10 供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- model:
训练使用的算法模型,目前提供 SqueezeNet, ShuffleNet 等卷积神经网络
- pretrained:
是否使用 PyTorch 预训练权重
- crop_size:
数据图像预处理剪裁大小,default为224,只有 LeNet 默认使用 32\times3232×32 尺寸大小
- shuffle:
是否重新生成新的train-test数据集样本
- batch_size:
单次训练所抓取的数据样本数量,default为32
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- epoch_size:
训练次数, default为20
- cuda:
是否调用GPU训练
- lr:
超参数学习率,采用Adam优化函数,default为 0.0020.002
- save_folder:
模型权重保存地址
- 训练细节
print 于 python console, 包括单个epoch训练时间、训练集损失值、准确率
- 模型权重
模型保存路径为 ./weight/{dataset}_{model}.pth
- 损失函数与正确率
图片保存路径为 ./result/{dataset}_{model}_train_details.png
4.2 模型测试代码
加载同级目录下 test.py 程序代码
# %load test.py import sys import os os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" import argparse import torch import torch.nn as nn import torch.backends.cudnn as cudnn from torchvision import transforms, datasets from torch.autograd import Variable import itertools import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt mpl.rc('axes', labelsize = 14) mpl.rc('xtick', labelsize = 12) mpl.rc('ytick', labelsize = 12) sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))) from shuffle import build_shufflev2 from squeeze import build_squeeze from datasets.config import * from datasets.cifar import CIFAR10 parser = argparse.ArgumentParser( description='Convolutional Neural Network Testing With Pytorch') parser.add_argument('--dataset', default='Flower', choices=['Flower', 'Oxford-IIIT', 'CIFAR-10'], type=str, help='Flower, Oxford-IIIT, or CIFAR-10') parser.add_argument('--dataset_root', default=FLOWER_ROOT, help='Dataset root directory path') parser.add_argument('--model', default='SqueezeNet', choices=['SqueezeNet', 'ShuffleNet'], type=str, help='SqueezeNet or ShuffleNet') parser.add_argument('--crop_size', default=224, type=int, help='Resized crop value') parser.add_argument('--batch_size', default=32, type=int, help='Batch size for training') parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading') parser.add_argument('--weight', default='weights/{}_{}.pth', type=str, help='Trained state_dict file path to open') parser.add_argument('--cuda', default=True, type=bool, help='Use cuda to train model') parser.add_argument('--pretrained', default=True, type=bool, help='Using pretrained model weights') parser.add_argument('-f', default=None, type=str, help="Dummy arg so we can load in Jupyter Notebooks") args = parser.parse_args() args.weight = args.weight.format(args.dataset,args.model) data_transform = transforms.Compose([transforms.RandomResizedCrop(args.crop_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) def confusion_matrix(preds, labels, conf_matrix): for p, t in zip(preds, labels): conf_matrix[p, t] += 1 return conf_matrix def save_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) plt.colorbar() tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=90) plt.yticks(tick_marks, classes) plt.axis("equal") ax = plt.gca() left, right = plt.xlim() ax.spines['left'].set_position(('data', left)) ax.spines['right'].set_position(('data', right)) for edge_i in ['top', 'bottom', 'right', 'left']: ax.spines[edge_i].set_edgecolor("white") thresh = cm.max() / 2. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): num = '{:.2f}'.format(cm[i, j]) if normalize else int(cm[i, j]) plt.text(j, i, num, verticalalignment='center', horizontalalignment="center", color="white" if num > thresh else "black") plt.ylabel('True label') plt.xlabel('Predicted label') plt.savefig(os.path.join( os.path.dirname( os.path.abspath(__file__)), "results", args.dataset + '_confusion_matrix.png')) def test(): # load data if args.dataset == 'Flower': if not os.path.exists(FLOWER_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = FLOWER_ROOT test_path = os.path.join(FLOWER_ROOT, 'val') if not os.path.exists(test_path): parser.error('Must train models before evaluating') dataset = datasets.ImageFolder(root=test_path,transform=data_transform) if args.dataset == 'Oxford-IIIT': if not os.path.exists(OXFORD_IIIT_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = OXFORD_IIIT_ROOT test_path = os.path.join(OXFORD_IIIT_ROOT, 'val') if not os.path.exists(test_path): parser.error('Must train models before evaluating') dataset = datasets.ImageFolder(root=test_path,transform=data_transform) if args.dataset == 'CIFAR-10': if not os.path.exists(CIFAR_ROOT): parser.error('Must specify dataset_root if specifying dataset') args.dataset_root = CIFAR_ROOT dataset = CIFAR10(train=False,transform=data_transform,target_transform=None) classes = dataset.classes num_classes = len(classes) data_loader = torch.utils.data.DataLoader(dataset, args.batch_size, num_workers=args.num_workers, shuffle=True, pin_memory=True) # load net if args.model == 'SqueezeNet': net = build_squeeze(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.model == 'ShuffleNet': net = build_shufflev2(phase='train', num_classes=len(classes), pretrained=args.pretrained) if args.cuda and torch.cuda.is_available(): net = torch.nn.DataParallel(net) cudnn.benchmark = True net.cuda() net.load_state_dict(torch.load(args.weight)) print('Finish loading model: ', args.weight) net.eval() print('Training on:', args.dataset) print('Using model:', args.model) print('Using the specified args:') print(args) # evaluation criterion = nn.CrossEntropyLoss() test_loss = 0 correct = 0 total = 0 conf_matrix = torch.zeros(num_classes, num_classes) class_correct = list(0 for i in range(num_classes)) class_total = list(0 for i in range(num_classes)) with torch.no_grad(): for step, data in enumerate(data_loader): images, labels = data if args.cuda: images = Variable(images.cuda()) labels = Variable(labels.cuda()) else: images = Variable(images) labels = Variable(labels) # forward outputs = net(images) loss = criterion(outputs, labels) test_loss += loss.item() _, predicted = outputs.max(1) conf_matrix = confusion_matrix(predicted, labels=labels, conf_matrix=conf_matrix) total += labels.size(0) correct += predicted.eq(labels).sum().item() c = (predicted.eq(labels)).squeeze() for i in range(c.size(0)): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 acc = 100.* correct / total loss = test_loss / step print('test loss: %.6f, acc: %.3f%% (%d/%d)' % (loss, acc, correct, total)) for i in range(num_classes): print('accuracy of %s : %.3f%% (%d/%d)' % ( str(classes[i]), 100 * class_correct[i] / class_total[i], class_correct[i], class_total[i])) save_confusion_matrix(conf_matrix.numpy(), classes=classes, normalize=False, title = 'Normalized confusion matrix') if __name__ == '__main__': test()
训练采用的数据集,目前提供 Flower, Oxford-IIIT, CIFAR-10 供选择。 点击查看数据集加载Demo
- dataset_root:
数据集读取地址, default已设置为数据集相对路径,部署在云端可能需要修改
- model:
训练使用的算法模型,目前提供 SqueezeNet, ShuffleNet 等卷积神经网络
- pretrained:
是否使用 PyTorch 预训练权重
- crop_size:
数据图像预处理剪裁大小,default为224,只有 LeNet 默认使用 32\times3232×32 尺寸大小
- shuffle:
单次训练所抓取的数据样本数量,default为32
- num_workers:
加载数据所使用线程个数,default为0,n\in (2,4,8,12\dots)n∈(2,4,8,12…)
- trained_model:
模型权重保存路径,default为 train.py 生成的ptb文件路径
- cuda:
是否调用GPU训练
- 测试集损失值与准确率
print 于 python console 第一行
- 各类别准确率
print 于 python console 后续列表
- 混淆矩阵
图片保存路径为 ./photos/%_confusion_matrix.png
第5节 Flower 数据集
-
Flower 数据集 来自 Tensorflow 团队,创建于 2019 年 1 月,作为 入门级轻量数据集 包含5个花卉类别 [‘daisy’, ‘dandelion’, ‘roses’, ‘sunflowers’, ‘tulips’]
-
Flower 数据集 是深度学习图像分类中经典的一个数据集,各个类别有 [633, 898, 641, 699, 799] 个样本,每个样本都是一张 320\times232320×232 像素的RGB图片
-
Dataset 库中的 flower.py 按照 0.1 的比例实现训练集与测试集的 样本分离
5.1 SqueezeNet
%run train.py --dataset Flower --model SqueezeNet --pretrained True
%run test.py --dataset Flower --model SqueezeNet --pretrained True
5.2 ShuffleNet
%run train.py --dataset Flower --model ShuffleNet --pretrained True
%run test.py --dataset Flower --model ShuffleNet --pretrained True
第6节 Oxford-IIIT 数据集

- Oxford-IIIT 数据集覆盖 30 个种类的猫狗品种,每个类别收集了约 200 张图像样本
- Oxford-IIIT 中每张图像在尺寸、姿势、光暗程度上有很大的浮动,但所有的图像都匹配了相关联的品种、头部框架定位、三维像素点语义分割的标注信息
- Dataset 库中的 oxford_iiit.py 按照 0.1 的比例实现训练集与测试集的 样本分离
6.1 SqueezeNet
%run train.py --dataset Oxford-IIIT --model SqueezeNet --pretrained True
%run test.py --dataset Oxford-IIIT --model SqueezeNet --pretrained True
6.2 ShuffleNet
%run train.py --dataset Oxford-IIIT --model ShuffleNet --pretrained True
%run test.py --dataset Oxford-IIIT --model ShuffleNet --pretrained True
第7节 CIFAR-10 数据集
- CIFAR-10 数据集是 Visual Dictionary (Teaching computers to recognize objects) 的子集,由三个多伦多大学教授收集,主要来自Google和各类搜索引擎的图片
- CIFAR-10 数据集包含 60000 张 32\times3232×32 的RBG彩色图像,共计 10 个 包含 6000 张样本图像的不同类别,训练集包含 50000 张图像样本,测试集包含 10000 张图像样本
- CIFAR-10 数据集在深度学习初期 (ImageNet 问世前) 一直是衡量各种算法模型的 benchmark,但其 32\times3232×32 的图像尺寸逐渐无法满足日渐飞速迭代的神经网络结构
7.1 SqueezeNet
%run train.py --dataset CIFAR-10 --model SqueezeNet --pretrained True
%run test.py --dataset CIFAR-10 --model SqueezeNet --pretrained True
7.2 ShuffleNet
%run train.py --dataset CIFAR-10 --model ShuffleNet --pretrained True
%run test.py --dataset CIFAR-10 --model ShuffleNet --pretrained True
开始实验
这篇关于第06章 移动端微量神经网络模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








