本文主要是介绍如何向NCBI的SRA上传数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先访问SRA的提交界面,https://submit.ncbi.nlm.nih.gov/subs/sra/,在没有登陆NCBI时,网页内容如下所示
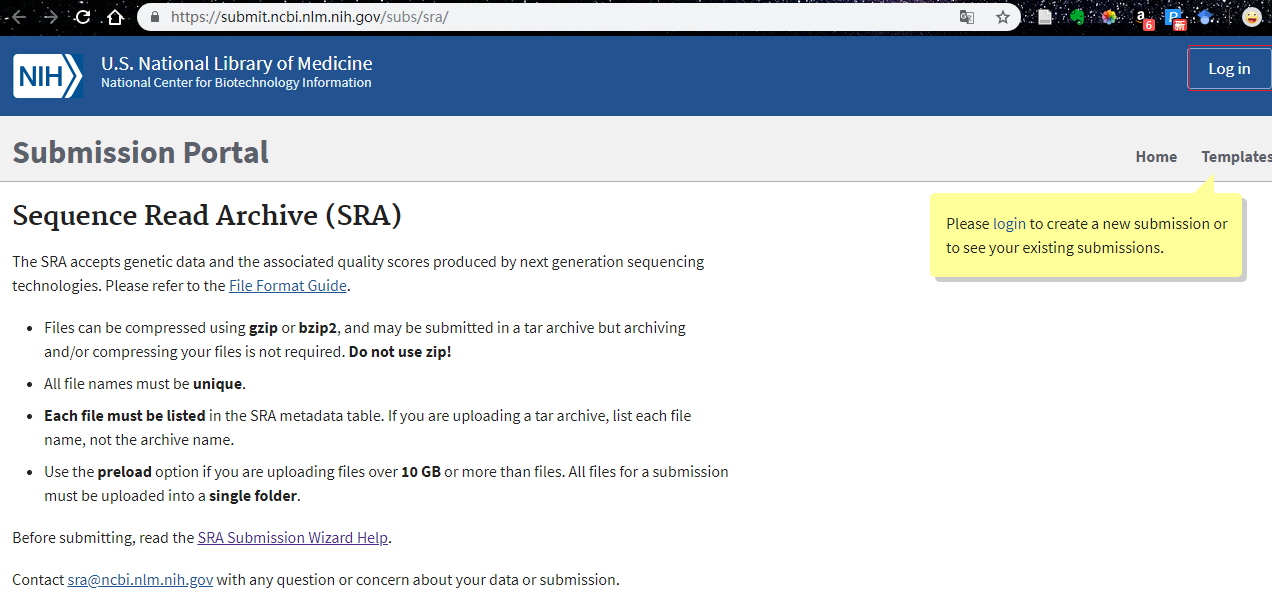
点击Log in, 会进入一个新的网页用于登陆或者创建新的NCBI账户。
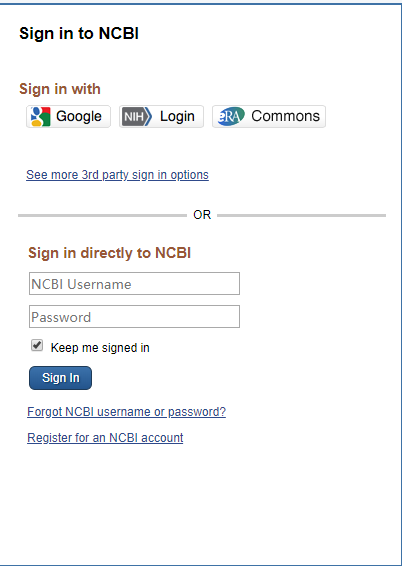
在创建完账号或者登陆之后,返回之前的SRA上传页面,界面就变成了如下。
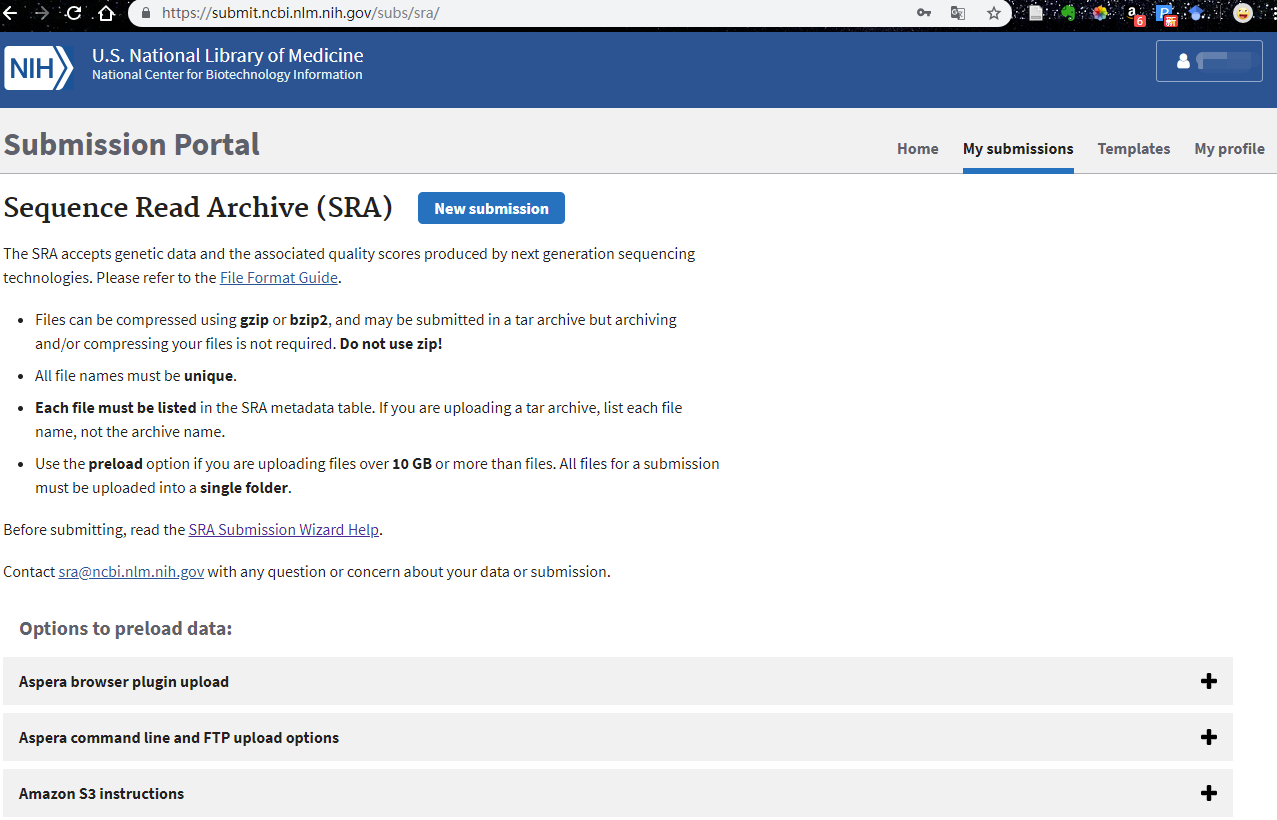
他提示了有三种方法可以递交:
- Aspera浏览器插件
- Aspera命令行和FTP上传
- Amzon S3方式
个人比较喜欢用Aspera命令行的方式(FTP对于国内用户或许有点慢)
在Apeara命令和FPT上传选项中点击如下的蓝色小按钮
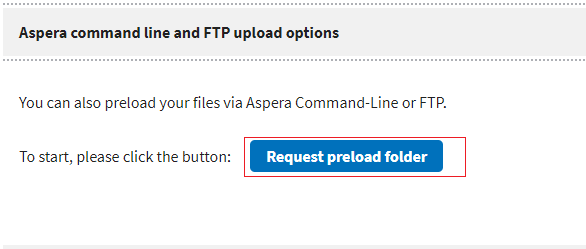
点击之后,页面就会发生变化,跳出每个用户专门的预上传地址,还有专门的上传说明文字。
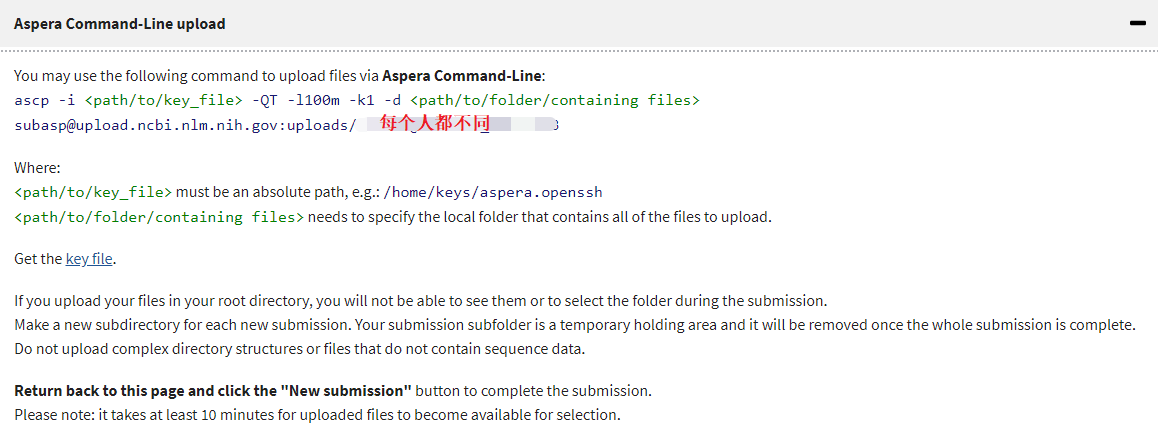
有了地址之后,下一步就是安装Aspera, 在Aspera上选择合适的版本,我装的就是Linux版本。
wget https://download.asperasoft.com/download/sw/connect/3.8.1/ibm-aspera-connect-3.8.1.161274-linux-g2.12-64.tar.gz
tar xf ibm-aspera-connect-3.8.1.161274-linux-g2.12-64.tar.gz
./ibm-aspera-connect-3.8.1.161274-linux-g2.12-64.sh
安装的内容存放在~/.aspera/connect下。所使用到的命令如下
ascp -i <path/to/key_file> -QT -l100m -k1 -d <path/to/folder/containing files> subasp@upload.ncbi.nlm.nih.gov:uploads/每个人都不同
<path/to/key_file>要点击上图中的Get the key file下载,然后上传到服务器上。<path/to/folder/containing files> 是你需要上传的数据的本地路径。
或者你对你自己的FTP速度有足够自信的话,可以尝试用FTP上传,在FTP upload中找到地址、用户名和密码,以及要上传的目录,
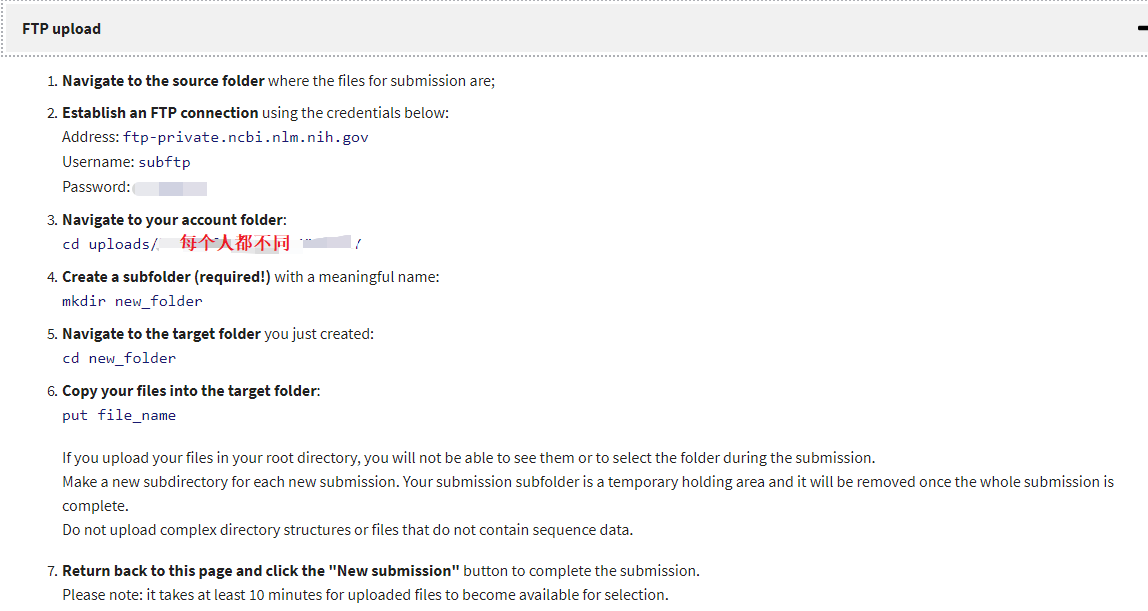
之后就随便找一个图形化的FTP工具上传即可,例如FileZilla
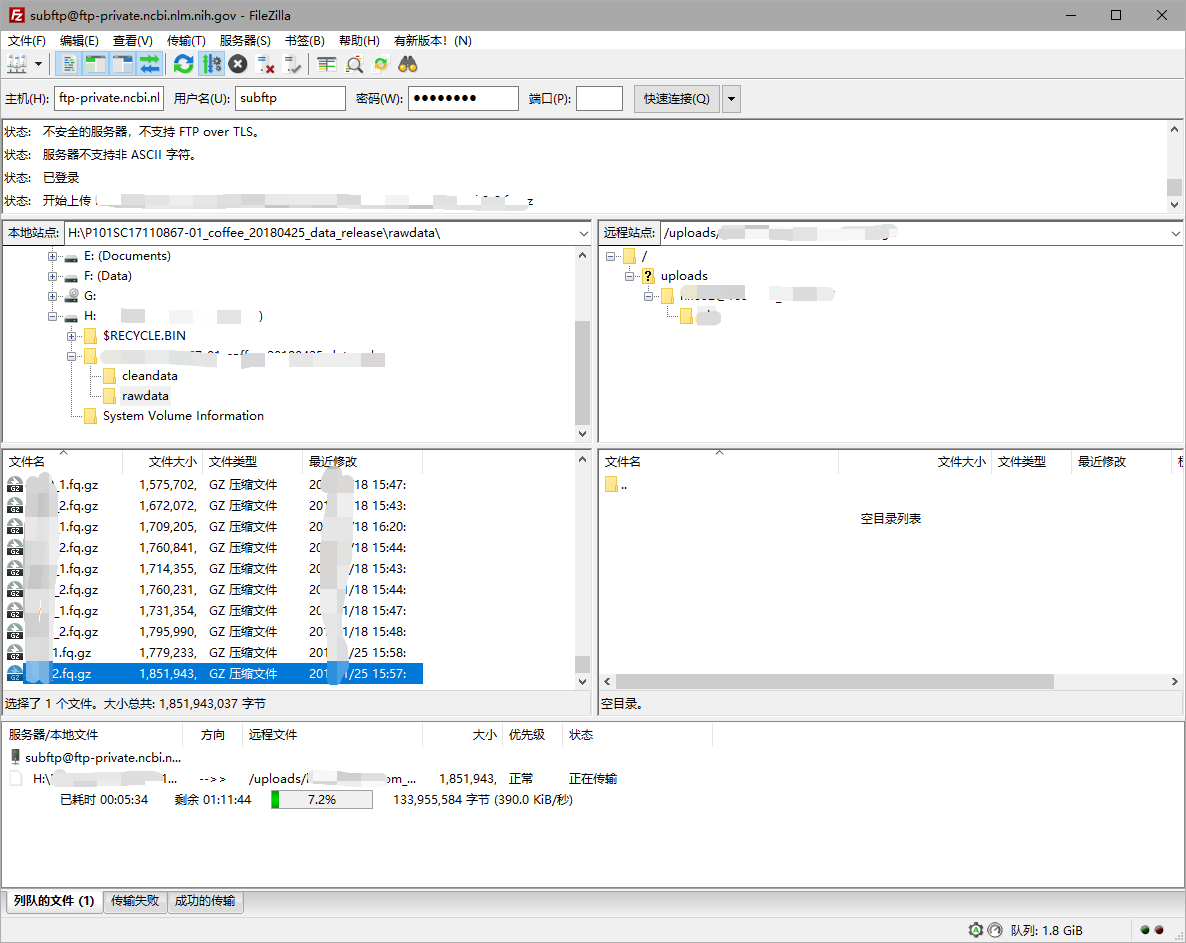
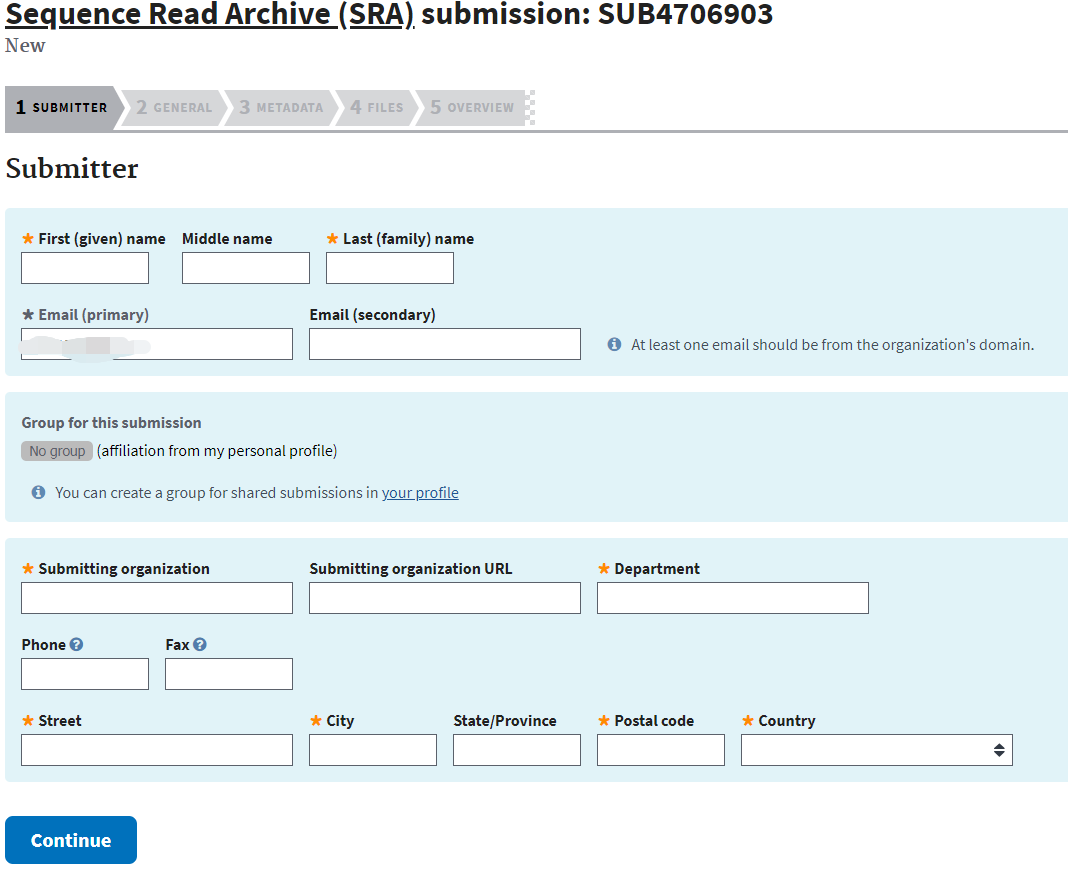
所有数据上传之后,你可以点击页面的New submission创建一个新的上传任务。
然后就是一步一步的填写信息,将你预先上传的数据和你的项目进行关联。这里的SUBXXXX是临时的,完成上传后就自动无效,并且还可以反悔中途取消掉。
这篇关于如何向NCBI的SRA上传数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






