本文主要是介绍041-使用DM进行同步上游数据到 TiDB,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:anjia
原文来源: https://tidb.net/blog/83d843fa
这是坚持技术写作计划(含翻译)的第41篇,定个小目标999,每周最少2篇。
回想一下之前数据同步一般会使用一些ETL工具,例如 DataX , StreamSets , Kettle , sqoop , nifi ,当然也可能使用原始的mysqldump进行人肉苦逼同步。因为每个团队的背景不一样,没法简单的说哪种工具更好,更优,还是需要落地才行。所以本文就不过多介绍不同ETL工具间的优劣了,毕竟PHP是世界上最好的语言。
本文主要讲解,如何使用tidb官方的同步工具DM进行数据同步。先搬运一下tidb官方对dm的简介
DM (Data Migration) 是一体化的数据同步任务管理平台,支持从 MySQL 或 MariaDB 到 TiDB 的全量数据迁移和增量数据同步。使用 DM 工具有利于简化错误处理流程,降低运维成本。
略微吐槽下,tidb的官方技术栈略有点复杂,比如,广义的 TiDB,一般是指 PD, TiDB, TiKV 这类核心组件(参考 TiDB 整体架构 ),但是,部署的话,得用ansible部署,监控呢,得学会看官方提供的 Prometheus+Grafana,同步数据的话,又的看 mydumper , loader , syncer , Data Migration , TiDB Lightning , 管理tidb集群的话,又会用到一些工具,比如,pd control,pd recover,tikv control,tidb controller,如果要给tidb开启binlog,用于同步到其他tidb或者mysql集群,又要研究 Pump,Drainer,binlogctl …
就感觉tidb团队,一看就是出身大户人家,看官方建议的集群配置吧。
- tidb集群最低配置要求
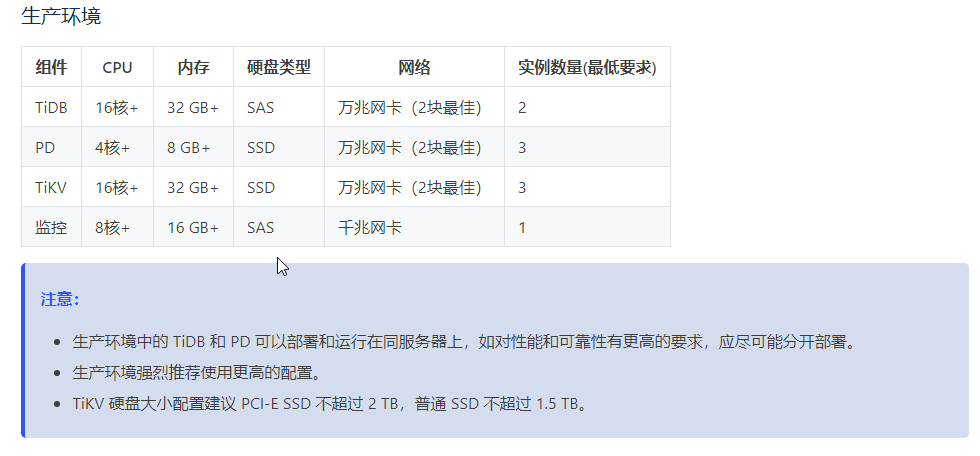
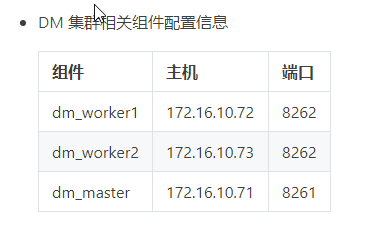
- dm实例配置
- tidb-lighting配置要求(超过200G以上的迁移,建议用tidb-lighting)

- tidb binlog的配置

所以,几乎每一个用tidb的人,第一件事,都是,如何修改ansible的参数,绕过检测 [手动滑稽],人嘛,都是,一边吐槽XX周边工具太少,又会吐槽XX太多,学不动,像是初恋的少女,等远方的男友,怕他乱来,又怕他不来,哈哈
对比一下友商的
其实tidb的官方文档,写的还挺详细的,就是不太像是给入门的人看的 [手动捂脸],本文主要是结合我在使用DM过程中,写一下遇到的问题,以及群内大牛的解答
简介
DM 简化了单独使用mysqldumper,loader,syncer的工作量,从易用性,健壮性和可观测等方面来看,建议使用DM。
注意一下 官方文档 写的限制条件。

部署DM
参考 使用 DM-Ansible 部署 DM 集群
如无特殊说明都按照官方文档操作。
第五步配置互信时,servers 是要部署DM的节点ip,注意当前登录名,确保是tidb(执行 woami )
vi hosts.ini
[servers]
172.16.10.71
172.16.10.72
172.16.10.73[all:vars]
username = tidb
执行 ansible-playbook -i hosts.ini create_users.yml -u root -k 时,如果是使用 ssh key的话,可以 ansible-playbook -i hosts.ini create_users.yml -u root -k --private-key /path/to/your/keyfile
第7步配置worker时,需要注意,如果要增量或者全量,并且上游服务的binlog被删过,并且是gtid格式的,需要执行 show VARIABLES like 'gtid_purged' 如果有值,则需要指定 relay_binlog_gtid ,否则会报 close sync with err: ERROR 1236 (HY000): The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires. 此时停掉worker后,修改 relay_binlog_gtid 重启无效,是需要修改meta文件的 /tidb/deploy/dm_worker_/relay_log/f5df-11e7-a1dd.000001/relay.meta 感谢 军军
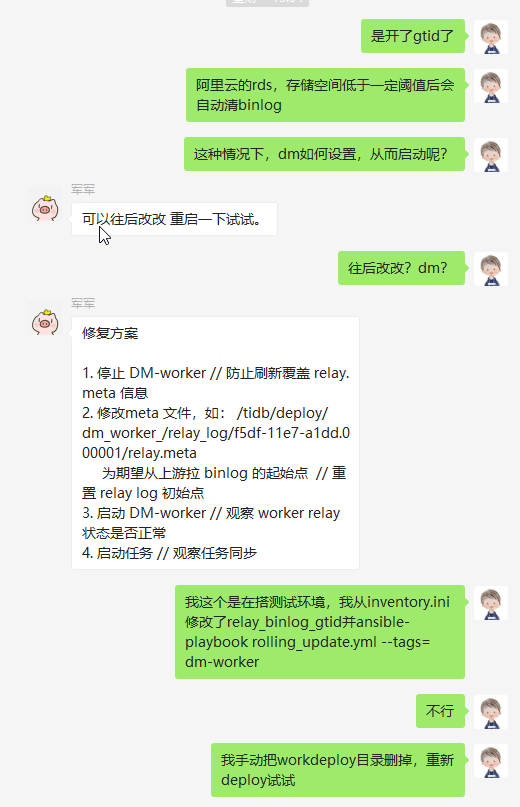
另外需要配置 enable_gtid=true
如果不是gtid格式的,则需要修改这个 relay_binlog_name (在mysql执行 show BINARY logs ) mysql_password 需要使用 dmctl -encrypt 你的密码 如果找不到dmctl,确保执行了 ansible-playbook local_prepare.yml 后在 /path/to/dm-ansible/resources/bin/dmctl
dm的worker支持单机多实例,也支持单机单实例(推荐) ,如果因为资源问题,要开启单机多实例的话,
[dm_worker_servers]
dm_worker1_1 ansible_host=172.16.10.72 server_id=101 deploy_dir=/data1/dm_worker dm_worker_port=8262 mysql_host=172.16.10.81 mysql_user=root mysql_password='VjX8cEeTX+qcvZ3bPaO4h0C80pe/1aU=' mysql_port=3306
dm_worker1_2 ansible_host=172.16.10.72 server_id=102 deploy_dir=/data2/dm_worker dm_worker_port=8263 mysql_host=172.16.10.82 mysql_user=root mysql_password='VjX8cEeTX+qcvZ3bPaO4h0C80pe/1aU=' mysql_port=3306dm_worker2_1 ansible_host=172.16.10.73 server_id=103 deploy_dir=/data1/dm_worker dm_worker_port=8262 mysql_host=172.16.10.83 mysql_user=root mysql_password='VjX8cEeTX+qcvZ3bPaO4h0C80pe/1aU=' mysql_port=3306
dm_worker2_2 ansible_host=172.16.10.73 server_id=104 deploy_dir=/data2/dm_worker dm_worker_port=8263 mysql_host=172.16.10.84 mysql_user=root mysql_password='VjX8cEeTX+qcvZ3bPaO4h0C80pe/1aU=' mysql_port=3306
注意 server_id=101 deploy_dir=/data1/dm_worker dm_worker_port=8262 别冲突,尤其是 deploy_dir 和 dm_worker_port
第九步,如果部署dm的节点数太多,可以提升并发数 ansible-playbook deploy.yml -f 10
第十步,启动 ansible-playbook start.yml
上述是简单操作, 如果涉及到复杂的,例如,扩容,缩容dm节点,重启dm-master或者dm-worker,可以参考 DM 集群操作
配置DM
如何看文档
配置dm-worker的tasks,三段文档结合着看
 一般场景,使用 Data Migration 简单使用场景 即可满足。
一般场景,使用 Data Migration 简单使用场景 即可满足。
库重命名
库重命名,将上游的user,备份成user_north库。另外,不支持实例内databases批量加前缀或者后缀。所以,有多少个需要重命名的,就乖乖写多少个吧
routes:...instance-1-user-rule:schema-pattern: "user"target-schema: "user_north"
忽略库或者表
black-white-list:log-ignored:ignore-dbs: ["log"] # 忽略同步log库ignore-tables:- db-name: "test" # 忽略同步log库内的test表tbl-name: "log"
尽量使用白名单
个人建议尽量使用白名单进行同步,防止因为新增库dm校验不通过,导致task被pause掉。此时的假设是,同步任务是严谨的,不应该出现不可控因素。当然这只是建议。
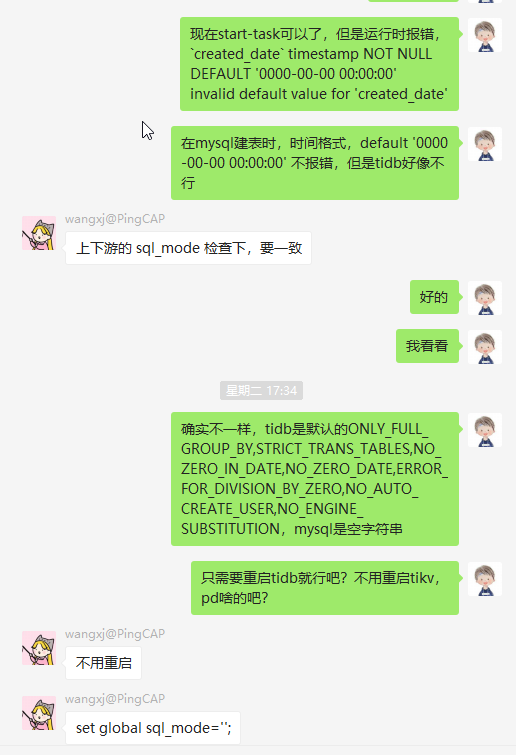
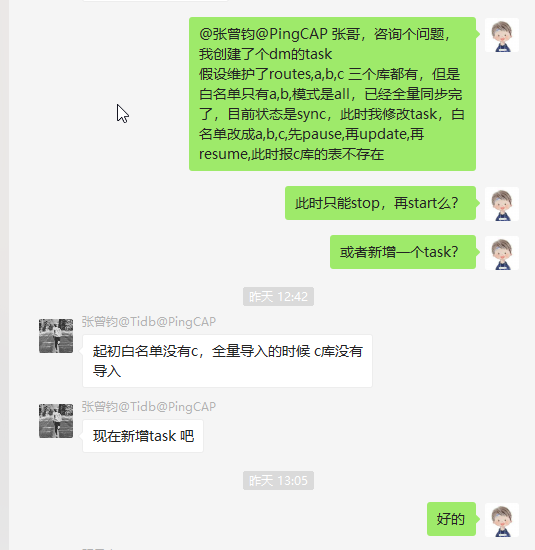
如果 上游数据库有,a,b,c三个库,前期白名单只写了a,b,进行全量+增量同步(all模式),并且task的unit已经是sync(非dump),如果此时要同步库,此时如果只是简单改白名单,然后pause-task,update-task,resume-task,会报表不存在的错。具体的解决办法,可以参见 我在tug上提的问题 https://asktug.com/t/db/616 ,感谢 wangxj @pingCAP
black-white-list:rule-1:do-dbs: ["~^test-*"] 同步所有test-开头的库
忽略drop和truncate操作
毕竟使用DM是用于同步数据,在一定程度上也可以用于灾备场景使用,万一业务库被人drop,truncate了,tidb这还可以救命,所以建议忽略这些危险操作,有必要的,可以人工去执行。
filters:...store-filter-rule:schema-pattern: "store"events: ["drop database", "truncate table", "drop table"]action: Ignore
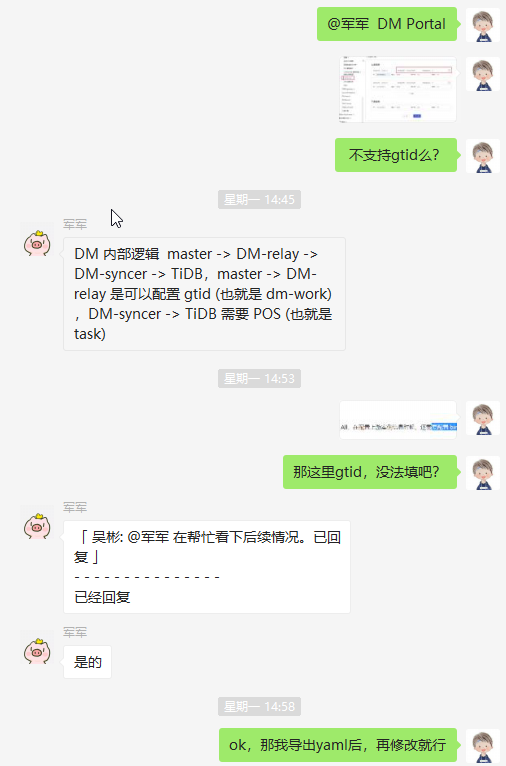
使用DM Portal生成配置文件,但是Portal生成的是不支持gtid的,详见 军军 的解释,详细使用,参见 DM Portal 简介
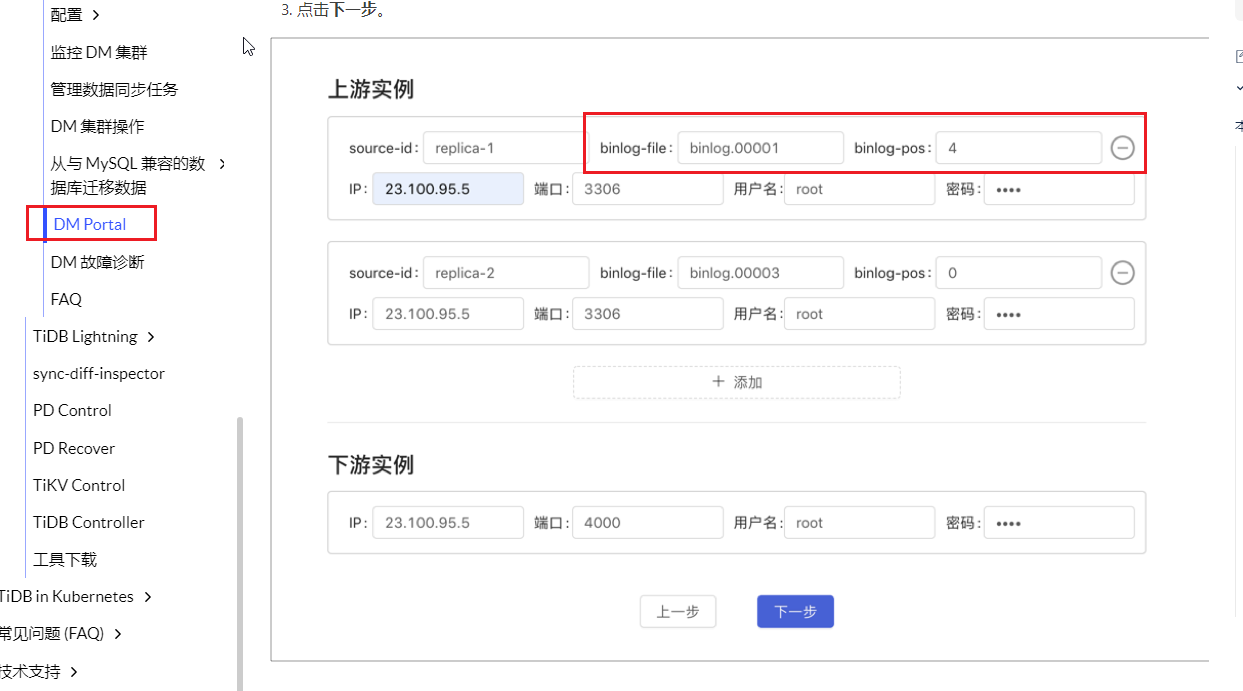
启动DM
常规操作
参考 管理数据同步任务
使用 ./dmctl -master-addr 172.16.30.14 进入交互式命令界面(不支持非交互式的,导致我在使用中遇到,当报错信息特别大时,超过缓冲区,会导致看不到有效的报错信息,check-task xx-task >result.log 这种的不支持,希望后边能改进下 )
- 启动任务
start-task /path/to/task.yaml注意是task文件,而不是任务名 - 查询任务
query-status [task-name]task-name是可选的,不填查所有,填了,只查指定的 - 暂停任务
pause-task task-name,如果要更新task文件(update-task) task一定要处于pause状态(报错导致的pause也行) - 恢复同步
resume-task task-name处于暂停(pause)的任务要恢复,需要使用resume-task ,如果是full或者all时unit处于dump状态的(非load),resume-task时会清空已经dump到本地的文件,重新拉取(想想200多G的数据库,到99%了,突然pause了,就肝儿颤) - 更新同步任务
update-task /path/to/task.yaml注意是task文件,不是任务名,执行更新操作,必须是pause状态,所以,尽量别再dump时执行update,要执行也是在前期执行。执行后,需要使用resume-task启动已pause的任务 - 停止任务
stop-task task-name
常见问题
- check通过,start时报错,或者start也正常,query时报错,这种错,有跟没有区别不大,只能ssh到worker节点,看日志
/path/to/deploy/log/
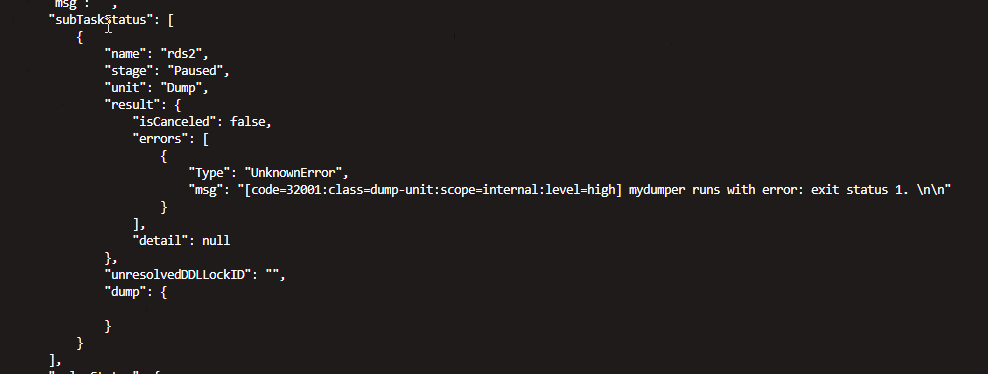
-
Couldn't acquire LOCK BINLOG FOR BACKUP, snapshots will not be consistent:Access denied; you need (at least one of) the SUPER privilege(s) for this operation

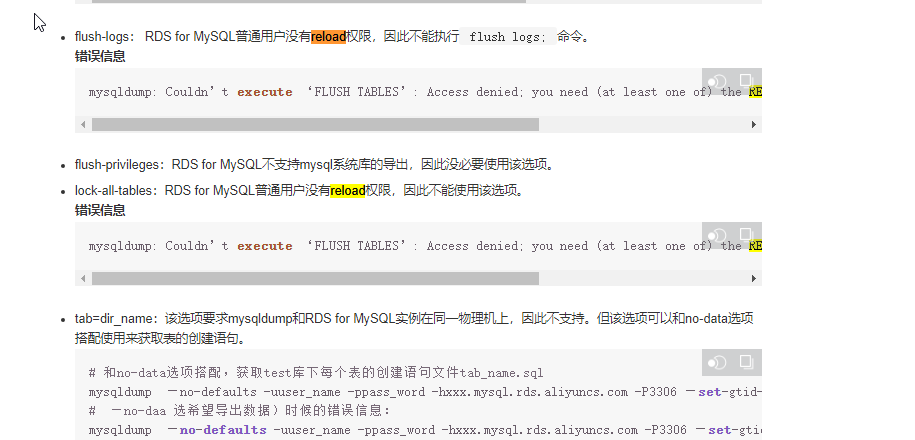
如果没有reload权限,会报错,但是不会终止操作,可以忽略
注意,如果是阿里云的rds的话,默认是把reload权限给去掉的。
- sql-mode 不一致引起的问题,mysql默认的sql-mode是空字符串,参考 SQL 模式 ,排查方式
SELECT @@sql_mode,如果是tidb是新库,可以set global sql_mode='';如果要改mysql的话,需要写到my.ini里,防止重启失效。
- all模式同步数据,如果task状态已经是sync,此时这个task白名单新增库或者表会导致报错,表不存在,然后task被pause。要么使用full-task+incremental-task两个文件,每次白名单新增时,先更新full-task,再更新incremental-task,要么直接新启一个task,用于full更新白名单库,然后改all的task,重启即可。
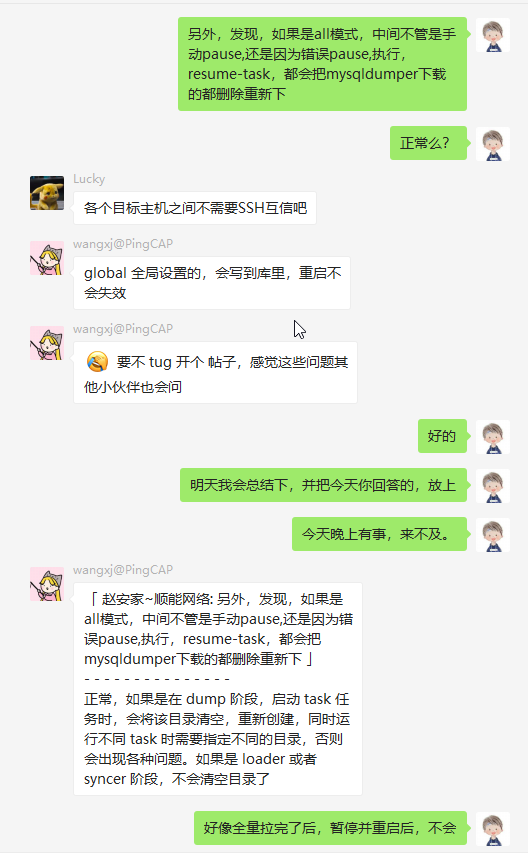
- 处于dump的任务,一旦pause了,再次resume,会删除已dump的数据文件,重新拉取
招聘小广告
山东济南的小伙伴欢迎投简历啊 加入我们 , 一起搞事情。
长期招聘,Java程序员,大数据工程师,运维工程师,前端工程师。
参考资料
- 我的博客
- 我的掘金
- DataX在有赞大数据平台的实践
- Data Migration 常见问题
- 使用 DM-Ansible 部署 DM 集群
这篇关于041-使用DM进行同步上游数据到 TiDB的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







