本文主要是介绍基于V100下Llama2-Atom大模型微调,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 大规模的中文数据预训练
- 模型部署
- 模型微调
- Step1: 环境准备
- Step2: 数据准备
- Step3: 微调脚本
- Step4: 加载微调模型
- 一些BUG
大规模的中文数据预训练
原子大模型Atom在Llama2的基础上,采用大规模的中文数据进行持续预训练,包含百科、书籍、博客、新闻、公告、小说、金融数据、法律数据、医疗数据、代码数据、专业论文数据、中文自然语言处理竞赛数据集等,详见📝 数据来源。
同时对庞大的数据进行了过滤、打分、去重,筛选出超过1T token的高质量中文数据,持续不断加入训练迭代中。
更高效的中文词表
为了提高中文文本处理的效率,我们针对Llama2模型的词表进行了深度优化。首先,我们基于数百G的中文文本,在该模型词表的基础上扩展词库至65,000个单词。经过测试,我们的改进使得中文编码/解码速度提高了约350%。此外,我们还扩大了中文字符集的覆盖范围,包括所有emoji符号😊。这使得生成带有表情符号的文章更加高效。
自适应上下文扩展
Atom大模型默认支持4K上下文,利用位置插值PI和Neural Tangent Kernel (NTK)方法,经过微调可以将上下文长度扩增到32K。
模型部署
基于Llama2的中文预训练模型Atom
社区提供预训练版本Atom-7B和基于Atom-7B进行对话微调的模型参数供开放下载,模型参数会持续不断更新,关于模型的进展详见社区官网llama.family。
模型下载:
类别 模型名称 🤗模型加载名称 下载地址
预训练 Atom-7B FlagAlpha/Atom-7B 模型下载
Chat Atom-7B-Chat FlagAlpha/Atom-7B-Chat 模型下载
github地址:https://github.com/FlagAlpha/Llama2-Chinese
预训练模型调用代码示例
# 预训练模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('FlagAlpha/Atom-7B',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Atom-7B',use_fast=False)
tokenizer.pad_token = tokenizer.eos_tokenwhile True:# element = input("请输入(输入0退出): ")str = input("输入你的问题(输入0退出): ")if str == "0":breakstr = "<s>Human: " + str + "\n</s><s>Assistant: "list = []list = strinput_ids = tokenizer(list, return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')generate_input = {"input_ids":input_ids,"max_new_tokens":512,"do_sample":True,"top_k":50,"top_p":0.95,"temperature":0.3,"repetition_penalty":1.3,"eos_token_id":tokenizer.eos_token_id,"bos_token_id":tokenizer.bos_token_id,"pad_token_id":tokenizer.pad_token_id}generate_ids = model.generate(**generate_input)text = tokenizer.decode(generate_ids[0])print(text)print('\n')
基本的可以回答中文问题,但要提示使用中文才可以回答。
模型微调
本仓库中同时提供了LoRA微调和全量参数微调代码,关于LoRA的详细介绍可以参考论文“LoRA: Low-Rank Adaptation of Large Language Models”以及微软Github仓库LoRA。
本文采用LoRA微调方法
微调代码结构等如下
Step1: 环境准备
根据requirements.txt安装对应的环境依赖。
conda create -n llama2-ch python=3.9
conda activate llama2-ch
安装其他依赖包
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple
pip install -r requirements.txt
验证bitsandbytes
python -m bitsandbytes
部分依赖需要领出来,单独下载安装,服务器可能不支持下载
cuda,toolkit版本对应问题等一定要注意,否则可能会报NCLL,[0],巴拉巴拉问题,导致进程终止
本文使用的是8张V100显卡,128G
Step2: 数据准备
在data目录下提供了一份用于模型sft的数据样例:
训练数据:data/train_sft.csv
验证数据:data/dev_sft.csv
每个csv文件中包含一列“text”,每一行为一个训练样例,每个训练样例按照以下格式将问题和答案组织为模型输入,您可以按照以下格式自定义训练和验证数据集:
"<s>Human: "+问题+"\n</s><s>Assistant: "+答案
例如,
<s>Human: 用一句话描述地球为什么是独一无二的。</s><s>Assistant: 因为地球是目前为止唯
如果使用自己的数据集,可以将json转换成对应的csv格式。
Step3: 微调脚本
全量参数微调
全量参数微调脚本见:train/sft/finetune.sh,关于全量参数微调的具体实现代码见train/sft/finetune_clm.py。
LoRA微调
LoRA微调脚本见:train/sft/finetune_lora.sh,(使用deepspeed进行GPU之间的并行计算)
关于LoRA微调的具体实现代码见train/sft/finetune_clm_lora.py,单机多卡的微调可以通过修改脚本中的–include localhost:0来实现。本文–include localhost:0,1,2,3,4,5,6,7。
output_model=output_mytest
# 需要修改到自己的输入目录if [ ! -d ${output_model} ];thenmkdir ${output_model}
fids --include localhost:0,1,2,3,4,5,6,7 --master_port 9888 finetune_clm_lora.py \--model_name_or_path /FlagAlpha/Atom-7B \--train_files /data/train_3_simple.csv \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--do_train \--do_eval \--use_fast_tokenizer false \--output_dir ${output_model} \--evaluation_strategy steps \--max_eval_samples 800 \--learning_rate 1e-4 \--gradient_accumulation_steps 8 \--num_train_epochs 10 \--warmup_steps 400 \--load_in_bits 4 \--lora_r 8 \--lora_alpha 32 \--target_modules q_proj,k_proj,v_proj,o_proj,down_proj,gate_proj,up_proj \--logging_dir ${output_model}/logs \--logging_strategy steps \--logging_steps 10 \--save_strategy steps \--preprocessing_num_workers 10 \--save_steps 20 \--eval_steps 20 \--save_total_limit 2000 \--seed 42 \--disable_tqdm false \--ddp_find_unused_parameters false \--block_size 2048 \--report_to tensorboard \--overwrite_output_dir \--deepspeed ds_config_zero2.json \--ignore_data_skip true \--fp16 \--gradient_checkpointing \--ddp_timeout 18000000 \Step4: 加载微调模型
LoRA微调
基于LoRA微调的模型参数见:基于Llama2的中文微调模型,LoRA参数需要和基础模型参数结合使用。
通过PEFT加载预训练模型参数和微调模型参数,以下示例代码中,base_model_name_or_path为预训练模型参数保存路径,finetune_model_path为微调模型参数保存路径。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel,PeftConfig
# 例如: finetune_model_path='FlagAlpha/Llama2-Chinese-7b-Chat-LoRA'
finetune_model_path=''
config = PeftConfig.from_pretrained(finetune_model_path)
# 例如: base_model_name_or_path='meta-llama/Llama-2-7b-chat'
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path,device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model = PeftModel.from_pretrained(model, finetune_model_path, device_map={"": 0})
model =model.eval()
input_ids = tokenizer(['<s>Human: 介绍一下北京\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {"input_ids":input_ids,"max_new_tokens":512,"do_sample":True,"top_k":50,"top_p":0.95,"temperature":0.3,"repetition_penalty":1.3,"eos_token_id":tokenizer.eos_token_id,"bos_token_id":tokenizer.bos_token_id,"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
加载微调参数,推理结果:
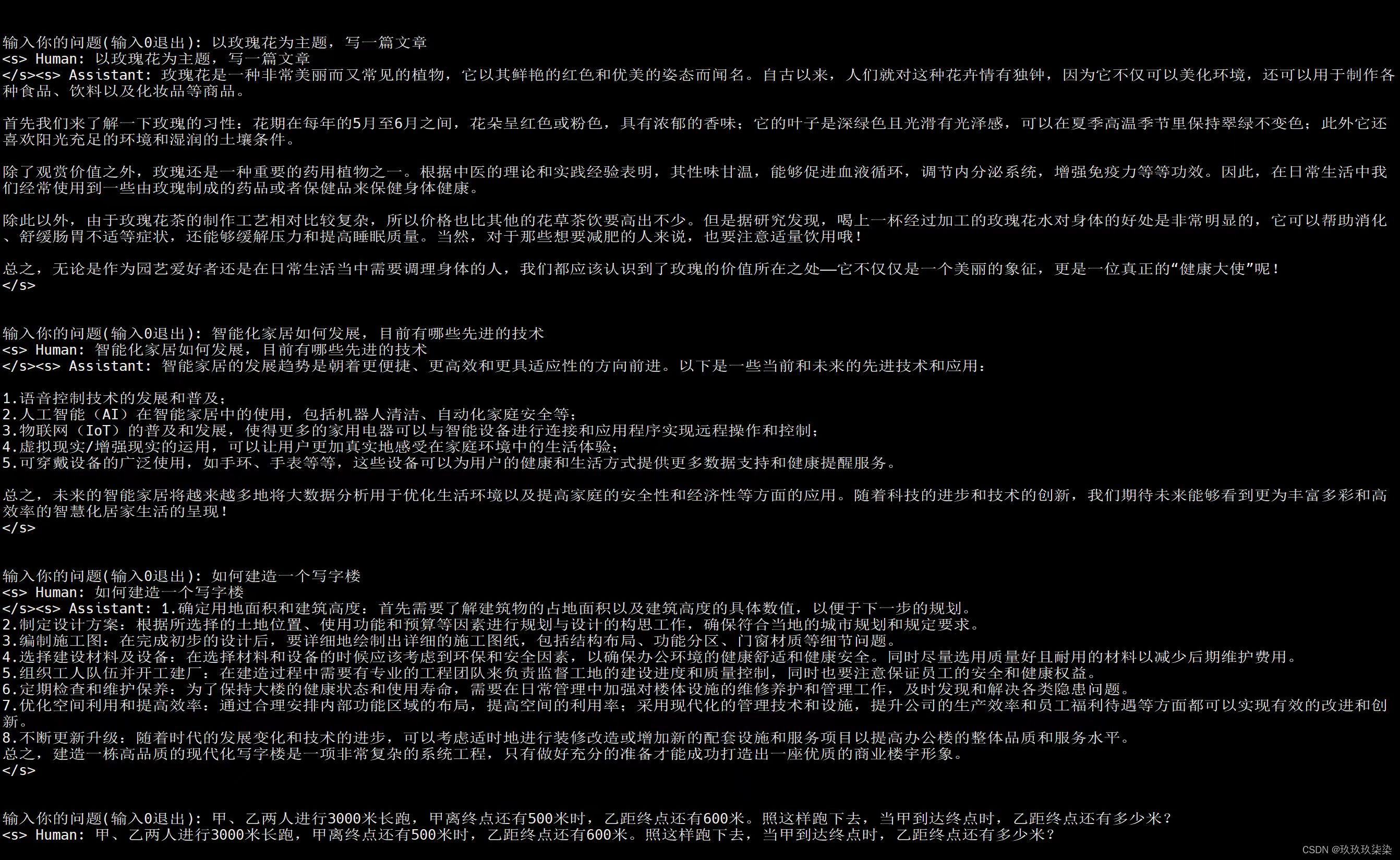
后台进行运行
eg:
nohup ./finetune_lora.sh > train.log 2>&1 &nohup ./finetune_lora_test.sh > train.log 2>&1 &
一些BUG
说多了都是泪
/home/project/GPT/Llama2-Chinese/train/sft
微调时,微调后的参数文件不能保存在这个文件夹下,否则会导致out of memory of disk,don’t find…
移出微调文件。
格式问题:csv,json之间转换需要用包处理,不然会有字符格式错误。参考extract.py。
ds: error: the following arguments are required: user_script, user_args
讲deepspeed 换成ds
torch.distributed.DistBackendError: NCCL error in: …/torch/csrc/distributed/c10d/NCCLUtils.hpp:121, unhandled cuda error (run with NCCL_DEBUG=INFO for details), NCCL ncclUnhandledCudaError: Call to CUDA function failed.
解决方案
首先,在网上找到一种方法,在训练代码命令前加以下几句代码:
export NCCL_DEBUG=info export NCCL_SOCKET_IFNAME=eth0 export NCCL_IB_DISABLE=1
export NCCL_DEBUG=info export NCCL_SOCKET_IFNAME=lo export NCCL_IB_DISABLE=1
NCCL[0] NCCL[1] 等出错,是因为cudatoolkit版本与驱动出问题。
raise HFValidationError(
huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/home//project/GPT/Llama2-Chinese/models/FlagAlpha/Llama2-Chinese-13b-Chat'. Use repo_type argument if needed.

改文件位置,改路径。两级目录。
cudatoolkit版本要与pytorch对应,否则python -m bitsandbytes,会报错,报error。conda模块有下载cudatoolkit的方法,官网需要注册。
CUDA driver version is insufficient for CUDA runtime version:
cudatoolkit的版本与驱动版本需要对应,pytorc(torch)版本也要对应。
这篇关于基于V100下Llama2-Atom大模型微调的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








