本文主要是介绍挖掘网络数据价值,构建运维场景化应用 ——数据驱动下的民生银行智能化运维创新实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文作者:云报资深记者郭涛
导言
早在2013年,民生银行就建立了“数据中心流量分析平台”,随着业务不断增长,IT构架技术变革,原有流量平台已经无法承载多样化的业务流量分析需求。而随着运维技术的新趋势进一步向AIOps(智能化运维)演进,挖掘流量数据价值,通过流量分析平台对各项目及业务系统提供数据支撑,需求已经非常迫切。2019年,民生银行上线了新一代的流量数据分析平台,并进行了数据驱动运维的应用场景探索,本次云报记者郭涛采访了民生银行总行信息科技部网络管理中心的项目负责人冯晶晶和王全,请他们分享在场景驱动下的应用创新经验。
01「 痛点:快速故障定位的困扰 」
记者:最初考虑要对网络流量进行监控和管理是出于什么样的需求和痛点呢?
冯晶晶:网络作为上层应用的最重要的基础设施,当系统应用和业务应用出现问题时,大部分人都会率先想到是不是网络出现了问题。如果没有一个好的监控分析系统,就没办法快速定位故障根本原因并第一时间解决故障。后续随着我们数据中心的运维工作逐渐向AIOps转变,我们开始尝试利用网络流量数据,在实现有效监控的基础上,同时输出高级应用场景推动整个运维工作的自动化和智能化,这时流量工具就从辅助角色变成了关键角色,除了监控更重要是智能分析能力。
记者:有没有与其他银行的网络运维特点不太一样的特征?
冯晶晶:我们希望用科技给业务赋能,助力业务的快速发展,那么具体的工作应该如何有效开展?站在网络角度,首先我们需要建立一套智能的流量数据分析系统,将网络流量数据进行深度挖掘和系统性的整合,从而利用这套系统输出对业务有高价值的应用场景;其次,把智能分析系统以产品形式对外提供服务,数据价值直观体现。
记者:之前的流量监控平台是什么样的情况呢?
冯晶晶:早期我们在流量监控这块是结合国外的一套产品来做的,由于他们的研发人员在国外,而伴随使用的深入,我们不断产生了新的应用场景急需落地,而对方往往反馈和响应时间较长,难以匹配时效性要求。如美国的Riverbed厂商在2019年月突然宣布退出亚太区市场,不再提供产品的升级和相关服务,这更加给我们工作带来较大的困扰,对项目的连续性也有很大的阻碍。同时,鉴于其他多方面原因,我行在2019年进行国内厂商新产品的引入,目前我们是与智维数据分析平台做了产品对接,结合我们运维团队对场景和技术的理解,形成了新的可视化流量数据分析平台以及相关应用。
02「 新的探索:从运维实际出发构建应用场景 」
记者:能不能描述下有哪些创新的应用场景?
王全:在数据分析这一方面,我们知道,在网络架构里负载均衡设备是众多关键业务的汇集点,物理位置优势让其成为绝佳的数据源,因此我们实现了将负载均衡业务流量和日志实时发送给流量分析平台,并与数据中心CMDB系统对接,自动生成端到端视图,实现了应用层的业务数据多维度细颗粒的展示与分析。
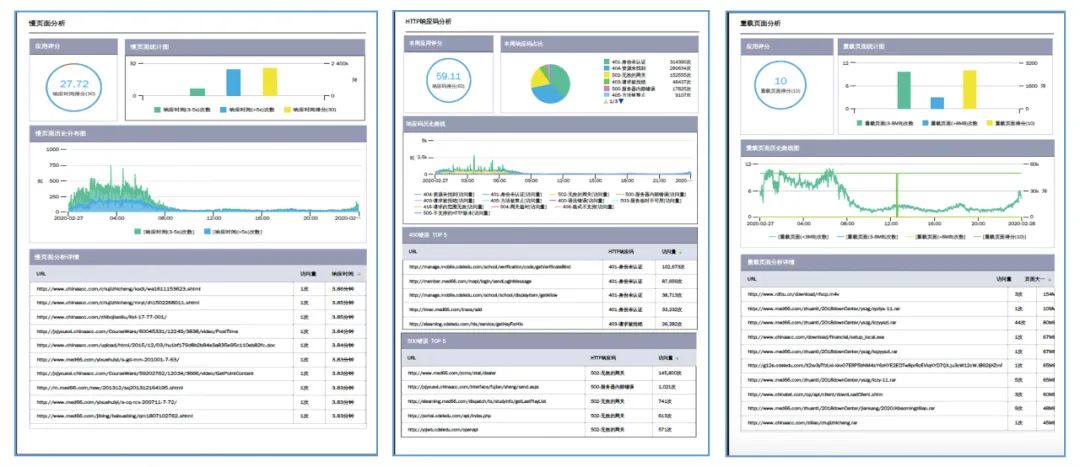
图1 URL优化统计分析详情(demo模拟)
之前,手机银行页面的URL详情开发人员和业务人员是不容易实时获取分析的,通过流量分析平台与负载均衡设备实时高速日志对接之后,就可以实时对请求和响应页面详情进行监控,并定期出具报表,输出访问量高且占用流量较大的页面,告知开发人员对其进一步评估和优化页面大小,从而降低互联网带宽。我们每年互联网运营商的带宽费用是比较高的,采用这个方案之后,可不断地降低带宽流量,单宽带费一项每年就能节省很多。
再一个就是去年我们大力推进应用系统和数据库系统的域名化改造工作,多种类型的操作系统属于首次启用域名解析功能,系统产生了大量未知或异常的DNS请求信息,在增加了网络里非必要垃圾流量的同时也给DNS系统带来了较大的性能压力。
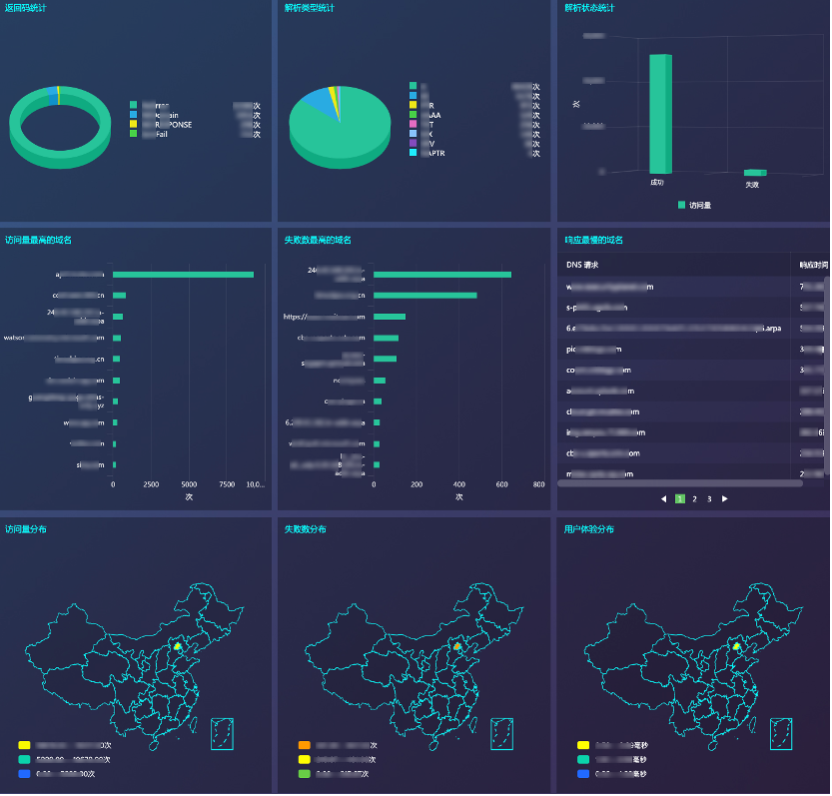
图2 DNS分析界面展示(demo模拟)
在建立新的流量分析平台后,通过可视化界面实时展示DNS请求的详情,对其请求类型智能分类和访问量排名,可实时识别出正常或异常的DNS域名请求信息,按需输出数据报表。将数据提供给系统或业务人员进行优化。通过此项功能我们快速高效地优化了大量DNS请求数据,从而使域名系统的运营效率得到了大幅提升。
记者:刚才您提到对域名系统运营效率的提升,那么在其他方面还有吗?我们是如何借助应用场景创新,提升整体运维效率的呢?
王全:借助新的流量分析平台我们可获取网络的全量流量,同时通过AI算法库、专家知识图谱、智能巡检等智能算法,可自动输出智能分析结果,展示问题根因,很大程度上提升了日常运维工作效率。例如,基于采集的数据和定期巡检任务可主动发现数据中心的异常流量及隐患问题,还可通过定期任务自动分析异常事件,可及时发现异常跨区访问、高危端口、恶意扫描等异常事件,实现主动发现和及时解决。这些都是基于我们日常运维中特别难、特别慢、特别繁琐又急需提升效率的场景去做的,而建立这些创新应用的目的就是减少对运营人员个体经验和技能的依赖,降低维护成本,从而提升整体运营效率和用户满意度。
记者:刚才说到的这些应用场景与前台业务是一种怎样的关系呢?通过后台运维技术的创新,能提升前台的客户体验吗?
王全:民生银行科技部一直在不断探索和利用人工智能、云计算、边缘计算等前沿技术提升客户体验,打造有温度的银行,快速响应客户需求,提供更优质的服务。所有的这些服务和系统都运行在数据中心,而数据中心的各种设备和系统关系越来越复杂,那么这些都给运维带来了新的挑战,这也是我们要不断提升运维技术与能力的源动力。
再以上面手机银行的例子来说,客户在手机银行办理业务的时候,能感知到的是使用的体验是否顺畅,效率是否高等等,这些稳定性和效率的保障一部分也来源于我们流量分析平台在异常检测和故障定位两方面的能力。通过对这些实际场景的创新型技术探索,比如在日志异常检测层面去分析,定位问题根因等,再通过可视化的方式展现出来,就可以得到推荐的解决方案,更好的为前台业务的稳定性服务。
03「 展望未来:持续创新,不断产出高价值的数据挖掘场景 」
记者:这次新一代网络流量分析平台的建设和创新,在我们民生银行内部有一些什么样的反馈呢?对AIOps实践之路未来的愿景是怎样的?
冯晶晶:2020年我们在智能分析这块实现了很多价值,流量分析监控包括智能告警还有故障定位等等反馈都非常好;另一方面,我们也初步实现了业务系统的互访关系视图,包括CMDB的资产数据展示等,这些都是基于业务部门的迫切需求来实现的,我们也给业务部门、调度部门、应用部门组织了多次培训,获得了他们的积极反馈。当然这些场景还有很多优化的空间,现在是基本实现了底层功能,但今年伴随业务部门对应用场景的进一步理解,在此基础上会萌生进一步的数据应用需求,比如刚才提到的资产管理和互访关系的数据关联等。我们希望未来与智维数据可以持续深入合作,把数据应用及场景进一步丰富起来,把这个流量分析平台完善成一个有架构的,有统一前端使用界面的优秀产品展现给业务用户,为自动化运维、智能化运维提供更大的价值。

这篇关于挖掘网络数据价值,构建运维场景化应用 ——数据驱动下的民生银行智能化运维创新实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



