本文主要是介绍读《Multimodal Video Sentiment Analysis Using Deep Learning Approaches, a Survey》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
最强大的多模式情感分析的架构任务是多模态多话语的架构,利用所有模式的信息和上下文信息从相邻的话语视频为了分类目标话语。该体系结构主要由两个模块组成,其顺序可能因模型而异。第一个模块是上下文提取模块,用于建模视频中相邻话语之间的上下文关系,并突出哪些相关的上下文话语对预测目标话语的情绪更重要。在最新的模型中,该模块通常是一个基于双向递归神经网络的模块。
(intra)
第二个模块是一个基于注意力的模块,它负责融合三种模式(文本、音频和视频),并只对重要的模式进行优先排序(inter)。此外,本文还简要总结了从多模态视频中提取特征的最流行的方法,并对该领域最流行的基准数据集进行了比较分析。我们希望这些发现可以帮助新来者了解整个领域的全景,并从所提供的有用的见解中获得快速的经验。这将很容易地引导他们开发更有效的模型。
引言
多模态情绪分析侧重于建模模块内交互(特定于视图的交互)和多模态交互(交叉视图交互)[10]。
模态内动力学(视图特定动力学)是指在一个特定模态内的相互作用,独立于其他模态。
另一方面,模态间动态(交叉视图动态)是指不同模态之间的相互作用,可分为同步类别和异步类别。同步交叉视图动态的一个例子是一个微笑和一个积极的词同时出现。异步交叉视图动态的一个例子是句子结束后笑声的延迟出现。多模态情绪分析的主要挑战是模态内表示和选择最佳方法来融合不同模态[1,11,12]的特征。(那这个同构异构还有些领域特殊?)
SOTA
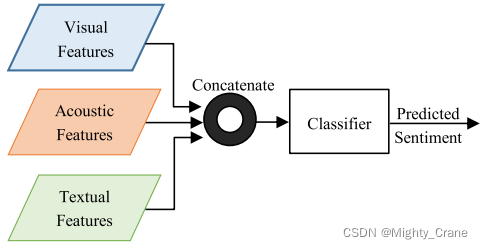
早期融合/特征级融合
所有的模式都被连接到一个视图中。然后将这个连接的视图作为预测模型的输入
(对齐拼接?),如图4a所示。预测模型可以像隐马尔可夫模型(HMMs)[69]、支持向量机(SVMs)[70]或隐条件随机场(HCRFs[71])一样简单。后来,随着深度学习的发展,递归神经网络,特别是长-短期记忆[72]已被用于序列建模
在小尺寸的训练数据集中导致过拟合,并且在直观上没有意义,因为建模视图特定的动态被忽略了,从而丢失了每个模态[73]中的上下文和时间依赖性。
THMM(三模态隐马尔可夫模型)
SVM
情绪二分类或回归
EF-LSTM(早期融合LSTM)
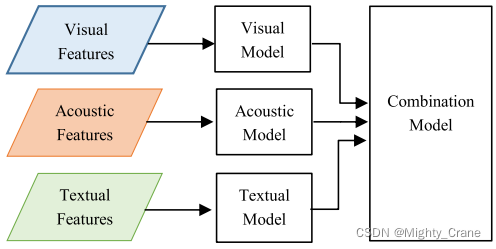
后期融合
对每个模态建立不同的模型,然后通过平均、加权和[76]、多数投票[77]或深度神经网络来组合它们的决策
(就决策层呗),如图4b所示。晚期融合方法在预测水平上集成了不同的模式。
这些模型的优点是它们是非常模块化的,并且可以从单个预先训练的单峰模型构建多模态模型,只需对输出层进行微调。这些方法通常在建模特定于视图的动态方面表现得很强,也可以优于单峰模型,但它们在建模跨视图动态方面存在问题,因为它们通常比决策投票[78]更复杂。本节将回顾使用此体系结构的一些模型。
决策投票(深度融合DF)
平均
LF-LSTM
Majority
时间融合
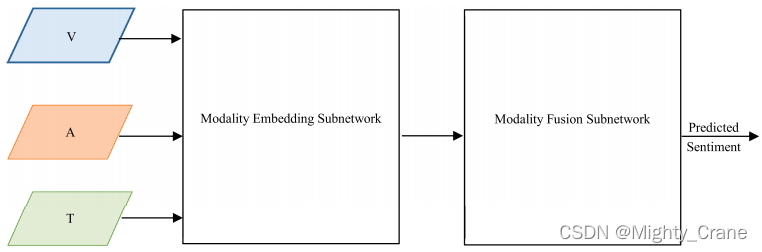
Utterance级的非时间融合
这种体系结构依赖于从输入中折叠时间维度。与体系结构3不同,模型在每个时间步长上工作,而在这个体系结构中,模型与整个话语一起工作。我们定义了三个矩阵T、A、V,它们分别由每个话语的语言特征、声学特征和视觉特征的串联组成。该体系结构中的大多数模型主要由两个主要组件组成,如图8所示。
(看描述就是先intra后inter啊,就是现在多模态的主流思想吧,这不算特征层融合?另外各自intra的话这图就画的不讲究啊)
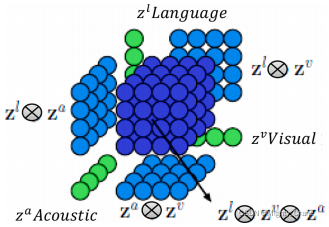
Tensor Fusion Network (TFN)
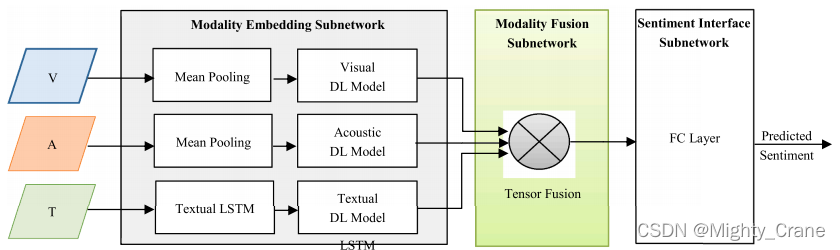
通过创建一个多维张量来执行融合,该张量捕获了三种模式之间的单峰、双峰和三峰的相互作用。它在数学上等价于视觉嵌入、声学嵌入和文本嵌入之间的外积。它是一个包含所有可能的单峰嵌入组合的三维立方体,如图9所示。因此,每个话语都可以用一个多模态张量来表示,该张量被传递到一个称为情绪推理子网络的全连接的深度神经网络,以产生一个可以用来预测情绪的向量表示(见图10)。
主要缺点是产生的张量是非常高维的,其维数随模态的数量呈指数增长。因此,情绪推理子网络中权值张量中可学习参数的数量也会呈指数增长。这引入了成本和内存的指数计算增长,并使模型暴露于过拟合[81][82]的风险。尽管这种类型的方法取得了有效性,但它们很少考虑承认特征向量不同部分的变化,这些部分可能包含不同的信息方面,因此不能使融合过程更专门的[83]。
Temporal Tensor Fusion Network (T2FN)
时间
低秩多模态融合(LMF)(这个还挺常见的)
在不影响性能的情况下提高多模态融合效率。LMF的体系结构与TFN[9]非常相似。LMF降低了参数的数量和计算的复杂度。
基于模态的冗余减少融合(MRRF)
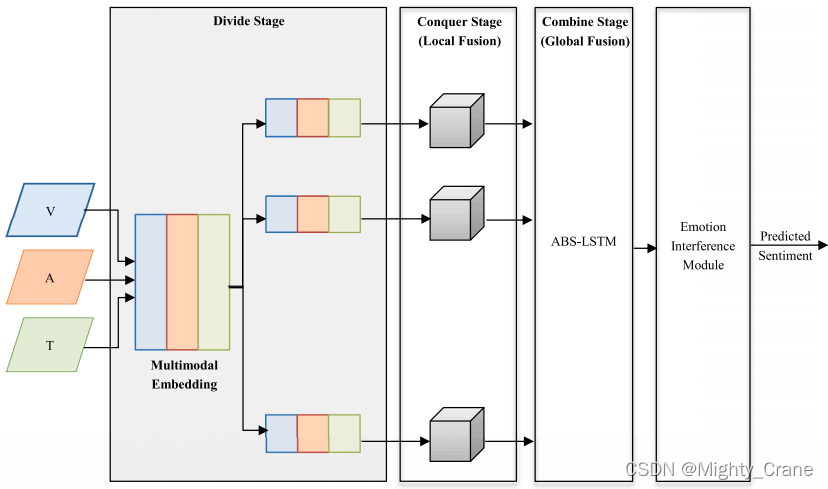
分层特征融合网络(HFFN)
(有点HGA那样先图的局部融合,再双线性block全局融合的意思)
多模态单话语自我注意(MMUUSA)
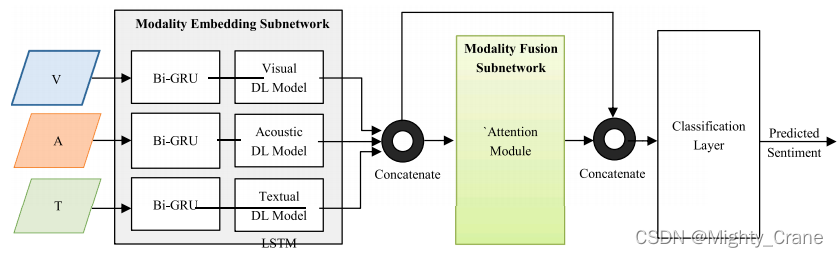
(残差啊)
多模态单话语双注意(MMUUBA)
双峰信息增强多头注意力(BIMHA)
多模态情绪分析中的情感词感知融合网络(SWAFN)
词级融合
RAVEN
多模态多通道融合
以往所有的方法都将每个话语都作为一个独立的实体,而忽略了视频中其他话语之间的关系和依赖关系。话语级情绪分析和传统的融合技术不能从多个话语中提取语境。但实际上,在同一个视频中的话语保持了一个序列,并且可以高度相关。因此,为了使模型从话语库中识别出更稳健和准确的[85,90,91],需要识别出相关和重要的信息。从这一主张出发,一些研究最近开始从其他话语的上下文信息中获益,以便对视频中的一个话语进行分类。然而,每一种形态和话语在情感和情感分类中可能没有相同的重要性,因此该结构主要由两个主要模块组成,其顺序可能因模型而异:
上下文提取模块
该模块用于模拟视频中相邻话语之间的上下文关系。此外,所有相邻的话语在目标话语的情感分类中都并不同等重要。因此,有必要强调相关语境话语中的哪些话语对预测目标话语的情绪更重要。在大多数架构中,该模块通常是一个基于双向递归神经网络的模块。
基于注意力的模态融合模块
双向上下文LSTM(Bc-LSTM)
多话语自我注意(MU-SA)
多模态多话语双注意(MMMUBA)
序列到序列(Seq2Seq)模型
基于量子的模型
这篇关于读《Multimodal Video Sentiment Analysis Using Deep Learning Approaches, a Survey》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






